谷歌推出全能扒譜AI:只要聽(tīng)一遍歌曲,鋼琴小提琴的樂(lè)譜全有了

本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
聽(tīng)一遍曲子,就能知道樂(lè)譜,還能馬上演奏,而且還掌握“十八般樂(lè)器”,鋼琴、小提琴、吉他等都不在話下。
這就不是人類音樂(lè)大師,而是谷歌推出的“多任務(wù)多音軌”音樂(lè)轉(zhuǎn)音符模型MT3。

首先需要解釋一下什么是多任務(wù)多音軌。
通常一首曲子是有多種樂(lè)器合奏而來(lái),每個(gè)樂(lè)曲就是一個(gè)音軌,而多任務(wù)就是同時(shí)將不同音軌的樂(lè)譜同時(shí)還原出來(lái)。
谷歌已將該論文投給ICLR 2022。
還原多音軌樂(lè)譜
相比于自動(dòng)語(yǔ)音識(shí)別 (ASR) ,自動(dòng)音樂(lè)轉(zhuǎn)錄 (AMT) 的難度要大得多,因?yàn)楹笳呒纫瑫r(shí)轉(zhuǎn)錄多個(gè)樂(lè)器,還要保留精細(xì)的音高和時(shí)間信息。
多音軌的自動(dòng)音樂(lè)轉(zhuǎn)錄數(shù)據(jù)集更是“低資源”的。現(xiàn)有的開源音樂(lè)轉(zhuǎn)錄數(shù)據(jù)集一般只包含一到幾百小時(shí)的音頻,相比語(yǔ)音數(shù)據(jù)集動(dòng)輒幾千上萬(wàn)小時(shí)的市場(chǎng),算是很少了。
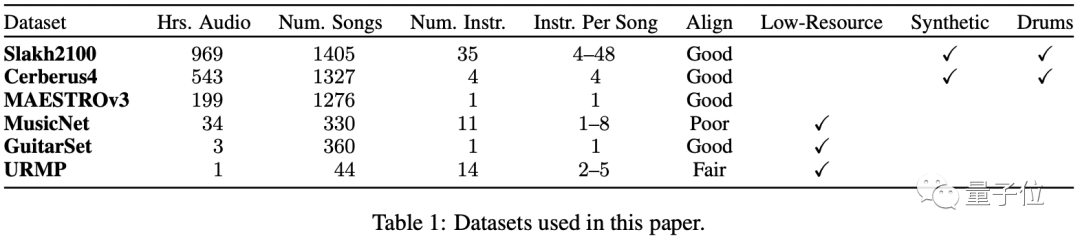
先前的音樂(lè)轉(zhuǎn)錄主要集中在特定于任務(wù)的架構(gòu)上,針對(duì)每個(gè)任務(wù)的各種樂(lè)器量身定制。
因此,作者受到低資源NLP任務(wù)遷移學(xué)習(xí)的啟發(fā),證明了通用Transformer模型可以執(zhí)行多任務(wù) AMT,并顯著提高了低資源樂(lè)器的性能。
作者使用單一的通用Transformer架構(gòu)T5,而且是T5“小”模型,其中包含大約6000萬(wàn)個(gè)參數(shù)。
該模型在編碼器和解碼器中使用了一系列標(biāo)準(zhǔn)的Transformer自注意力“塊”。為了產(chǎn)生輸出標(biāo)記序列,該模型使用貪婪自回歸解碼:輸入一個(gè)輸入序列,將預(yù)測(cè)出下一個(gè)出現(xiàn)概率最高的輸出標(biāo)記附加到該序列中,并重復(fù)該過(guò)程直到結(jié)束 。
MT3使用梅爾頻譜圖作為輸入。對(duì)于輸出,作者構(gòu)建了一個(gè)受MIDI規(guī)范啟發(fā)的token詞匯,稱為“類MIDI”。
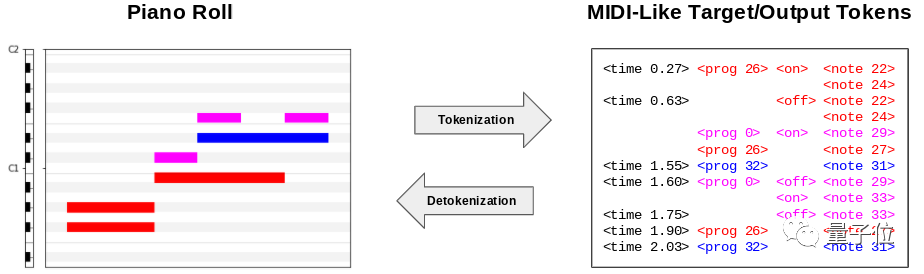
生成的樂(lè)譜通過(guò)開源軟件FluidSynth渲染成音頻。
此外,還要解決不同樂(lè)曲數(shù)據(jù)集不平衡和架構(gòu)不同問(wèn)題。
作者定義的通用輸出token還允許模型同時(shí)在多個(gè)數(shù)據(jù)集的混合上進(jìn)行訓(xùn)練,類似于用多語(yǔ)言翻譯模型同時(shí)訓(xùn)練幾種語(yǔ)言。
這種方法不僅簡(jiǎn)化了模型設(shè)計(jì)和訓(xùn)練,而且增加了模型可用訓(xùn)練數(shù)據(jù)的數(shù)量和多樣性。
實(shí)際效果
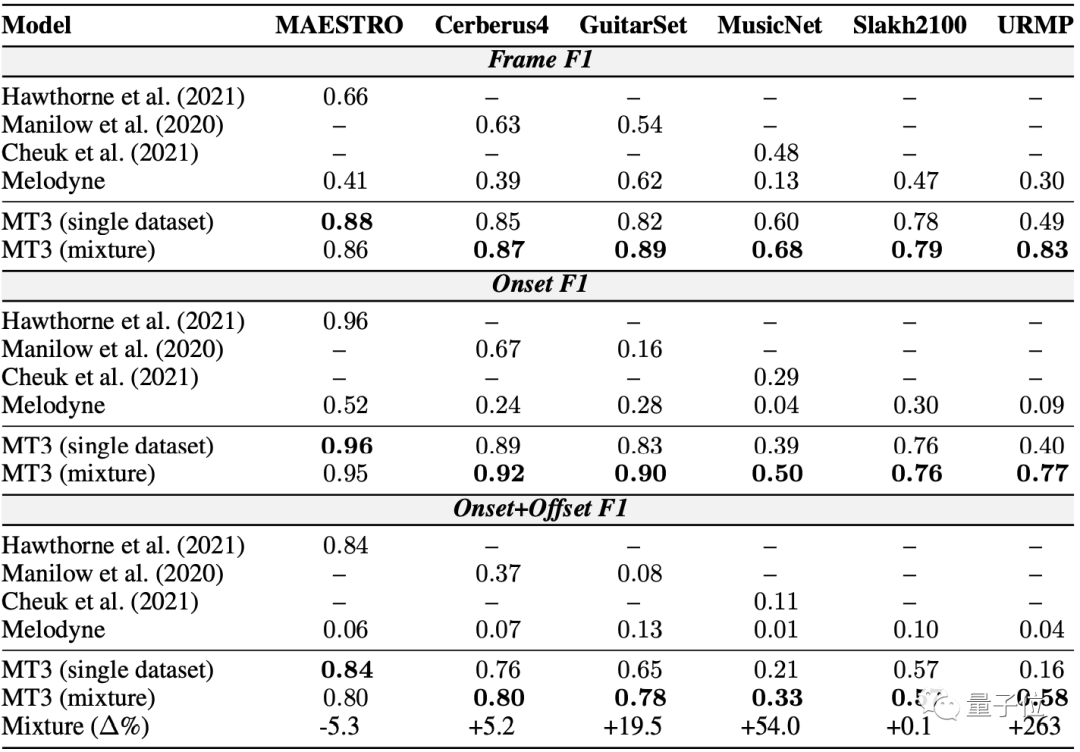
在所有指標(biāo)和所有數(shù)據(jù)集上,MT3始終優(yōu)于基線。
訓(xùn)練期間的數(shù)據(jù)集混合,相比單個(gè)數(shù)據(jù)集訓(xùn)練有很大的性能提升,特別是對(duì)于 GuitarSet、MusicNet 和 URMP 等“低資源”數(shù)據(jù)集。
最近,谷歌團(tuán)隊(duì)也放出了MT3的源代碼,并在Hugging Face上放出了試玩Demo。
不過(guò)由于轉(zhuǎn)換音頻需要GPU資源,在Hugging Face上,建議各位將在Colab上運(yùn)行Jupyter Notebook。
論文地址:
https://arxiv.org/abs/2111.03017
源代碼:
https://github.com/magenta/mt3
Demo地址:
https://huggingface.co/spaces/akhaliq/MT3