













3D模型“換皮膚”有多簡單?也就一句話的事
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
給灰突突的3D模型加“新皮膚”,這事兒能有多簡單?
現在,只需要一句話就能搞定。
看!
一個普通小臺燈,給個“Brick Lamp”的描述,瞬間變“磚塊燈”:

一匹灰色小馬,加上“Astronaut Horse”,搖身一變就成了“宇航馬”:

操作簡單不說,每一個角度上的細節和紋理也都呈現出來了。
這就是用一個專門給3D物體“換皮膚”的模型Text2Mesh做出來的,由芝加哥大學和特拉維夫大學聯合打造。

是不是有點意思?

一句話給3D物體“換皮膚”
Text2Mesh模型的輸入只需一個3D Mesh(無論原始圖像質量高低),外加一句文字描述。
具體變換過程如下:
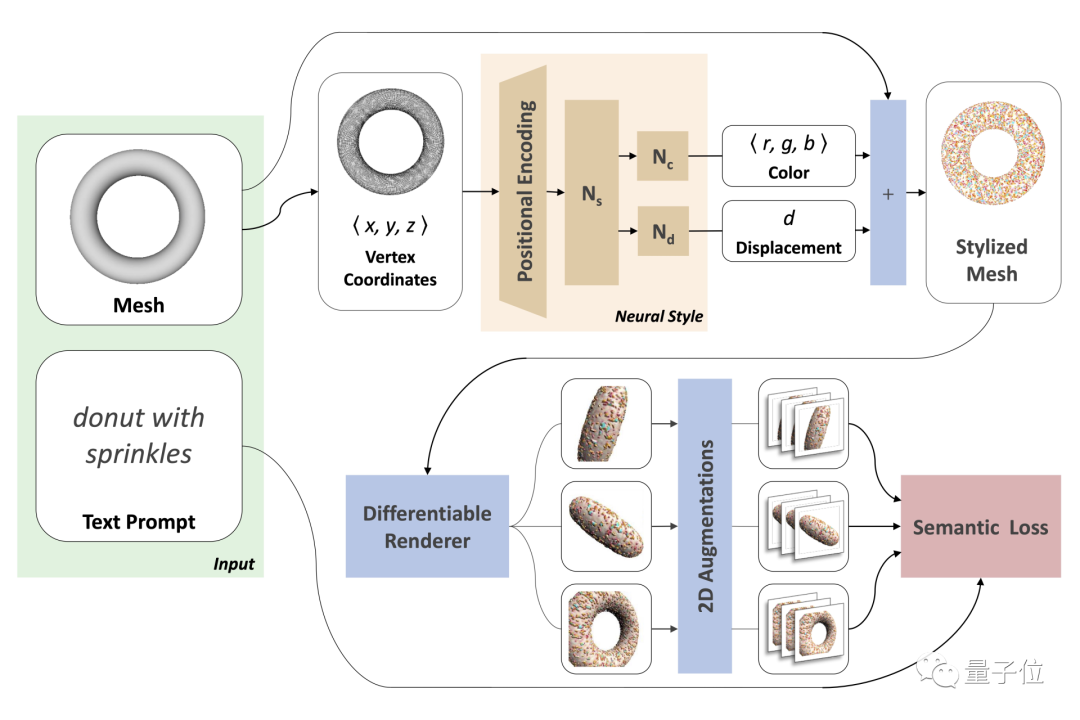
輸入的原始網格模型mesh,頂點V∈Rn×3,表面F∈{1, . . . , n}m×3,它們在整個訓練過程中固定不變。
然后再構造一個神經風格(neural style)網絡,為mesh每個頂點生成一個樣式屬性,后續好在整個表面上定義風格。
具體來說,該網絡將網格表面p∈V上的點映射成相應的RGB顏色,并沿法線方向位移,生成一個風格化了的初始mesh。
接著從多個視圖對這個mesh進行渲染。
再使用CLIP嵌入的2D增強技術讓結果更逼真。
在這個過程中,渲染圖像和文本提示之間的CLIP相似性得分,會被作為更新神經網絡權重的信號。
整個Text2Mesh不需要預訓練,也不需要專門的3D Mesh數據集,更無需進行UV參數化(將三角網格展開到二維平面)。
具體效果如何?
Text2Mesh在單個GPU上訓練的時間只需不到25分鐘,高質量的結果可以在10分鐘之內出現。
它可以生成各種風格,并且細節還原非常到位:

再比如下面這個,不管是變雪人、忍者、蝙蝠俠、綠巨人,還是喬布斯、梅西、律師……衣服的褶皺、配飾、肌肉、發絲……等細節都可以生動呈現。

研究人員還設計了一個用戶調查,將Text2Mesh與基線方法VQGAN相比。
評分涉及三個問題:1、生成的結果自然程度;2、文本與結果的匹配度;3、結果與原始圖像的匹配度。
57名用戶打分后,得出的結果如下:
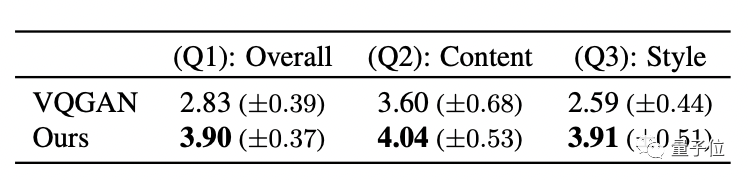
Text2Mesh在每一項上得分都比VQGAN高。
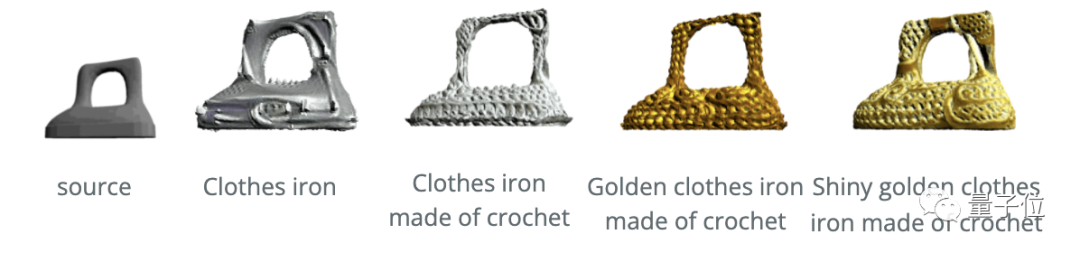
此外,在更復雜、更特殊的文本描述之下,Text2Mesh也能hold住。
比如“由鉤針編織成的閃亮的金色衣服熨斗”:
“帶波紋金屬的藍鋼luxo臺燈”:

更厲害的是,Text2Mesh模型還可以直接使用圖片驅動。
比如就給一張仙人掌的照片,也能直接把原始灰色的3D小豬變成“仙人掌風格”:

One More Thing
Text2Mesh代碼已開源,在Kaggle Notebook上也有人上傳了demo。感興趣的便朋友可以一試:
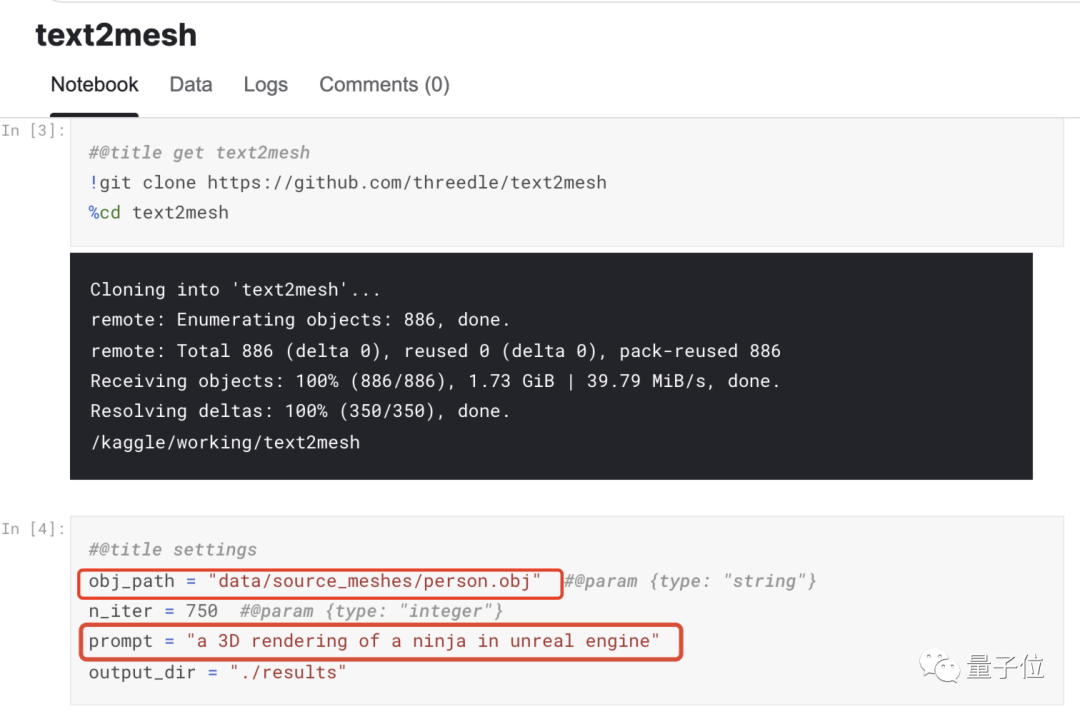
最后,大家知道這是只啥么?

demo地址:
https://www.kaggle.com/neverix/text2mesh/
論文:
https://arxiv.org/abs/2112.03221
代碼:
https://github.com/threedle/text2mesh
參考鏈接:
https://threedle.github.io/text2mesh/
























