













橫掃6個SOTA,谷歌行為克隆算法登CoRL頂會,機器人干活10倍速
谷歌團隊在CoRL 2021上提出了一種隱式行為克隆 (Implicit BC) 算法,該方法在7項測試任務中的6項上優于此前最佳的離線強化學習方法(Conservative Q Learning)。Implicit BC在現實世界中表現也得特別好,比基線的顯式行為克隆(explicit BC)模型好10倍。
盡管過去幾年中,機器人學習取得了相當大的進步,但在模仿精確或復雜的行為時,機器人代理的一些策略仍難以果斷地選擇動作。
要讓機器人把桌子上的小滑塊精確地滑進一個插槽里。解決這個任務有很多方法,每種方法都需要精確的移動和修正。機器人只能采取這些策略選項中的一個,還必須在每次滑塊滑得比預期的更遠時及時改變策略。
人類可能認為這樣的任務很容易,但對于機器人來說,情況往往并非如此,它們經常會學習一些人類專家看來「優柔寡斷」或「不精確」的行為。

機器人需要在桌子上滑動滑塊,然后將其精確插入固定裝置,顯式行為克隆模型表現得很猶豫
為了讓機器人更加果斷,研究人員經常利用離散化的動作空間,迫使機器人進行明確的「二選一」,而不是在選項之間搖擺不定。
比如,離散化是近年來很多游戲agent著名模型的固有特征,比如AlphaGo、AlphaStar 和 OpenAI 打Dota的AI agent。
但離散化有其自身的局限性——對于在空間連續的現實世界中運行的機器人來說,離散化至少有兩個缺點:
- 精度有限。
- 因計算維度導致成本過高,許多離散化不同的維度會顯著增加內存和計算需求。在 3D 計算機視覺任務中,近期的許多重要模型都是由連續,而非離散表示來驅動的。
為了學習沒有離散化特征缺陷的決定性策略,谷歌團隊提出了一種隱式行為克隆 (Implicit BC) 的開源算法,這是一種新的、簡單的模仿學習方法,已經在 CoRL 2021 上展示。
該方法在模擬基準任務和需要精確和果斷行為的現實世界機器人任務上都取得了很好的結果。在7項測試任務中,隱式 BC 的性能在其中6項上優于此前最佳的離線強化學習方法(Conservative Q Learning)。
有趣的是,隱式 BC 在不需要任何獎勵信息的情況下實現了這些結果,即可以使用相對簡單的監督學習,而不是更復雜的強化學習。
隱式行為克隆(Implicit BC)
這種方法是一種行為克隆,可以說是機器人從演示中學習新技能的最簡單的方法。在行為克隆中,agent會學習如何通過標準監督學習模仿專家的行為。傳統的行為克隆一般是訓練一個顯式神經網絡(如下圖左所示),接受觀察并輸出專家動作。
而隱式行為克隆背后的關鍵思想是,訓練一個神經網絡來接受觀察和動作,并輸出一個數字,該數字對專家動作來說很低,對非專家動作來說很高,將行為克隆變成一個基于能量的建模問題。
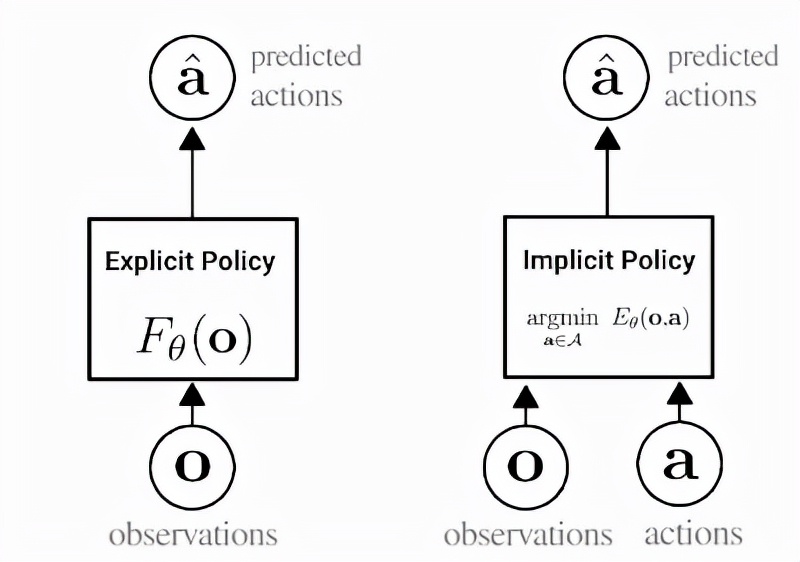
顯式(左)和隱式(右)策略之間差異的描述。在隱式策略中,「argmin」表示與特定觀察配對時最小化能量函數值的動作。
訓練后,隱式行為克隆策略會查找對給定觀察具有最低能量函數值的動作輸入,以此生成動作。
為了訓練隱式 BC 模型,研究人員使用InfoNCE損失,讓網絡為數據集中的專家動作輸出低能量,為所有其他動作輸出高能量。有趣的是,這種使用同時接受觀察和行動的模型的思想在強化學習中很常見,但在有監督的策略學習中則不然。
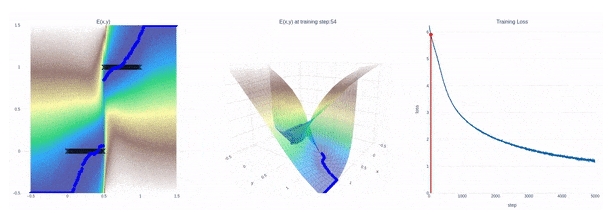
上圖所示為隱式模型如何適應不連續性的動畫——在這種情況下,訓練隱式模型來適應一個步長(Heaviside)函數。左:擬合黑色訓練點的2D圖,顏色代表能量值(藍色低,棕色高)。中間:訓練期間能量模型的3D圖。右圖:訓練損失曲線。
一旦經過訓練,Google AI發現隱式模型(implicit model)特別擅長精確地建模先前顯式模型(explicit model)難以解決的不連續性問題,從而產生新的策略,能夠在不同行為之間果斷切換。

為什么傳統的顯式模型(explicit model)在這個問題上表現不佳呢?
現代神經網絡幾乎總是使用連續激活函數——例如,Tensorflow、Jax和PyTorch都只提供連續激活函數。
在試圖擬合不連續數據時,用這些激活函數構建的顯式網絡無法準確表示,因此必須在數據點之間繪制連續曲線。隱式模型(implicit model)的一個關鍵優勢是,即使網絡本身僅由連續層組成,也能夠表示出尖銳的不連續性。
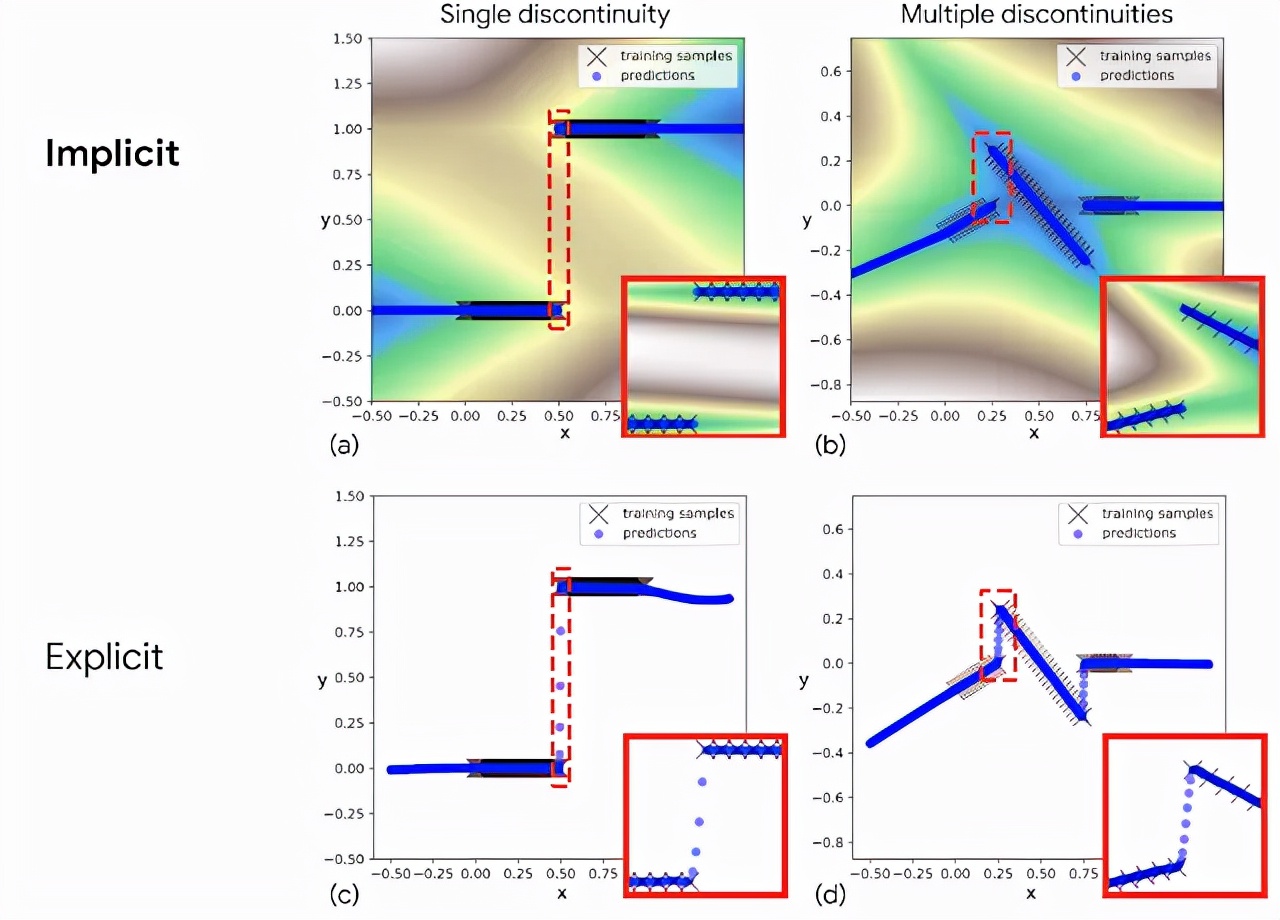
與顯式模型(底部)相比,隱式模型(頂部)擬合不連續函數的示例。紅色突出顯示的插圖顯示,隱式模型表示不連續性(a)和(b),而顯式模型必須在不連續性之間畫出連續的線(c)和(d)
Google AI在這個方面建立了理論基礎,提出了一個普遍近似的概念,證明了隱式神經網絡可以表示的函數類別,這將有助于證明和指導未來的研究。
Google AI最初嘗試這種方法時面臨的一個挑戰是「高動作維度」,這意味著機器人必須決定如何同時協調多個電機。為了擴展到高作用維度,Google AI使用自回歸模型或朗之萬動力學。
全新SOTA
在實驗中,Google AI發現Implicit BC在現實世界中表現得特別好,在毫米精度的滑塊滑動及插槽任務上比基線的顯式行為克隆(explicit BC)模型好10倍。
在此任務中,隱式模型(implicit model)在將滑塊滑動到位之前會進行幾次連續的精確調整。

將滑塊精確地插入插槽的示例任務。這些是隱式策略的自主行為,僅使用圖像(來自所示的攝像機)作為輸入
這項任務有多種決定性因素:由于塊的對稱性和推動動作的任意順序,有許多不同的可能解決方案。
機器人需要決定滑塊何時已經被推動足夠遠,然后需要切換到向不同方向滑動。這一過程是不連續的,所以,連續控制型機器人在這一任務上會表現得十分優柔寡斷。

完成這項任務的不同策略。這些是來自隱式策略的自主行為,僅使用圖像作為輸入
在另一個具有挑戰性的任務中,機器人需要按顏色對滑塊進行篩選,由于挑選順序是很隨意的,這就產生了大量可能的解決方案。

頗具挑戰性的連續篩選任務中顯式BC模型的表現(4倍速度)
在這項任務中,顯式模型(explicit model)還是表現得很拿不準,而隱式模型(implicit model)表現得更好。

頗具挑戰性的連續篩選任務中隱式BC模型表現(4倍速度)
而且在Google AI的測試中,Implicit BC在面臨干擾時,盡管模型從未見過人類的手,也依然可以表現出強大的適應能力。

機器人受到干擾時,隱式BC模型的穩健行為
總的來說,Google AI發現,與跨多個不同任務領域的最先進的離線強化學習方法相比,Implicit BC策略可以獲得更好的結果。
Implicit BC可以完成很多具有挑戰性的任務,比如演示次數少(少至19次),基于圖像的觀察具有高觀察維度,還有高達30維的高動作維度,這就需要機器人充分利用自身具有的大量致動器。
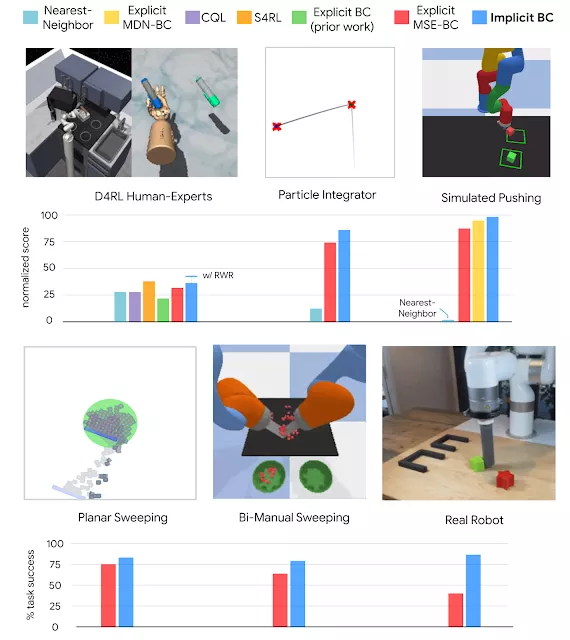
隱式策略學習結果與跨多個域的基線進行了比較
盡管Implicit BC目前還有其局限性,但使用監督學習的行為克隆仍然是機器人從人類行為例子中學習的最簡單方法之一。
該工作表明,在進行行為克隆時,用隱式策略替換顯式策略可以讓機器人克服「猶猶豫豫」,使它們能夠模仿更加復雜和精確的行為。
雖然Implicit BC取得的實驗結果來自機器人學習問題上,但是隱式函數對尖銳不連續性和多模態標簽建模的能力可能在機器學習的其他領域也有更廣泛的應用。
















