













豪取四個SOTA,谷歌魔改Transformer登NeurIPS 2021
谷歌改造Vision Transformer的新作被NeurIPS 2021收錄了。在這篇文章里,谷歌提出了TokenLearner方法,Vision Transformer用上它最多可以降低8倍計算量,而分類性能反而更強!
目前,Transformer模型在計算機視覺任務(包括目標檢測和視頻分類等任務)中獲得了最先進的結果。
不同于逐像素處理圖像的標準卷積方法,Vision Transformer(ViT)將圖像視為一系列patch token(即由多個像素組成的較小部分圖像)。
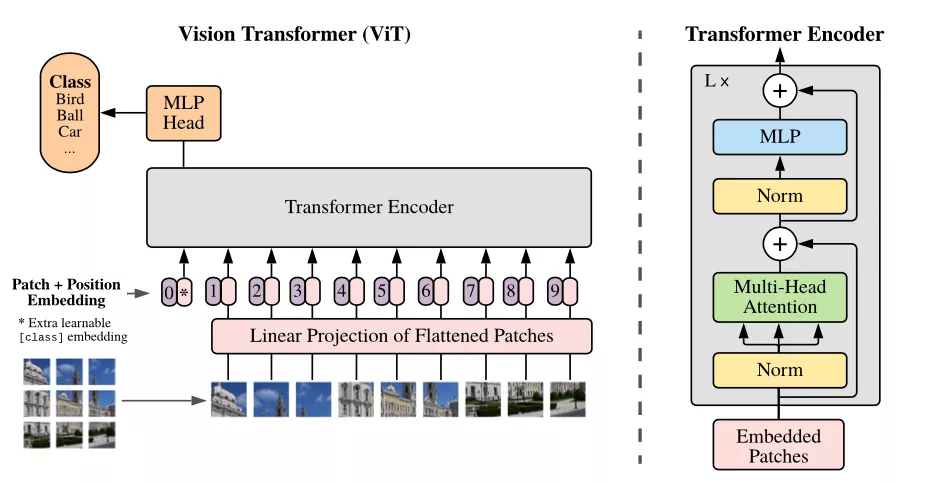
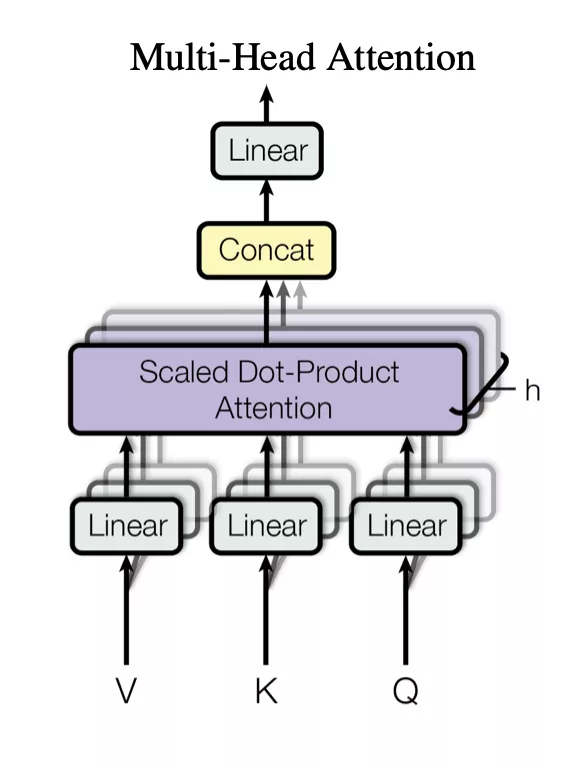
這也就意味著在每一層神經網絡中,ViT模型使用多頭自注意力(multi-head self-attention),基于每對token之間的關系來處理patch token。
這樣,ViT模型就能夠構建整個圖像的全局表示。
在輸入端,將圖像均勻地分割成多個部分來形成token,例如,將512×512像素的圖像分割成16×16像素的patch token。在中間層,上一層的輸出成為下一層的token。
這里插一句。如果處理的是視頻,則視頻「管道」如16x16x2視頻片段(2幀16x16圖像)就成為了token。視覺token的質量和數量決定了Vision Transformer的整體性能。
許多Vision Transformer結構面臨的主要挑戰是,它們通常需要太多的token才能獲得合理的結果。
例如,即使使用16x16patch token化,單個512x512圖像也對應于1024個token。對于具有多個幀的視頻,每層可能都需要處理數萬個token。
考慮到Transformer的計算量隨著token數量的增加而二次方增加,這通常會使Transformer難以處理更大的圖像和更長的視頻。
這就引出了一個問題:真的有必要在每一層處理那么多token嗎?
谷歌在「TokenLearner:What Can 8 Learned Tokens Do for Images and Videos?」中提到了「自適應」這個概念。這篇文章將在NeurIPS 2021上進行展示。

論文地址:https://arxiv.org/pdf/2106.11297.pdf
項目地址:
https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
實驗表明,TokenLearner可以自適應地生成更少數量的token,而不是總是依賴于由圖像均勻分配形成的token,這樣一來,可以使Vision Transformer運行得更快,性能更好。
TokenLearner是一個可學習的模塊,它會獲取圖像張量(即輸入)并生成一小組token。該模塊可以放置在Vision Transformer模型中的不同位置,顯著減少了所有后續層中要處理的token數量。
實驗表明,使用TokenLearner可以節省一半或更多的內存和計算量,而分類性能卻并不會下降,并且由于其適應輸入的能力,它甚至可以提高準確率。
TokenLearner是啥?
TokenLearner其實是一種簡單的空間注意力方法。
為了讓每個TokenLearner學習到有用的信息,先得計算一個突出的重要區域的空間注意力圖(使用卷積層或MLP)。
接著,這樣的空間注意力圖會被用來對輸入的每個區域進行加權(目的是丟棄不必要的區域),并且結果經過空間池化后,就可以生成最終的學習好了的token。
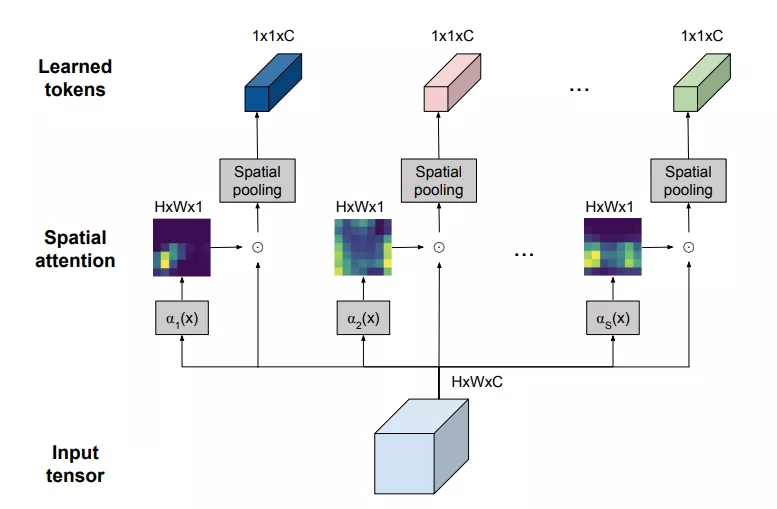
應用于單個圖像的TokenLearner模塊的直觀圖示
TokenLearner學習在張量像素的子集上進行空間處理,并生成一組適應輸入的token向量。
這種操作被并行重復多次,就可以從原始的輸入中生成n個(10個左右)token。
換句話說,TokenLearner也可以被視為基于權重值來執行像素的選擇,隨后進行全局平均。
值得一提的是,計算注意力圖的函數由不同的可學習參數控制,并以端到端的方式進行訓練。這樣也就使得注意力函數可以在捕捉不同輸入中的空間信息時進行優化。
在實踐中,模型將學習多個空間注意力函數,并將其應用于輸入,并平行地產生不同的token向量。
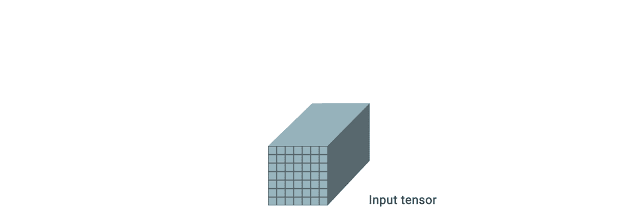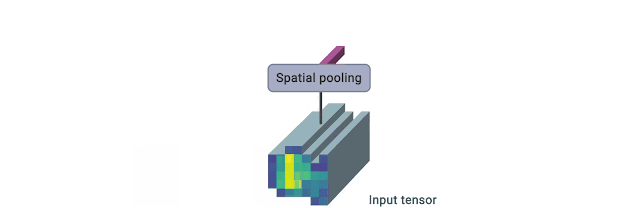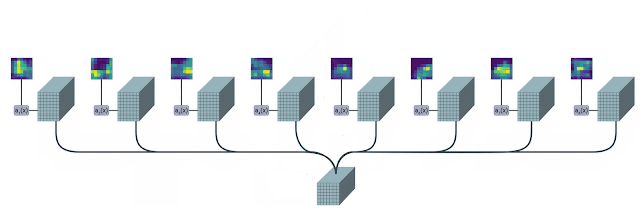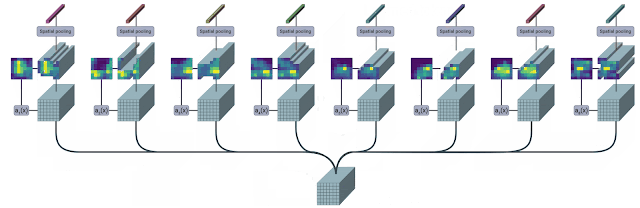
TokenLearner模塊學習為每個輸出標記生成一個空間注意力圖,并使用它來抽象化輸入的token
因此,TokenLearner使模型能夠處理與特定識別任務相關的少量token,而不是處理固定的、統一的token化輸入。
也就是說,TokenLearner啟用了自適應token,以便可以根據輸入動態選擇token,這一做法有效地減少了token的總數,大大減少了Transformer網絡的計算。
而這些動態自適應生成的token也可用于標準的Transformer架構,如圖像領域的ViT和視頻領域的ViViT(Video Vision Transformer)。
TokenLearner放在哪?
構建TokenLearner模塊后,下一步就必須要確定將其放置在哪個位置。
首先,研究人員嘗試將它放置在標準ViT架構中的不同位置,輸入圖像使用224x224的大小。
TokenLearner生成的token數量為8個和16個,遠遠少于標準ViT使用的196個或576個token。
下圖顯示了在ViT B/16中的不同相對位置插入TokenLearner的模型的ImageNet 5-shot分類精度和FLOPs,其中ViT B/16是一個基礎模型,有12個注意力層。其運行時使用16x16大小的patch token。
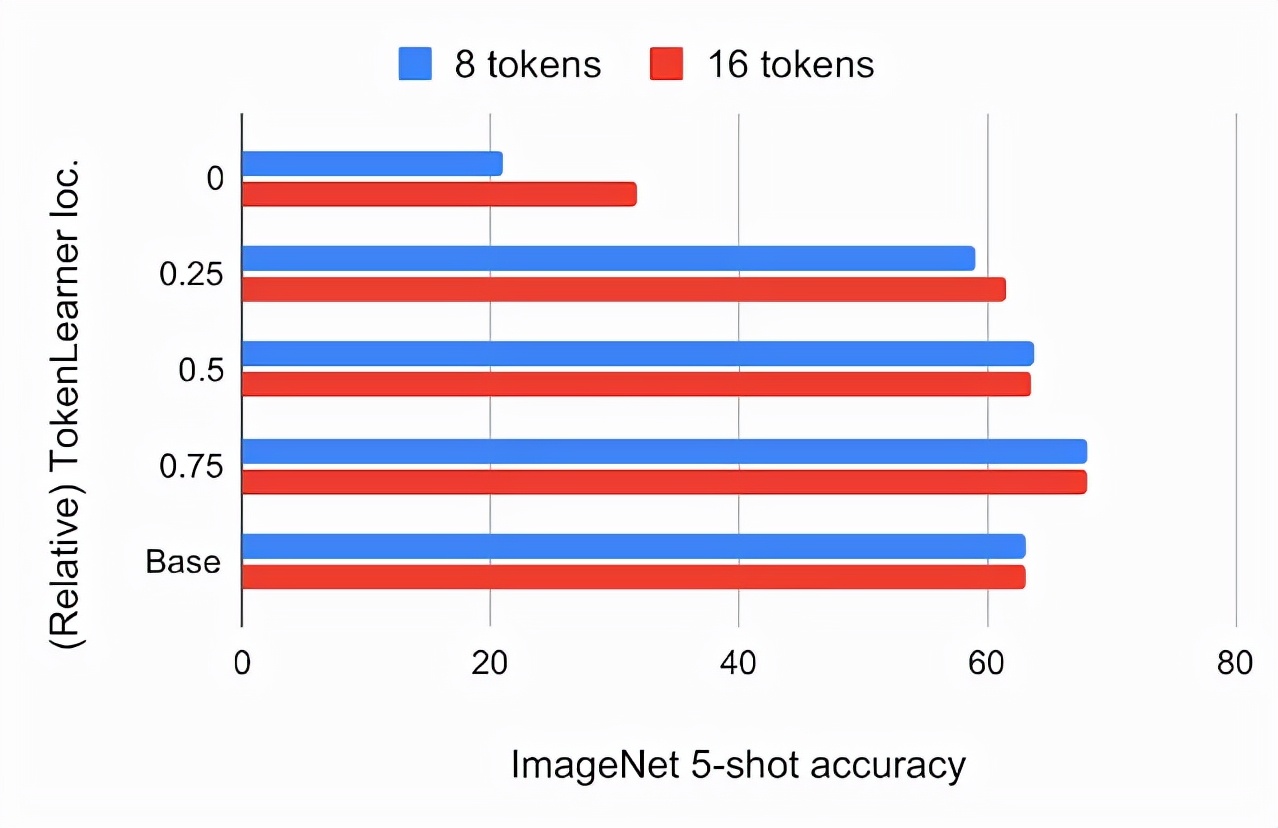
在JFT 300M的預訓練下,ImageNet的5-shot精度與ViT B/16中TokenLearner的相對位置有關
位置0意味著TokenLearner被置于任何Transformer層之前。其中,baseline是標準的ViT B/16的ImageNet 5-shot分類精度和FLOPs。
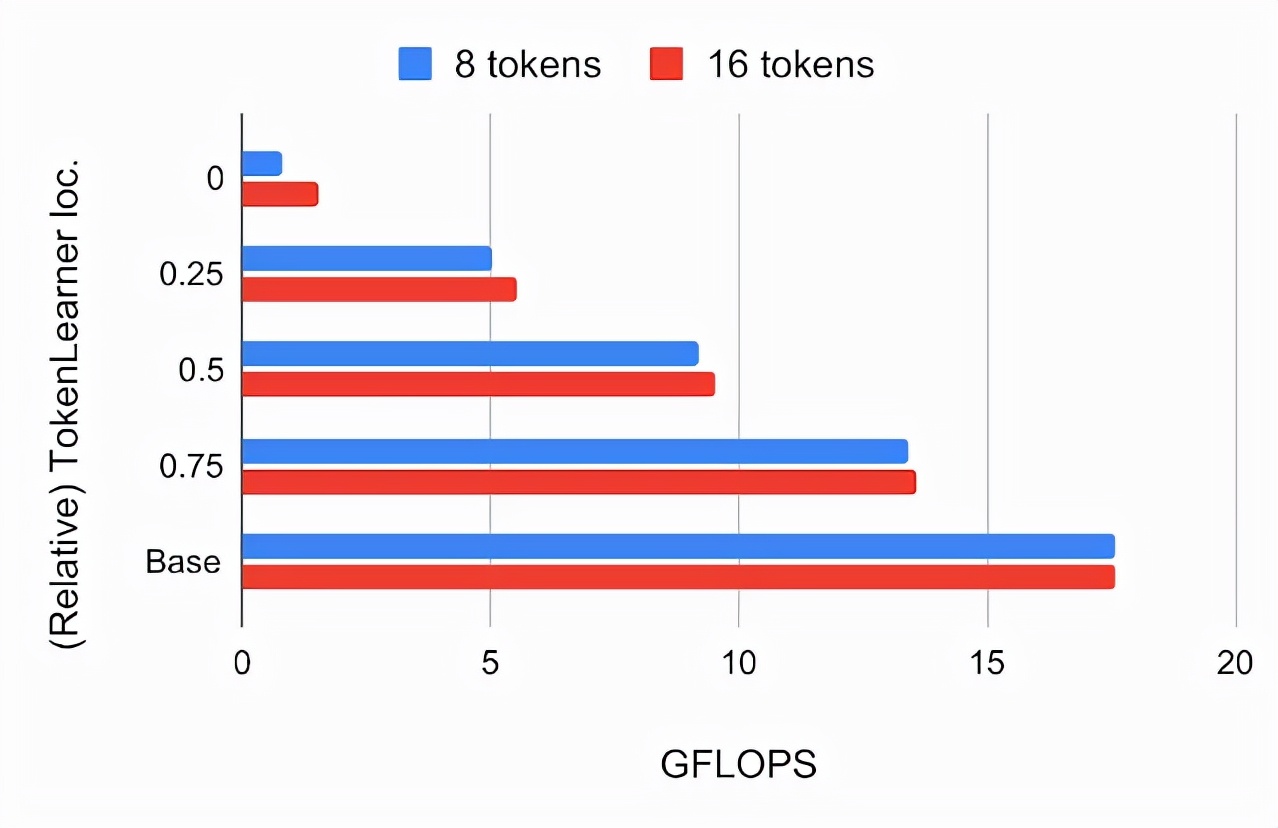
計算量以數十億次浮點運算(GFLOPS)衡量
我們發現,在網絡的最初四分之一處(1/4處)插入TokenLearner,實現了與基線幾乎相同的準確性,同時將計算量減少到基線的三分之一以下。
此外,將TokenLearner放在后面一層(網絡的3/4之后),與不使用TokenLearner相比,取得了更好的性能,同時由于其適應性,性能更快。
由于TokenLearner前后的token數量相差很大(例如,前196個,后8個),TokenLearner模塊后的相對計算量幾乎可以忽略不計。
TokenLearner VS ViT
將帶有TokenLearner的ViT模型和普通的ViT模型進行對比,同時在ImageNet的few-shot上采用相同的設置。
TokenLearner會被放置在每個ViT模型中間的不同位置,如網絡的1/2和3/4處。其中,模型通過JFT 300M進行預訓練。
從圖上觀察可以得知,TokenLearner模型在準確率和計算量方面的表現都比ViT要好。
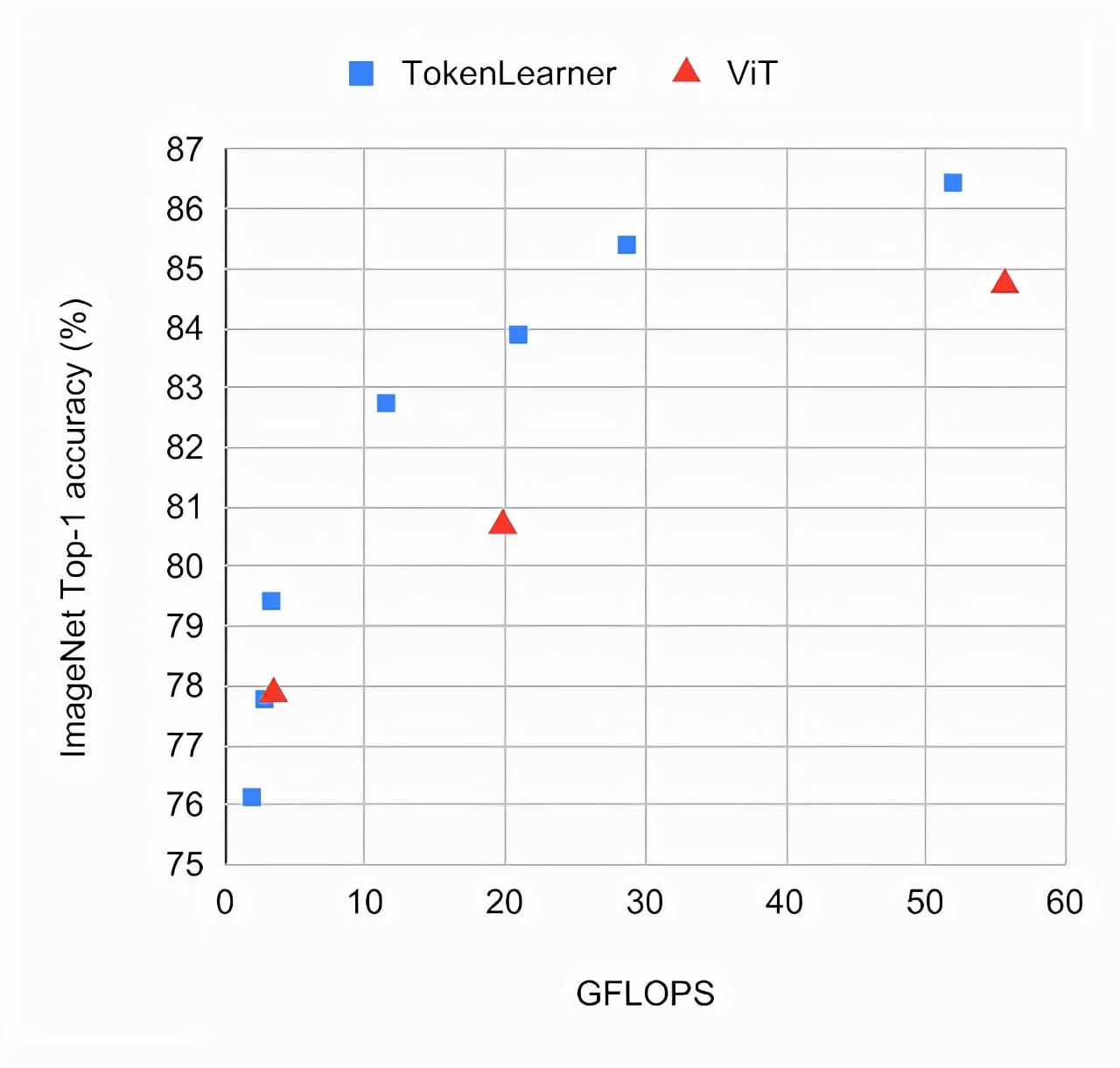
不同版本的ViT模型在ImageNet分類上的表現
在更大的ViT模型中插入TokenLearner,如具有24個注意力層,并以10x10(或8x8)個patch作為初始token的L/10和L/8。
之后,將這兩個模型與48層的ViT G/14模型進行比較。
可以看到,在表現和G/14模型相當的情況下,TokenLearner只需要非常少的參數和計算量。
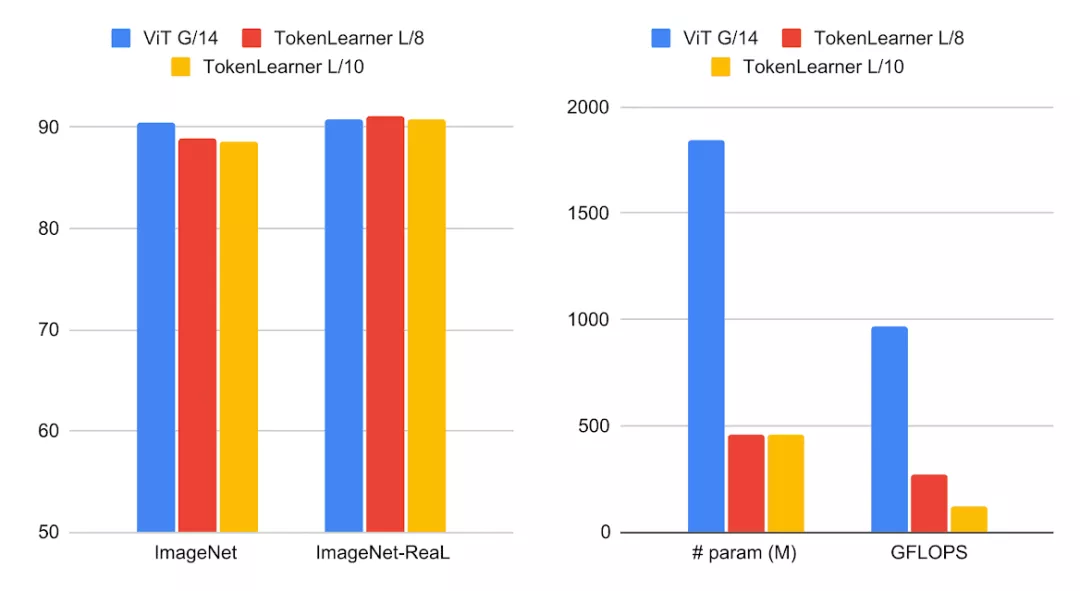
左:大規模TokenLearner模型與ViT G/14在ImageNet數據集上的分類精度對比;右:參數量和FLOPS的對比
高性能視頻模型
視頻理解是計算機視覺的關鍵挑戰之一,TokenLearner在多個視頻分類數據集基準上取得了SOTA的性能。
其中,在Kinetics-400和Kinetics-600上的性能超過了以前的Transformer模型,在Charades和AViD上也超過了之前的CNN模型。
通過與視頻視覺Transformer(Video Vision Transformer,ViViT)結合,TokenLearner會在每個時間段學習8(或16)個token。
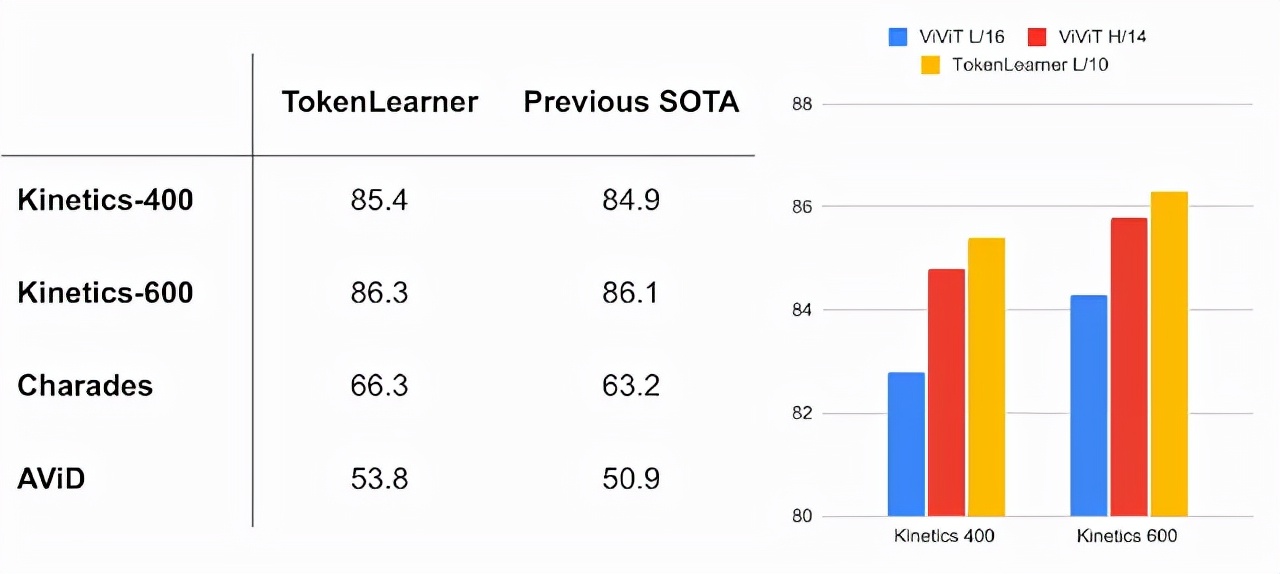
左:視頻分類任務;右圖:不同模型的對比
隨著時間的推移,當人物在場景中移動時,TokenLearner會注意到不同的空間位置變化從而進行token化。
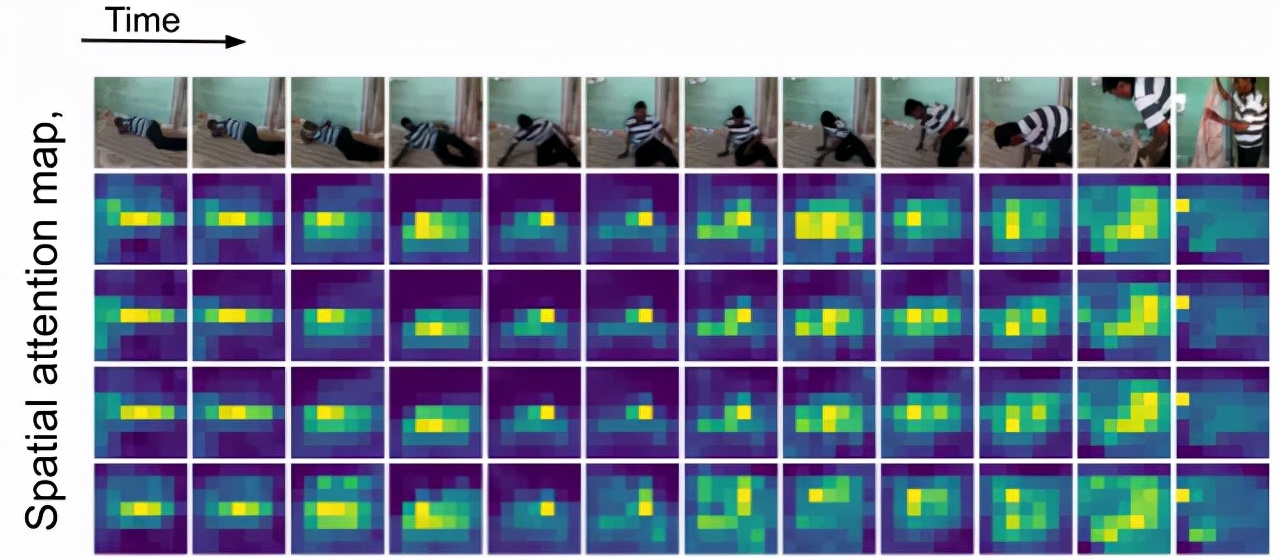
TokenLearner的空間注意力圖的可視化
結論
雖然Vision Transformer是計算機視覺領域的一個強大模型,但大量的token及龐大的計算量一直是將ViT應用于更大圖像和更長視頻的瓶頸。
本文中作者表明,保留如此大量的token并在整個層集上完全處理它們是沒有必要的。
此外,作者還證明了通過學習一個基于輸入圖像自適應提取token的模塊,可以在節省計算的同時獲得更好的性能。
最后,多個公共數據集上的驗證也表明了TokenLearner在視頻表征學習任務中的表現十分優異。





















