













嵌入式算法之大數據變長存儲算法

1、應用場景
對于高精度采樣結果,其數值最大可能需要3字節,最少1字節,采用標準C的基礎數據類型,U16太小無法滿足需求,U32則浪費內存。當樣本量很大時,其占用的空間問題便突顯出來。能否采用變長數據類型存儲呢?對小數據采用U8,大數據采用U32,隨著數值大小動態分配存儲空間,就是本文的討論的重點。
2、數據去冗余
U32的空間其數值范圍最大接近2^32,該值非常大,實際數值范圍遠小于它,高位必然為0。例如U32表示1使用0x00000001,前面位都是0,其表達的數值和U8的0x01是一樣的,前面重復的一串0屬于冗余數據區,是可以剔除的。
假設5個數據D0..4,原本每個數據固定為U32類型,將其高位冗余0去掉,再拼接到U8的一維數組,則占用的空間和大大縮小。思路的核心是把 U32 或者U64 數組裁剪后拼接成U8 數組,同時確保使用時可
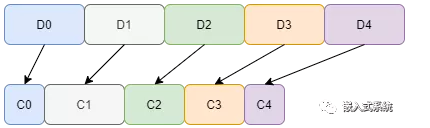
根據U8 數組中存儲的信息將對應的數值還原。
假設有0x00000001、0x00000101、0x00000001三個數據,其有效部分是0x01、0x0101、0x01,如果直接拼接在一起,則沒法區分0x01010101的含義。因此數據在去掉高位0之后,還需進行編碼標記,便于后續解析還原。
3、數據編碼
數據編碼的主要作用是標記當前數據占用多少連續字節,有兩種方案:
1、固定位來定義字節長度(2位可以表示4字節)
一字節:00******
二字節:01******,00******
三字節:10******,01******,00******
四字節:11******,10******,01******,00******
五字節:使用2位不支持
每個字節的最高2位表示屬于原始數據的第幾個(從0開始),前面舉例的3個字節可以表示為:
0x01 編碼后二進制為 00-000001,最高2位為0,表示當前是編碼后的數據的最后一個字節;
0x0101 編碼后二進制為 01-000001--00-000001 解析時取每個字節的2位判斷,若為00則表示一個編碼數值結束。
因為前面2位固定用于標記字節數,每個字節實際可用范圍只有6位,如果原數據位1000 0001,則最高兩位的10需要再占用一個字節表示,最終編碼為 01-000010--00-000001。
這種編碼方式,所有字節有效位是固定的,編解碼實現容易。缺點是4字節只有24位有效數據,假如原數據最大到25位,則每個字節分配3位來表示,不過這種大數據一般嵌入式很少使用。
2、字節最高位表示還有剩余數據,借鑒UTF8的編碼方式
一字節:0*******
兩字節:110*****,10******
三字節:1110****,10******,10******
四字節:11110***,10******,10******,10******
五字節:111110**,10******,10******,10******,10******
六字節:1111110*,10******,10******,10******,10******,10******
七字節:不支持
這種編碼方式,最高字節的有效位是變化的,其它字節有效位是6位。
兩種編碼方式的選取,主要是依據原始數據分布概率,如果原數據范圍在24位內,則前面固定位的方式占優,超過32位內則動態的合適,如果數據范圍在16位內則沒必要如此折騰。
關于源碼或者更多交流,請關注微信公眾號 嵌入式系統。
4、數據訪問
原數據每個值占用固定字節長度,可以方便的使用數組下標遍歷,即地址偏移為(單個數字占用的字節數)*(第幾個),編碼為變長數據后,要想取到某個原數據編碼后的值,如果從數組頭開始遍歷效率是相當低的,有沒有更好的辦法呢?
將前面一維數組轉為二維數組,每行數組按前面的編碼實現,數據中預留4個字節,每行占滿時尾部標記當前行結束累計包括多少個原始數據,下個編碼值則存入下一行,依次類推。
圖片如上圖,二維數組的一行就退化為一維數組,每行在固定位置標記存儲的數量。如果需要查找C10,先按標記數目的字節地址遍歷,則可以找到第2行(從0開始)為13,表示需要查找的數據在本行,只需要遍歷該行,從C9開始往后查詢。
5、總結
選擇合適的數據類型的減小存儲空間,對大范圍的數據使用變長的類型拼接存儲,犧牲了部分時間,但節約了ram或flash空間,對資源緊缺的嵌入式設備具有一定的價值。
本文轉載自微信公眾號「嵌入式系統」,可以通過以下二維碼關注。轉載本文請聯系嵌入式系統公眾號。

















