512張GPU煉出10萬億參數巨模型!這個模型今年雙十一已經用上了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
超大規模的預訓練模型的參數量級又雙叒被刷爆了!
100000億!
(沒錯,是10萬億)
而且還是用512張GPU,訓練了10天搞出來的!
這就是達摩院最新推出的超大規模通用性人工智能大模型,M6-10T。
它在電商、制造業、文學藝術、科學研究等領域都有著多模態、多任務的能力,在各自現實場景的下游任務中也頻頻出現。
而且還能做到即開即用,你今年的雙十一背后就有M6-10T的身影。
少量資源快速訓練大模型
不過剁手節的事可以先放一邊,問題關鍵是:M6-10T到底是怎么使用少量資源完成對極限規模模型的訓練的?
要知道,之前微軟的DeepSpeed MoE模型,也是使用了512張A100才完成了3.5萬億參數的訓練。
而自家在5個月前推出的萬億級參數的M6,則是用480塊GPU訓練的。
所以,512張GPU怎么就放下了10萬億參數?
這就要提到達摩院自研的分布式框架Whale。
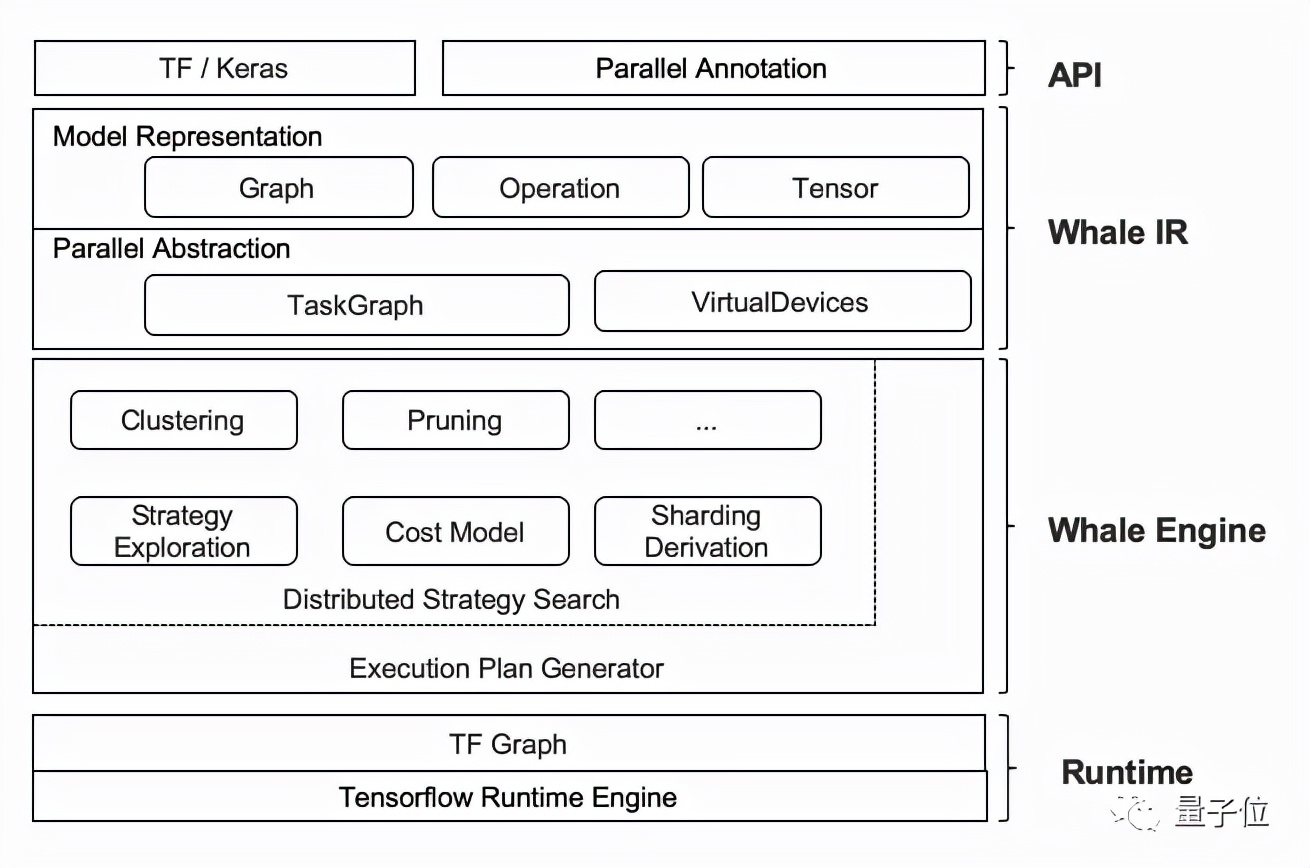
基于這一框架,M6模型可以使用粒度可控的CPU offload方法,靈活地選擇offload的模型層。
也就是說,可以不用將所有的權重offload到CPU memory中,而選擇保留部分權重在GPU memory上進行計算,以進一步地提高GPU利用率。
放下了參數,下一步就是提高訓練效率。
M6-10T模型采用了一種叫做共享解除(Pseudo-to-Real)的新的訓練策略:
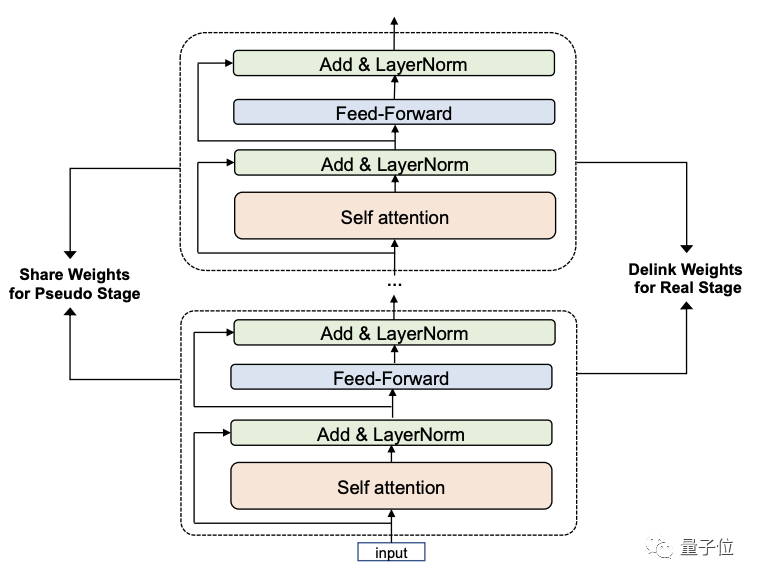
這一策略分為兩個階段。
第一階段,利用跨層參數共享機制快速構建并訓練小模型Pseudo Giant。
參數少得多的Pseudo Giant不受內存的限制,因此可以用大批量訓練來加速。
再配合上專家拆分和合并的機制,最終只需要使用256張GPU即可快速訓練一個Pseudo Giant。
第二階段則解除共享參數的聯系,得到新的Real Giant模型。
“共享”階段訓練好的模型層的參數會為Real Giant的每一層提供初始化,大模型即可在訓練好的小模型的基礎上繼續優化。
在下游評估中可以看到,從頭開始訓練Real Giant模型非常耗時,而Pseudo Giant訓練的收斂速度比Real Giant訓練有5倍左右的優勢:
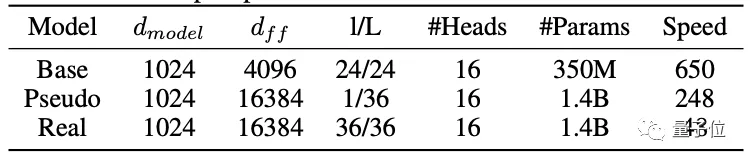
△在48個NVIDIA V100 GPU設備上訓練
這一機制不僅能夠使M6-10T在樣本量的維度上具有更快的收斂速度,也能將模型的訓練速度提升7倍以上。
而相對于之前的M6-MoE和M6-T,采用了新的訓練策略的M60-10T迷惑度(perplexity)更低,模型更優越:
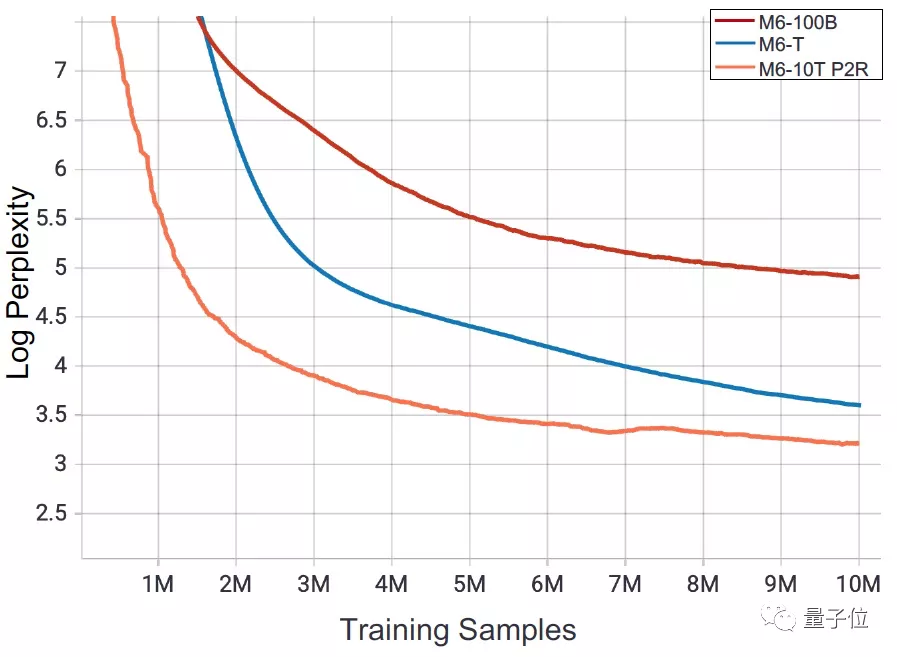
可以說,之前使用480GPU的萬億參數模型M6,如果采用現在的方法,那就只需要64張GPU就能完成訓練。
雙十一背后的模型
而除了算法層面的價值,M6-10T一經推出就能夠投入使用。
比如說即將來臨的雙十一中,你或許就能發現這些AI設計款的衣服上架。

△基于M6設計生成的服裝款式
這就是大模型帶來的創造力。
在結合了StyleGAN后,M6能夠在少樣本情況下自動生成圖像,且保持良好的細節質量和可編輯性。
而且與傳統的設計款式圖不同,M6生成的還是更接近實物的照片效果。
在手機淘寶和支付寶中,也會有基于M6智能生成的內容文案:

同時,大模型的多模態特征提取能力,也能進行商品屬性標簽補充,用于進行認知召回。
可以說,阿里巴巴內部超過40個業務團隊背后,都有著基于個版本的M6模型形成的服務化平臺的支撐。
而除了電商領域,還有金融、工業、傳統科學等諸多應用方向。
現在,M6服務化平臺以及成為了前業界覆蓋最廣泛的大模型生態的服務化平臺。
那么未來是繼續追求更大量級的模型,進行參數規模的迭代嗎?
阿里達摩院M6的科研團隊表示:
伴隨著參數規模的擴大,當前的預訓練模型在語言模型建模之類的任務上取得了不錯的進展,
但對知識的理解還比較淺薄。因此,如何將大模型有效遷移到多種類型的下游任務上,讓大模型真正地理解并運用知識,這將是研究人員會進一步探索的問題。
論文:
https://arxiv.org/abs/2110.03888