基于 Scrapy 框架的微博評論爬蟲實戰
文末本文轉載自微信公眾號「志斌的python筆記」,作者志斌。轉載本文請聯系志斌的python筆記公眾號。
大家好,我是志斌~
之前志斌寫過的微博爬蟲是基于Requests的,今天來跟大家分享一下,基于Scrapy的微博爬蟲應該怎么寫。
之前分享過一個Requests對微博評論的爬蟲,已經對頁面進行了全面的分析,本文主要注重對數據采集、存儲和文件配置進行分析講解。
一Scrapy簡介
首先,我們需要對Scrapy框架有一個簡單的了解,不然在你書寫代碼的時候會非常的麻煩。
01安裝
使用pip對Scrapy進行安裝,代碼如下:
- pip install scrapy
02創建項目
安裝好Scrapy框架之后,我們需要通過終端,來創建一個Scrapy項目,命令如下:
- scrapy startproject weibo
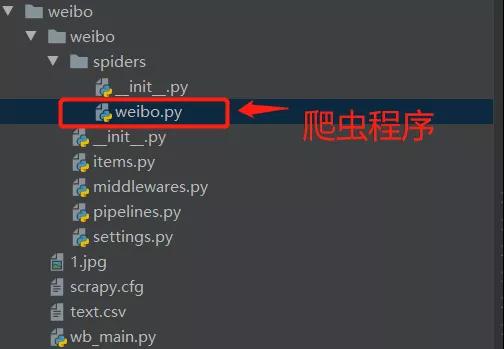
創建好后的項目結構,如下圖:
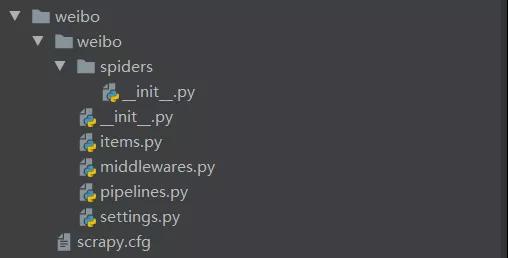
這里我們來簡單介紹一下結構中我們用到的部分的作用,有助于我們后面書寫代碼。
spiders是存放爬蟲程序的文件夾,將寫好的爬蟲程序放到該文件夾中。items用來定義數據,類似于字典的功能。settings是設置文件,包含爬蟲項目的設置信息。pipelines用來對items中的數據進行進一步處理,如:清洗、存儲等。
二數據采集
經過上面的簡單介紹,我們現在對Scrapy框架有了簡單的了解,下面我們開始寫數據采集部分的代碼。
01定義數據
首先,我們對數據存儲的網頁進行觀察,方便我們對獲取數據進行定義
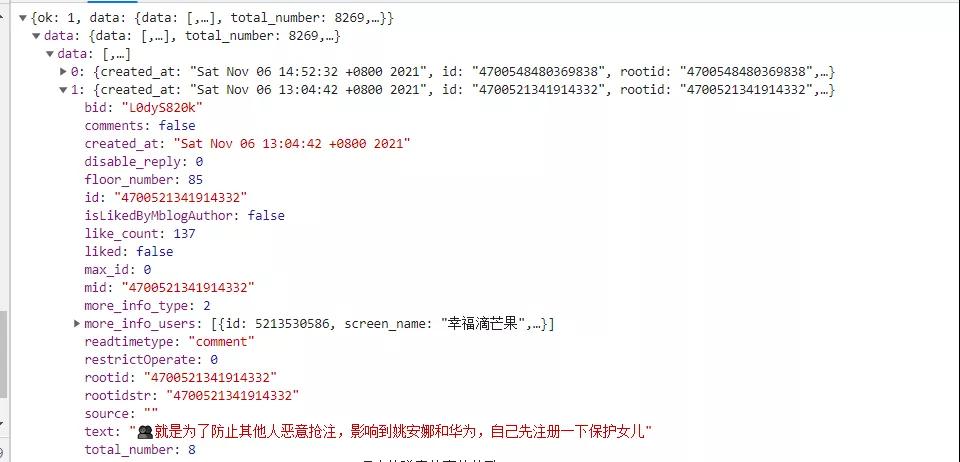
通過對網頁中數據存儲的形式進行觀察后,items.py中對數據的定義方式為:
- data = scrapy.Field()
02編輯爬蟲
接下來我們在spiders文件夾里面創建一個weibo.py爬蟲程序用以書寫請求的爬蟲代碼
代碼如下:
- import scrapy
- class WeiboSpider(scrapy.Spider):
- name = 'weibo' #用于啟動微博程序
- allowed_domains = ['m.weibo.cn'] #定義爬蟲爬取網站的域名
- start_urls = ['https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id_type=0'] #定義起始網頁的網址
- for i in res['data']['data']:
- weibo_item = WeiboItem()
- weibo_item['data'] = re.sub(r'<[^>]*>', '', i['text'])
- # start_url = ['https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&'+str(max_id)+'&max_id_type=0']
- yield weibo_item #將數據回傳給items
03遍歷爬取
學過Requests對微博評論進行爬蟲的朋友應該知道,微博評論的URL構造方式,這里我直接展示構造代碼:
- max_id_type = res['data']['max_id_type']
- if int(max_id_type) == 1:
- new_url = 'https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id=' + str(
- max_id) + '&max_id_type=1'
- else:
- new_url = 'https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id=' + str(
- max_id) + '&max_id_type=0'
三數據存儲
光爬取下來數據是不行的,我們還需要對數據進行存儲,這里我采用的是csv文件,來對評論數據進行存儲,代碼如下:
- class CsvItemExporterPipeline(object):
- def __init__(self):
- # 創建接收文件,初始化exporter屬性
- self.file = open('text.csv','ab')
- self.exporter = CsvItemExporter(self.file,fields_to_export=['data'])
- self.exporter.start_exporting()
四程序配置
光寫上面的代碼是無法爬取到評論的,因為我們還沒有對整個程序進行有效的配置,下面我們就在settings.py里面進行配置。
01不遵循robots協議
需要對robts協議的遵守進行修改,如果我們遵循網頁的robots協議的話,那無法進行爬取,代碼如下:
- # Obey robots.txt rules
- ROBOTSTXT_OBEY = False
02使用自定義cookie
我們知道,想要爬取微博評論,需要帶上自己的cookie用以信息校驗,因為我們的cookie是在headers中包裹著的,所以我們需要將COOKIES_ENABLED改為False,代碼如下:
- # Disable cookies (enabled by default)
- COOKIES_ENABLED = False
03打開管道
想要進行數據存儲,還需要在配置中,打開通道,用以數據傳輸,代碼如下:
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- 'weibo.pipelines.CsvItemExporterPipeline': 1,
- 'weibo.pipelines.WeiboPipeline': 300,
- }
五啟動程序
我們在spiders同級的的目錄下創建一個wb_main.py文件,便于我們在編輯器中啟動程序,代碼如下:
- from scrapy import cmdline
- #導入cmdline模塊,可以實現控制終端命令行。
- cmdline.execute(['scrapy','crawl','weibo'])
- #用execute()方法,輸入運行scrapy的命令。
六總結
1. 本文詳細的介紹了,如何用Scrapy框架來對微博評論進行爬取,建議大家動手實操一下,便于理解。
2. 本文僅供學習參考,不做它用。