人人都會數據采集- Scrapy 爬蟲框架入門
在這個言必稱“大數據”“人工智能”的時代,數據分析與挖掘逐漸成為互聯網從業者必備的技能。本文介紹了利用輕量級爬蟲框架 scrapy 來進行數據采集的基本方法。
一、scrapy簡介
scrapy 是一套用 Python 編寫的異步爬蟲框架,基于 Twisted 實現,運行于 Linux/Windows/MacOS 等多種環境,具有速度快、擴展性強、使用簡便等特點。即便是新手也能迅速掌握并編寫出所需要的爬蟲程序。scrapy 可以在本地運行,也能部署到云端(scrapyd)實現真正的生產級數據采集系統。
我們通過一個實例來學習如何利用 scrapy 從網絡上采集數據。“博客園”是一個技術類的綜合資訊網站,本次我們的任務是采集該網站 MySQL 類別
https://www.cnblogs.com/cate/mysql/ 下所有文章的標題、摘要、發布日期、閱讀數量,共4個字段。最終的成果是一個包含了所有4個字段的文本文件。如圖所示:

最終拿到的數據如下所示,每條記錄有四行,分別是標題、閱讀數量、發布時間、文章摘要:

二、安裝scrapy
下面來看看怎么安裝 scrapy。首先你的系統里必須得有 Python 和 pip,本文以最常見的 Python2.7.5 版本為例。pip 是 Python 的包管理工具,一般來說 Linux 系統中都會默認安裝。在命令行下輸入如下命令并執行:
- sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip 會從豆瓣網的軟件源下載并安裝 scrapy,所有依賴的包都會被自動下載安裝。”sudo”的意思是以超級用戶的權限執行這條命令。所有的進度條都走完之后,如果提示類似”Successfully installed Twisted, scrapy … “,則說明安裝成功。
三、scrapy交互環境
scrapy 同時也提供了一個可交互運行的 Shell,能夠供我們方便地測試解析規則。scrapy 安裝成功之后,在命令行輸入 scrapy shell 即可啟動 scrapy 的交互環境。scrapy shell 的提示符是三個大于號>>>,表示可以接收命令了。我們先用 fetch() 方法來獲取首頁內容:
- >>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕上有如下輸出,則說明網頁內容已經獲取到了。
- 2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
- 2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
- <GET https://www.cnblogs.com/cate/mysql/> (referer: None)
獲取到的響應會保存在 response 對象中。該對象的 status 屬性表示 HTTP 響應狀態,正常情況為 200。
- >>> print response.status
- 200
text 屬性表示返回的內容數據,從這些數據中可以解析出需要的內容。
- >>> print response.text
- u'<!DOCTYPE html>\r\n<html lang=”zh-cn”>\r\n<head>\r\n
- <meta charset=”utf-8″ />\r\n
- <meta name=”viewport” content=”width=device-width, initial-scale=1″ />\r\n
- <meta name=”referrer” content=”always” />\r\n
- <title>MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed</title>\r\n
- <link rel=”shortcut icon” href=”//common.cnblogs.com/favicon.ico” type=”image/x-icon” />’
可以看到是一堆很亂的 HTML 代碼,沒法直觀地找到我們需要的數據。這個時候我們可以通過瀏覽器的“開發者工具”來獲取指定數據的 DOM 路徑。用瀏覽器打開網頁 https://www.cnblogs.com/cate/mysql/ 之后,按下 F12 鍵即可啟動開發者工具,并迅速定位指定的內容。
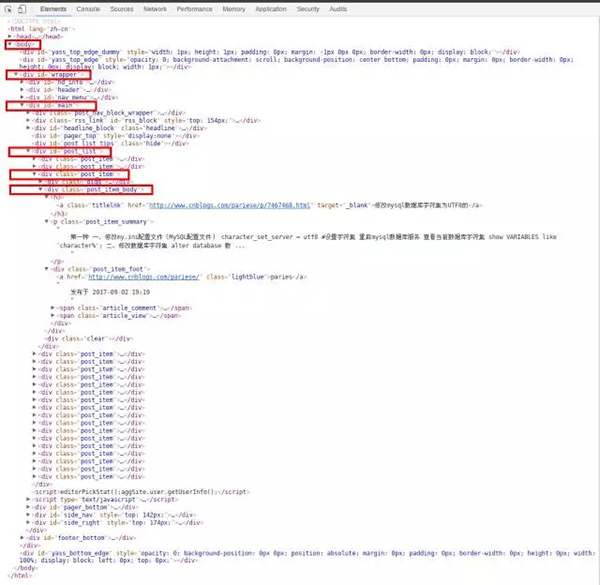
可以看到我們需要的4個字段都在 / body / div(id=”wrapper”) / div(id=”main”) / div(id=”post_list”) / div(class=”post_item”) / div(class=”post_item_body”) / 下,每一個”post_item_body”都包含一篇文章的標題、摘要、發布日期、閱讀數量。我們先獲取所有的”post_item_body”,然后再從里面分別解析出每篇文章的4個字段。
- >>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
- >>> len( post_item_body )
- 20
response 的 xpath 方法能夠利用 xpath 解析器獲取 DOM 數據,xpath 的語法請參考官網文檔。可以看到我們拿到了首頁所有 20 篇文章的 post_item_body。那么如何將每篇文章的這4個字段提取出來呢?
我們以***篇文章為例。先取***個 post_item_body:
- >>> first_article = post_item_body[ 0 ]
標題在 post_item_body 節點下的 h3 / a 中,xpath 方法中text()的作用是取當前節點的文字,extract_first() 和 strip() 則是將 xpath 表達式中的節點提取出來并過濾掉前后的空格和回車符:
- >>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
- >>> print article_title
- Mysql之表的操作與索引操作
然后用類似的方式提取出文章摘要:
- >>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
- >>> print article_summary
- 表的操作: 1.表的創建: create table if not exists table_name(字段定義); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
在提取 post_item_foot 的時候,發現提取出了兩組內容,***組是空內容,第二組才是“發布于 XXX”的文字。我們將第二組內容提取出來,并過濾掉“發布于”三個字:
- >>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “發布于” )[ 1 ].strip()
- >>> print post_date
- 2017-09-03 18:13
***將閱讀數量提取出來:
- >>> article_view = first_article.xpath( “div[@class=’post_item_foot’]/span[@class=’article_view’]/a/text()” ).extract_first()
- >>> print article_view
- 閱讀(6)
很多人覺得 xpath 方法里的規則太過復雜。其實只要了解一點 HTML 文件的 DOM 結構,掌握 xpath 的提取規則還是比較輕松容易的。好在 scrapy shell 允許我們反復對 DOM 文件進行嘗試解析。實驗成功的 xpath 表達式就可以直接用在項目里了。
四、創建scrapy項目
scrapy shell 僅僅適用于測試目標網站是否可以正常采集以及采集之后如何解析,真正做項目的時候還需要從頭建立一個 scrapy 項目。 輸入以下命令退出 scrapy shell 并返回 Linux 命令行:
- >>> exit()
假設我們的項目名稱叫 cnblogs_scrapy ,則可通過下面的命令來創建一個 scrapy 項目:
- scrapy startproject cnblogs_scrapy
會自動生成如下結構的目錄與文件:
- |– cnblogs_scrapy
- | |– __init__.py
- | |– items.py
- | |– middlewares.py
- | |– pipelines.py
- | |– settings.py
- | `– spiders
- | `– __init__.py
- `– scrapy.cfg
五、解析與存儲
我們需要改三個地方:
1. 在spiders目錄下建一個文件cnblogs_mysql.py
內容如下:
- # -*- coding: utf-8 -*-
- import scrapy
- import sys
- reload( sys )
- sys.setdefaultencoding( "utf8" )
- class CnblogsMySQL(scrapy.Spider):
- # 爬蟲的名字,必須有這個變量
- name = 'cnblogs_mysql'
- page_index = 1
- # 初始地址,必須有這個變量
- start_urls = [
- 'https://www.cnblogs.com/cate/mysql/' + str( page_index ),
- ]
- def parse(self, response):
- post_items = response.xpath(
- "//div[@id='wrapper']/div[@id='main']/div[@id='post_list']/div[@class='post_item']/div[@class='post_item_body']"
- )
- for post_item_body in post_items:
- yield {
- 'article_title':
- post_item_body.xpath( "h3/a/text()" ).extract_first().strip(),
- 'article_summary':
- post_item_body.xpath( "p[@class='post_item_summary']/text()" ).extract_first().strip(),
- 'post_date':
- post_item_body.xpath( "div[@class='post_item_foot']/text()" ).extract()[ 1 ].strip(),
- 'article_view' :
- post_item_body.xpath(
- "div[@class='post_item_foot']/span[@class='article_view']/a/text()"
- ).extract_first().strip()
- }
- next_page_url = None
- self.page_index += 1
- if self.page_index <= 20:
- next_page_url = "https://www.cnblogs.com/cate/mysql/" + str( self.page_index )
- else:
- next_page_url = None
- if next_page_url is not None:
- yield scrapy.Request(response.urljoin(next_page_url))
這個就是我們的爬蟲,其中 name 和 start_urls 兩個變量必須存在。parse 方法的作用是將響應內容解析為我們需要的數據。parse 中的 for 循環就是在提取每一頁中的 20 篇文章。解析并提取完成后,通過 yield 將結果拋到 pipeline 進行存儲。
2. 修改pipelines.py文件,內容如下:
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
- class CnblogsScrapyPipeline(object):
- def open_spider( self, spider ):
- self.fp = open( "data.list", "w" )
- def close_spider( self, spider ):
- self.fp.close()
- def process_item(self, item, spider):
- self.fp.write( item[ "article_title" ] + "\n" )
- self.fp.write( item[ "article_view" ] + "\n" )
- self.fp.write( item[ "post_date" ] + "\n" )
- self.fp.write( item[ "article_summary" ] + "\n\n" )
- return item
可以看到有三個方法。這三個方法是從基類中繼承而來。open_spider/close_spider 分別在爬蟲啟動和結束的時候執行,一般用作初始化及收尾。process_item 會在每一次 spider 解析出數據后 yield 的時候執行,用來處理解析的結果。上面這個 pipeline 的作用是將每一條記錄都存儲到文件中。當然也可以通過 pipeline 將內容存儲到數據庫或其它地方。
3. 配置pipeline
注意僅僅有這個 pipeline 文件還不能工作,需要在配置文件中向 scrapy 聲明 pipeline。同目錄下有個 settings.py 文件,加入如下內容:
- ITEM_PIPELINES = {
- 'cnblogs_scrapy.pipelines.CnblogsScrapyPipeline': 300,
- }
后面的數字是 pipeline 的權重,如果一個爬蟲有多個 pipeline,各個 pipeline 的執行順序由這個權重來決定。
修改完成并保存之后,退到 cnblogs_scrapy 的上層目錄,并輸入以下命令啟動爬蟲:
- scrapy crawl cnblogs_mysql
所有經過處理的信息都會輸出到屏幕上。結束之后,當前目錄中會生成名為 data.list 的文件,里面存儲了本次采集的所有數據。
六、翻頁
cnblogs_mysql.py 的 parse 方法中有個 next_page_url 變量,一般情況下這個變量的內容應當是當前頁面的下一頁 URL,該 URL 當然也可以通過解析頁面來獲取。獲得下一頁的URL之后,用 scrapy.Request 來發起新一次的請求。 簡單起見本文通過直接拼接 URL 的形式來指定僅采集前 20 頁的數據。
七、其它
用 scrapy 發請求之前,也可以自己構造 Request,這樣就能偽裝為真實訪問來避免被封。一般情況下有修改 User-Agent、隨機采集時間、隨機代理 IP 等方法。 scrapy 項目可以直接運行,也可以部署在云端進行批量采集和監控。云端部署需要用到 scrapyd,操作起來也很簡單,有需要的話可自行參考官網文檔。
【本文是51CTO專欄機構“豈安科技”的原創文章,轉載請通過微信公眾號(bigsec)聯系原作者】