













都2021年了,還把x86和ARM歸為CISC和RISC?
CISC 和 RISC 是 David Patterson 和 David Ditzel 在 1981 年正式提出的。四十年過去了,二者的發(fā)展有哪些融合與變遷?IT 新聞界資深人士 Joel Hruska 撰長(zhǎng)文對(duì)該領(lǐng)域的發(fā)展史及其將面臨的挑戰(zhàn)做了詳細(xì)闡述,以下是文章原文。
隨著基于 ARM 的 M1 被推出,關(guān)于 x86 和 ARM 的比較和討論也越來越多。這些討論通常還涉及 CISC 和 RISC,因?yàn)椤竫86 與 ARM」和「CISC 與 RISC」之間的非常緊密。
但這種關(guān)聯(lián)造成了一種誤解:「x86 與 ARM 可以被對(duì)應(yīng)歸類為 CISC 與 RISC,其中 x86 是 CISC,ARM 是 RISC」,三十年前的確是這樣,但現(xiàn)在已經(jīng)不是了。
人們經(jīng)常將 x86 CPU 與其他公司制造的處理器進(jìn)行比較,但近二十年來 x86 都沒有一個(gè)真正的架構(gòu)競(jìng)爭(zhēng)對(duì)手。
發(fā)展歷程
RISC 是 David Patterson 和 David Ditzel 在他們 1981 年的開創(chuàng)性論文《The Case for a Reduced Instruction Set Computer》中創(chuàng)造的術(shù)語。他們根據(jù) 20 世紀(jì) 70 年代后期領(lǐng)域內(nèi)的發(fā)展趨勢(shì)以及當(dāng)時(shí) CPU 面臨的擴(kuò)展問題,正式提出了 RISC 這種半導(dǎo)體設(shè)計(jì)方法。此外,他們還提出了另一個(gè)術(shù)語「CISC(復(fù)雜指令集)」,來描述許多已經(jīng)存在但不遵循 RISC 原則的 CPU 架構(gòu)。
隨著限制 CPU 性能的瓶頸發(fā)生改變,人們意識(shí)到需要一種新的 CPU 設(shè)計(jì)方法。原始 8086 就是遵循 CISC 設(shè)計(jì)原則的一個(gè)例子,它旨在通過將復(fù)雜性轉(zhuǎn)移到硬件中,來緩解內(nèi)存成本高的問題。這種方法強(qiáng)調(diào)代碼密度和對(duì)一個(gè)變量依次執(zhí)行多個(gè)操作的某些指令。作為一種設(shè)計(jì)理念,CISC 試圖最小化 CPU 執(zhí)行給定任務(wù)所必需的指令數(shù)來提高性能,其指令集架構(gòu)通常會(huì)提供一些專用指令。
20 世紀(jì) 70 年代后期,CISC CPU 存在很多缺點(diǎn)。它們通常必須跨多個(gè)芯片才能實(shí)現(xiàn),因?yàn)楫?dāng)時(shí)的超大規(guī)模集成電路(VLSI)技術(shù)無法將所有必要的組件封裝到一起。實(shí)現(xiàn)支持大量極少用指令的復(fù)雜指令集架構(gòu)需要消耗 die space,并且可實(shí)現(xiàn)的最大時(shí)鐘速度也有限。與此同時(shí),內(nèi)存成本持續(xù)降低,代碼尺寸變得不那么重要了。
Patterson 和 Ditzel 認(rèn)為當(dāng)時(shí) CISC CPU 仍在嘗試解決代碼膨脹問題,他們意識(shí)到絕大多數(shù) CISC 指令都沒有被用到。因此他們提出了一種完全不同的處理器設(shè)計(jì)方法——一個(gè)小得多的指令集 RISC,其中的指令長(zhǎng)度固定,并且所有指令都能在單個(gè)時(shí)鐘周期內(nèi)完成。盡管 RISC CPU 每條指令執(zhí)行的工作量比 CISC 的對(duì)應(yīng)指令少了一些,但芯片設(shè)計(jì)人員通過簡(jiǎn)化處理器來彌補(bǔ)了這一點(diǎn)。
這種簡(jiǎn)化允許把晶體管的預(yù)算用來實(shí)現(xiàn)其他功能,例如用于一些額外的寄存器。1981 年人們?cè)O(shè)想未來可用的功能包括片上緩存、更大更快的晶體管,甚至是 pipelining 技術(shù)。RISC CPU 的目標(biāo)是盡可能加快指令執(zhí)行速度,提高 IPC(即每個(gè)時(shí)鐘周期內(nèi)執(zhí)行的指令數(shù),用于度量 CPU 的效率)。Patterson 和 Ditzel 認(rèn)為,通過以這種方式重新分配資源,RISC 的性能最終將優(yōu)于 CISC。
不久這種猜想就被證實(shí)。MIPS 于 1985 年推出的 R2000 在某些情況下能夠維持接近 1 的 IPC。早期的 RISC CPU,例如 SPARC 和 HP 的 PA-RISC 系列,都創(chuàng)造了性能記錄。在 20 世紀(jì) 80 年代末和 90 年代初,人們常說:「x86 等基于 CISC 的架構(gòu)已經(jīng)過時(shí)了,也許對(duì)于家庭計(jì)算來說足夠了,但如果您想使用真正的 CPU,請(qǐng)購買 RISC 芯片」。以數(shù)據(jù)中心、工作站和高性能計(jì)算 (HPC) 為例:
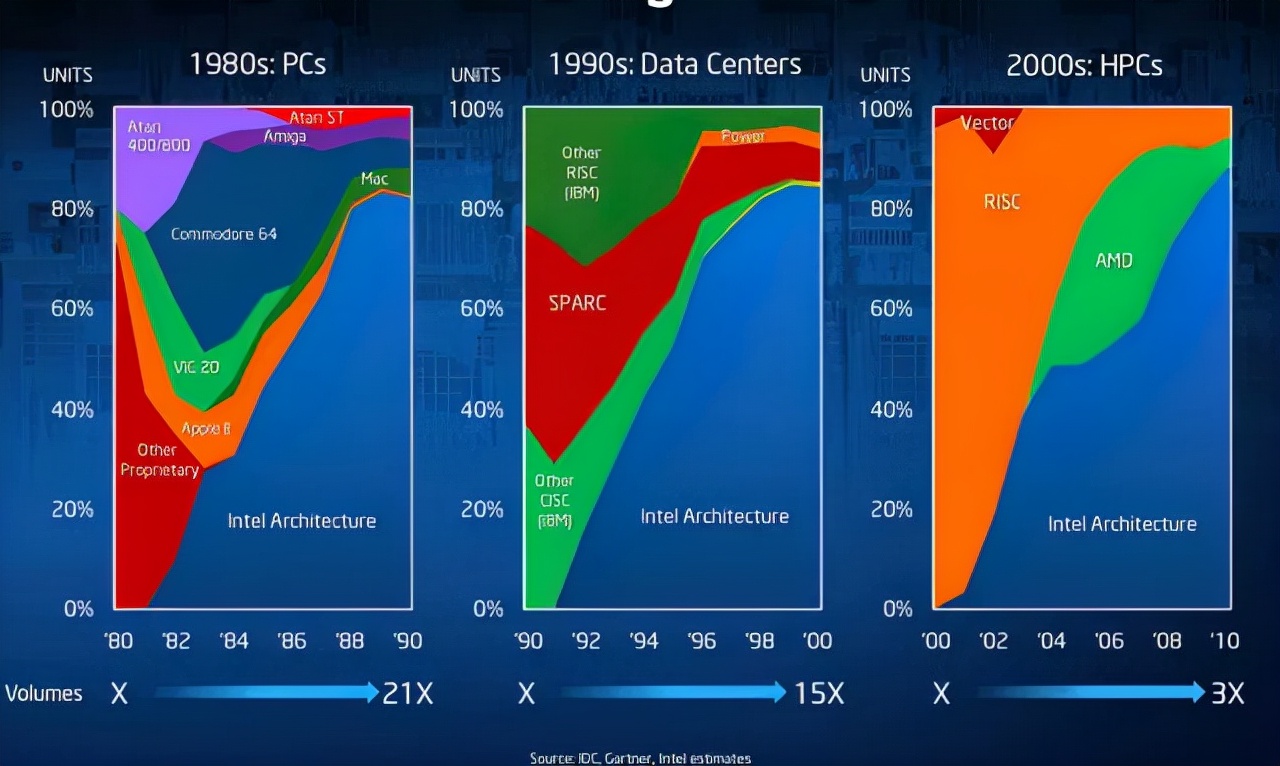
注:此處「英特爾架構(gòu)」僅指 x86 CPU,而不是 8080 等芯片,后者在早期的計(jì)算機(jī)市場(chǎng)上很受歡迎。此外,英特爾在 2000 年擁有許多屬于「RISC」類的超級(jí)計(jì)算機(jī),并且 x86 機(jī)器在市場(chǎng)上還占據(jù)較大的份額。
上圖分析了 80 年代 - 00 年代 CPU 的市場(chǎng)狀況。截止到 1990 年,在個(gè)人計(jì)算機(jī)市場(chǎng),x86 占據(jù)了相當(dāng)大的市場(chǎng)份額,非 x86 CPU 僅占約 20%;但在數(shù)據(jù)中心方面,x86 幾乎沒有份額,在 HPC 中也沒有。當(dāng)時(shí)蘋果正準(zhǔn)備設(shè)計(jì)下一代 CPU,1991 年蘋果、IBM、Motorola 組成的 AIM 聯(lián)盟推出了微處理器架構(gòu) PowerPC,他們相信按照 RISC 原則構(gòu)建的高性能 CPU 將是計(jì)算機(jī)的未來。
CISC 與 RISC 并肩發(fā)展的歷史至 20 世紀(jì) 90 年代初為止。英特爾的 x86 架構(gòu)在 PC、數(shù)據(jù)中心和 HPC 等計(jì)算行業(yè)繼續(xù)占據(jù)主導(dǎo)地位的事實(shí)是無可爭(zhēng)議的,有爭(zhēng)議的是:英特爾和 AMD 的 CPU 架構(gòu)是否真的是采用 RISC 設(shè)計(jì)原則實(shí)現(xiàn)的
觀點(diǎn)分歧
在 CPU 開發(fā)領(lǐng)域,一些概念和屬性是長(zhǎng)期存在分歧的。例如 Paul DeMone 曾在《RISC vs. CISC Still Matters》一文中寫道:
隨著使用固定長(zhǎng)度控制字來操縱亂序執(zhí)行數(shù)據(jù)路徑的現(xiàn)代 x86 處理器的出現(xiàn),RISC 和 CISC 之間的混淆變得越來越嚴(yán)重。「RISC 和 CISC 正在融合」是一個(gè)在根本上就存在缺陷的觀點(diǎn),可以追溯到 1992 年 i486 的發(fā)布。其根源在于人們對(duì)指令集架構(gòu)和物理處理器實(shí)現(xiàn)細(xì)節(jié)之間的差異普遍無知。
相比之下,Jon Stokes 在《RISC vs. CISC: the Post-RISC Era》中說:
顯然到目前為止,「RISC」和「CISC」這兩種縮寫術(shù)語掩蓋了一個(gè)事實(shí),即兩種設(shè)計(jì)理念都不僅僅處理指令集的簡(jiǎn)單性或復(fù)雜性...... 從 RISC 和 CISC 的發(fā)展史以及兩種方法試圖解決的問題看,這兩個(gè)術(shù)語都很荒謬…… 關(guān)于「RISC 與 CISC」的辯論早已結(jié)束,現(xiàn)在必須要進(jìn)行一個(gè)更細(xì)致入微、更有趣的討論,即基于硬件和軟件、ISA 和實(shí)現(xiàn)等方面進(jìn)行討論。
然而,這些文章都過時(shí)了。Stokes 的文章寫于 1999 年,DeMone 的文章寫于 2000 年。這里引用他們的文章是為了說明 RISC 與 CISC 和現(xiàn)代計(jì)算的關(guān)聯(lián)早已有 20 多年的歷史。
關(guān)于實(shí)現(xiàn)與 ISA的兩種觀點(diǎn)
上文提到的引述反映了關(guān)于「CISC 與 RISC」的兩種不同觀點(diǎn)。DeMone 的觀點(diǎn)與今天 ARM 和蘋果的觀點(diǎn)基本一致,這種觀點(diǎn)被稱為「以 ISA 為中心(ISA-centric position)」。
在過去幾十年里,Stokes 的觀點(diǎn)是 PC 領(lǐng)域的主流觀點(diǎn),被稱為「以實(shí)現(xiàn)為中心(implementation-centric position)」。我使用「實(shí)現(xiàn)(implementation)」這個(gè)詞是因?yàn)樗梢栽谏舷挛闹兄复?CPU 的微架構(gòu)或用于制造物理芯片的制程節(jié)點(diǎn)。
上述兩種位置都以「中心(centric)」的形式描述,兩種觀點(diǎn)之間是存在交集的。即使觀點(diǎn)不一,但都遵循一些共同的趨勢(shì)。
在以 ISA 為中心的觀點(diǎn)中,RISC 指令集的某些先天特征使其比 x86 更高效,包括使用固定長(zhǎng)度指令和加載 / 存儲(chǔ)設(shè)計(jì)。雖然 CISC 和 RISC 之間的一些原始差異不再有意義,但以 ISA 為中心的觀點(diǎn)認(rèn)為,就 x86 和 ARM 之間的性能和能效而言,仍然具有一些關(guān)鍵差異。
以 ISA 為中心的觀點(diǎn)認(rèn)為,英特爾、AMD 和 x86 勝過 MIPS、SPARC 和 POWER/PowerPC,原因有以下三個(gè):英特爾卓越的工藝制造、英特爾的優(yōu)勢(shì)使所謂的「CISC tax」逐漸減少、二進(jìn)制兼容性提升了 x86 的價(jià)值。
以實(shí)現(xiàn)為中心的觀點(diǎn)則著眼于自 RISC、CISC 等術(shù)語出現(xiàn)以來現(xiàn)代 CPU 的發(fā)展方式,并認(rèn)為這兩種術(shù)語已完全過時(shí)。
例如,現(xiàn)在 x86 和高端 ARM CPU 都使用亂序執(zhí)行來提高 CPU 的性能。而使用芯片即時(shí)重排序指令以提高執(zhí)行效率的做法與 RISC 的原始設(shè)計(jì)理念完全不一致,Patterson 和 Ditzel 主張采用能夠以更高時(shí)鐘速度運(yùn)行的不太復(fù)雜的 CPU。現(xiàn)代 ARM CPU 還有一些特性,例如 SIMD 執(zhí)行單元和分支預(yù)測(cè),在 1981 年也都不存在。RISC 最初的目標(biāo)是讓所有指令都能在一個(gè)周期內(nèi)執(zhí)行,大多數(shù) ARM 指令都符合這個(gè)規(guī)則,但是 ARMv8 ISA 和 ARMv9 ISA 包含執(zhí)行時(shí)間超過一個(gè)時(shí)鐘周期的指令。現(xiàn)代 x86 CPU 也是如此。
以實(shí)現(xiàn)為中心的觀點(diǎn)認(rèn)為:制程節(jié)點(diǎn)改進(jìn)和微架構(gòu)增強(qiáng)的結(jié)合使 x86 在很久以前就可以縮小與 RISC CPU 的差距,并且 ISA 級(jí)別的差異在非常低的功率范圍內(nèi)無關(guān)緊要。英特爾和 AMD 等都普遍支持這種觀點(diǎn),2014 年我曾撰寫一篇題為《The final ISA showdown: Is ARM, x86, or MIPS intrinsically more power efficient?》的相關(guān)文章。
2014 年文章鏈接:https://www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient
但這種觀點(diǎn)是完全正確的嗎?
RISC 和 CISC 的開發(fā)融合了嗎?
以實(shí)現(xiàn)為中心的觀點(diǎn)認(rèn)為,CISC 和 RISC CPU 已經(jīng)交互發(fā)展了幾十年,從 1990 年代中期為 x86 CPU 采用「類 RISC」解碼方法開始。
常見的解釋是這樣的:在 1990 年代初期,英特爾和其他 x86 CPU 制造商意識(shí)到未來提高 CPU 性能需要的不僅僅是更大的緩存和更快的時(shí)鐘。多家公司決定投資 x86 CPU 微架構(gòu),以動(dòng)態(tài)重排序他們自己的指令流來提高性能。在該過程中,原生 x86 指令被送入 x86 解碼器,并在執(zhí)行前轉(zhuǎn)換為「類 RISC」微操作。
二十多年來業(yè)界的觀點(diǎn)一直是如此,但最近這種觀點(diǎn)遭到了挑戰(zhàn)。2020 年 Erik Engheim 寫道:「x86 芯片中根本沒有 RISC 的內(nèi)部結(jié)構(gòu),這只是一種營(yíng)銷策略。」他還提到了 DeMone 的故事和 P6 微架構(gòu)背后的首席架構(gòu)師 Bob Colwell 的一句話。
P6 微架構(gòu)是第一個(gè)實(shí)現(xiàn)亂序執(zhí)行和原生 x86 到微操作解碼引擎的英特爾微架構(gòu)。P6 隨奔騰 Pro 發(fā)布,后來又演變出奔騰 II、奔騰 3 及更高版本。它是現(xiàn)代 x86 CPU 的鼻祖。因此,P6 微架構(gòu)的首席架構(gòu)師 Bob Colwell 有資格解釋上文所述的挑戰(zhàn),他說:
英特爾的 x86 在「引擎的外表」下并沒有 RISC 引擎。它們通過依賴于將 x86 指令映射到機(jī)器操作或復(fù)雜指令的機(jī)器操作序列的解碼 / 執(zhí)行的方案來實(shí)現(xiàn) x86 指令集架構(gòu),然后這些操作通過微架構(gòu)找到自己的方式,遵守有關(guān)數(shù)據(jù)依賴的各種規(guī)則,最終確定時(shí)序。
完成這個(gè)過程的「微操作」有 100 多比特,攜帶各種復(fù)雜特異的信息,不能由編譯器直接生成,且不一定是單周期。但最重要的是,它們只是一種微架構(gòu)技巧,而 RISC/CISC 是關(guān)于指令集架構(gòu)的。微操作的想法不是受 RISC 啟發(fā)的、「類 RISC」的,或者說與 RISC 完全無關(guān)。而是我們的設(shè)計(jì)團(tuán)隊(duì)找到了一種方法,打破了非常復(fù)雜的指令集的復(fù)雜性,也擺脫了競(jìng)爭(zhēng)型微處理器中存在的限制。
英特爾并不是首個(gè)將 x86 前端解碼器與所謂的 RISC 風(fēng)格后端結(jié)合起來的 x86 CPU 制造商,被 AMD 收購的 NexGen 同樣如此。NexGen 5×86 CPU 于 1994 年 3 月首次亮相,而奔騰 Pro 直到 1995 年 11 月才推出。以下是 NexGen 對(duì)其 CPU 的描述:Nx586 處理器是 NexGen 創(chuàng)新以及 RISC86 微架構(gòu)專利的首次實(shí)現(xiàn)。后來該公司給出了更多實(shí)現(xiàn)細(xì)節(jié):RISC86 方法動(dòng)態(tài)地將 x86 指令轉(zhuǎn)化為 RISC86 指令。如下圖所示,Nx586 利用了 RISC 性能原理的優(yōu)勢(shì)。出于 RISC86 環(huán)境的限制,每個(gè)執(zhí)行單元都要更小更緊湊。
也許人們依然覺得這只是市場(chǎng)營(yíng)銷的說辭,那么讓我們?cè)賮砜聪?1996 年的 AMD K5。K5 通常被描述為與 AMD 從其 32 位 RISC 微控制器 Am29000 借來的執(zhí)行后端結(jié)和的 x86 前端。在查看它的具體框架圖之前,我們首先把它與最初的英特爾奔騰比較一下。奔騰可以說是 CISC x86 進(jìn)化的頂峰,因?yàn)樗?x86 CPU 中同時(shí)實(shí)現(xiàn)了 pipeline 和超標(biāo)量設(shè)計(jì)(superscaling),但沒有將 x86 指令轉(zhuǎn)換為微操作,也缺乏亂序執(zhí)行引擎。
AMD K5 框架圖如下圖所示:
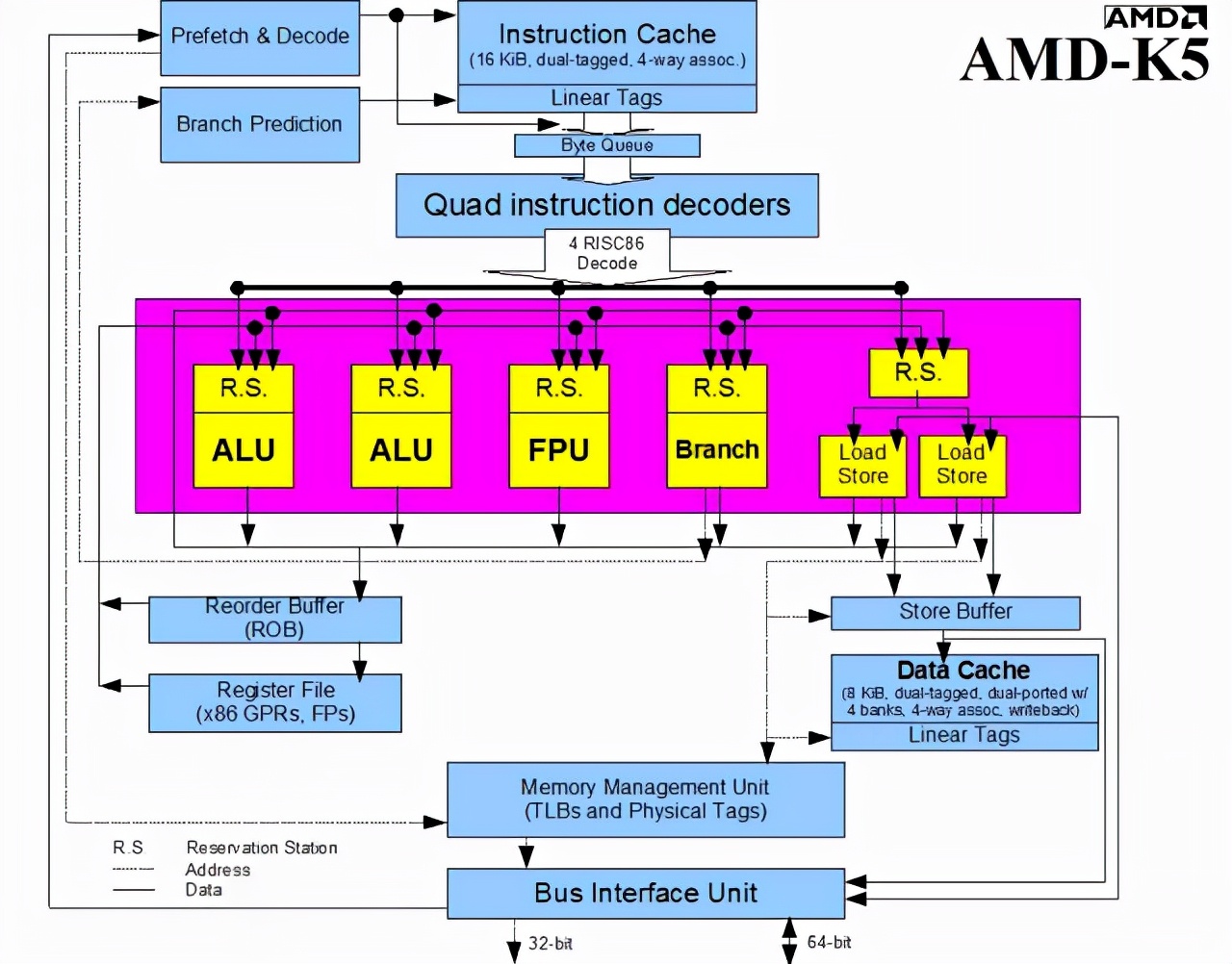
如果你曾經(jīng)研究過微處理器原理圖,你可能會(huì)發(fā)現(xiàn) K5 和微處理器有許多相似之處,但奔騰卻相反。AMD 在 Nx586 上市后收購了 NexGen。K5 是 AMD 自主設(shè)計(jì)的,而 K6 最初是 NexGen 的產(chǎn)品。也是從那時(shí)開始,CPU 變得像今天我們熟悉的樣子。設(shè)計(jì)這些芯片的工程師曾表示:這些相似之處不僅僅是表面上的。
早在 1996 年,AMD 的 David Christie 就在 IEEE Micro 上發(fā)表了一篇關(guān)于 K5 的文章,闡述了 K5 是如何將 RISC 和 CISC 結(jié)合在一起的,這里引用一段該文章的內(nèi)容:
我們開發(fā)了一個(gè)松散地基于 29000 指令集的微型 ISA。一些額外的控制字段將微指令的大小擴(kuò)展到 59 位。其中一些簡(jiǎn)化并加速了超標(biāo)量控制邏輯,其他的用于提供特定于 x86 的功能,這些功能對(duì)于性能非常重要,因此不能用微指令序列來合成。但是這些微指令仍然遵循基本的 RISC 原則:簡(jiǎn)單的寄存器到寄存器操作,對(duì)寄存器指定符和其他字段進(jìn)行固定位置編碼,并且每個(gè)操作不多于一個(gè)內(nèi)存引用。因此我們稱它們?yōu)?RISC 操作,或簡(jiǎn)稱為 ROPs。這種簡(jiǎn)單、通用的特性為實(shí)現(xiàn)更復(fù)雜的 x86 操作提供了靈活性,從而有利于保持執(zhí)行邏輯相對(duì)簡(jiǎn)單。
RISC 微架構(gòu)最關(guān)鍵的一點(diǎn)是 x86 指令集的復(fù)雜性止于解碼器,并且在很大程度上對(duì)亂序執(zhí)行內(nèi)核是透明的。這種方法只需要很少的額外控制復(fù)雜度,而不需要亂序的 RISC 執(zhí)行來實(shí)現(xiàn)亂序的 x86 執(zhí)行。任務(wù)切換的 ROP 序列看起來并不比簡(jiǎn)單指令串的 ROP 序列復(fù)雜。執(zhí)行內(nèi)核的復(fù)雜性被有效地從架構(gòu)的復(fù)雜性中分離出來,而不是復(fù)合起來的。
Christie 并沒有混淆 ISA 與 CPU 物理實(shí)現(xiàn)細(xì)節(jié)之間的區(qū)別。他認(rèn)為物理實(shí)現(xiàn)本身在一些重要的方面是 RISC 式的。K5 重用了 AMD 為其 Am29000 系列 RISC CPU 開發(fā)的執(zhí)行后端部分,它實(shí)現(xiàn)了一個(gè)比原生 x86 ISA 更類似于 RISC 的內(nèi)部指令集。在此期間,NexGen 和 AMD 引用的 RISC 式技術(shù)參考了數(shù)據(jù)緩存、pipeline 和超標(biāo)量架構(gòu)等參考概念。
這些想法都不是嚴(yán)格的 RISC,但它們都是首先在 RISC CPU 中首次亮相的,將這些功能作為「類 RISC」進(jìn)行營(yíng)銷是有道理的。
這些功能與 RISC 的相關(guān)程度以及 x86 CPU 是否解碼 RISC 樣式指令,取決于選擇的框架標(biāo)準(zhǔn)。這一爭(zhēng)論比奔騰 Pro 還大,即使 P6 是與亂序執(zhí)行引擎等技術(shù)發(fā)展最相關(guān)的微架構(gòu)。不同公司的工程師都有自己的看法。
現(xiàn)代 x86 CPU 的壓力
那么這種「RISC 與 CISC」比較對(duì)今天的 ARM 和 x86 CPU 有什么實(shí)際影響呢?當(dāng)我們將 AMD 和英特爾 CPU 與蘋果的 M1 和未來的 M2 進(jìn)行比較時(shí),我們真正要問的問題是:x86 是否存在一些瓶頸,使得其無法與蘋果以及高通等公司未來的 ARM 芯片有效競(jìng)爭(zhēng)?
AMD 和英特爾給出的答案是否定的,而 ARM 給出的答案是肯定的。行業(yè)內(nèi)的公司之間具有明顯的利益沖突,因此我詢問了丹麥計(jì)算機(jī)科學(xué)家 Agner Fog,他以其在 x86 架構(gòu)和微架構(gòu)方面的研究而聞名。以下是他的看法
ISA 并非無關(guān)緊要。x86 ISA 非常復(fù)雜,因?yàn)殚L(zhǎng)期以來人們一直在進(jìn)行小的更改和補(bǔ)丁,以向 ISA 中添加更多功能,而 ISA 確實(shí)已沒有空間容納此類新功能。
復(fù)雜的 x86 ISA 使解碼成為瓶頸。x86 指令的長(zhǎng)度在 1 到 15 個(gè)字節(jié)之間,計(jì)算長(zhǎng)度非常復(fù)雜。在開始解碼下一條指令之前需要知道指令的長(zhǎng)度。如果您想每個(gè)時(shí)鐘周期解碼 4 或 6 條指令,這肯定是個(gè)問題!英特爾和 AMD 現(xiàn)在都在不斷增加微操作緩存來克服這個(gè)瓶頸。而 ARM 有固定大小的指令,所以這個(gè)瓶頸不存在,也不需要微操作緩存。
x86 的另一個(gè)問題是它需要很長(zhǎng)的管道來處理復(fù)雜性。分支誤預(yù)測(cè)懲罰等于 pipeline 的長(zhǎng)度。因此,他們正在添加越來越復(fù)雜的分支預(yù)測(cè)機(jī)制,其中包含大型分支歷史信息表和分支目標(biāo)緩沖區(qū)。當(dāng)然,所有這些都需要更多的芯片空間和更多的功耗。
盡管有這些負(fù)擔(dān),x86 ISA 還是相當(dāng)成功的。這是因?yàn)樗梢詾槊織l指令做更多的工作。
Agner 還在他的微架構(gòu)手冊(cè)中寫道:AMD 和英特爾 CPU 設(shè)計(jì)的最新趨勢(shì)已經(jīng)回歸到 CISC 原則,以更好地利用有限的代碼緩存,增加管道帶寬,并通過在 pipeline 中維持較少的微操作數(shù)量來降低功耗。這些改進(jìn)代表了提高 x86 整體性能和功耗效率的微架構(gòu)變遷。
那么就存在一個(gè)重要的問題:現(xiàn)代 AMD 和英特爾 CPU 為 x86 兼容性付出了多大的代價(jià)?
Agner 提到的解碼瓶頸、分支預(yù)測(cè)和 pipeline 復(fù)雜性是 ARM 認(rèn)為 x86 產(chǎn)生的「CISC tax」的一部分。過去,英特爾和 AMD 告訴我們解碼功耗只是芯片總功耗的極小一部分。但是,如果 CPU 正在為微操作緩存或復(fù)雜的分支預(yù)測(cè)器消耗能量以彌補(bǔ)解碼帶寬的不足,那么意義就不一樣了。微操作緩存功耗和分支預(yù)測(cè)功耗均由 CPU 的微架構(gòu)及其制造制程節(jié)點(diǎn)決定。「RISC 與 CISC」并沒有充分體現(xiàn)這三個(gè)變量之間關(guān)系的復(fù)雜性。
也許我們還需要幾年的時(shí)間才能知道蘋果的 M1 和高通未來的 CPU 是否代表了市場(chǎng)翻天覆地的變化,AMD 和英特爾是否將面臨下一個(gè)挑戰(zhàn)。保持 x86 兼容性是否是現(xiàn)代 CPU 的負(fù)擔(dān),這既是一個(gè)新問題,也是一個(gè)非常古老的問題。之所以說它是一個(gè)新問題是因?yàn)樵?M1 推出之前,無法進(jìn)行有意義的比較;說它是一個(gè)舊問題是因?yàn)楫?dāng)初 x86 CPU 誕生時(shí),一些個(gè)人計(jì)算機(jī)延續(xù)使用非 x86 CPU 就讓這個(gè)主題引起過相當(dāng)多的討論。
AMD 仍在以每年 1.15 至 1.2 倍的速度改進(jìn) Zen,英特爾的 Alder Lake 也將使用低功耗 x86 CPU 內(nèi)核來改進(jìn)功耗,兩家 x86 制造商都在不斷改進(jìn)他們的方法。需要一些時(shí)間來觀察這些內(nèi)核及其后繼者如何與未來的蘋果產(chǎn)品競(jìng)爭(zhēng),但 x86 一直未脫離這場(chǎng)競(jìng)爭(zhēng)。
回到最初那個(gè)問題:為什么用 RISC 與 CISC 比較 x86 和 ARM CPU 是錯(cuò)誤的?
當(dāng) Patterson 和 Ditzel 創(chuàng)造 RISC 和 CISC 時(shí),他們打算闡明 CPU 設(shè)計(jì)的兩種不同策略。四十年過去了,這些術(shù)語既模糊又清晰。RISC 和 CISC 并非毫無意義,但這兩個(gè)術(shù)語的含義和適用性已變得高度語境化。
使用 RISC 與 CISC 來比較現(xiàn)代 x86 和 ARM CPU,其問題在于:它需要 3 個(gè)對(duì) x86 和 ARM 比較重要的特定屬性——制程節(jié)點(diǎn)、微架構(gòu)和 ISA——將 3 個(gè)屬性結(jié)婚在一起,然后才能聲明 ARM 在 ISA 的基礎(chǔ)上更勝一籌。「以 ISA 為中心」與「以實(shí)現(xiàn)為中心」是一種更好的理解方式,但前提是人們需要記得兩者之間的關(guān)系。具體來說:
以 ISA 為中心的觀點(diǎn)認(rèn)為制造幾何(manufacturing geometry)和微架構(gòu)非常重要,并且促成了 x86 在 PC、服務(wù)器和 HPC 市場(chǎng)曾經(jīng)的主導(dǎo)地位。這種觀點(diǎn)認(rèn)為,當(dāng)制造能力和安裝基礎(chǔ)的優(yōu)勢(shì)被控制或取消時(shí),RISC(以及 ARM CPU)通常會(huì)優(yōu)于 x86 CPU。
以實(shí)現(xiàn)為中心的觀點(diǎn)認(rèn)為 ISA 確實(shí)很重要,但從發(fā)展歷程的角度看,微架構(gòu)和制程幾何(process geometry)更重要。當(dāng)前,英特爾正在努力縮小一些業(yè)內(nèi)差距,AMD 在努力改進(jìn) Ryzen(尤其是在移動(dòng)領(lǐng)域)。但從發(fā)展歷程上看,這兩家 x86 制造商都表現(xiàn)出具備與 RISC CPU 制造商有效競(jìng)爭(zhēng)的能力。
考慮到 CPU 設(shè)計(jì)周期的現(xiàn)實(shí)情況,我們還需要幾年的時(shí)間才能真正得出哪個(gè)觀點(diǎn)更好的答案。今天的半導(dǎo)體市場(chǎng)與 20 年前的市場(chǎng)之間有一個(gè)區(qū)別:與英特爾在 1990 年代末和 2000 年代初所面臨的大多數(shù) RISC 制造商相比,臺(tái)積電是一個(gè)更強(qiáng)大的代工競(jìng)爭(zhēng)對(duì)手。英特爾的 7nm 團(tuán)隊(duì)不得不承受巨大的壓力。
RISC 與 CISC 是理解兩種不同類型 CPU 之間差異的起點(diǎn),而不是今天如何比較的準(zhǔn)確依據(jù)。














