泛化性的危機!LeCun發(fā)文質(zhì)疑:測試集和訓練集永遠沒關系
長久以來一個觀點就是在測試集上表現(xiàn)更好的模型,泛化性一定更好,但事實真是這樣嗎?LeCun團隊最近發(fā)了一篇論文,用實驗證明了在高維空間下,測試集和訓練集沒有關系,模型做的一直只有外推沒有內(nèi)插,也就是說訓練集下的模型和測試集表現(xiàn)沒關系!如此一來,刷榜豈不是毫無意義?
內(nèi)插(interpolation)和外推(extrapolation)是機器學習、函數(shù)近似(function approximation)中兩個重要的概念。
在機器學習中,當一個測試樣本的輸入處于訓練集輸入范圍時,模型預測過程稱為「內(nèi)插」,而落在范圍外時,稱為「外推」。
一直以來深度學習的研究都依賴于兩個概念:
- 最先進的算法之所以工作得這么好,是因為它們能夠正確地內(nèi)插訓練數(shù)據(jù);
- 在任務和數(shù)據(jù)集中只有內(nèi)插,而沒有外推。
但圖領獎得主Yann LeCun團隊在arxiv掛了一篇論文公開質(zhì)疑這兩個概念是錯誤的!

他們在論文中表示,從理論上和經(jīng)驗上來說,無論是合成數(shù)據(jù)還是真實數(shù)據(jù),幾乎可以肯定的是無論數(shù)據(jù)流形(data manifold)的基本本征維數(shù)(intrinstic dimension)如何,內(nèi)插都不會出現(xiàn)在高維空間(>100)中。
本征維度即在降維或者壓縮數(shù)據(jù)過程中,為了讓你的數(shù)據(jù)特征最大程度的保持,你最低限度需要保留哪些features,它同時也告訴了我們可以把數(shù)據(jù)壓縮到什么樣的程度,所以你需要了解哪些 feature 對你的數(shù)據(jù)集影響是最大的。
考慮到當前計算能力可以承載的實際數(shù)據(jù)量,新觀察到的樣本極不可能位于該數(shù)據(jù)集的convex hull中。因此,他們得出了兩個結論:
- 目前使用和研究的模型基本都是外推的了;
- 鑒于這些模型所實現(xiàn)的超越人類的性能,外推機制也不一定非要避免,但這也不是泛化性能的指標。
文中研究的第一階段主要包括理解環(huán)境維度(即數(shù)據(jù)所在空間的維度)的作用,還包括基本數(shù)據(jù)流形內(nèi)在維度(即數(shù)據(jù)最小表示所需的變量數(shù)量)的作用,以及包含所有數(shù)據(jù)流形的最小仿射子空間的維數(shù)。
可能有人認為像圖像這樣的數(shù)據(jù)可能位于低維流形上,因此從直覺和經(jīng)驗上認為無論高維環(huán)境空間如何,內(nèi)插都會發(fā)生。但這種直覺會產(chǎn)生誤導,事實上,即使在具有一維流形的極端情況下,底層流形維度也不會變化。
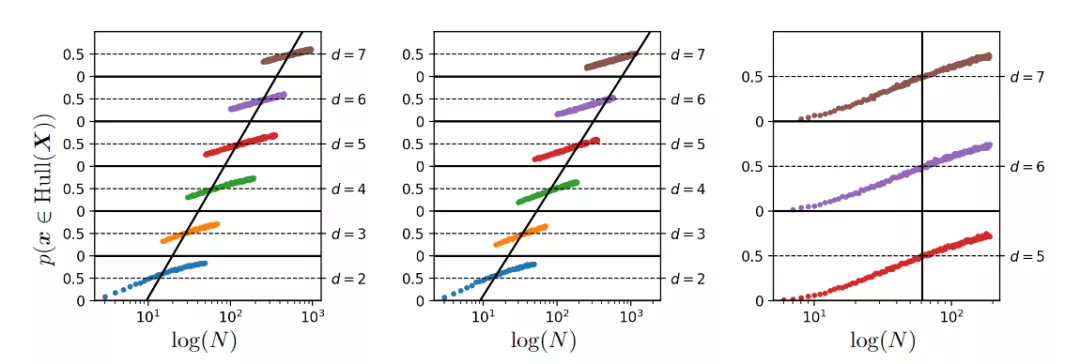
在描述新樣本處于內(nèi)插區(qū)域的概率演變時,上圖給出了在對數(shù)尺度上看到的不斷增加的數(shù)據(jù)集大小,以及基于對500000次試驗的蒙特卡羅估計的各種環(huán)境空間維度(d),左側圖為從高斯密度N(0, Id)中采樣數(shù)據(jù),中間圖從具有1的本征維數(shù)的非線性連續(xù)流形采樣數(shù)據(jù),右圖從高斯密度恒定維數(shù)4的仿射子空間中采樣數(shù)據(jù),而環(huán)境維數(shù)增加。
從這些數(shù)字可以清楚地看出,為了保持內(nèi)插區(qū)域的恒定概率,不管潛在的內(nèi)在流形維度訓練集的大小必須隨d呈指數(shù)增長,其中d是包含整個數(shù)據(jù)流形的最低維仿射子空間的維數(shù)。
在所有情況下,該數(shù)據(jù)集的本征維度均為1,流形是連續(xù)的、非線性的、分段光滑的,對應于單純形的遍歷。
因此可以得出結論,為了增加處于內(nèi)插區(qū)域的概率,應該控制d, 而不是控制流形基礎維度和環(huán)境空間維度。
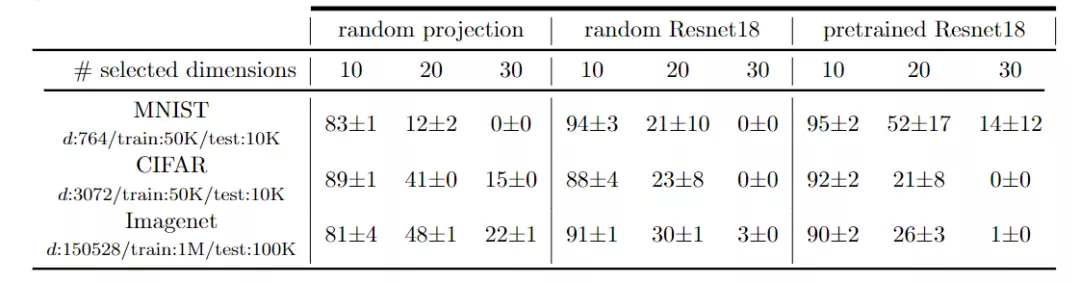
在研究像素空間中的測試集外推時,研究人員首先研究了MNIST、CIFAR和Imagenet序列集中處于插值狀態(tài)的測試集的比例。
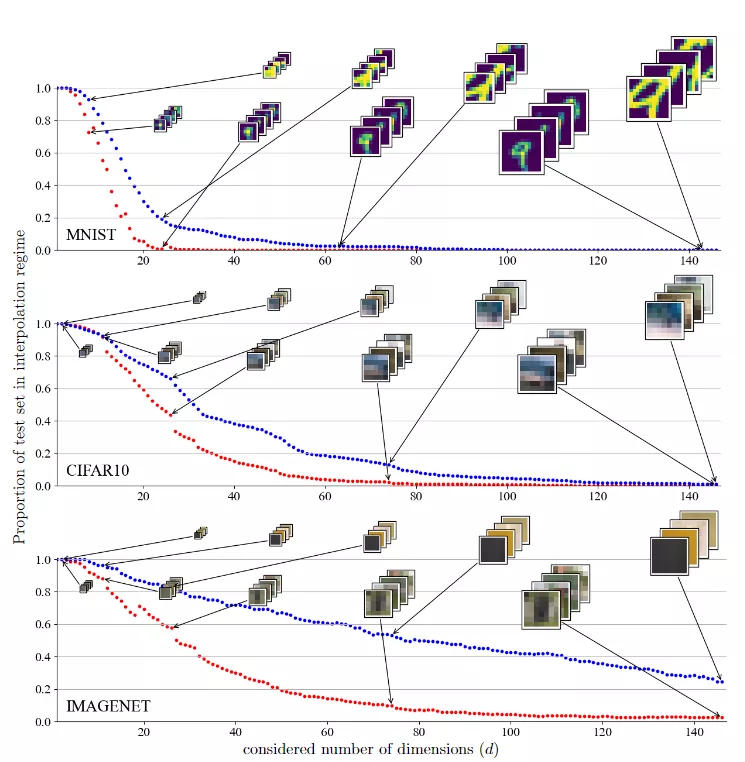
為了掌握數(shù)據(jù)維度的影響,使用從兩種策略獲得的不同數(shù)量的維度來計算該比例。第一種策略只從圖像的中心保留一定數(shù)量的維度,它的優(yōu)點是保留流形幾何體,同時只考慮有限的維數(shù);第二種策略對圖像進行平滑和子采樣,它的優(yōu)點是能夠保留流形的整體幾何體,同時刪除高頻結構(圖像細節(jié))并壓縮較少維數(shù)的信息。
在這兩種情況下都看到,盡管自然圖像具有數(shù)據(jù)流形幾何結構,但相對于數(shù)據(jù)維度d,在內(nèi)插區(qū)域中查找樣本還是非常困難。
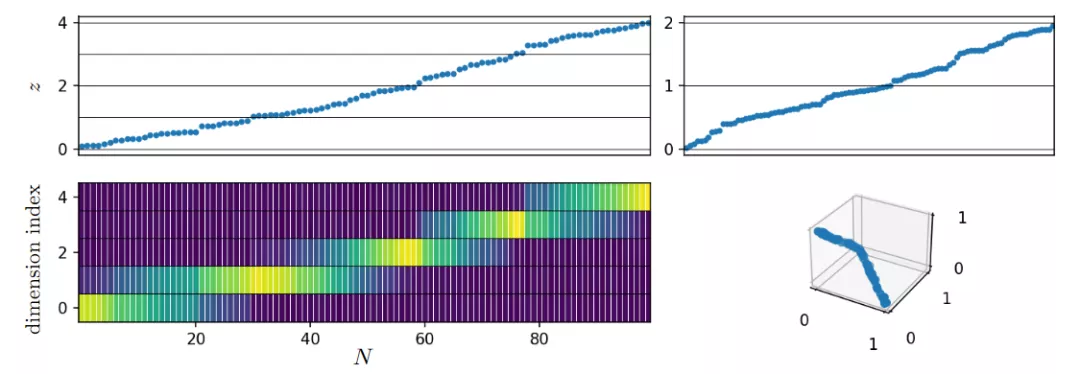
在降維空間中研究測試集外推時,一組實驗使用非線性或線性降維技術來可視化高維數(shù)據(jù)集。為了明確地了解所用的降維技術是否保留了內(nèi)插或外推信息時,研究人員創(chuàng)建了一個數(shù)據(jù),該數(shù)據(jù)由d=8,12的d維超立方體的2d頂點組成。
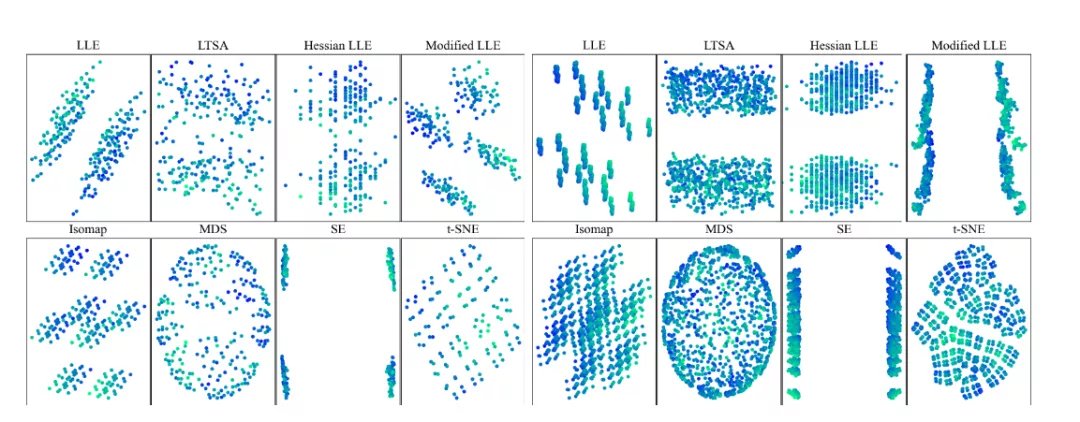
這些數(shù)據(jù)集具有特定性,即任何樣本相對于其他樣本都處于外推狀態(tài)。并且使用8種不同的常用降維技術對這些頂點進行二維表示。可以觀察到降維方法會丟失內(nèi)插/外推信息,并導致明顯偏向插值的視覺誤解。
內(nèi)插和外推提供了一種關于給定數(shù)據(jù)集的新樣本位置的直觀幾何特征,這些術語通常被用作幾何代理來預測模型在看不見的樣本上的性能。從以往的經(jīng)驗來看似乎已經(jīng)下了定論,即模型的泛化性能取決于模型的插值方式。這篇文章通過實驗證明了這個錯誤觀念。
并且研究人員特別反對使用內(nèi)插和外推作為泛化性能的指標,從現(xiàn)有的理論結果和徹底的實驗中證明,為了保持新樣本的插值,數(shù)據(jù)集大小應該相對于數(shù)據(jù)維度呈指數(shù)增長。簡而言之,模型在訓練集內(nèi)的行為幾乎不會影響該模型的泛化性能,因為新樣本幾乎肯定位于該凸包(convex)之外。
無論是考慮原始數(shù)據(jù)空間還是嵌入,這一觀察結果都是成立的。所以研究人員認為,這些觀察為構建更適合的內(nèi)插和外推幾何定義打開了大門,這些定義與泛化性能相一致,特別是在高維數(shù)據(jù)的情況下