LeCun聯手博士后arxiv發文,遭reddit網友質疑:第一張圖就錯了
神經網絡模型訓練最大的弊端在于需要大量的訓練數據,而非監督學習和自監督學習則能很好地解決標注的問題。
今年三月,Facebook AI Research和紐約大學的Yann LeCun聯手在arxiv上發布一篇關于自監督學習的論文,提出模型Barlow Twins,這個名字來源于神經科學家H. Barlow的redundancy-reduction原則。
近日這篇論文又在Reddit上掀起一陣討論熱潮,網友對LeCun的論文似乎有些不買賬。
自監督學習
所謂自監督,就是訓練了,但沒有完全訓練,用到的標簽來源于自身,它與無監督學習之間的界限逐漸模糊。
自監督學習在NLP領域已經取得了非常大的成就,BERT、GPT、XLNET等自監督模型幾乎刷遍了NLP各大榜單,同時在工業界也帶來了很多的進步。在CV領域,自監督似乎才剛剛興起。
從Kaiming的MoCo和Hinton組Chen Ting的SimCLR,近兩年自監督學習(SSL,self-supervised learning)在大佬們的推動下取得了很大的成功。
何愷明一作的Moco模型發表在CVPR2020上,并且是Oral。文章核心思想是使用基于contrastive learning的方式自監督的訓練一個圖片表示器也就是編碼器,能更好地對圖片進行編碼然后應用到下游任務中。基于對比的自監督學習最大的問題就是負樣本數量增大后會帶來計算開銷的增大,何愷明使用了基于隊列的動態字典來存儲樣本,同時又結合了動量更新編碼器的方式,解決了編碼器的快速變化會降低了鍵的表征一致性問題。MoCo在多個數據集上取得了最優效果,縮小了監督學習和無監督學習之間的差距。
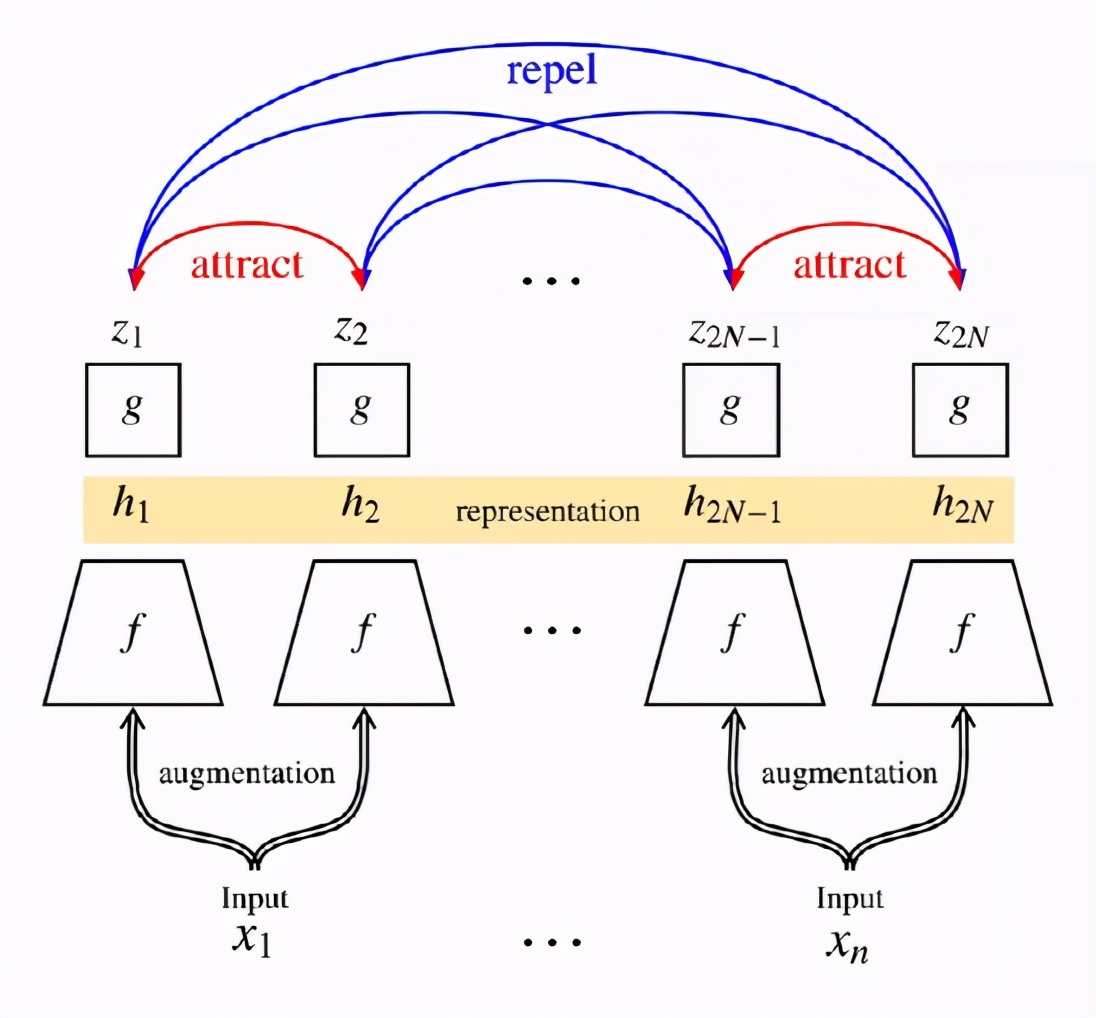
而Hinton組的SimCLR側重于同一張圖像的不同數據增強的方法,具體而言就是隨機采樣一個batch,對batch里每張圖像做兩種增強,可以認為是兩個view;讓同一張圖的不同view在latent space里靠近,不同圖的view在latent space里遠離,通過NT-Xent實現。
從AutoEncoder到語言模型,可以說是無標簽的數據讓預訓練模型取得驚人的成績,之后在有標簽數據上的fine tune讓他有了應用價值。
Barlow Twins
今年3月,arxiv上多了一篇Yann Lecun的論文。
CV領域的自監督學習的最新成果總是向世人證明無需數據標簽也可以達到有監督的效果。目前自監督學習主流的方法就是使網絡學習到輸入樣本不同失真(distortions)版本下的不變性特征(也稱為數據增強),但是這種方法很容易遭遇平凡解,現有方法大多是通過實現上的細節來避免出現collapse。
LeCun團隊解釋說,這種方法經常會出現瑣碎的常量表示形式,這些方法通常采用不同的機制和仔細的實現細節,以避免collapse的解決方案。Barlow Twins是解決此問題的目標函數,它測量兩個相同網絡的輸出特征之間的互相關矩陣,這些輸出饋送了失真的版本,以使其盡可能接近單位矩陣,同時最大程度地減少了相關向量分量之間的冗余。
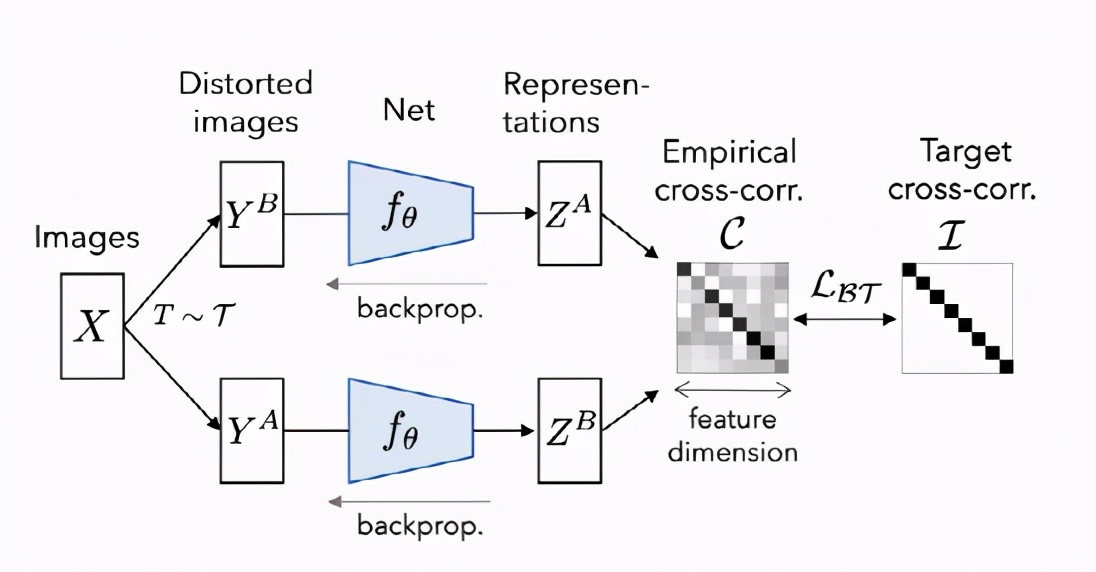
這個方法受英國神經科學家霍勒斯·巴洛(Horace Barlow)在1961年發表的文章中的啟發,Barlow Twins方法將「減少冗余」(一種可以解釋視覺系統組織的原理)應用于自我監督學習,也是感官信息轉化背后的潛在原理。
研究人員通過遷移學習將模型應用到不同的數據集和計算機視覺任務來評估Barlow Twins的表示形式,還在圖像分類和對象檢測的任務上進行試驗,使用ImageNet ILSVRC-2012數據集上的自我監督學習對網絡進行了預訓練。
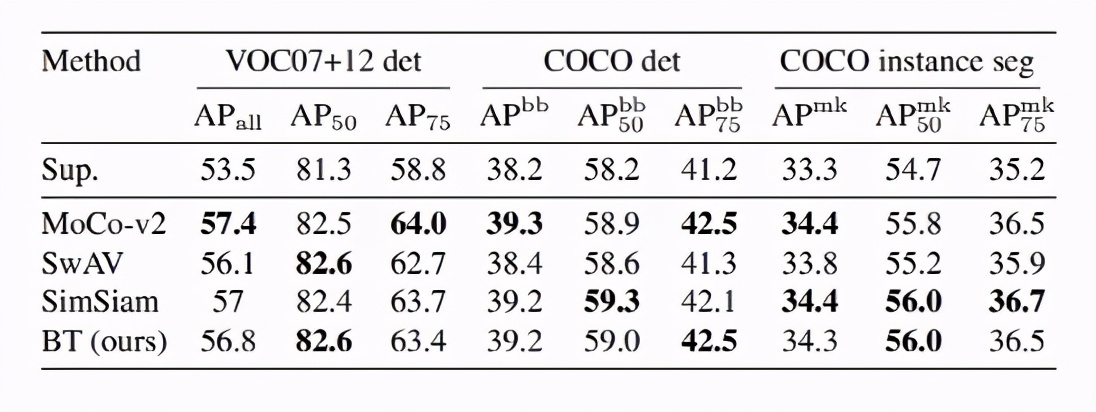
結果表明,Barlow Twins在概念上更簡單并且避免了瑣碎的參數,其性能優于以前的自我監督學習方法。研究人員認為,所提出的方法只是應用于SSL的信息瓶頸原理的一種可能實例,并且進一步的算法改進可能會導致更有效的解決方案。
Jing Li
靖禮是這篇論文的第二作者,本科被保送到北大物理學院,獲得了物理學學士學位和經濟學學士學位,獲得了麻省理工學院的物理學博士學位。他在2010年贏得了第41屆國際中學生物理學奧林匹克競賽金牌。
目前是Facebook AI Research(FAIR)的博士后研究員,與Yann LeCun一起研究自我監督學習。
他的研究領域還包括表示學習,半監督學習,多模式學習,科學AI。
他還是Lightelligence Inc.的聯合創始人,該公司生產光學AI計算芯片。
在企業技術領域,他被授予《福布斯》中國30位30歲以下人士。
而Yann LeCun是CNN之父,紐約大學終身教授,與Geoffrey Hinton、Yoshua Bengio并成為“深度學習三巨頭”。前Facebook人工智能研究院負責人,IJCV、PAMI和IEEE Trans 的審稿人,他創建了ICLR(International Conference on Learning Representations)會議并且跟Yoshua Bengio共同擔任主席。
1983年在巴黎ESIEE獲得電子工程學位,1987年在 Université P&M Curie 獲得計算機科學博士學位。1998年開發了LeNet5,并制作了被Hinton稱為“機器學習界的果蠅”的經典數據集MNIST。2014年獲得了IEEE神經網絡領軍人物獎,2019榮獲圖靈獎。
大牛也會出錯?
Yann LeCun可謂是深度學習界的大牛,但同樣要遭受質疑。
有網友評價這篇論文是完全沒意義的,這篇論文中提出的方法只有在特定條件下才好用,并且仍然需要大規模計算資源。
并且隨著batch size的增加,效果下降了,但是為什么?
還有說圖1就是錯的,損失函數也是無意義的。
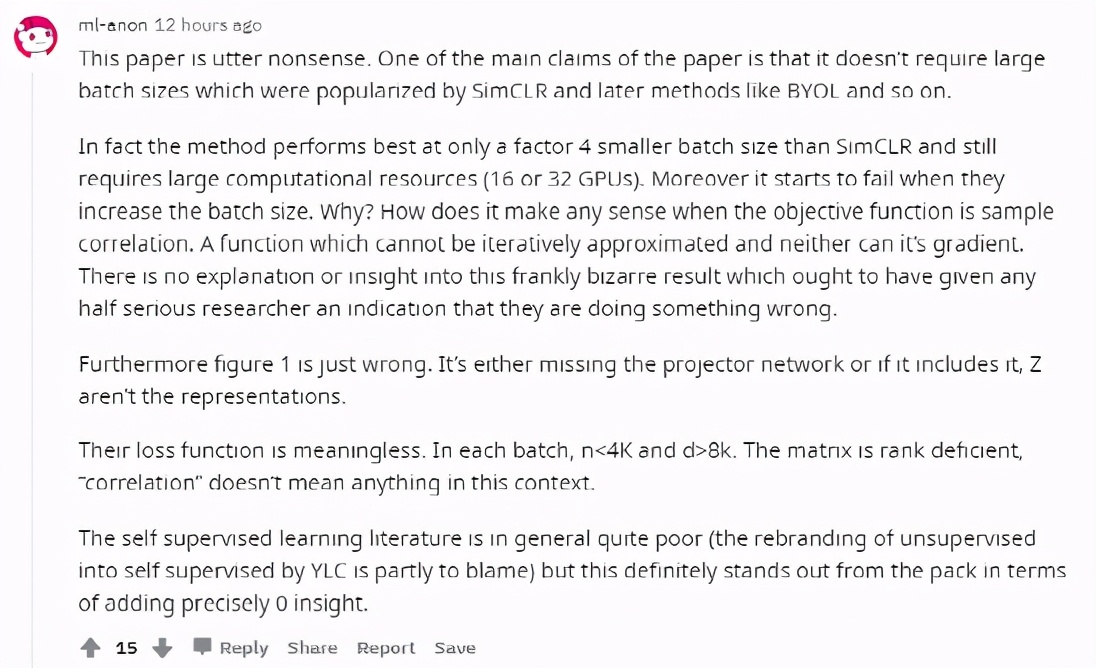
知乎網友討論中也有認為Barlow Twins只是整合了自監督學習的技巧,如增加batch size、增加訓練時間、交替迭代、predictor機制、stop gradient等這些技巧層面的工作,學習過程則是讓互相關矩陣與單位陣要盡可能接近。

對此你怎么看?