為什么數據庫調整大小如此困難?
為什么規劃數據庫容量如此困難?那么怎么簡化?可以使用開源NoSQL數據庫ScyllaDB來演示示例。
調整數據庫的大小看起來很簡單:用數據集的大小和所需吞吐量除以節點的容量。很容易,不是嗎?
如果有人曾經嘗試規劃數據庫容量,就會知道這有多難。即使是做出粗略的估計也很具挑戰性。那么為什么這么難?
以下是估算集群大小的步驟:
(1) 對使用模式做出假設。
(2) 估計所需工作量。
(3) 決定數據庫的高級配置。
(4) 將工作負載、配置和使用模式提供給數據庫的性能模型。
(5) 收入。
這個流程雖然容易理解,但在實踐工作中卻不那么容易。
例如,在對數據庫配置(例如復制因子和一致性級別)做出決策時,做出的決策會受到預先設想答案的影響。而當成本變得非常昂貴時,而進行一些復制似乎有點過分。
將數據庫的規模調整看作一個設計過程,需要意識它是迭代的,并且支持需求和使用的發現和研究。與任何設計過程一樣,最佳規模在經濟上和操作上都不理想,其投入的時間和資源也很有限。
在設計過程的簡單性和成本與準確性之間存在內在的權衡。畢竟,復雜的模型可以更好地預測數據庫性能,但其成本可能與構建數據庫本身一樣高,而且需要太多的輸入,以至于其應用不切實際。
帶來哪些問題?
數據庫的工作負載通常被描述為查詢的吞吐量和它必須支持的數據集大小。這將會引發出一些問題:
•這個數字是最大吞吐量還是平均值?(工作量通常有周期性變化和峰值)
•是否應該分離某些類型的查詢?(例如讀取和寫入)
•如果還沒有使用這個數據庫,那么如何估計查詢的數量?數據集多大?
•熱門數據集是什么?數據庫存儲的數據比它們在任何給定時間點所能提供的數據多得多。
•數據模型呢?從經驗中知道,數據模型對查詢數量、性能和存儲大小有很大的影響。
•預期增長是多少?希望構建一個可以隨工作負載擴展的數據庫。
•查詢的服務等級目標(SLO)是什么?設計的延遲目標是什么?
有些人很幸運,擁有一個可以正常工作的系統,也許還有運行正常的數據庫,他們可以很容易地從中提取或推斷出這些問題的答案。但在通常情況下,一些被迫使用猜測方法和粗略計算。這并不像聽起來那么糟糕。例如,可以了解這個使用蒙特卡羅工具的模型,如下圖所示。
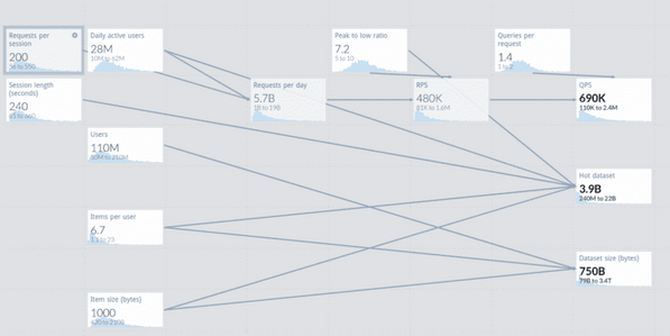
估計工作量很有趣。但是出于簡單的分級目的,人們感興趣的是吞吐量和數據集的最大值,并將只區分兩種查詢:讀取和寫入,其原因將在后面解釋。
還可以假設對數據模型的控制程度很高。對于任何NoSQL數據庫,其目標是通過一個查詢來處理所有需要的數據--如果用戶想優化讀取或寫入,需要做出決定。
通常的基本步驟是:
(1) 估計峰值數據集大小和工作負載。
(2) 初步繪制數據模型,對優化目標進行高層決策。
(3) 根據數據模型估計讀/寫比率。
構建數據庫的性能模型
數據庫的性能模型必須在一些有時相互沖突的需求之間取得平衡,它必須考慮足夠的性能和容量安全裕度,但需要在成本、可靠性與性能、持續和峰值負載之間實現平衡,但仍然可以簡化,即使在沒有特定應用程序的情況下使用,同時提供明確的結果。
這確實是一項具有挑戰性的任務。但它可以簡單得多。例如,以下是它如何與Scylla一起工作,Scylla是一個兼容Apache Cassandra的開源NoSQL數據庫。
查詢vs操作
工作負載是根據查詢(通常是CQL)指定的。CQL查詢可能非常復雜,并生成數量不一的基本操作,這些操作的性能相對可預測。以下面的CQL查詢為例:
- SELECT * FROM user_stats WHERE id=UUID
- SELECT * FROM user_stats WHERE username=USERNAME
- SELECT * FROM user_stats WHERE city=”New York” ALLOW FILTERING
查詢#1將使用主鍵定位記錄,因此會立即在正確的分區上執行--根據一致性級別,它仍然可能分解為幾個操作,因為將查詢多個副本(稍后詳細介紹)。
盡管查詢#2看起來非常相似,但它會基于二級索引查找記錄,分解為兩個子查詢:一個子查詢到全局二級索引以查找主鍵,另一個子查詢從分區檢索行。此外,根據一致性級別,這可能會生成多個操作。
查詢#3甚至更極端,因為它跨分區掃描;它的表現將是糟糕的和不可預測的。
另一個例子是UPDATE查詢:
- UPDATE user_stats SET username=USERNAME, rank=231, score=3432 WHERE ID=UUID
- UPDATE user_stats SET username=USERNAME, rand=231, score=3432 WHERE ID=UUID IF EXISTS
查詢#1可能會直觀地分解為讀取和寫入這兩個操作--但在CQL UPDATE查詢中是UPSERT查詢,只會生成1個寫入操作。
然而,查詢#2盡管看起來很相似,但它不僅要求在所有副本上先讀取后寫入,而且還要求進行編排的輕量級事務(LWT)。
類似地,查詢生成的磁盤操作數量可能會有很大的不同。大多數數據庫在排序字符串表(SSTable)存儲格式中使用日志結構的合并樹(LSM)結構。他們從不修改磁盤上的SSTable文件,它們是不變的。寫入被持久化到只追加提交日志以進行恢復,并寫入內存緩沖區(memtable)。當memtable變得太大時,它會被寫入磁盤上的一個新的SSTable文件,并從內存中刷新。這使得寫路徑非常高效,但在讀取時引入了一個問題:數據庫必須在多個SSTables中搜索一個值。
為了防止這種讀取失控放大,數據庫定期將多個SSTables壓縮到數量更少的文件中,只保留最新的數據。這減少了完成查詢所需的讀取操作數量。
這意味著將磁盤操作歸因于單個查詢實際上是不可能的。磁盤操作的確切數量取決于SSTables的數量、它們的排列、壓縮策略等。開源的NoSQL數據庫旨在最大限度地利用存儲空間,所以只要磁盤速度足夠快并且不是瓶頸,就可以忽略這個維度。這就是推薦快速本地NVMe磁盤的原因。
雖然這個示例主要關注CQL,但預測查詢成本并不是唯一的問題。事實上,查詢語言越豐富、功能越強大,就越難以預測其性能。例如,由于SQL的強大功能,它的性能可能難以預測。因此,復雜的查詢優化器是RDBMS的重要組成部分,它確實提高了性能,但其代價是使性能更加難以預測。這是NoSQL采取的另一種折衷方法:優先考慮可預測的性能和可擴展性,而不是功能豐富的查詢語言。
一致性的難題
分布式可用數據庫需要可靠地將數據復制到多個節點。每個鍵空間可以配置副本的數量,稱之為復制因子。從客戶端的角度來看,這可以同步發生,也可以異步發生,這取決于寫入的一致性級別。
例如,當一致性級別為1時,數據最終會寫入所有副本,但客戶端只會等待一個副本確認寫入。即使有些節點暫時不可用,數據庫也應該在這些節點可用時緩存寫入和復制(這稱為暗示切換)。在實踐中,可以假設每個寫查詢都會在每個副本上生成至少一個寫入操作。
然而,對于讀取來說,情況有些不同。一致性級別為ALL的查詢必須從所有副本讀取數據,從而生成與集群的復制因子一樣多的讀取操作,但一致性級別為1的查詢只從單個節點讀取數據,從而實現更便宜、更快的讀取。這允許用戶以犧牲一致性為代價從集群中擠出更多的讀吞吐量,因為一個節點在被讀取時可能還沒有獲得最近的更新。
最后,還有輕量級事務(LWT)需要考慮。如上所述,輕量級事務(LWT)需要利用Paxos算法對所有副本進行編排。輕量級事務(LWT)不僅強制每個副本讀取然后寫入該值,而且還需要維護事務的狀態,直到Paxos輪結束。由于輕量級事務(LWT)的行為方式不同,需要將其視為每個核心能夠支持的吞吐量的獨立性能模型。
所有操作都是平等的,但有些操作比其他操作更平等
現在已經將CQL查詢分解為基本操作,那么可以詢問一些問題:每個操作需要多少時間(和資源)?CPU核心能支持的容量是多少?同樣,其答案有點復雜。作為一個例子,可以考慮一個簡單的讀取并遵循節點中的執行步驟:
(1) 在內存表中查找值。
(2) 在緩存中查找值。
(3) 在SSTables中逐層查找值并合并值。
(4) 響應協調者。
顯然,如果它們在基于內存的memtable或行級緩存中,讀取將更快地完成,這沒什么好奇怪的。此外,步驟#3和#4可能會產生更高的成本,這取決于從磁盤讀取、處理和通過網絡傳輸的數據的大小。如果需要讀取10MB的數據,這可能需要相當長的時間。這可能是因為存儲在單個單元格中的值很大,也可能是因為范圍掃描返回許多結果。但是,在值很大的情況下,Scylla不能將它們分成更小的塊,必須將整個單元格加載到內存中。
一般來說,建議對數據進行建模,使分區、行和單元不要增長得太大,以確保減少性能的差異。然而在現實中,總會有一些差異。
當涉及到分區訪問模式時,這種差異尤其顯著。許多數據庫用于跨節點擴展和傳播數據的策略是將數據分塊到彼此獨立的分區中。但獨立也意味著分區可能會經歷不均勻的負載,導致所謂的“熱分區”問題,即單個分區會遇到節點容量限制,盡管集群的其余部分有足夠的資源。這個問題的發生在很大程度上取決于數據模型、數據集中分區鍵的分布以及工作負載中鍵的分布。由于預測熱分區通常需要分析整個數據集和工作負載,因此在設計階段是不切實際的,因此可以提供某些已知的分布作為模型的輸入,或者對分區的相對熱進行一些假設。另外,nodetool toppartitions命令可以幫助定位熱分區。
物化視圖、二級索引和其他
數據庫具有自動二級索引和物化視圖以及變更數據捕獲(CDC)功能。這些表本質上是由數據庫本身維護的輔助表,只允許使用一個寫操作以多種形式寫入數據。
而在幕后,Scylla根據用戶提供的模式派生要寫入的新值,并將這些新值寫入不同的表。在這方面,Scylla和RDBMS之間的主要區別在于,派生數據是異步寫入的,并且作為索引和物化視圖跨網絡寫入,而不局限于單個分區。這是另一個需要考慮的寫入的來源。在Scylla中,它是可以預測的,并且在性能上與用戶生成的操作相似。對于寫入的每一項,CDC和從寫入單元格派生的每個物化視圖或二級索引都將觸發一次寫入。在某些情況下,物化視圖和CDC可能需要額外的讀取,例如,如果啟用了CDC的“預映像”功能,就會發生這種情況。另外需要記住的是,一個CQL查詢可以觸發多個寫操作。
CDC、二級索引和物化視圖被實現為由Scylla本身管理的常規表,但這也意味著它們消耗的磁盤空間與用戶表相當,因此必須在容量計劃中考慮到這一點。
高峰和數據庫維護
所有數據庫都需要執行各種維護操作。RDBMS需要清理重做日志(例如Postgre SQL VACUUM),轉儲快照到磁盤(查看Redis),或執行內存垃圾收集(Cassandra、Elastic、HBase)。使用LSM存儲的數據庫(如Cassandra、HBase、Scylla)也需要定期壓縮SSTables,并將memtable刷新到新的SSTables中。
如果數據庫足夠智能,可以將壓縮和修復等維護操作推遲到稍后、負載更少的時間,那么可以在短時間內獲得最佳性能。然而,最終將不得不為這些維護操作預留資源。這對于大多數系統來說非常有用,因為一天內的負載的分配并不是均勻的。但是,企業的計劃應該為數據庫的持續長期操作提供足夠的容量。
此外,僅根據吞吐量進行規劃是不夠的。在某種程度上,可以使數據庫過載以獲得更高的吞吐量,但其代價是更高的延遲。
在這個意義上,基準往往具有誤導性,通常時間太短而無法達到有意義的持續運行。延遲/吞吐量的權衡通常更容易度量,甚至在較短的基準測試中也可以觀察到。
另一個重要但經常被忽視的問題是降級操作。作為一個本地冗余和高可用的數據庫,Scylla被設計為平滑地處理節點故障(根據用戶設置的一致性約束)。但是,雖然故障在語義上是一致的,但這并不意味著它們是動態透明的,而其容量的顯著損失將影響集群的性能,以及故障節點的恢復或替換。在調整集群規模時也需要考慮這些因素。
選擇適當規模的節點
由于Scylla的容量可以通過增加節點或選擇更大的節點來增加,一個有趣的問題出現了:應該選擇哪種擴展策略?一方面,更大的節點效率更高,因為可以獨立于服務Scylla的內核分配CPU核來處理網絡和其他任務,并減少節點協調的相對開銷。另一方面,擁有的節點越多,當其中一個節點出現故障時,損失的部分容量就越少--盡管丟失節點的概率稍微高一些。
對于非常大的工作負載,解決這個問題是沒有意義的,因為大型節點是不夠的。但是對于許多較小的工作負載來說,3個中大型節點就足夠了。這個決定與工作量相關。但是,對于可靠性降級操作,建議至少運行6~9個節點(假設復制因子為3)。
結論
容量規劃和調整集群規模可能非常復雜和具有挑戰性。本文已經討論了如何考慮安全裕度、維護操作和使用模式。重要的是要記住,任何猜測都只是迭代的初始估計。一旦投入生產并有了真實的數據,可以讓它指導實施容量計劃。