Sentry 監控 - Snuba 數據中臺架構(Query Processing 簡介)
本文轉載自微信公眾號「黑客下午茶」,作者為少 。轉載本文請聯系黑客下午茶公眾號。
Snuba 有一個查詢處理管道,首先將 Snuba 查詢語言( legacy 和 SnQL)解析為 AST,然后在 Clickhouse 上執行 SQL 查詢。在這兩個階段之間,在 AST 上執行幾次傳遞以應用查詢處理轉換。
處理管道有兩個主要目標:優化查詢并防止對我們的基礎設施構成危險的查詢。
在數據模型上,查詢處理流水線分為邏輯部分,進行產品相關處理,物理部分專注于優化查詢。
邏輯部分包含查詢驗證等步驟,以確保它與數據模型匹配或應用自定義函數。物理部分包括諸如提升標簽(promoting tags)和選擇預聚合視圖(pre-aggregated view)來為查詢提供服務等步驟。
查詢處理階段
本節介紹了上述各階段的代碼和示例,并提供了一些提示。
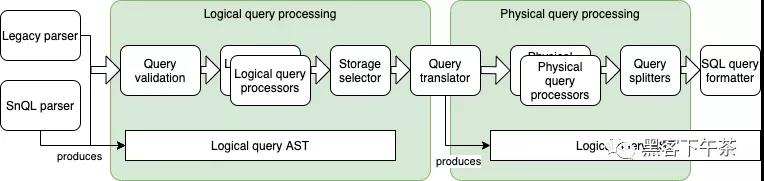
Legacy 和 SnQL 解析器
Snuba 支持兩種語言,傳統的基于 JSON 的語言和新的名為 SnQL 的語言。除了傳統語言不支持的連接和復合查詢之外,查詢處理管道不會更改是否使用一種或另一種語言。
Snuba 支持兩種語言,一種是基于 JSON 的舊語言,另一種是名為 SnQL 的新語言。除了遺留語言不支持的連接和復合查詢之外,無論使用哪種語言,查詢處理管道都不會改變。
它們都生成一個邏輯查詢AST,該查詢由下面數據結構表示。
- https://github.com/getsentry/snuba/tree/master/snuba/query
基于 JSON 的語言舊解析器源碼:
- https://github.com/getsentry/snuba/blob/master/snuba/query/parser/__init__.py
SnQL 解析器:
- https://github.com/getsentry/snuba/tree/master/snuba/query/snql
查詢驗證(Query Validation)
此階段確保可以運行查詢(大多數情況下,我們還沒有捕獲所有可能的無效查詢)。這個階段的職責是在無效查詢的情況下返回一個 HTTP400,并向用戶提供適當的有用消息。
這分為兩個子階段:一般驗證(general validation)和實體特定驗證(entity specific validation)。
一般驗證由一組檢查組成,這些檢查在解析器生成查詢之后立即應用于每個查詢。這在 QueryEntity 函數中發生。這包括防止別名陰影(alias shadowing)和函數簽名驗證(function signature validation)等驗證。
- QueryEntity:https://github.com/getsentry/snuba/blob/master/snuba/query/parser/__init__.py#L91
每個實體也可以以必需列的形式提供一些驗證邏輯。這發生在 class Entity(Describable, ABC):。這允許查詢處理拒絕在 project_id 上沒有條件或沒有時間范圍的查詢。
- https://github.com/getsentry/snuba/blob/master/snuba/datasets/entity.py#L46-L47
邏輯查詢處理器(Logical Query Processors)
查詢處理器是無狀態轉換,接收查詢對象(及其 AST)并就地轉換。這是為邏輯處理器實現的接口。在邏輯階段,每個實體提供按順序應用的查詢處理器。常見的用例是像 apdex 這樣的自定義函數,或者像時間序列處理器(time series processor)那樣的計時。
- apdex: https://github.com/getsentry/snuba/blob/10b747da57d7d833374984d5eb31151393577911/snuba/query/processors/performance_expressions.py#L12-L20
- time series processor:https://github.com/getsentry/snuba/blob/master/snuba/query/processors/timeseries_processor.py
查詢處理器不應該依賴于在之前或之后執行的其他處理器,并且應該彼此獨立。
存儲選擇器(Storage Selector)
如 Snuba 數據模型中所述,每個實體可以定義多個存儲。多個存儲代表多個表,并且出于性能原因可以定義物化視圖(materialized views),因為某些視圖可以更快地響應某些查詢。
在邏輯處理階段(完全基于實體)結束時,存儲選擇器可以檢查查詢并為查詢選擇合適的存儲。存儲選擇器在實體數據模型中定義并實現此接口。一個例子是 Errors 實體,它有兩個存儲,一個用于一致查詢(它們被路由到寫入事件的相同節點),另一個只包括我們沒有寫入的副本來服務大多數查詢。這減少了我們寫入的節點上的負載。
- https://github.com/getsentry/snuba/blob/master/snuba/datasets/storage.py#L155-L165
查詢轉換器(Query Translator)
不同的 storage 有不同的 schema(這些反映了 clickhouse 表或視圖的 schema)。它們通常都與實體模型不同,最顯著的例子是用于標簽 tags[abc] 的可下標表達式,它在 clickhouse 中不存在,其中訪問標簽看起來像 tags.values[indexOf(tags.key, 'abc')]。
選擇 storage 后,需要將查詢轉換為物理查詢。Translator 是一個基于規則的系統,規則由實體(針對每個 storage)定義并按順序應用。
與查詢處理器相反,翻譯規則在查詢上沒有完整的上下文,只能翻譯單個表達式。這使我們能夠輕松地編寫翻譯規則并跨實體重用它們。
這些是 transactions 實體的轉換規則。
- https://github.com/getsentry/snuba/blob/master/snuba/datasets/entities/transactions.py#L33-L81
物理查詢處理器(Physical Query Processors)
與邏輯查詢處理器相比,物理查詢處理器的工作方式非常相似。它們的接口非常相似,語義相同。不同之處在于它們對物理查詢進行操作,因此,它們主要是為優化而設計的。例如,該處理器在標簽上找到相等條件,并將它們替換為標簽哈希圖(有布隆過濾器索引)上的等效條件,從而使過濾操作更快。
- https://github.com/getsentry/snuba/blob/master/snuba/query/processors/mapping_optimizer.py
查詢拆分器(Query Splitter)
通過將某些查詢拆分為多個單獨的 Clickhouse 查詢并組合每個查詢的結果,可以以優化的方式執行某些查詢。
兩個例子是時間拆分和列拆分。兩者都在下面這個文件中。
- https://github.com/getsentry/snuba/blob/master/snuba/web/split.py
時間拆分(Time splitting)將一個查詢(不包含聚合且已正確排序)在一個可變的時間范圍內拆分為多個查詢,該時間范圍的大小逐漸增大,并在得到足夠的結果后按順序停止執行。
列拆分(Column splitting)拆分篩選和列獲取。它對最少數量的列執行查詢的篩選部分,以便 Clickhouse 加載較少的列,然后通過第二個查詢,僅為第一個查詢篩選的行獲取缺少的列。
查詢格式化器(Query Formatter)
該組件只是將查詢格式化為 Clickhouse 查詢字符串。
復合查詢處理
上面的討論僅適用于簡單查詢、復合查詢(連接和包含子查詢的查詢遵循稍微不同的路徑)。
上面討論的簡單查詢管道不適用于連接查詢或包含子查詢的查詢。為了使這項工作發揮作用,每個步驟都必須考慮連接的查詢和子查詢,這會增加過程的復雜性。
為了解決這個問題,我們將每個連接查詢轉換為多個簡單子查詢的連接。每個子查詢都是一個簡單的查詢,可以通過上述管道進行處理。這也是運行 Clickhouse 連接(join)的首選方式,因為它允許我們在連接之前應用過濾器。

此類查詢的查詢處理管道由與上述內容相關的幾個附加步驟組成。
子查詢生成器(Subquery Generator)
該組件采用一個簡單的 SnQL 連接查詢,并為連接中的每個表創建一個子查詢。
表達式下推(Expressions Push Down)
上一步生成的查詢將是一個有效的連接,但效率極低。這一步基本上是一個連接優化器(join optimizer),它將所有可以成為子查詢一部分的表達式下推到子查詢中。這是一個獨立于子查詢處理的必要步驟,因為 Clickhouse join 引擎不執行任何表達式下推,所以它由 Snuba 來優化查詢。
簡單查詢處理管道(Simple Query Processing Pipeline)
這與上面討論的從邏輯查詢驗證到物理查詢處理器的管道相同。
連接優化(Join Optimizations)
在處理結束時,我們可以對整個復合查詢應用一些優化,例如將 join 轉換為 Semi Join。