分頁場景慢?MySQL的鍋!
圖片來自 Pexels
具體 sql 如下:
- select * from t_record where age > 10 offset 10000 limit 10
下表所示為表 t_record 結(jié)構(gòu),為了簡單起見,只列了我們將討論的字段,其余字段省略。

其中 t_record 是要查詢的數(shù)據(jù)表,表中一共有 50000 條記錄,age 字段上有索引,且 age>10 的記錄有 20000 條。
這條語句非常慢,基本達到了秒級延遲,在第二次請求有緩存之后,才變快。
在數(shù)據(jù)量這么少的情況下,走索引還這么慢,這完全不能接受,我就問我導(dǎo)師為什么,他反問“索引場景,MySQL 中獲得第 n 大的數(shù),時間復(fù)雜度是多少?”
答案的追尋
①小白直覺作答
當(dāng)時只知道 MySQL 索引使用的是樹,瞎猜了個 O(logn),心想二叉樹找一個節(jié)點不就是 O(logn) 么。自然而然,導(dǎo)師白了一眼,讓我自己去研究。
②繼續(xù)解答
想來想去...只能從底層結(jié)構(gòu)分析了,MySQL 的索引是 B+ 樹。仔細(xì)想一下,就會發(fā)現(xiàn)通過索引去找很別扭。
因為你不知道前 n 個數(shù)在其他子樹的分布情況,也沒有標(biāo)記讓你能快速選擇去哪個子樹尋找,我們無法利用 B+ 樹分支過濾的查找特性。
這下我明白導(dǎo)師的用意了——offset n,就是從第 n 大的數(shù)開始找!第 n 大的數(shù)沒法使用樹分支查找,所以 offset,也不能!
回到我們一開始的問題:
- select * from t_record where age > 10 offset 10000 limit 10
通過二級索引 age,我們只能找到對應(yīng)的起始節(jié)點,但無法通過樹結(jié)構(gòu)過濾掉 10000 個節(jié)點,再獲取 10 個節(jié)點,因為我們無法知道某個子樹下有多少數(shù)據(jù),就無法通過分支進行排除。
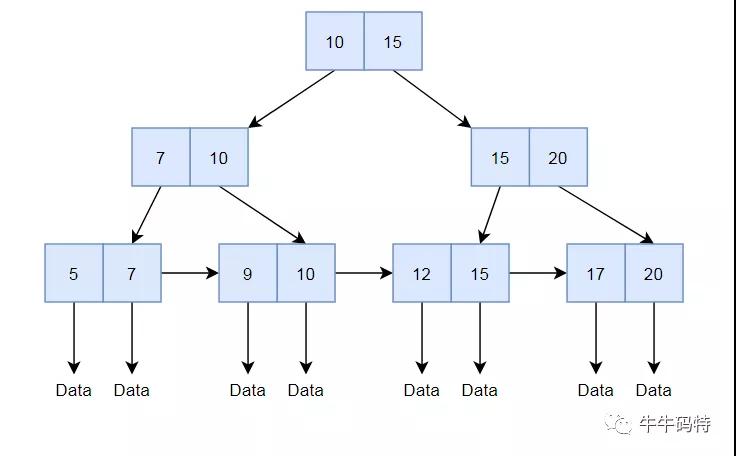
那該怎么辦呢?我們來仔細(xì)看下 B+ 樹的結(jié)構(gòu),它不光有常規(guī)樹的分支結(jié)構(gòu),底部還有一個由葉子節(jié)點組成鏈表。
顯而易見,最方便最快的方式,就是用樹定位到起始位置,然后直接通過葉子節(jié)點組成的鏈表,以 O(n) 的復(fù)雜度找到第 n 大的數(shù)據(jù)。
回到我們最初的問題,總結(jié)一下:問題的本質(zhì)其實就是讓 offset 找到第 n 大的數(shù),再通過鏈表遍歷,在數(shù)據(jù)量很大的情況下,確實會慢。
但是即使是 O(n),也不至于僅有幾萬數(shù)據(jù)就慢得令人發(fā)指。是不是還有其他影響因素?
③系統(tǒng)學(xué)習(xí)
我決定深入研究,帶著問題去查找了很多資料。
這里推薦兩本書,一本《MySQL 技術(shù)內(nèi)幕 InnoDB 存儲引擎》,通過它可以對 InnoDB 的底層機制,如 ACID、MVCC、索引實現(xiàn)、文件存儲,有更深的理解。
第二本是《高性能 MySQL》,這本書從使用層面著手,講得比較深入,并提到了很多設(shè)計和優(yōu)化的思路,對日常工作和學(xué)習(xí)都有很大的幫助。
兩本書相結(jié)合,反復(fù)領(lǐng)會,MySQL 就差不多能登堂入室了。
針對我們的問題,這里介紹兩個相關(guān)的概念:
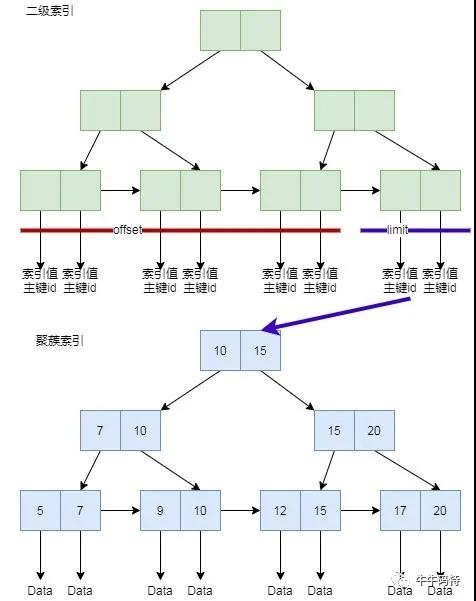
- 聚簇索引:包含主鍵索引和對應(yīng)的實際數(shù)據(jù),索引的葉子節(jié)點就是數(shù)據(jù)節(jié)點。
- 輔助索引:也叫二級節(jié)點,其葉子節(jié)點還是索引節(jié)點,并沒有完整的數(shù)據(jù),僅包含了索引值本身和主鍵 id,用主鍵 id 反查聚蔟索引才能獲取完整數(shù)據(jù)。
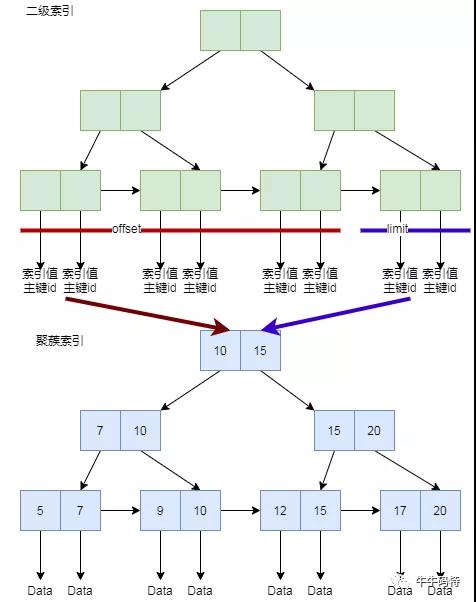
如圖所示,offset 會先從二級索引的鏈表順序找 10000 個節(jié)點。
注意,即使這 10000 個節(jié)點會被扔掉,MySQL 也會通過二級索引上的主鍵 id,去聚簇索引上查一遍數(shù)據(jù),這可是 10000 次隨機 IO,自然慢成哈士奇。
大家讀到這里可能會提出疑問,為什么 MySQL 會有這種行為?
這和它的優(yōu)化器有關(guān)系,也算是 MySQL 的一個大坑,時至今日,也沒有優(yōu)化。
問題的解決
針對分頁性能問題,《高性能 MySQL》中提到了兩種方案,讓我們一起來看看:
方案一:產(chǎn)品上繞過
根據(jù)業(yè)務(wù)實際需求,看能否替換為上一頁、下一頁的功能,這樣子就可以通過和上次返回數(shù)據(jù)進行比較,搭上樹分支過濾的便車。
特別在 iOS,Android 端,以前那種完全的分頁是不常見的。即轉(zhuǎn)換為如下 sql,第一次 last_id 傳 0 即可。
- select * from t_record where id > last_id limit 10
優(yōu)點:
- 能利用樹的分支結(jié)構(gòu),過濾掉第 n 個數(shù)之前的數(shù)據(jù)集。
- 直接通過主鍵索引查找,省略了二級索引查找過程,性能會更高。
缺點:
- 使用場景其實是受限制的。比如,如果是針對 age 字段有條件判斷,再分頁,那么使用主鍵 id 查找就不滿足需求。
- 把主鍵 id 暴露出去了,這個本身不應(yīng)該是業(yè)務(wù)層面關(guān)心的字段。
可以看到,該方案在我們的場景中,是不適用的。
因為我們還有 age 做過濾條件,此時用大于主鍵 id 的方式,雖然看起來變成順序 IO 了,但由于是根據(jù)主鍵 id 排列來尋找,而不是根據(jù)需要的 age 索引,所以會導(dǎo)致 MySQL 去查更多的數(shù)據(jù)。
雖然不符合我們案例的需求,但還是來看看優(yōu)缺點:
方案二:正面剛
這里先介紹一個概念:索引覆蓋。當(dāng)輔助索引查詢的數(shù)據(jù)只有主鍵 id 和輔助索引本身,那么就不必再去查聚簇索引。
思路如下:
- select * from t_record id in
- (select id from t_record where age > 10 offset 10000 limit 10)
這句話是說,先從條件查詢中,查找數(shù)據(jù)對應(yīng)的數(shù)據(jù)庫唯一 id 值,因為主鍵在輔助索引上就有,所以不用回歸到聚簇索引的磁盤上拉取。
如此以來,offset 部分均不需要去反查聚蔟索引,只有 limit 出來的 10 個主鍵 id 會去查詢聚簇索引,這樣只會十次隨機 IO。
在業(yè)務(wù)確實需要用分頁的情況下,使用該方案可以大幅度提高性能。通常能滿足性能要求。
優(yōu)點:
- 維持了分頁需求,適用所有 limit offset 場景,大大減少隨機 IO,提高了性能。
- 二級索引上,只查找 id,傳輸?shù)臄?shù)據(jù)包也變小。
缺點:二級索引上還是會走下面的鏈表來遍歷,這部分時間復(fù)雜度還是 O(n)。
方案選型
如果產(chǎn)品本身的需求,是分上下頁,且沒用其他過濾條件,可以用方案一。
方案二更具有普適性,同時由于合理分表的大小,一般也就 500w,二級索引上 O(n) 的查找損耗,通常也在可接受范圍。
總結(jié)
從一個小問題,往下深究,不僅可以深入理解這個問題,在面試和工作中大放異彩,同時在探索的過程中,自身的知識儲備也能得到拓展,是技術(shù)的一個提升捷徑。
作者:牛牛碼特
編輯:陶家龍
出處:轉(zhuǎn)載自公眾號牛牛碼特(ID:niuniu_mart)