和女朋友聊天:什么是Dubbo服務調用
本文轉載自微信公眾號「大魚仙人」,作者大魚仙人。轉載本文請聯系大魚仙人公眾號。
前言
之前有了服務的暴露和服務的引用了,服務提供者暴露出來服務了,服務消費者將其引用進來了,就差最后一步了,消費者和提供者之間的調用了,調用也就是真正的通信RPC過程,既然涉及到通信,就涉及到相應的客戶端和服務端之間的交互協議,約定,以及序列化和反序列化機制
先說兩邊的約定其實就是客戶端這邊需要帶著參數、參數類型,以及告訴服務端要調用的是哪個接口,這樣服務端就知道要調用的接口了,服務端就可以執行了
關于應用層的協議的交互一般有三種形式,分別是:固定長度形式、特殊字符間隔形式和header+body形式,Dubbo支持dubbo、rmi、hessian、http、webservice、thrift、redis等多種協議,但是Dubbo官網是推薦我們使用Dubbo協議的
Dubbo協議

這種看看就行了,咱們主要了解下相應的特點,Dubbo協議采用單一長連接和NIO異步通訊,適合于小數據量大并發的服務調用,以及服務消費者機器數遠大于服務提供者機器數的情況;不適合傳送大數據量的服務,比如傳文件,傳視頻等,除非請求量很低。
適用范圍:傳入傳出參數數據包較小(建議小于100K),消費者比提供者個數多,單一消費者無法壓滿提供者,盡量不要用dubbo協議傳輸大文件或超大字符串。
為什么要消費者比提供者個數多?
因dubbo協議采用單一長連接,假設網絡為千兆網卡(1024Mbit=128MByte),根據測試經驗數據每條連接最多只能壓滿7MByte(不同的環境可能不一樣,供參考),理論上1個服務提供者需要20個服務消費者才能壓滿網卡
為什么采用異步單一長連接?
因為服務的現狀大都是服務提供者少,通常只有幾臺機器,而服務的消費者多,可能整個網站都在訪問該服務,如果采用常規的服務,服務提供者很容易就被壓跨,通過單一連接,保證單一消費者不會壓死提供者,長連接,減少連接握手驗證等,并使用異步IO,復用線程池,防止出現網絡崩潰。
接口增加方法,對客戶端無影響,如果該方法不是客戶端需要的,客戶端不需要重新部署;輸入參數和結果集中增加屬性,對客戶端無影響,如果客戶端并不需要新屬性,不用重新部署
另外一個需要特別關注的點就是序列化,涉及到交互就會涉及到對象的傳遞,就會涉及到序列化,序列化就是內存中的數據對象轉換成二進制流才可以進行數據持久化和網絡傳輸,將數據對象轉換為二進制流的過程稱為對象的序列化(Serialization)。
反之,將二進制流恢復為數據對象的過程稱為反序列化(Deserialization)。序列化需要保留充分的信息以恢復數據對象,但是為了節約存儲空間和網絡帶寬,序列化后的二進制流又要盡可能小
常見的序列化方式有三種:Java原生序列化、Hessian序列化、Json序列化
Java原生序列化:Java類通過實現Serializable接口來實現該類對象的序列化,實現Serializable接口的類建議設置serialVersionUID字段值,如果不設置,那么每次運行時,編譯器會根據類的內部實現,包括類名、接口名、方法和屬性等來自動生成serialVersionUID。如果類的源代碼有修改,那么重新編譯后serial VersionUID的取值可能會發生變化。
因此實現Serializable接口的類一定要顯式地定義serialVersionUID屬性值。修改類時需要根據兼容性決定是否修改serialVersionUID值:
如果是兼容升級,請不要修改serialVersionUID字段,避免反序列化失敗。
如果是不兼容升級,需要修改serialVersionUID值,避免反序列化混亂。
Hessian序列化:它的實現機制是著重于數據,附帶簡單的類型信息的方法。就像Integer a = 1,hessian會序列化成I 1這樣的流,I表示int or Integer,1就是數據內容。而對于復雜對象,通過Java的反射機制,hessian把對象所有的屬性當成一個Map來序列化,而在序列化過程中,如果一個對象之前出現過,hessian會直接插入一個R index這樣的塊來表示一個引用位置,從而省去再次序列化和反序列化的時間
在父類、子類存在同名成員變量的情況下, Hessian 序列化時,先序列化子類 ,然后序列化父類,因此反序列化結果會導致子類同名成員變量被父類的值覆蓋。
Json序列化:是一種輕量級的數據交換格式。JSON 序列化就是將數據對象轉換為 JSON 字符串。在序列化過程中拋棄了類型信息,所以反序列化時只有提供類型信息才能準確地反序列化。相比前兩種方式,JSON 可讀性比較好,方便調試
序列化通常會通過網絡傳輸對象,而對象中往往有敏感數據,所以攻擊者可以巧妙地利用反序列化過程構造惡意代碼,使得程序在反序列化的過程中執行任意代碼。
Java 工程中廣泛使用的 Apache Commons Collections 、Jackson 、 fastjson 等都出現過反序列化漏洞。如何防范這種黑客攻擊呢?
有些對象的敏感屬性不需要進行序列化傳輸,可以加 transient 關鍵字,避免把此屬性信息轉化為序列化的二進制流。如果一定要傳遞對象的敏感屬性,可以使用對稱與非對稱加密方式獨立傳輸,再使用某個方法把屬性還原到對象中。總之吧,就是有一定的防范意識
我們接下來要分析的就是調用過程了,先看一下官網的流程圖
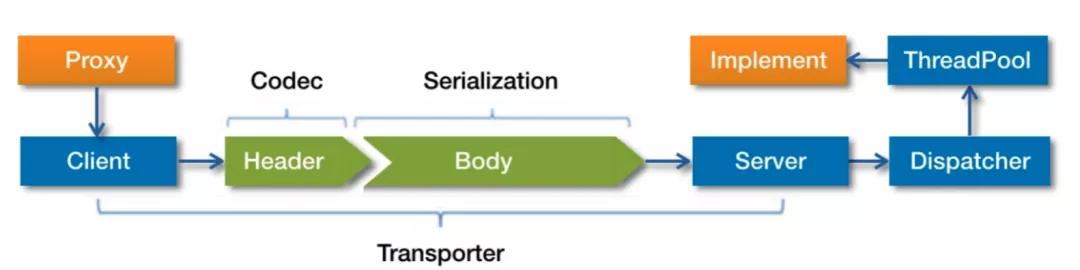
首先服務消費者通過代理對象 Proxy 發起遠程調用,接著通過網絡客戶端 Client 將編碼后的請求發送給服務提供方的網絡層上,也就是 Server。Server 在收到請求后,首先要做的事情是對數據包進行解碼。然后將解碼后的請求發送至分發器 Dispatcher,再由分發器將請求派發到指定的線程池上,最后由線程池調用具體的服務。這就是一個遠程調用請求的發送與接收過程。
整個調用鏈路大概就是分為三個步驟,我們按照這幾個步驟來分析下:
1、消費者發起調用請求
2、提供者接收處理請求
3、消費者處理響應
消費者發起調用請求
消費者調用 Invoker 時,實際上調用的是一個由 Java 動態代理生成的代理對象。該代理對象經過 Cluster 層的路由與負載均衡,找到一個服務節點,將調用參數封裝成 Request 形式,通過 Netty Client 將數據進行序列化,通過 Netty 發送給對應的服務提供者。
調用具體的接口會調用生成的代理類,而代理類會生成一個RpcInvocation對象調用MockClusterInvoke#invoke 方法,包括方法名、參數類和參數值,其實實際上最終調用的是AbstractClusterInvoker#invoker方法
入口在InvocationHandler這個家伙,這個類其中的invoke會得到調用結果,并把結果返回給調用方
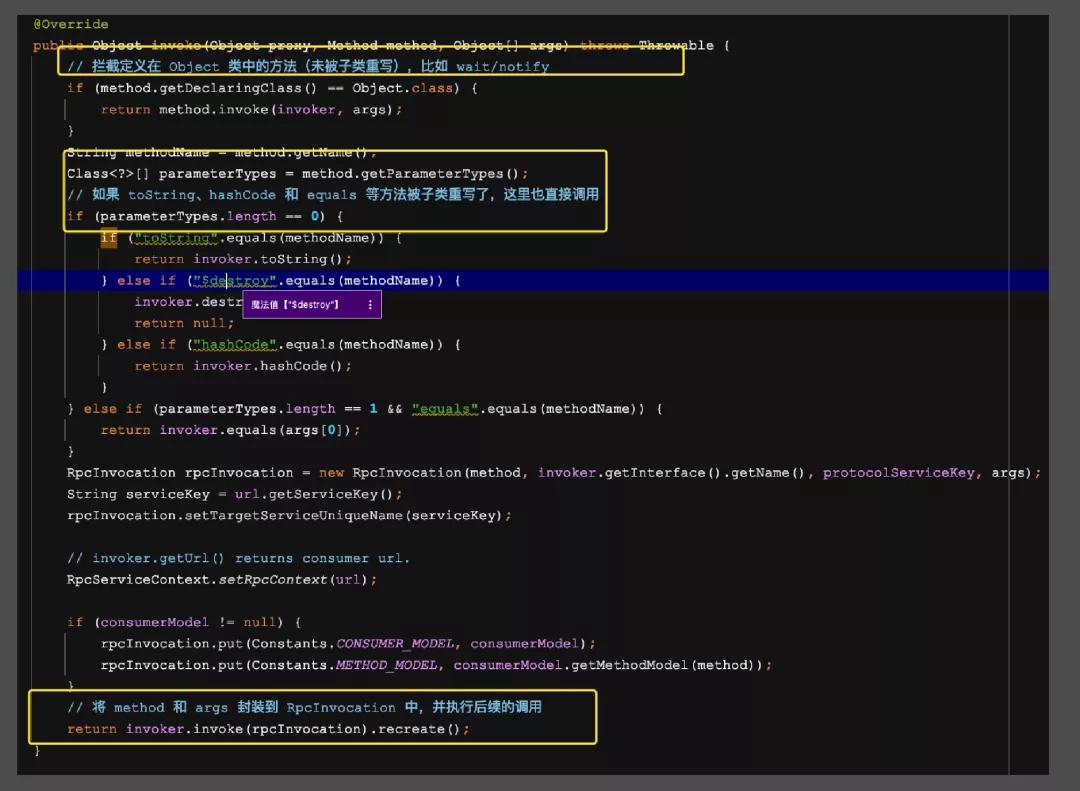
InvokerInvocationHandler 中的 invoker 成員變量類型為 MockClusterInvoker,MockClusterInvoker 內部封裝了服務降級邏輯。下面簡單看一下:

服務降級就簡單看看就行了先,當然這也不是服務調用的重點
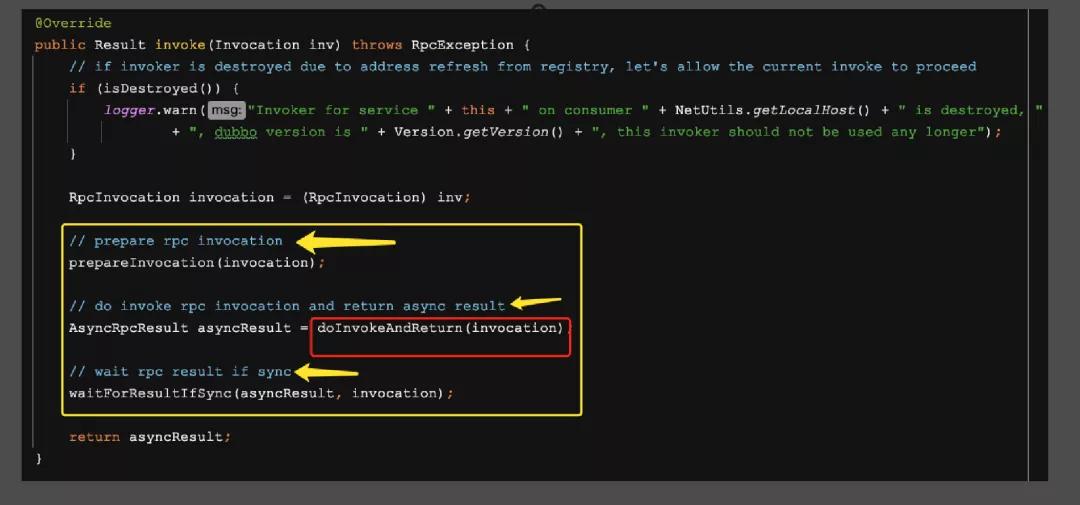
上面這塊代碼是AbstractInvoker類中的invoke方法,看注釋分別是準備RPC的調用列表,然后是真正的調用并且返回結果,如果是異步的,則等待結果返回;
重點在第二步的doInvokeAndReturn中,點進去看到實際執行的是doInvoke方法,而這個方法在這個類中又是個抽象方法,需要由子類實現,下面到 DubboInvoker 中看一下。
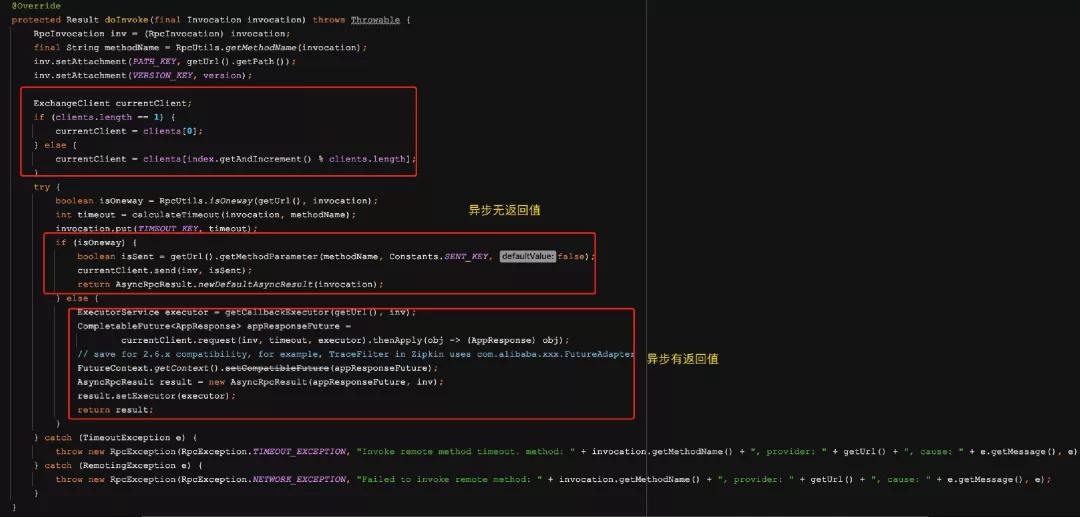
上面的代碼包含了 Dubbo 對同步和異步調用的處理邏輯,搞懂了上面的代碼,會對 Dubbo 的同步和異步調用方式有更深入的了解。Dubbo 實現同步和異步調用比較關鍵的一點就在于由誰調用 CompletableFuture 的 get 方法。同步調用模式下,由框架自身調用 CompletableFuture 的 get 方法。異步調用模式下,則由用戶調用該方法。
當服務消費者還未接收到調用結果時,用戶線程調用 get 方法會被阻塞住。同步調用模式下,框架獲得 DefaultFuture 對象后,會立即調用 get 方法進行等待。而異步模式下則是將該對象封裝到 FutureAdapter 實例中,并將 FutureAdapter 實例設置到 RpcContext 中,供用戶使用
接下來我們看一個客戶端HeaderExchangeClient,HeaderExchangeClient 中很多方法只有一行代碼,即調用 HeaderExchangeChannel 對象的同簽名方法。那 HeaderExchangeClient 有什么用處呢?答案是封裝了一些關于心跳檢測的邏輯
來到了其內部的屬性HeaderExchangeChannel這個類之后,大家終于看到了 Request 語義了,上面的方法首先定義了一個 Request 對象,然后再將該對象傳給 NettyClient 的 send 方法,進行后續的調用
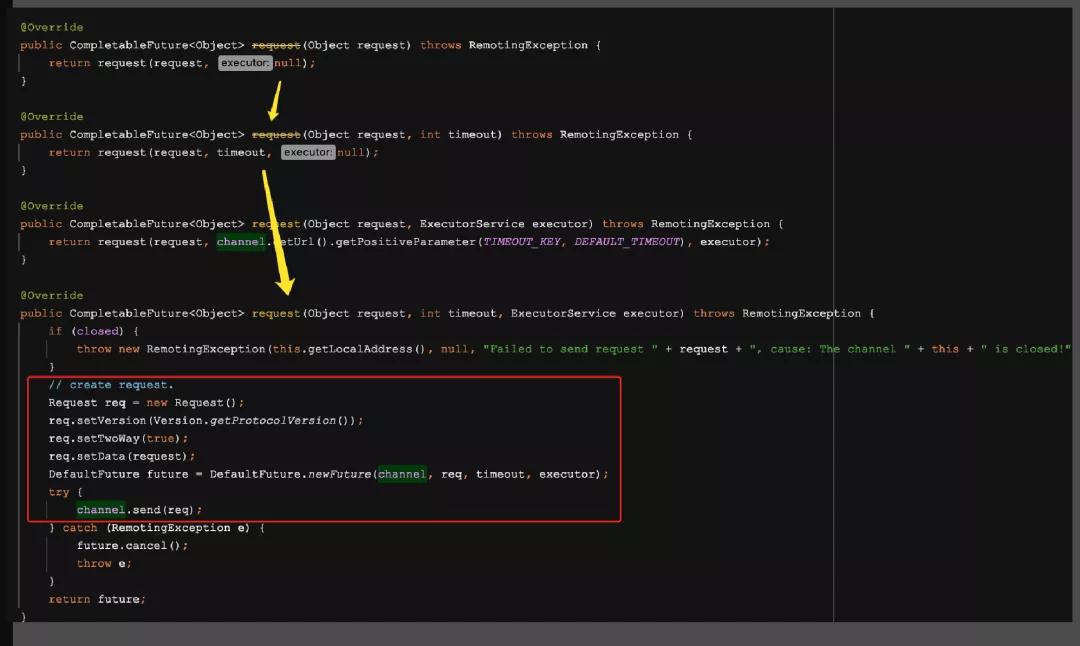
需要說明的是,NettyClient 中并未實現 send 方法,該方法繼承自父類 AbstractPeer,看其子類AbstractClient類中的send實現
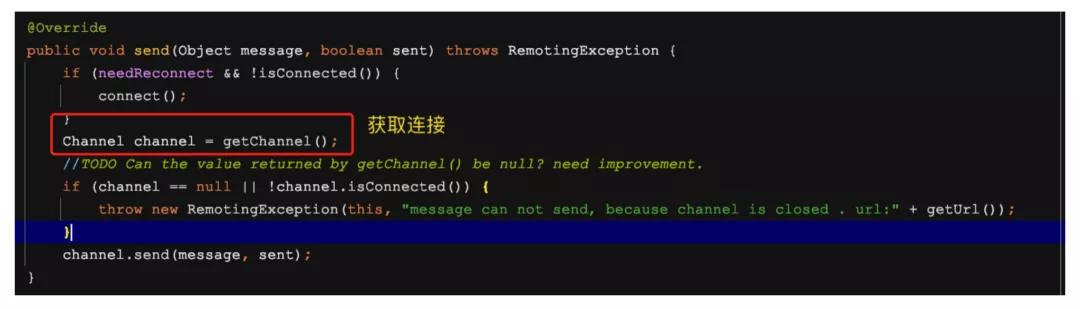
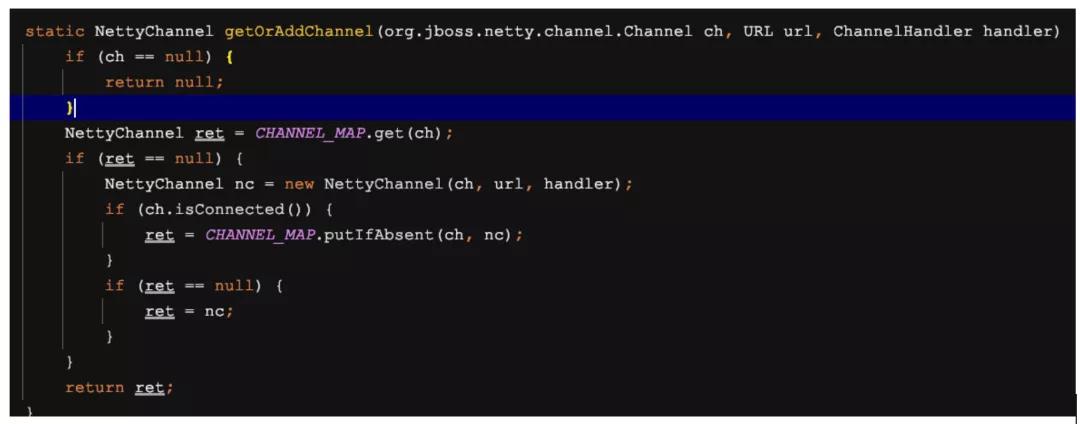
然后就是NettyChannel的send發送了
提供者接收處理請求
默認情況下 Dubbo 使用 Netty 作為底層的通信框架。Netty 檢測到有數據入站后,首先會通過解碼器對數據進行解碼,并將解碼后的數據包裝成一個request對象傳遞給下一個入站處理器的指定方法。
解碼器將數據包解析成 Request 對象后,NettyHandler 的 messageReceived 方法緊接著會收到這個對象,并將這個對象繼續向下傳遞。
這期間該對象會被依次傳遞給 NettyServer、MultiMessageHandler、HeartbeatHandler 以及 AllChannelHandler。最后由 AllChannelHandler 將該對象封裝到 Runnable 實現類對象中,并將 Runnable 放入線程池中執行后續的調用邏輯
我們了解一下Dubbo的線程派發模型:
背景呢就是如果一個處理事件很快執行完,此時可以直接在IO線程上執行完就行了,但是如果處理比較耗時呢,比如邏輯可能會發起DB查詢或者HTTP請求,此時這種就不應該讓事件處理邏輯在IO線程上執行,而是直接派發到線程池中去執行
原因很簡單,IO線程主要是用來接收請求,如果IO被占滿被阻塞,就不能接收新的請求了
舉個例子,大公司業務數量大,核心部門A主要是負責分發業務的處理,會有其余部門分別處理,一些很簡答的業務處理甚至還沒有分發任務的耗時時間長,所以核心部門就直接處理了,你想啊,發一個任務一秒,如果處理這個業務只需要0.5秒,那就沒必要去發這個業務了,直接自己處理了就可以了
于是就有了這個線程派發模型

Dispatcher就是線程派發器,但是它本身不具有線程派發能力,它的職責是創建具有線程派發能力的ChannelHandler,比如 AllChannelHandler、MessageOnlyChannelHandler 和 ExecutionChannelHandler 等,Dubbo 支持 5 種不同的線程派發策略

默認配置下,Dubbo 使用 all 派發策略,即將所有的消息都派發到線程池中
處理的邏輯我覺得沒什么必要細細分析了,無非就是封裝成Runnable交給handler分發的線程來處理,然后把結果封裝成response,返回該對象
消費者處理響應
響應數據解碼完成后,Dubbo 會將響應對象派發到線程池上。要注意的是,線程池中的線程并非用戶的調用線程,所以要想辦法將響應對象從線程池線程傳遞到用戶線程上。
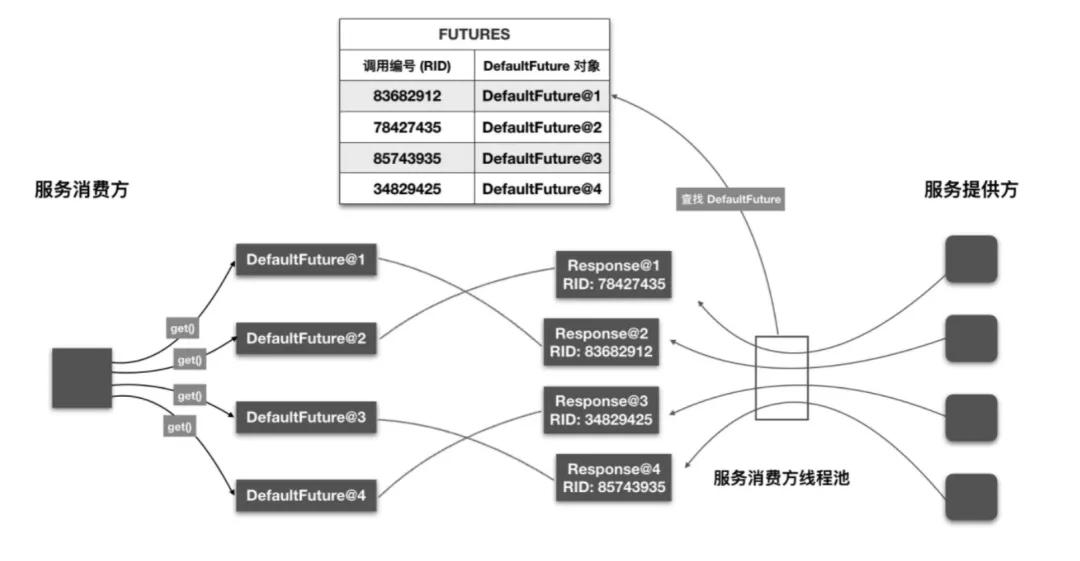
一般情況下,服務消費方會并發調用多個服務,每個用戶線程發送請求后,會調用不同 DefaultFuture 對象的 get 方法進行等待。
一段時間后,服務消費方的線程池會收到多個響應對象。這個時候要考慮一個問題,如何將每個響應對象傳遞給相應的 DefaultFuture 對象,且不出錯
消費者接收到提供者發來的響應,解碼后投入到線程分發器中,置入線程池。
放到線程池的是一個 DefaultFuture 對象,其中包含了響應結果。在前面第一步發起調用請求的過程中,負載均衡之后的調用就是通過 RpcInvocation 代理對象使用 DefaultFuture.get() 方法異步獲取響應內容,這也是 RPC 遠程調用從同步轉為異步的方式。
答案是通過調用編號。DefaultFuture 被創建時,會要求傳入一個 Request 對象。此時 DefaultFuture 可從 Request 對象中獲取調用編號,并將 <調用編號, DefaultFuture 對象> 映射關系存入到靜態 Map 中,即 FUTURES
線程池中的線程在收到 Response 對象后,會根據 Response 對象中的調用編號到 FUTURES 集合中取出相應的 DefaultFuture 對象,然后再將 Response 對象設置到 DefaultFuture 對象中。
最后再喚醒用戶線程,這樣用戶線程即可從 DefaultFuture 對象中獲取調用結果了