













漫話:如何給女朋友解釋什么是"大案牘術"?
作者:漫話編程
微信公眾號id:mhcoding

聽說最近《長安十二時辰》比較火,于是趁著一個周末趕緊補一補劇。相信很多人都對其中的"大案牘術"比較感興趣,靖安司說"大案牘術"選中了張小敬。
看到這里,我以為女朋友會問我:什么是大案牘術?
萬萬沒想到,女朋友并沒有這么問,而是說了一句:四字弟弟好帥啊~!





大案牘術
大案牘術,并不是歷史上真實存在的,而是《長安十二時辰》的作者馬伯庸自創的。
大案牘術的發明者是徐賓,只是靖安司一個八品主事,因為其出色的記憶力,以及對術數的刻苦鉆研,研究出了一套以檔案數據為基礎的處理事務的方法,即為“大案牘術”,無論是破案調查找人,甚至預言未來,都可以做到。
《長安十二時辰》原著中有兩處關于大案牘術的描述:
他做不良帥那么多年,破案無數,深知很多事情并不需要搜考秘聞,真相就藏在人人可見的文卷之中,就看你能不能找出來——此所謂’大案牘’之術。李泌特意在靖安司集中一批精干官吏,專事檢校查閱,正適合應付眼下這局面,可見此人卓識。
憑借大案牘之術和祆教的戶籍配合,他迅速地找出一個可疑之人。此人叫作龍波,來自龜茲,開元二十年來京落為市籍,同年拜入祆教,就住在懷遠坊內,一直單身。供奉記錄顯示他最近半年來,給祆祠的供奉陡增,為此還特受褒獎。天寶二載底市籍有過一次清冊重造,但龍波的戶口仍是開元二十年。有一位戶部老吏敏銳地注意到這個小紕漏。戶籍上要寫清相貌,若是舊冊不造,則有可能冒名頂替。
其實,所謂"大案牘術",就是我們今天所說的大數據。


大數據
大數據,Big Data,是指無法在一定時間內用常規軟件工具對其內容進行抓取、管理和處理的數據集合。大數據具有4個基本特征:
- 數據體量巨大。百度資料表明,其新首頁導航每天需要提供的數據超過1.5PB(1PB=1024TB),這些數據如果打印出來將超過5千億張A4紙。有資料證實,到目前為止,人類生產的所有印刷材料的數據量僅為200PB。
- 數據類型多樣。現在的數據類型不僅是文本形式,更多的是圖片、視頻、音頻、地理位置信息等多類型的數據,個性化數據占絕對多數。
- 處理速度快。數據處理遵循“1秒定律”,可從各種類型的數據中快速獲得高價值的信息。
- 價值密度低。以視頻為例,一小時的視頻,在不間斷的監控過程中,可能有用的數據僅僅只有一兩秒。
現如今,大數據是一個很火的詞匯,但是所有的理解也都不盡相同,對于不同的人,大數據有著不同的意思。
對于廣大用戶來說,大數據就是被采集到的各種信息。簡單來說,指的就是用戶的一些個人信息,如姓名、手機號、職業等。再深層次一些可能是用戶的人際關系、交易記錄、用戶的行為記錄等。
對于一些從事大數據相關的技術人員來說,大數據就是數據采集、數據存取、數據處理、統計分析、數據挖掘等。而做這些的目的主要是通過大量數據,進行預測分析,來實現商業價值。
就像"大案牘術"一樣,徐賓可以通過一些案牘中的記錄,進行破案找人、預測未來,如今的大數據更是有著廣泛的應用。
無論是各行各業,一旦有了大量數據,通過對不同來源數據的管理、處理、分析與優化,將結果反饋到上述應用中,將創造出巨大的經濟和社會價值。大數據利用已經逐漸成為提高核心競爭力的關鍵因素,各行各業的決策正在從“業務驅動” 轉變“數據驅動”。在大數據時代,可通過實時監測、跟蹤研究對象在互聯網上產生的海量行為數據,進行挖掘分析,揭示出規律性的東西,提出研究結論和對策。
比如:
銀行有了大數據,可以提前識別風險,降低經濟損失。
電商網站有了大數據,可以分析用戶行為,推薦適合商品。
醫院有了大數據,可以對各種疑難病癥進行分析并治愈。
制造業有了大數據,可以提前預知銷量,動態調整生產力。
公安系統有了大數據,可以更好的維護社會穩定。


大數據的處理
我們通過《長安十二時辰》的影視劇以及原著我們知道,大案牘術之所以可以進行斷案和預知未來主要是有幾個基本前提:
1、需要有很多錄入吏將各地發生的事件詳盡的記錄下來。
2、錄入吏將自己記錄的信息進行整理成案牘,提交給靖安司。
3、靖安司將這些案牘分門別類的保存在案牘庫中。
4、需要查詢某個事件或人物時,需要各個文官們一起翻閱案牘,進行信息檢索
5、最后根據這些數據進行整理、分析得出結果。

以上環節,其實也是當今的大數據處理的主要流程:包括數據收集、數據預處理、數據存儲、數據處理與分析、數據展示/數據可視化、數據應用等環節。
整個處理流程也可以精簡概括為四步,分別是數據采集存儲、數據預處理、數據統計分析,最后是數據挖掘。
在《長安十二時辰》中,徐賓說:案牘上的數字,是百姓的生計、生涯,更是大唐的未來。
這案牘上的數字,其實指的就是大數據中很重要的數據質量。數據質量貫穿于整個大數據流程,每一個數據處理環節都會對大數據質量產生影響作用。
這里針對上面提到的大數據處理流程,簡單介紹下其中比較重要的幾個流程。
數據采集存儲
數據的采集是指利用多個數據庫來接收發自客戶端的數據,并且用戶可以通過這些數據庫來進行簡單的查詢和處理工作。比如,電商會使用傳統的關系型數據庫MySQL和Oracle等來存儲每一筆事務數據,除此之外,Redis和MongoDB這樣的NoSQL數據庫也常用于數據的采集。
數據預處理
雖然采集端本身會有很多數據庫,但是如果要對這些海量數據進行有效的分析,還是應該將這些來自前端的數據導入到一個集中的大型分布式數據庫,或者分布式存儲集群,并且可以在導入基礎上做一些簡單的清洗和預處理工作。
數據統計分析
統計與分析主要利用分布式數據庫,或者分布式計算集群來對存儲于其內的海量數據進行普通的分析和分類匯總等,以滿足大多數常見的分析需求。
數據挖掘
與前面統計和分析過程不同的是,數據挖掘一般沒有什么預先設定好的主題,主要是在現有數據上面進行基于各種算法的計算,從而起到預測(Predict)的效果,從而實現一些高級別數據分析的需求。


大數據處理相關技術
大數據技術的體系龐大且復雜,基礎的技術包含數據的采集、數據預處理、分布式存儲、NoSQL數據庫、數據倉庫、機器學習、并行計算、可視化等各種技術范疇和不同的技術層面
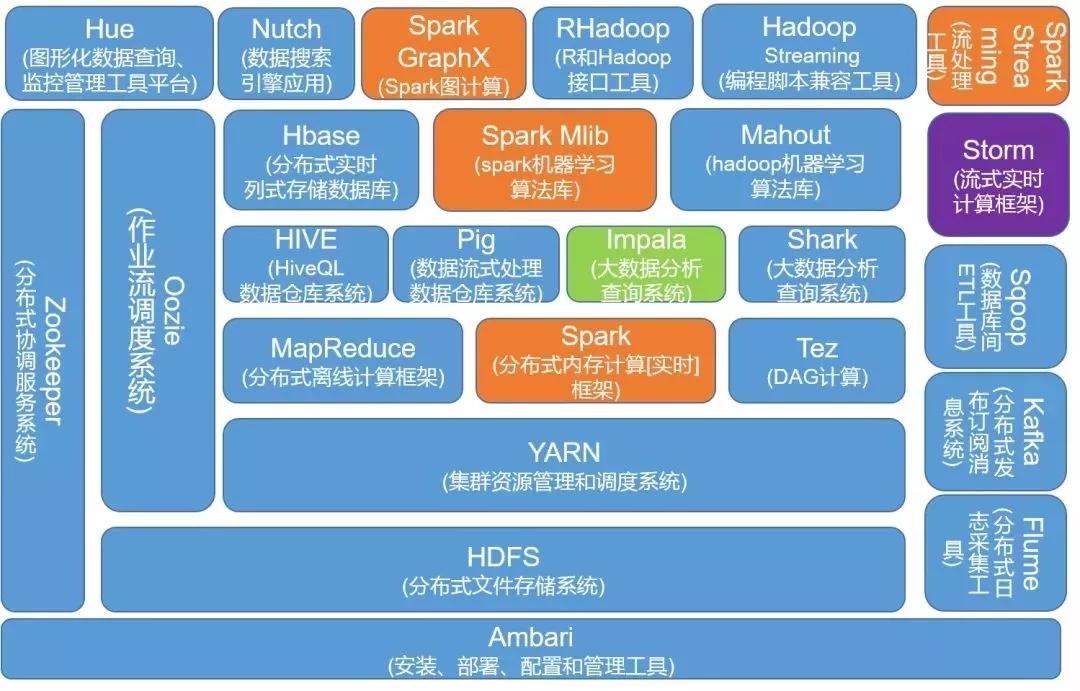
文件存儲:Hadoop HDFS、Tachyon、KFS
離線計算:Hadoop MapReduce、Spark
流式、實時計算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL數據庫:HBase、Redis、MongoDB
資源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系統:Kafka、StormMQ、ZeroMQ、RabbitMQ
查詢分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式協調服務:Zookeeper
集群管理與監控:Ambari、Ganglia、Nagios、Cloudera Manager
數據挖掘、機器學習:Mahout、Spark MLLib
數據同步:Sqoop任務調度:Oozie
以上這些工具,是和大數據有關的一些框架技術,可以看到每一個類型中都有多種技術可以實現,所以在做技術選型的時候,需要根據自己的業務實際情況選擇最適合自己的框架。





















