關于自然語言處理之One Hot模型
本文轉載自微信公眾號「python與大數據分析」,作者 一只小小鳥鳥 。轉載本文請聯系python與大數據分析公眾號。
最近工作實在有點忙,前陣子關于梯度和導數的事情把人折騰的夠嗆,數學學不好,搞機器學習和神經網絡真是頭疼;想轉到應用層面輕松一下,想到了自然語言處理,one hot模型是基礎也是入門,看起來很簡單的一個列表轉矩陣、詞典的功能,想著手工實現一下,結果看了一下CountVectorizer,發現不是那么回事兒,還是放棄了。
顧名思義,單熱表示從一個零向量開始,如果單詞出現在句子或文檔中,則將向量中的相應條目設置為 1。
對句子進行標記,忽略標點符號,并將所有的單詞都用小寫字母表示,就會得到一個大小為 8 的詞匯表: {time, fruit, flies, like, a, an, arrow, banana} 。所以,我們可以用一個八維的單熱向量來表示每個單詞。在本書中,我們使用 1[w] 表示標記/單詞 w 的單熱表示。
對于短語、句子或文檔,壓縮的單熱表示僅僅是其組成詞的邏輯或的單熱表示。短語 like a banana 的單熱表示將是一個 3×8 矩陣,其中的列是 8 維的單熱向量。通常還會看到“折疊”或二進制編碼,其中文本/短語由詞匯表長度的向量表示,用 0 和 1 表示單詞的缺失或存在。like a banana 的二進制編碼是: [0,0,0,1,1,0,0,1] 。
- from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
- import seaborn as sns
- import matplotlib.pyplot as plt
- import jieba
- import jieba.analyse
- # 單熱表示從一個零向量開始,如果單詞出現在句子或文檔中,則將向量中的相應條目設置為 1。
- # 英文的處理和展示
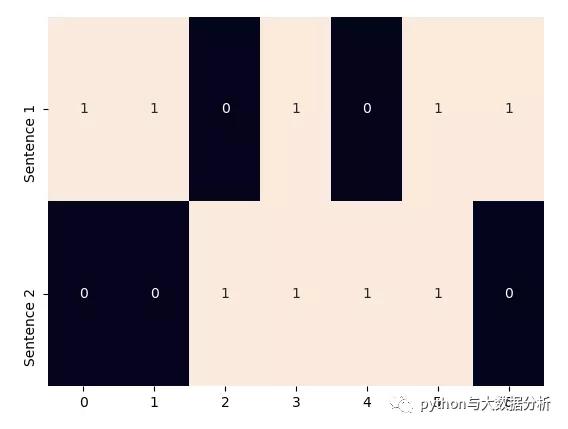
- corpus = ['Time flies flies like an arrow.', 'Fruit flies like a banana.']
- one_hot_vectorizer = CountVectorizer(binary=True)
- one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
- sns.heatmap(one_hot, annot=True, cbar=False, yticklabels=['Sentence 1', 'Sentence 2'])
- plt.show()
- # 中文的處理和展示
- # 獲取停用詞列表
- def get_stopwords_list(stopwordfile):
- stopwords = [line.strip() for line in open(stopwordfile, encoding='UTF-8').readlines()]
- return stopwords
- # 移除停用詞
- def movestopwords(sentence):
- stopwords = get_stopwords_list('stopwords.txt') # 這里加載停用詞的路徑
- santi_words = [x for x in sentence if len(x) > 1 and x not in stopwords]
- return santi_words
- # 語料
- corpus = ["小明碩士畢業于中國科學院計算所,后在日本京都大學深造。",
- "小王本科在清華大學,后在南京計算所工作和深造,后在日本早稻田大學深造",
- "小李本科在清華大學,碩士畢業于中國科學院計算所,博士在南京大學"]
- newcorpus = []
- for str in corpus:
- orgwordlist = jieba.lcut(str) # jieba分詞
- wordlist = movestopwords(orgwordlist) # 移除停用詞
- newword = " ".join(wordlist) # 按照語料庫要求進行空格分隔
- newcorpus.append(newword) # 按照語料庫要求轉換成列表
- # newcorpus
- # ['小明 碩士 畢業 中國科學院 計算所 日本京都大學 深造',
- # '小王 本科 清華大學 南京 計算所 工作 深造 日本早稻田大學 深造',
- # '小李 本科 清華大學 碩士 畢業 中國科學院 計算所 博士 南京大學']
- one_hot_vectorizer = CountVectorizer(binary=True) # 創建詞袋數據結構
- one_hot = one_hot_vectorizer.fit_transform(newcorpus).toarray() # 轉換語料,并矩陣化
- # 下面為熱詞的輸出結果
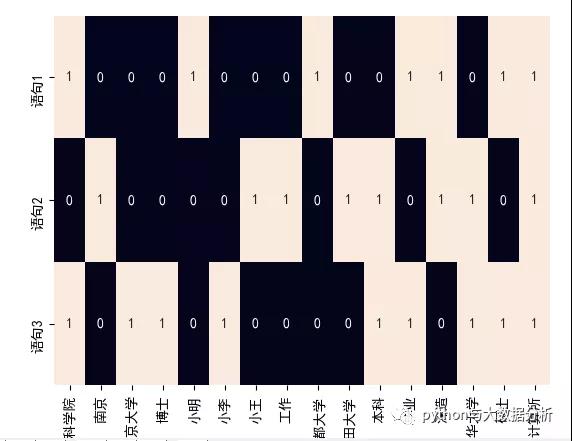
- # one_hot_vectorizer.vocabulary_
- # {'小明': 4, '碩士': 14, '畢業': 11, '中國科學院': 0, '計算所': 15, '日本京都大學': 8, '深造': 12, '小王': 6, '本科': 10, '清華大學': 13, '南京': 1, '工作': 7, '日本早稻田大學': 9, '小李': 5, '博士': 3, '南京大學': 2}
- # one_hot_vectorizer.get_feature_names()
- # ['中國科學院', '南京', '南京大學', '博士', '小明', '小李', '小王', '工作', '日本京都大學', '日本早稻田大學', '本科', '畢業', '深造', '清華大學', '碩士', '計算所']
- # one_hot
- # [[1 0 0 0 1 0 0 0 1 0 0 1 1 0 1 1]
- # [0 1 0 0 0 0 1 1 0 1 1 0 1 1 0 1]
- # [1 0 1 1 0 1 0 0 0 0 1 1 0 1 1 1]]
- sns.set_style({'font.sans-serif': ['SimHei', 'Arial']})
- sns.heatmap(one_hot, annot=True, cbar=False, xticklabels=one_hot_vectorizer.get_feature_names(),
- yticklabels=['語句1', '語句2', '語句3'])
- plt.show()
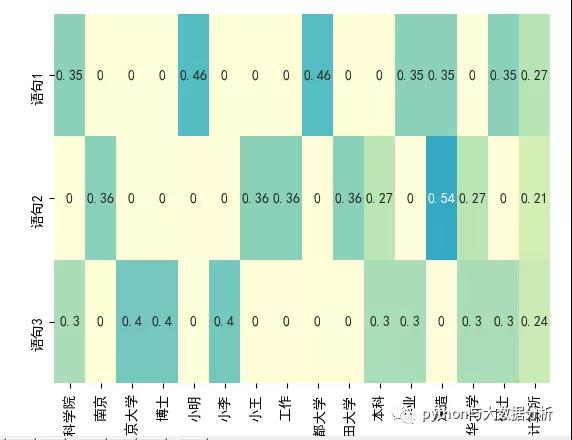
IDF 表示懲罰常見的符號,并獎勵向量表示中的罕見符號。符號 w 的 IDF(w) 對語料庫的定義為其中 n[w] 是包含單詞 w 的文檔數量, N 是文檔總數。TF-IDF 分數就是 TF(w) * IDF(w) 的乘積。首先,請注意在所有文檔(例如, n[w] = N ), IDF(w) 為 0, TF-IDF 得分為 0,完全懲罰了這一項。其次,如果一個術語很少出現(可能只出現在一個文檔中),那么 IDF 就是 log n 的最大值
- tfidf_vectorizer = TfidfVectorizer() # 創建詞袋數據結構
- tfidf = tfidf_vectorizer.fit_transform(newcorpus).toarray() # 轉換語料,并矩陣化
- # 下面為熱詞的輸出結果
- # tfidf_vectorizer.vocabulary_
- # '小明': 4, '碩士': 14, '畢業': 11, '中國科學院': 0, '計算所': 15, '日本京都大學': 8, '深造': 12, '小王': 6, '本科': 10, '清華大學': 13, '南京': 1, '工作': 7, '日本早稻田大學': 9, '小李': 5, '博士': 3, '南京大學': 2}
- # tfidf_vectorizer.get_feature_names()
- # ['中國科學院', '南京', '南京大學', '博士', '小明', '小李', '小王', '工作', '日本京都大學', '日本早稻田大學', '本科', '畢業', '深造', '清華大學', '碩士', '計算所']
- # tfidf
- # [[0.35221512 0. 0. 0. 0.46312056 0. 0. 0. 0.46312056 0. 0. 0.35221512 0.35221512 0. 0.35221512 0.27352646]
- # [0. 0.35761701 0. 0. 0. 0. 0.35761701 0.35761701 0. 0.35761701 0.27197695 0. 0.54395391 0.27197695 0. 0.21121437]
- # [0.30443385 0. 0.40029393 0.40029393 0. 0.40029393 0. 0. 0. 0. 0.30443385 0.30443385 0. 0.30443385 0.30443385 0.23642005]]
- sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=tfidf_vectorizer.get_feature_names(),
- yticklabels=['語句1', '語句2', '語句3'], vmin=0, vmax=1, cm