













基于博弈論的大規模數據分析
現代 AI 系統可以像勤奮的學生準備考試一樣,去處理諸如識別圖像中的對象以及預測蛋白質 3D 結構之類的任務。通過大量示例問題訓練,這類系統可以逐漸降低錯誤,直至取得成功。
但這是一項需要獨自完成的工作,并且只是已知的學習形式之一。學習也需要與他人互動和交流。一個單獨的個體很難自行解決極其復雜的問題。通過讓問題解決方案具有類游戲的特質,DeepMind 之前在研究中已經訓練了 AI 智能體 (Agent) 來玩奪旗賽并在《星際爭霸》中達到大師級水平。因此,我們希望了解基于,以博弈論為模型的視角能否幫助解決其他基本的機器學習問題。
最近,在 2021 年 ICLR 上,我們發表了論文 “EigenGame:將 PCA 作為納什均衡 (EigenGame: PCA as a Nash Equilibrium)”,并獲得杰出論文獎。我們的研究探索了一種解決舊問題的新方法:我們將主成分分析 (PCA)(一種特征值問題)重新表述為競爭性的多智能體博弈游戲,即 EigenGame。PCA 通常表現為優化問題(或單智能體問題);但是,我們發現多智能體視角可使我們利用最新的計算資源生成新的數據分析和算法。這使得我們能夠將主成分分析擴展到以往計算密集型的大規模數據集,并為未來的研究探索提供一種替代方法。
將 PCA 作為納什均衡
PCA (Principal component analysis) 最早于 20 世紀初期提出,之后便成為了分析高維數據結構長期使用的一項技術。現在,這種方法已普遍用作數據處理流水線中的第一步,簡化了集群和可視化數據。同時,它也是學習低維表示以進行回歸和分類的實用工具。自 PCA 提出后的一個多世紀,我們仍然有充分的理由對其進行學習和研究。
首先,數據最初是由人工用紙筆記錄,而現在則存儲在像倉庫一樣大的數據中心。結果,這種熟悉的分析方式成為了計算瓶頸。研究人員已經探索了隨機算法和其他方向來改善 PCA 的擴展方式,但是我們發現,這些方法難以擴展到大規模數據集,因為它們無法完全利用計算領域以深度學習為中心的最新進展:即訪問多個并行 GPU 或 TPU。
其次,PCA 與許多重要的機器學習和工程問題都需要使用共同的解決方案,即奇異值分解 (SVD)。通過以正確的方式解決 PCA 問題,我們的數據分析和算法將更廣泛地應用于機器學習樹的各個分支。
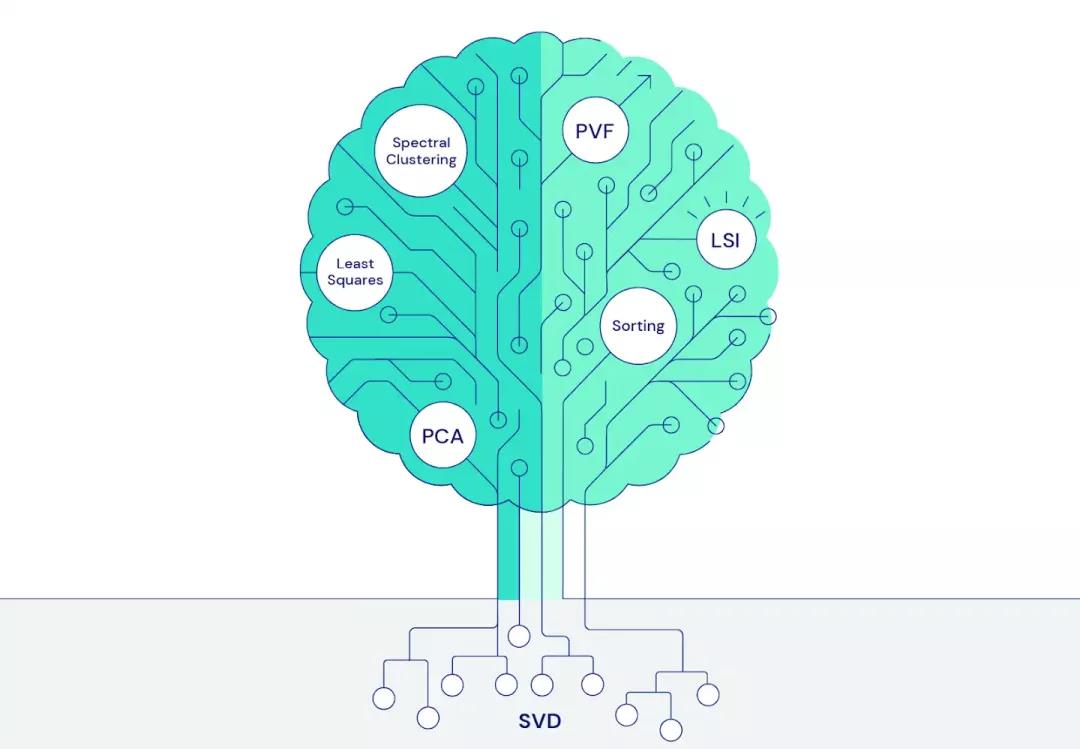
與任何棋盤游戲一樣,為了將 PCA 重新設計為游戲,我們需要制定一套規則和目標讓玩家遵循。設計此類游戲的方式有很多種;但是,重要的設計理念源自 PCA 本身:最佳解決方案由特征向量組成,而特征向量捕獲數據中的重要方差并且彼此正交。
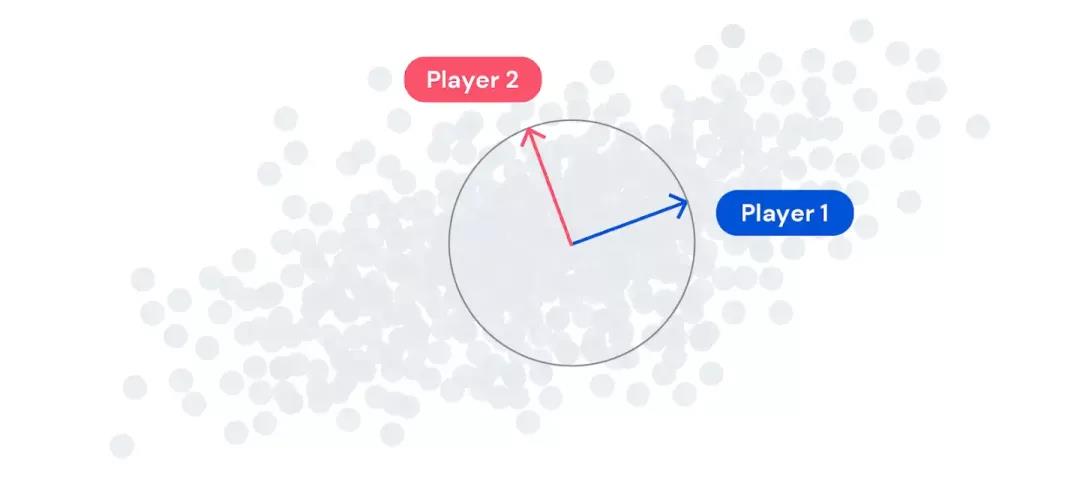
在 EigenGame 中,每個玩家都控制一個特征向量。玩家通過解釋數據中的方差來提高得分,但如果他們與其他玩家過于相似,則會受到懲罰。我們還建立了一個層次結構:玩家 1 只關注最大化方差,而其他玩家則還必須關注如何最小化與層級結構中高于自己的玩家的相似度。這種獎勵和懲罰的組合決定了每個玩家的效用。
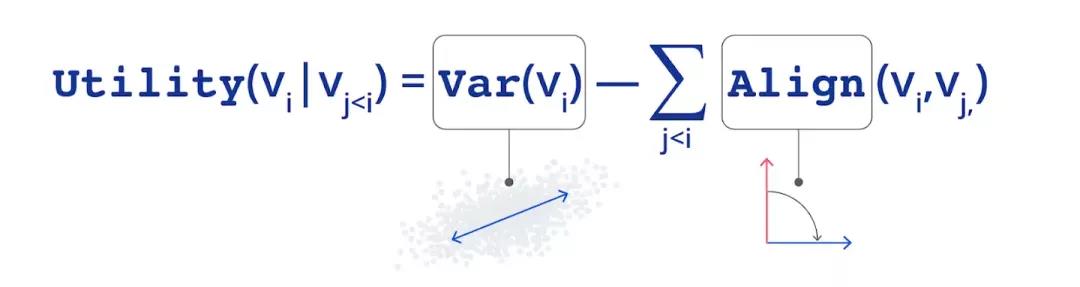
通過經適當設計的方差 Var 和對齊 Align 項,我們證明了:
- 如果所有的玩家都表現最優,他們則一起實現了游戲的納什均衡點,而這就是 PCA 算法的解決方案。
- 如果每個玩家單獨且同步使用梯度上升法來最大化其效用,則可實現該目標。
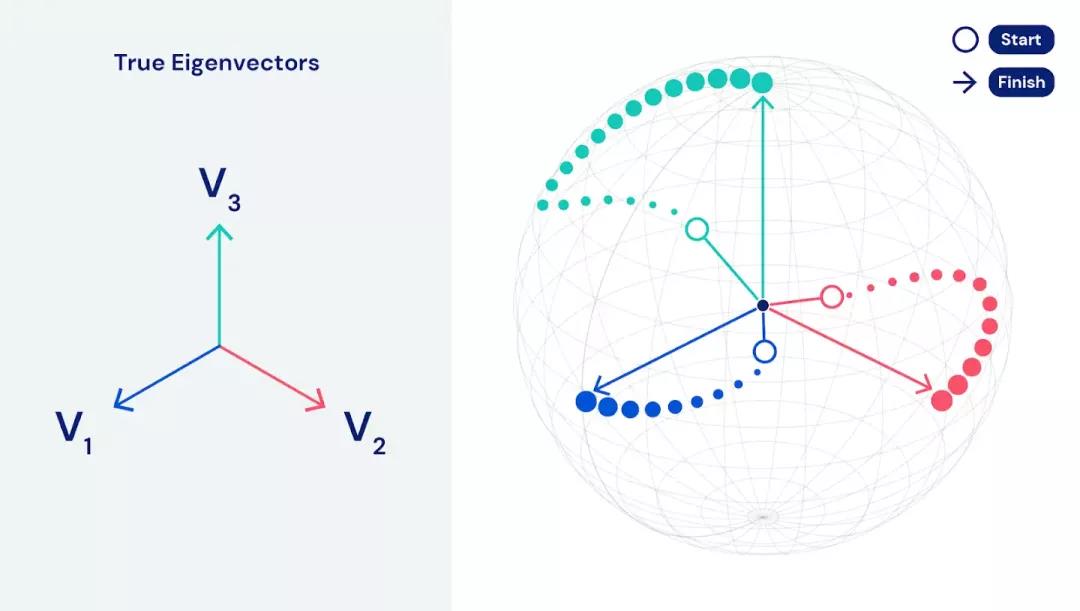
這種同步上升的獨立性特別重要,因為它允許將計算分布在數十個 Google Cloud TPU 上,從而實現數據和模型并行。這使我們的算法適應真正的大規模數據成為了可能。EigenGame 可以在數小時內找到包含數百萬個特征或數十億行的上百兆字節數據集的主要成分。
效用、更新及兩者之間的一切
通過從多智能體角度審視 PCA,我們能夠提出可擴展的算法和新穎的分析方法。我們還發現了與赫布學習 (Hebbian Learning) 存在的驚人聯系,或者也可以說神經元在學習時如何調整適應。在 EigenGame 中,每個最大化效用的玩家都會產生更新方程,該方程類似于從關于大腦中突觸可塑性的赫布模型中衍生的更新規則。我們已知赫布更新可以收斂到 PCA 解決方案,但不能作為任何效用函數的梯度導出。博弈論為我們提供了一個新的視角來研究赫布學習,也為機器學習問題提供了一系列的解決方法。
機器學習連續曲線的一端是提出可優化的目標函數的完善路徑:使用凸優化和非凸優化理論,研究人員可以對解決方案的整體性質進行推理。而在另一端上,則直接指定了受神經科學啟發的純聯結主義方法和更新規則,但是這可能增加了對整個系統的分析難度,常常需要研究復雜的動力系統。
像 EigenGame 這樣的游戲理論方法則介于兩者之間。玩家更新將不受限于函數的梯度,而只是對其他玩家當前策略的最佳響應。我們可以自由設計具有必要屬性的效用函數程序和更新,例如,指定無偏或加速的更新,同時確保納什屬性仍然允許我們對整個系統進行分析。

EigenGame 形象地展示了如何將機器學習問題的解決方案設計為大型多智能體系統的輸出。一般而言,將機器學習問題設計為多智能體游戲是頗具挑戰性的機制設計問題;但是,研究人員已經使用兩個玩家間的這類零和博弈來解決機器學習問題。最值得注意的是,生成對抗網絡 (GAN) 這一生成建模方法的成功吸引了人們對博弈論與機器學習之間關系的興趣。
EigenGame 超越了這一點,進入了更為復雜的多玩家非零和博弈設置。這優化了并行性,從而能夠支持更大的規模和速度。它還為機器學習的相關社區提供了可量化的基準,以測試新穎的多智能體算法以及更豐富的領域,例如外交風云和足球。
我們希望我們的效用和更新設計藍圖能夠鼓勵其他人探索設計算法、智能體和系統的新方向。我們期待未來能看到其他問題也可表述為游戲,以及我們收集的數據分析是否會進一步增進我們對多智能體的智能本質的理解。



















