













使用超大規模數據分析技術支持大數據預測
我給大家帶來的演講內容是關于“使用超大規模數據分析技術支持大數據預測”這方面的。首先介紹一下我自己,我叫韓卿,很多人叫我Luke。我是Kyligence公司的聯合創始人兼CEO,Apache Kylin開源項目的創始人,同時也是這個項目的項目管理委員會主席,以及Apache軟件基金會會員。
一、超大規模數據分析的挑戰
Hadoop
首先,我想和大家分享一下我們在大數據技術領域碰到的挑戰,這里在座很多朋友都是從傳統的數據倉庫出來的,事實上以前是沒有Hadoop的,因此數據并不是很大,我記得在07年、08年的時候,那時候說沃爾瑪是全球***的數據倉庫,數據量是幾個PB。那么如今又是怎樣的量級呢?我原來在ebay工作,今年年初的時候ebay的整個Hadoop數據量已經超過幾百個PB了,但這還不是***的。由此可以看出,在這短短幾年之間,數據的膨脹是相當大的。
Hadoop平臺今年正好是第十年,發展到今天,它非常擅長批量處理,這里大部分的企業都用它做過批量的東西。那帶來的***個問題是什么呢?比如說,我的數據已經在Hadoop上面了,那么后面不管是報表分析、交叉分析還是預測分析,是不是也應該在平臺上面直接去做?但現實告訴我們,由于各種各樣的挑戰,很多時候在Hadoop上面把數據處理完又被扔回到數據倉庫里面了。
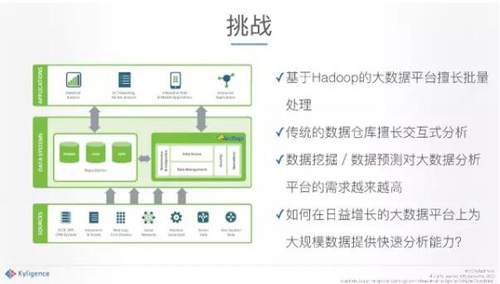
傳統的數據倉庫非常擅長大型的交互式分析和復雜分析,但它面臨的問題是如此龐大的數據無法全部儲存在里面,或者說如果存下如此大量的數據,它的成本是很恐怖的。我們在ebay的時候做過一個測算,在傳統數據倉庫上面每TB的存儲成本遠遠超過在Hadoop上面每PB的存儲成本,這是基于我們投資成本算出來的。一個TB和一個PB相差1024倍,如果說我們將在Hadoop上面的200多個PB的數據都放在傳統數據庫上面,那肯定是不現實的。至于我們該如何在Hadoop大數據平臺上將分析能力提供出來,是我們當時面臨的巨大挑戰。
數據挖掘與數據預測
另外,在數據挖掘、數據預測的時候,這個需求非常的旺盛。以前人們更多的是說要做一個報表,而這兩年人們傾向于建立一個系統,進行風控控制、數據預測、挖掘等。但這又引出了一個問題:這么大的數據量我怎么能夠在最快的時間內提供給你完整的分析結果,能夠滿足你在具備傳統數據倉庫經驗能力的情況下又能夠利用大數據的平臺進行工作,我覺得這是我們今天面臨的巨大挑戰。
二、Apache Kylin快速分析解決方案
在ebay工作的時候,我們發現在Hadoop上面如果直接進行分析是不可能的,因為我的分析師不可能花費很長時間去等一個分析結果。如果說我們把數據都放到DW里面也不能現實,至少成本上面是不可接受的。所以導致我們那時候探索了很多這方面的技術,無論是商業的技術,還是開源的技術,最終發現沒有一個技術能夠滿足我們的需求,這件事情發生在2013年9月份,是三年以前。
所以后來我們在上海的幾位同事想要不自己試試看,我們的架構師真的蠻厲害的,在9月份做出的決定,國慶節回來就說跑通了,當然我們也花了很多的力氣去說服管理層、說服我們的客戶以及合作伙伴。
這里面解釋一下,這個項目叫做Apache Kylin,也是我們目前活下來的唯一項目。Apache Kylin這個名字在Apache軟件基金會里面也是唯一一個中國來,我們覺得還是蠻驕傲的。
我們完全可以說在開源領域里面我們是***的OLAP on Hadoop的解決方案。這里澄清一下,我們做的并不是SQL,我們做的是OLAP on Hadoop,叫做多維分析或者更大一點叫做數據集市。今天只要搜索這樣幾個關鍵字,不管在谷歌還是百度上面,基本上我們都是***。
整個社區發展是非常快的,我們這個社區活躍度非常好,以及有一百多家公司了。最重要的是這是唯一一個來自中國的***項目,這意味著我們的項目跟Apache的Hadoop是一個級別的,是中國開發者社區的代表。Apache孵化器的副總裁,也是我們的導師,當時我們剛剛加入進去的時候,整個社區對我們并不看好,說歡迎中國人過來玩,但不覺得你們能畢業。
但當我們花了11個月畢業,并成為***項目的時候,整個社區對我們的認可度是非常高的。說我們代表了整個亞洲國家,特別是中國人在整個開源社區的貢獻、參與度。我想告訴大家的是,整個核心團隊并不多,其實就幾個人,大部分核心團隊現在都在我們公司,后來我們從ebay出來了,看到這樣一個機會,我們成立了一家創業公司,希望在社區能夠做更多的事情。
Apache Kylin的技術
那么,我們用什么樣的技術來解決問題呢?無論是并行計算、還是列式存儲,如今行業里擁有許多不同的技術,而Kylin則結合了這些技術的優點。
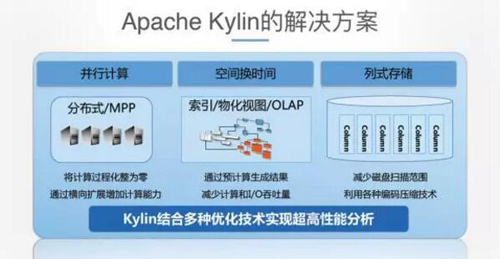
首先我們應用了并行計算。傳統的數據倉庫、BI的工具之類的以前都是很小的,不能夠支撐單個文件超過2個G的,或者還有一些說不能超過多大的數據量。我們在ebay的時候曾經用了另外一個BI工具,單個不能超過20億的數據,因為把里面的算法寫死掉了,沒有辦法改。而今天我們能夠大量地利用并行計算Hadoop這樣的技術做并行的處理,所以相應的能力、計算的速度、效率那是指數級增長。
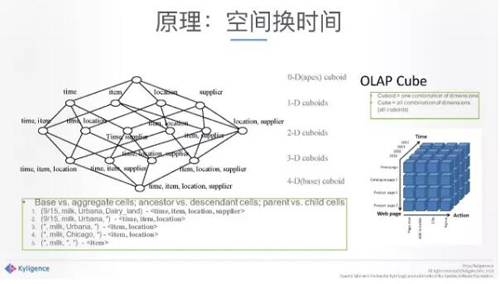
中間是空間換時間。這是最根本的設計理念,當你海量數據進來的時候,你的查詢相對來說是比較固定的,或者相對來說原始數據百分之七八十或者九十不會再動了,我有理由幫你做一些這方面的預計算。
列式存儲。另外一塊,即使算完了,如果還是放在磁盤上面是不夠的,因為磁盤效率很低,放內存,內存又很貴。而通過列式存儲的方式,就能大大解決這一問題。
技術核心
我們的技術核心其實非常簡單,叫做用空間換時間。因為你實時算這個東西的時候,實在是太慢了,我們當時碰到的給我們的數據級、測試數據級都是一百億以上的規模的,但今天我們能做到的數據是千億、萬億規模的。我經常舉一個例子,好比你中午吃飯,如果從買菜開始到菜買回來洗好,電飯煲插上,吃好洗碗,兩小時肯定不夠。怎么辦呢?前一天晚上把飯做好拿過來,今天微波爐一熱,就能大大節省了午飯時間,這就是預計算能夠帶給你的。
另一方面,我們非常Care查詢階段。非常重要的數學,一旦進行預計算之后,這個地方的查詢復雜度是O(1),給定的條件之下,不管你數據級有多大,查詢都可以保證在一定的范圍內達到秒級別,數據再大也沒有關系。
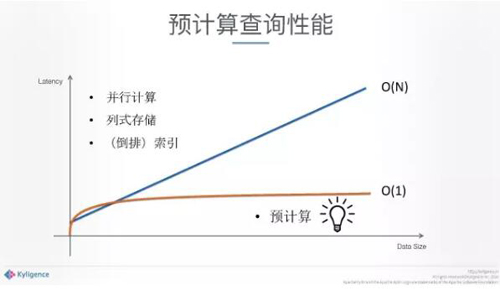
但其他的一些并行計算也好、列式存儲也好,是一個分布式實時計算,不可避免帶來的算法復雜度是O(N)。我們通過預計算帶給大數據分析技術最核心的價值,跟你的數據量并沒有關系,并且滿足你在各個場景下的訪問。
架構
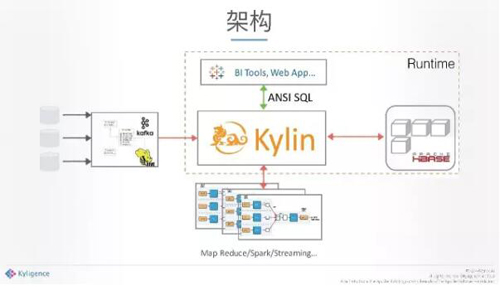
簡單講一下架構,整個Hadoop生態圈里面,Kylin用了Hadoop組件,也可以做整個預計算。當整個計算結束之后,所有的分析應用、查詢應用、挖掘應用會像數據庫一樣,通過標準的SQL訪問,我們的系統會非常精準地知道你給我的查詢結果在哪里,馬上可以把這個結果反饋給你。當然我們也在做更深的研發支撐更多的條件,我們在上面支撐的是標準SQL,所以就像數據倉庫一樣的,這也是我們的定位,希望未來做成一個數據倉庫Hadoop的解決方案。
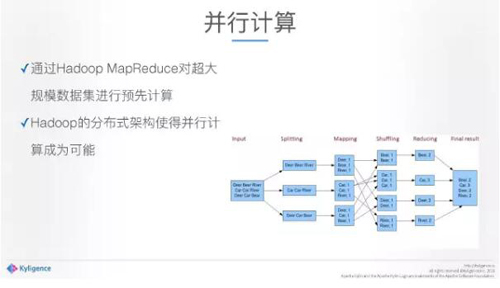
講一下細節,***個怎樣利用并行計算,如果給一百億的數據靠一臺電腦去計算,不知道要算到什么時候,但如果有一百臺、一千臺機器就很快了,這是并行計算帶來的威力。我們的預計算的好處是,通過Hadoop MapReduce來做并行計算,這個計算,***很快,同時產生的成本并不高,這是利用并行計算。
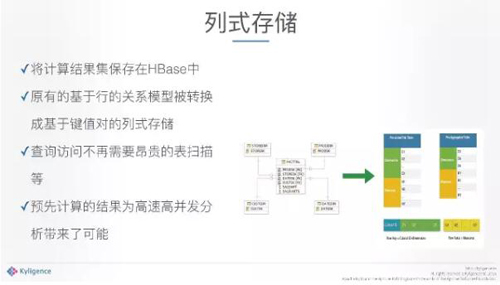
算完之后存哪里?轉化成列式存儲,把一個傳統的模型結構,充分利用HBase列式存儲的組件達到性能,所以說我們的數據最終在HBase每個節點上面是均勻分布的。***已經沒有SQL的問題了,而且已經全部轉成了Kb value。今天基本上你給我一個SQL,就可以給到你結果。
結果
給大家看我們做到的結果,我用了四個字:多、快、好、省。
——“多”,我們支撐的數據量非常大,在ebay單個cube已經超過千億規模。
—— “快”,是指達到的查詢性,90%的查詢性是在1.18秒內。包括百度的百度地圖、百度導航的數據都在上面。這里分享一下,***的來自廣東移動,廣東移動數據非常大,如今4G、移動互聯網非常火熱,相應的數據都在里面,進來的數據每天增量超過一百億條,這個系統運行快一年了,基本上超過萬億規模,每個查詢都可以在秒級返回。另外,美團整個外賣數據也都在上面,95%查詢在1秒以內。重要的是說,我們所使用的硬件成本是很低的,就是普通的機器。如果用內存機器或者傳統的數據倉庫、一體機等等,這個成本是呈指數的。
——“好”,這方面就不多說了,國內、國外有非常多的公司都在使用。
——“省”,大數據平臺上面是一個開源的技術,最重要的是這還是一個國產技術。我們在唯品會的一些技術已經在遷移,把傳統的國外的這些數據倉庫的技術遷移到今天我們這樣一個國產自主的,在大數據的平臺上的技術上面,而且成本將會大大降低,這對客戶的價值是非常大的。另外一個“省”的很重要的原因是,我們把建模過程封裝的非常好,使用的時候對于開發人員、應用人員要求很低,懂數據庫、SQL就夠了,不需要寫任何JAVA的腳本,不需要寫任何的程序。我們希望我們在這方面做更多的工作來降低整個大數據的門檻,來快速的為客戶提供價值。
下面是不完全的全球用戶的簡介。ebay就不說了,微軟,包括來自德國的,來自美國的都有。最重要的是在中國有非常多的互聯網公司,包括京東、網易、美團、百度、唯品會等等,以及像OPPO、魅族、樂視這些手機廠商,還有聯想、國泰君安、三大運營商,我們都有很好的案例,而且使用的規模都是非常大的。
我們說每個成功的開源項目后面都有一個創業公司,以往這些公司的故事都發生在美國,而我們這家公司在中國,在上海。

解釋一下這個公司名字的議程,我們的公司叫做Kyligence,來自Kylin+Intelligence,我們希望把一個神獸帶到大數據生態圈里面,整個大數據里面都是動物,而我們希望我們的神獸變得更加智能一點。
三、對大數據預測技術的支持
有了這樣一個基礎以及數據技術之后,談一下對于大數據預測技術我們的想法,怎么來支撐、怎么讓我們用戶做一些應用?

首先我們看一下最重要的,我們在千億規模上面做到亞秒級的查詢延遲。不管做預測也好,做什么也好,最重要的是要快速的獲取數據的能力,特別是預測,不斷地迭代,我們能夠支撐到不管你改變任何的查詢條件,我可以非常快的把這個查詢給你。很多時候做預測工作,其實是在不斷地換參數,但相對的下面的數據模型很多時候是固定的或者相對固定,我們能夠有這個能力,無論你給我幾個參數,或是換參數,馬上就給你結果級。上層應用,基于這個結果級進一步的通過算法做演算、調整。
另外一個很重要的是我們支持的是標準SQL,很多時候現在的技術是要你自己寫程序的,這要求的入門門檻太高了,但是通過標準的SQL,我們在傳統的數據庫里面有非常多的模型與算法是可以使用的。

對于整個技術的支持來說,我們為上層數據應用、挖掘應用提供的接口是ODBC、JDBC、REST API。所以跟你用一個傳統數據倉庫其實沒有任何區別。最重要的是,我們能夠在非常大的規模的數據上面直接把這個給到你,不管你原來的數據是一百億、一千億、一萬億,你要拿的東西往往是那么一點點,拿到關鍵的幾個數據就夠了。
今天來說,對于未來我們看到大數據預測應用越來越多的變成在線應用。在線對這個底層數據倉庫帶來的***壓力在于并發,傳統的數據倉庫在并發上面都是上不去的,都有很大的問題。今天可以做到互聯網級別的高并發應用了。我們有能力為這些分析應用、預測應用提供高并發的快速分析能力。
四、去哪兒案例分享
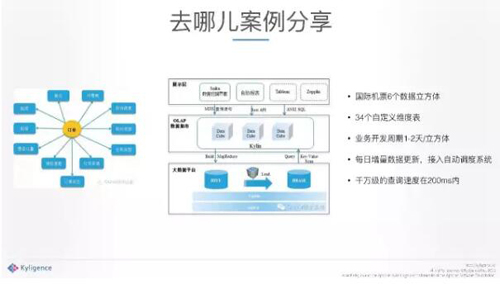
非常簡單的介紹一下去哪兒的案例,去哪兒在做機票訂單、酒店等等,跟攜程非常像。中間是訂單,有代理商、公司、各種各樣的信息。它把數據都放到Hadoop之上,中間一層是Kylin,把下面的數據做了加工之后,處理好,按照數據模型建立起來。上層應用通過相應的數據挖掘界面,以及其他的一些SQL的工具就可以訪問后臺了,訪問中間一層可以看到不同的維度、不同的指標等等,***的查詢速度。它的應用基于一個數據模型可以做各種各樣的分析,就能夠預測一下賣的好不好或者什么地方有問題。
至于我們公司,我們在開源之上,并且還在持續的投入做開源社區,非常重要的是我們百分之八九十的工作還在發展開源的技術,提供一些企業級的產品。

后面介紹一下我們整個的生態系統,我們要做一家產品和技術公司,希望在中國為用戶提供純粹的產品技術。此外,我們希望跟大數據供應商、云平臺的供應商,上層供應商,以及每個行業的解決方案供應商一起壯大整個大數據生態。

















