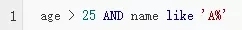換一種存儲方式,居然能節約這么多內存?

前言
提到緩存,就會想到redis,提到 Redis,我們的腦子里馬上就會出現一個詞:快。那么我們也知道,redis 之所以這么快,因為數據是放在內存中的,但是內存是非常昂貴的,怎么來設計我們的應用的存儲結構,讓應用滿足正常的業務的前提下來節約內存呢?首先我們從Redis的數據類型開始看起。
Redis 的數據類型及底層實現
說到redis的數據類型,大家肯定會說:不就是 String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)嗎?”
其實,這些只是 Redis 鍵值對中值的數據類型,也就是數據的保存形式。
而這里,我們說的數據結構,是要去看看它們的底層實現。簡單說底層數據結構一共有 6 種:
- 簡單動態字符串
- 雙向鏈表
- 壓縮列表
- 哈希表
- 跳表和整數數組。
Redis 存儲結構總覽
其實在Redis中,并不是單純將key 與value保存到內存中就可以的。它需要依賴上面講的數據結構對其進行管理。
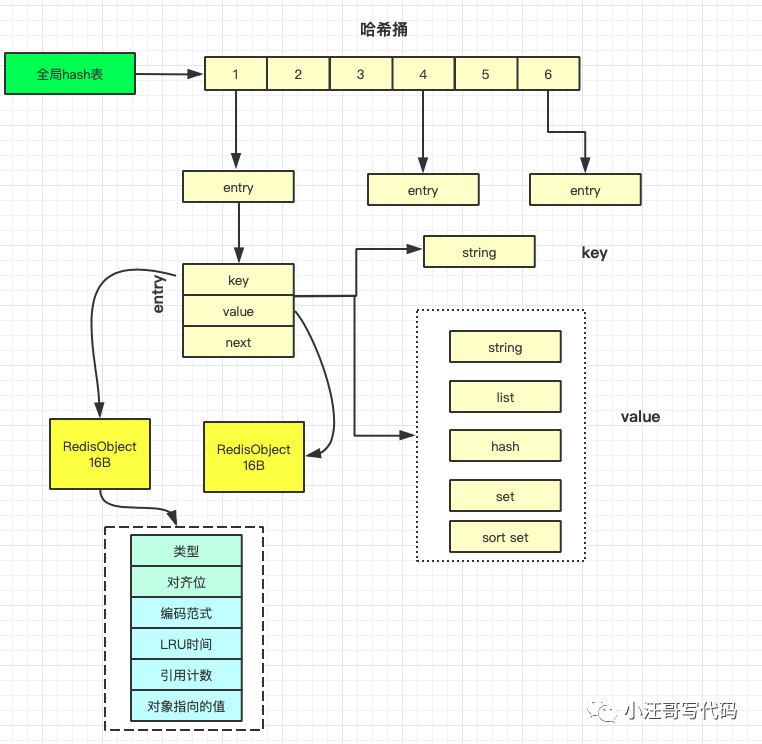
因為這個哈希表保存了所有的鍵值對,所以,我也把它稱為全局哈希表。哈希表的最大好處很明顯,就是讓我們可以用 O(1) 的時間復雜度來快速查找到鍵值對——我們只需要計算鍵的哈希值,就可以知道它所對應的哈希桶位置,然后就可以訪問相應的 entry 元素。每個entry 都會有一個數據類型。
Redis 不同數據類型的編碼
而且每個類型又對應了多種編碼格式,不同的編碼格式對應的底層數據結構是不同的。可以先做個了解,后面會具體用到。
編碼編碼對應的底層數據結構INTlong 類型的整數EMBSTRembstr 編碼的簡單動態字符串RAW簡單動態字符串HT字典 HASH_TABLELINKEDLIST雙端鏈表ZIPLIST壓縮列表INTSET整數集合SKIPLIST跳躍表和字典
類型與編碼映射
類型編碼編碼對應的底層數據結構STRINGINTlong 類型的整數STRINGEMBSTRembstr 編碼的簡單動態字符串STRINGRAW簡單動態字符串LISTZIPLIST壓縮列表LISTQUICKLIST快速列表LISTLINKEDLIST雙端鏈表HASHZIPLIST壓縮列表HASHHT字典SETINTSET整數集合SETHT字典ZSETZIPLIST壓縮列表ZSETSKIPLIST跳躍表和字典
具體的映射關系
1. 字符串類型(STRING)對象
2. 集合類型(SET)對象

3. 有序集合類型(ZSET)對象
有序集合類型的對象有兩種編碼方式:OBJ_ENCODING_SKIPLIST、OBJ_ENCODING_ZIPLIST。Redis 對于有序集合類型的編碼有兩個配置項:
- zset_max_ziplist_entries,默認值為 128,表示有序集合中壓縮列表節點的最大數量。
- zset_max_ziplist_value,默認值為 64,表示有序集合中壓縮列表節點的最大長度。

注:當刪除或更新元素,使得滿足以上兩個配置項時,編碼方式是不會自動從 OBJ_ENCODING_SKIPLIST 轉化為 OBJ_ENCODING_ZIPLIST 的,但 Redis 提供了函數
zsetConvertToZiplistIfNeeded 支持。
4. 哈希類型(HASH)對象
哈希類型對象有兩種編碼方式:OBJ_ENCODING_ZIPLIST、OBJ_ENCODING_HT。Redis 對于哈希類型對象的編碼有兩個配置項:
- hash_max_ziplist_entries,默認值 512, 表示哈希類型對象中壓縮列表節點的最大數量。
- hash_max_ziplist_value,默認值 64,表示哈希類型對象中壓縮列表節點的最大長度。

注:當刪除或更新元素,使得滿足以上兩個配置項時,編碼方式是不會自動從 OBJ_ENCODING_HT 向 OBJ_ENCODING_ZIPLIST 轉化。
關于壓縮鏈表
因為這個和我們后面的優化有關系,我們先來看看什么是壓縮鏈表。
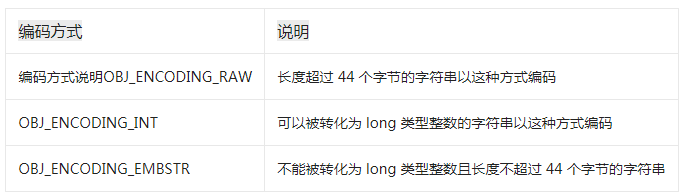
壓縮列表實際上類似于一個數組,數組中的每一個元素都對應保存一個數據。和數組不同的是,壓縮列表在表頭有三個字段 zlbytes、zltail 和 zllen,分別表示列表長度、列表尾的偏移量和列表中的 entry 個數;壓縮列表在表尾還有一個 zlend,表示列表結束。
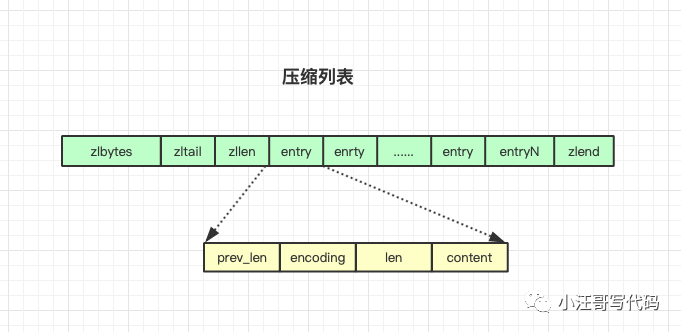
prev_len,表示前一個 entry 的長度。prev_len 有兩種取值情況:1 字節或 5 字節。取值 1 字節時,表示上一個 entry 的長度小于 254 字節。雖然 1 字節的值能表示的數值范圍是 0 到 255,但是壓縮列表中 zlend 的取值默認是 255,因此,就默認用 255 表示整個壓縮列表的結束,其他表示長度的地方就不能再用 255 這個值了。所以,當上一個 entry 長度小于 254 字節時,prev_len 取值為 1 字節,否則,就取值為 5 字節。
- len:表示自身長度,4 字節;
- encoding:表示編碼方式,1 字節;
- content:保存實際數據。
壓縮鏈表的查詢
壓縮列表的設計不是為了查詢的,而是為了減少內存的使用和內存的碎片化。比如一個列表中的只保存int,結構上還需要兩個額外的指針prev和next,每添加一個結點都這樣。而壓縮列表是將這些數據集合起來只需要一個prev和next。
在壓縮列表中,如果我們要查找定位第一個元素和最后一個元素,可以通過表頭三個字段的長度直接定位,復雜度是 O(1)。而查找其他元素時,就沒有這么高效了,只能逐個查找,此時的復雜度就是 O(N) 了。
為什么 String 類型內存開銷大?
對于kv 類型的緩存數據,我們經常會用redis string 類型。比如日常工作中經常對合作方客戶一周內是否營銷進行緩存,key 為 32位的hash(用戶編碼),value 為是否(0或者1)營銷。很符合string 的數據類型。
但是隨著營銷數據量的不斷增加,我們的 Redis 內存使用量也在增加,結果就遇到了大內存 Redis 實例因為生成 RDB 而響應變慢的問題。很顯然,String 類型并不是一種好的選擇,需要進一步尋找能節省內存開銷的數據類型方案。
通過上面的文章,我們對string 類型進行研究,會發現:
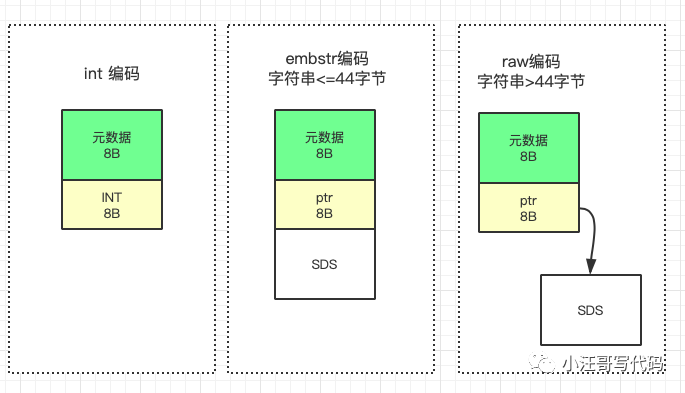
當你保存 64 位有符號整數時,String 類型會把它保存為一個 8 字節的 Long 類型整數,這種保存方式通常也叫作 int 編碼方式。但是,當你保存的數據中包含字符時,String 類型就會用簡單動態字符串(Simple Dynamic String,SDS)結構體來保存,
另一方面,當保存的是字符串數據,并且字符串小于等于 44 字節時,RedisObject 中的元數據、指針和 SDS 是一塊連續的內存區域,這樣就可以避免內存碎片。這種布局方式也被稱為 embstr 編碼方式。
int、embstr 和 raw 這三種編碼模式,如下所示:
根據文章開頭的示意圖,redis 全局hash 表中的 entry 元素 其實是dictEntry,dictEntry 結構中有三個 8 字節的指針,分別指向 key、value 以及下一個 dictEntry,三個指針共 24 字節,如下圖所示:
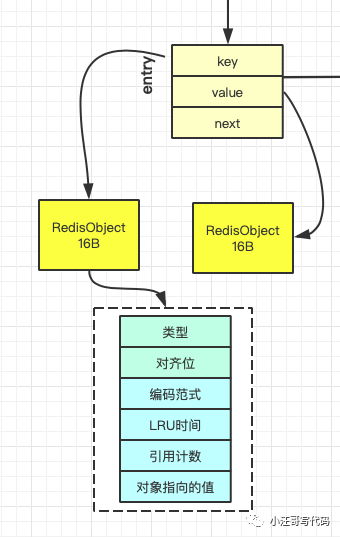
而且redis 模式使用jemalloc進行內存管理, jemalloc 在分配內存時,會根據我們申請的字節數 N,找一個比 N 大,但是最接近 N 的 2 的冪次數作為分配的空間,這樣可以減少頻繁分配的次數。所以,我們用string這種存儲簡單數據的方式比較浪費內存!!
用什么數據結構可以節省內存?
那么,用什么數據結構可以節約內存呢?就是我們上面講的壓縮列表(ziplist),這是一種非常節省內存的結構。
通過前文編碼對應的底層數據結構我們了解到,使用壓縮鏈表實現的數據結構有 List、Hash 和 Sorted Set 這樣的集合類型。
基于壓縮列表最大好處就是節省了 dictEntry 的開銷。當你用 String 類型時,一個鍵值對就有一個 dictEntry。當采用集合類型時,一個 key 就對應一個集合的數據,能保存的數據多了很多,但也只用了一個 dictEntry,這樣就節省了內存。
通過研究hash數據結構。我發現,hash類型有非常節省內存空間的底層實現結構,但是,hash類型保存的數據模式,是一個鍵對應一系列值,并不適合直接保存單值的鍵值對。所以就使用二級編碼【二級編碼:把32位前3位作為key,后29位作為field】的方法,實現了用集合類型保存單值鍵值對,Redis 實例的內存空間消耗明顯下降了。
實驗數據
我們模擬20w數據的寫入,看看string 類型和hash 類型分別對內存的占用情況。
string類型:
- Long id = 10000000000l;
- for (Long i=0l;i<200000l;i++){
- id+=i;
- System.out.println(i);
- try {
- String encode = MD5.encode(id+"");
- jCacheClient.set(encode,"1");
- sleeptime(1);//防止qps 過高
- } catch (Exception e) {
- e.printStackTrace();
- sleeptime(1000);
- }
- }
- flushdb
- +OK
- info memory
- $1165
- # Memory
- used_memory:135261368
- info memory
- $1166
- # Memory
- used_memory:156517632
- 使用 20.27m
hash類型
- Long id = 10000000000l;
- for (Long i=0l;i<200000l;i++){
- id+=i;
- try {
- String encode = MD5.encode(id+"");
- String prex = encode.substring(0,3);
- String key = encode.substring(3,32);
- jCacheClient.hset(prex,key,"1");
- sleeptime(1);
- } catch (Exception e) {
- e.printStackTrace();
- sleeptime(1000);
- }
- }
- flushdb
- +OK
- info memory
- $1165
- # Memory
- used_memory:135220400
- info memory
- $1166
- # Memory
- used_memory:142697280
- 內存使用 7.13M
只是改了一個存儲結構,內存節約了大概2/3.
二級編碼使用注意事項
因為Redis Hash 類型的兩種底層實現結構,分別是壓縮列表和哈希表。
那么,Hash 類型底層結構什么時候使用壓縮列表,什么時候使用哈希表呢?根據上面表格的內容,我們知道有兩個閾值:
- hash-max-ziplist-entries:表示用壓縮列表保存時哈希集合中的最大元素個數。
- hash-max-ziplist-value:表示用壓縮列表保存時哈希集合中單個元素的最大長度。
如果我們往 Hash 集合中寫入的元素個數超過了 hash-max-ziplist-entries,或者寫入的單個元素大小超過了 hash-max-ziplist-value,Redis 就會自動把 Hash 類型的實現結構由壓縮列表轉為哈希表。一旦從壓縮列表轉為了哈希表,Hash 類型就會一直用哈希表進行保存,而不會再轉回壓縮列表了。在節省內存空間方面,哈希表就沒有壓縮列表那么高效了。
所以要根據實際情況調整二級編碼的實現方式,節約內存,提高redis的響應速度!
通過 config get 命令 我們可以查看 閥值的設置: