













Snowflake 如日中天是否代表 Hadoop 已死?大數(shù)據(jù)體系到底是什么?
任何一種技術(shù)都會(huì)經(jīng)歷從陽春白雪到下里巴人的過程,就像我們對(duì)計(jì)算機(jī)的理解從“戴著鞋套才能進(jìn)的機(jī)房”變成了隨處可見的智能手機(jī)。在前面20年中,大數(shù)據(jù)技術(shù)也經(jīng)歷了這樣的過程,從曾經(jīng)高高在上的 “火箭科技(rocket science)”,成為了人人普惠的技術(shù)。
回首來看,大數(shù)據(jù)發(fā)展初期涌現(xiàn)了非常多開源和自研系統(tǒng),并在同一個(gè)領(lǐng)域展開了相當(dāng)長(zhǎng)的一段“紅海”競(jìng)爭(zhēng)期,例如Yarn VS Mesos、Hive VS Spark、Flink VS SparkStreaming VS Apex、Impala VS Presto VS Clickhouse等等。經(jīng)歷激烈競(jìng)爭(zhēng)和淘汰后,勝出的產(chǎn)品逐漸規(guī)模化,并開始占領(lǐng)市場(chǎng)和開發(fā)者。
事實(shí)上,近幾年,大數(shù)據(jù)領(lǐng)域已經(jīng)沒有再誕生新的明星開源引擎(Clickhouse@2016年開源,PyTorch@2018年開源),以Apache Mesos等項(xiàng)目停止維護(hù)為代表,大數(shù)據(jù)領(lǐng)域進(jìn)入“后紅海”時(shí)代:技術(shù)開始逐步收斂,進(jìn)入技術(shù)普惠和業(yè)務(wù)大規(guī)模應(yīng)用的階段。
本文作者關(guān)濤是大數(shù)據(jù)系統(tǒng)領(lǐng)域的資深專家,在微軟(互聯(lián)網(wǎng)/Azure云事業(yè)群)和阿里巴巴(阿里云)經(jīng)歷了大數(shù)據(jù)發(fā)展20年過程中的后15年。本文試從系統(tǒng)架構(gòu)的角度,就大數(shù)據(jù)架構(gòu)熱點(diǎn),每條技術(shù)線的發(fā)展脈絡(luò),以及技術(shù)趨勢(shì)和未解問題等方面做一概述。
值得一提的是,大數(shù)據(jù)領(lǐng)域仍然處于發(fā)展期,部分技術(shù)收斂,但新方向和新領(lǐng)域?qū)映霾桓F。本文內(nèi)容和個(gè)人經(jīng)歷相關(guān),是個(gè)人的視角,難免有缺失或者偏頗,同時(shí)限于篇幅,也很難全面。僅作拋磚引玉,希望和同業(yè)共同探討。
一、當(dāng)下的大數(shù)據(jù)體系熱點(diǎn)
BigData概念在上世紀(jì)90年代被提出,隨Google的3篇經(jīng)典論文(GFS,BigTable,MapReduce)奠基,已經(jīng)發(fā)展了將近20年。這20年中,誕生了包括Google大數(shù)據(jù)體系,微軟Cosmos體系,阿里云的飛天系統(tǒng),開源Hadoop體系等優(yōu)秀的系統(tǒng)。這些系統(tǒng)一步步推動(dòng)業(yè)界進(jìn)入“數(shù)字化“和之后的“AI化”的時(shí)代。
海量的數(shù)據(jù)以及其蘊(yùn)含的價(jià)值,吸引了大量投入,極大的推動(dòng)大數(shù)據(jù)領(lǐng)域技術(shù)。云(Cloud)的興起又使得大數(shù)據(jù)技術(shù)對(duì)于中小企業(yè)唾手可得。可以說,大數(shù)據(jù)技術(shù)發(fā)展正當(dāng)時(shí)。
從體系架構(gòu)的角度看,“Shared-Everything”架構(gòu)演進(jìn)、湖倉(cāng)技術(shù)的一體化融合、云原生帶來的基礎(chǔ)設(shè)計(jì)升級(jí)、以及更好的AI支持,是當(dāng)下平臺(tái)技術(shù)的四個(gè)熱點(diǎn)。
1.1 系統(tǒng)架構(gòu)角度,平臺(tái)整體向Shared-Everything架構(gòu)演進(jìn)
泛數(shù)據(jù)領(lǐng)域的系統(tǒng)架構(gòu),從傳統(tǒng)數(shù)據(jù)庫(kù)的Scale-up向大數(shù)據(jù)的Scale-out發(fā)展。從分布式系統(tǒng)的角度,整體架構(gòu)可以按照Shared-Nothing(也稱MPP), Shared-Data, Shared-Everything 三種架構(gòu)。
大數(shù)據(jù)平臺(tái)的數(shù)倉(cāng)體系最初由數(shù)據(jù)庫(kù)發(fā)展而來,Shared-Nothing(也稱MPP)架構(gòu)在很長(zhǎng)一段時(shí)間成為主流。隨云原生能力增強(qiáng),Snowflake為代表的Shared-Data逐漸發(fā)展起來。而基于DFS和MapReduce原理的大數(shù)據(jù)體系,設(shè)計(jì)之初就是Shared-Everything架構(gòu)。
Shared-Everything架構(gòu)代表是GoogleBigQuery和阿里云MaxCompute。從架構(gòu)角度,Shared-Everything架構(gòu)具備更好的靈活性和潛力,會(huì)是未來發(fā)展的方向。
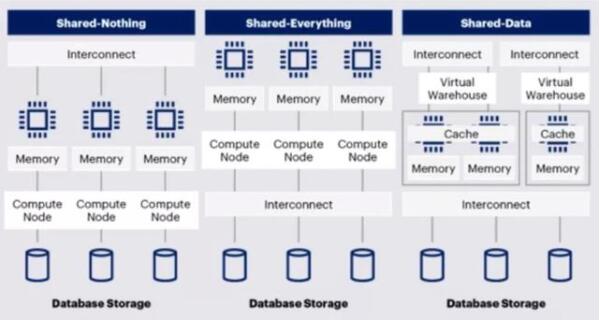
(圖:三種大數(shù)據(jù)體系架構(gòu))
1.2 數(shù)據(jù)管理角度,數(shù)據(jù)湖與數(shù)據(jù)倉(cāng)庫(kù)融合,形成湖倉(cāng)一體
數(shù)據(jù)倉(cāng)庫(kù)的高性能與管理能力,與數(shù)據(jù)湖的靈活性,倉(cāng)和湖的兩套體系在相互借鑒與融合。在2020年各個(gè)廠商分別提出湖倉(cāng)一體架構(gòu),成為當(dāng)下架構(gòu)演進(jìn)最熱的趨勢(shì)。但湖倉(cāng)一體架構(gòu)有多種形態(tài),不同形態(tài)尚在演進(jìn)和爭(zhēng)論中。

(圖:數(shù)據(jù)湖與數(shù)據(jù)倉(cāng)庫(kù)借鑒融合)
1.3 云架構(gòu)角度,云原生與托管化成為主流
隨著大數(shù)據(jù)平臺(tái)技術(shù)進(jìn)入深水區(qū),用戶也開始分流,越來越多的中小用戶不再自研或自建數(shù)據(jù)平臺(tái),開始擁抱全托管型(通常也是云原生)的數(shù)據(jù)產(chǎn)品。Snowflake作為這一領(lǐng)域的典型產(chǎn)品,得到普遍認(rèn)可。面向未來,后續(xù)僅會(huì)有少量超大規(guī)模頭部公司采用自建(開源+改進(jìn))的模式。
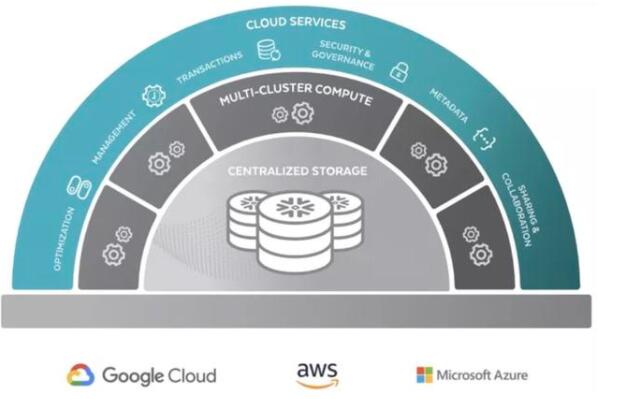
(圖:snowflake的云原生架構(gòu))
1.4 計(jì)算模式角度,AI逐漸成為主流,形成BI+AI雙模式
BI作為統(tǒng)計(jì)分析類計(jì)算,主要是面向過去的總結(jié);AI類計(jì)算則具備越來越好的預(yù)測(cè)未來的能力。在過去五年中,算法類的負(fù)載從不到數(shù)據(jù)中心總?cè)萘康?%,提升到30%。AI已經(jīng)成為大數(shù)據(jù)領(lǐng)域的一等公民。
二、大數(shù)據(jù)體系的領(lǐng)域架構(gòu)
在前文(#1.1)介紹的Shared-Nothing、Shared-Data、Shared-Everything 三種架構(gòu)中,筆者經(jīng)歷過的兩套體系(微軟Cosmos/Scope體系,和阿里云MaxCompute)均為Shared-Everything架構(gòu),因此筆者主要從Shared-Everything架構(gòu)角度,將大數(shù)據(jù)領(lǐng)域分成6個(gè)疊加的子領(lǐng)域、3個(gè)橫向領(lǐng)域,共9個(gè)領(lǐng)域,具體如下圖。

(圖:基于 Shared-Everything 大數(shù)據(jù)體系下的領(lǐng)域架構(gòu))
經(jīng)過多年的發(fā)展,每個(gè)領(lǐng)域都有一定的進(jìn)展和沉淀,下面各個(gè)章節(jié)將概述每個(gè)子領(lǐng)域的演進(jìn)歷史、背后驅(qū)動(dòng)力、以及發(fā)展方向。
2.1 分布式存儲(chǔ)向多層智能化演進(jìn)
分布式存儲(chǔ),本文特指通用大數(shù)據(jù)海量分布式存儲(chǔ),是個(gè)典型的帶狀態(tài)(Stateful)分布式系統(tǒng),高吞吐、低成本、容災(zāi)、高可用是核心優(yōu)化方向。(注:下述分代僅為了闡述方便,不代表嚴(yán)格的架構(gòu)演進(jìn)。)
第一代,分布式存儲(chǔ)的典型代表是谷歌的GFS和Apache Hadoop的HDFS,均為支持多備份的Append-only文件系統(tǒng)。因HDFS早期NameNode在擴(kuò)展性和容災(zāi)方面的短板不能充分滿足用戶對(duì)數(shù)據(jù)高可用的要求,很多大型公司都有自研的存儲(chǔ)系統(tǒng),如微軟的Cosmos(后來演進(jìn)成Azure Blob Storage),以及阿里巴巴的Pangu系統(tǒng)。HDFS作為開源存儲(chǔ)的奠基,其接口成為事實(shí)標(biāo)準(zhǔn),同時(shí)HDFS又具備支持其他系統(tǒng)作為背后存儲(chǔ)系統(tǒng)的插件化能力。
第二代,基于上述底盤,隨海量對(duì)象存儲(chǔ)需求激增(例如海量的照片),通用的Append-only文件系統(tǒng)之上,封裝一層支持海量小對(duì)象的元數(shù)據(jù)服務(wù)層,形成對(duì)象存儲(chǔ)(Object-based Storage),典型的代表包括AWS S3,阿里云OSS。值得一提的是,S3與OSS均可作為標(biāo)準(zhǔn)插件,成為HDFS的事實(shí)存儲(chǔ)后端。
第三代,以數(shù)據(jù)湖為代表。隨云計(jì)算技術(shù)的發(fā)展,以及(2015年之后)網(wǎng)絡(luò)技術(shù)的進(jìn)步,存儲(chǔ)計(jì)算一體的架構(gòu)逐漸被云原生存儲(chǔ)(存儲(chǔ)托管化)+ 存儲(chǔ)計(jì)算分離的新架構(gòu)取代。這也是數(shù)據(jù)湖體系的起點(diǎn)。同時(shí)因存儲(chǔ)計(jì)算分離帶來的帶寬性能問題并未完全解決,在這個(gè)細(xì)分領(lǐng)域誕生了Alluxio等緩存服務(wù)。
第四代,也是當(dāng)下的趨勢(shì),隨存儲(chǔ)云托管化,底層實(shí)現(xiàn)對(duì)用戶透明,因此存儲(chǔ)系統(tǒng)有機(jī)會(huì)向更復(fù)雜的設(shè)計(jì)方向發(fā)展,從而開始向多層一體化存儲(chǔ)系統(tǒng)演進(jìn)。由單一的基于SATA磁盤的系統(tǒng),向Mem/SSD+SATA (3X備份)+SATA (1.375X為代表的EC備份)+冰存儲(chǔ)(典型代表AWS Glacier)等多層系統(tǒng)演進(jìn)。
如何智能/透明的將數(shù)據(jù)存儲(chǔ)分層,找到成本與性能的Trade-off,是多層存儲(chǔ)系統(tǒng)的關(guān)鍵挑戰(zhàn)。這領(lǐng)域起步不久,開源領(lǐng)域沒有顯著好的產(chǎn)品,最好的水平由幾個(gè)大廠的自研數(shù)倉(cāng)存儲(chǔ)系統(tǒng)引領(lǐng)。
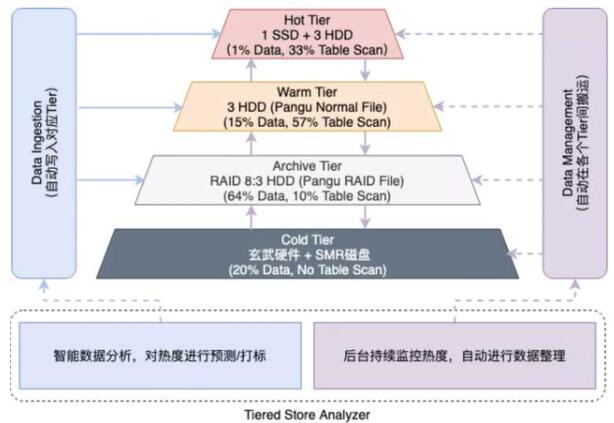
(圖:阿里巴巴 MaxCompute 的多層一體化存儲(chǔ)體系)
在上述系統(tǒng)之上,有一層文件存儲(chǔ)格式層(File Format layer),與存儲(chǔ)系統(tǒng)本身正交。
存儲(chǔ)格式第一代,包含文件格式、壓縮和編碼技術(shù)、以及Index支持等。目前主流兩類的存儲(chǔ)格式是Apache Parquet和Apache ORC,分別來自Spark和Hive生態(tài)。兩者均為適應(yīng)大數(shù)據(jù)的列式存儲(chǔ)格式,ORC在壓縮編碼上有特長(zhǎng),Parquet在半結(jié)構(gòu)支持上更優(yōu)。此外另有一種內(nèi)存格式Apache Arrow,設(shè)計(jì)體系也屬于format,但主要為內(nèi)存交換優(yōu)化。
存儲(chǔ)格式第二代 - 以 Apache Hudi/Delta Lake 為代表的近實(shí)時(shí)化存儲(chǔ)格式。存儲(chǔ)格式早期,是大文件列存儲(chǔ)模式,面向吞吐率優(yōu)化(而非latency)。隨著實(shí)時(shí)化的趨勢(shì),上述主流的兩個(gè)存儲(chǔ)模式均向支持實(shí)時(shí)化演進(jìn),Databricks推出了Delta Lake,支持Apache Spark進(jìn)行近實(shí)時(shí)的數(shù)據(jù)ACID操作;Uber推出了Apache Hudi,支持近實(shí)時(shí)的數(shù)據(jù)Upsert能力。
盡管二者在細(xì)節(jié)處理上稍有不同(例如Merge on Read or Write),但整體方式都是通過支持增量文件的方式,將數(shù)據(jù)更新的周期降低到更短(避免傳統(tǒng)Parquet/ORC上的針對(duì)更新的無差別FullMerge操作),進(jìn)而實(shí)現(xiàn)近實(shí)時(shí)化存儲(chǔ)。因?yàn)榻鼘?shí)時(shí)方向,通常涉及更頻繁的文件Merge以及細(xì)粒度元數(shù)據(jù)支持,接口也更復(fù)雜,Delta/Hudi均不是單純的format、而是一套服務(wù)。
存儲(chǔ)格式再向?qū)崟r(shí)更新支持方向演進(jìn),會(huì)與實(shí)時(shí)索引結(jié)合,不再單單作為文件存儲(chǔ)格式,而是與內(nèi)存結(jié)構(gòu)融合形成整體方案。主流的是實(shí)時(shí)更新實(shí)現(xiàn)是基于LogStructuredMergeTree(幾乎所有的實(shí)時(shí)數(shù)倉(cāng))或者Lucene Index(Elastic Search的格式)的方式。
從存儲(chǔ)系統(tǒng)的接口/內(nèi)部功能看,越簡(jiǎn)單的接口和功能對(duì)應(yīng)更開放的能力(例如GFS/HDFS),更復(fù)雜更高效的功能通常意味著更封閉,并逐步退化成存算一體的系統(tǒng)(例如AWS當(dāng)家數(shù)倉(cāng)產(chǎn)品RedShift),兩個(gè)方向的技術(shù)在融合。
展望未來,我們看到可能的發(fā)展方向/趨勢(shì)主要有:
1)平臺(tái)層面,存儲(chǔ)計(jì)算分離會(huì)在兩三年內(nèi)成為標(biāo)準(zhǔn),平臺(tái)向托管化和云原生的方向發(fā)展。平臺(tái)內(nèi)部,精細(xì)化的分層成為平衡性能和成本的關(guān)鍵手段(這方面,當(dāng)前數(shù)據(jù)湖產(chǎn)品還做得遠(yuǎn)遠(yuǎn)不夠),AI在分層算法上發(fā)揮更大的作用。
2)Format層面,會(huì)繼續(xù)演進(jìn),但大的突破和換代很可能取決于新硬件的演進(jìn)(編碼和壓縮在通用處理器上的優(yōu)化空間有限)。
3)數(shù)據(jù)湖和數(shù)倉(cāng)進(jìn)一步融合,使得存儲(chǔ)不僅僅是文件系統(tǒng)。存儲(chǔ)層做的多厚,與計(jì)算的邊界是什么,仍然是個(gè)關(guān)鍵問題。
2.2 分布式調(diào)度,基于云原生,向統(tǒng)一框架和算法多元化發(fā)展
計(jì)算資源管理是分布式計(jì)算的核心能力,本質(zhì)是解決不同種類的負(fù)載與資源最優(yōu)匹配的問題。在“后紅海時(shí)代”,Google的Borg系統(tǒng),開源Apache Yarn 依舊是這個(gè)領(lǐng)域的關(guān)鍵產(chǎn)品,K8S在大數(shù)據(jù)計(jì)算調(diào)度方向上仍在起步追趕。
常見的集群調(diào)度架構(gòu)有:
中心化調(diào)度架構(gòu):早期的Hadoop1.0的MapReduce、后續(xù)發(fā)展的Borg、和Kubernetes都是中心化設(shè)計(jì)的調(diào)度框架,由單一的調(diào)度器負(fù)責(zé)將任務(wù)指派給集群內(nèi)的機(jī)器。特別的,中心調(diào)度器中,大多數(shù)系統(tǒng)采用兩級(jí)調(diào)度框架通過將資源調(diào)度和作業(yè)調(diào)度分開的方式,允許根據(jù)特定的應(yīng)用來定做不同的作業(yè)調(diào)度邏輯,并同時(shí)保留了不同作業(yè)之間共享集群資源的特性。Yarn、Mesos都是這種架構(gòu)。
共享狀態(tài)調(diào)度架構(gòu):半分布式的模式。應(yīng)用層的每個(gè)調(diào)度器都擁有一份集群狀態(tài)的副本,并且調(diào)度器會(huì)獨(dú)立地對(duì)集群狀態(tài)副本進(jìn)行更新。如Google的Omega、Microsoft的Apollo,都是這種架構(gòu)。
全分布式調(diào)度架構(gòu):從Sparrow論文開始提出的全分布式架構(gòu)則更加去中心化。調(diào)度器之間沒有任何的協(xié)調(diào),并且使用很多各自獨(dú)立的調(diào)度器來處理不同的負(fù)載。
混合式調(diào)度架構(gòu):這種架構(gòu)結(jié)合了中心化調(diào)度和共享狀態(tài)的設(shè)計(jì)。一般有兩條調(diào)度路徑,分別為為部分負(fù)載設(shè)計(jì)的分布式調(diào)度,和來處理剩下的負(fù)載的中心式作業(yè)調(diào)度。
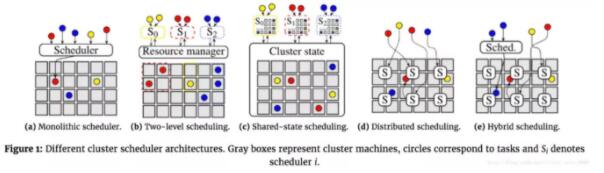
(圖 :The evolution of cluster scheduler architectures by Malte Schwarzkopf)
無論大數(shù)據(jù)系統(tǒng)的調(diào)度系統(tǒng)是基于哪種架構(gòu),在海量數(shù)據(jù)處理流程中,都需要具備以下幾個(gè)維度的調(diào)度能力:
數(shù)據(jù)調(diào)度:多機(jī)房跨區(qū)域的系統(tǒng)服務(wù)帶來全域數(shù)據(jù)排布問題,需要最優(yōu)化使用存儲(chǔ)空間與網(wǎng)絡(luò)帶寬。
資源調(diào)度:IT基礎(chǔ)設(shè)施整體云化的趨勢(shì),對(duì)資源的調(diào)度和隔離都帶來更大的技術(shù)挑戰(zhàn);同時(shí)物理集群規(guī)模的進(jìn)一步擴(kuò)大,去中心化的調(diào)度架構(gòu)成為趨勢(shì)。
計(jì)算調(diào)度:經(jīng)典的MapReduce計(jì)算框架逐漸演化到支持動(dòng)態(tài)調(diào)整、數(shù)據(jù)Shuffle的全局優(yōu)化、充分利用內(nèi)存網(wǎng)絡(luò)等硬件資源的精細(xì)化調(diào)度時(shí)代。
單機(jī)調(diào)度:資源高壓力下的SLA保障一直以來是學(xué)術(shù)界和工業(yè)界發(fā)力的方向。Borg等開源探索都假設(shè)在資源沖突時(shí)無條件向在線業(yè)務(wù)傾斜;但是離線業(yè)務(wù)也有強(qiáng)SLA需求,不能隨意犧牲。
展望未來,我們看到可能的發(fā)展方向/趨勢(shì)主要有:
1.K8S統(tǒng)一調(diào)度框架:Google Borg很早就證明了統(tǒng)一的資源管理有利于最優(yōu)匹配和削峰填谷,盡管K8S在“非在線服務(wù)”調(diào)度上仍然有挑戰(zhàn),K8S準(zhǔn)確的定位和靈活的插件式設(shè)計(jì)應(yīng)該可以成為最終的贏家。大數(shù)據(jù)調(diào)度器(比如KubeBatch)是目前投資的一個(gè)熱點(diǎn)。
2.調(diào)度算法多元化和智能化:隨各種資源的解耦(例如,存儲(chǔ)計(jì)算分離),調(diào)度算法可以在單一維度做更深度的優(yōu)化,AI優(yōu)化是關(guān)鍵方向(實(shí)際上,很多年前Google Borg就已經(jīng)采用蒙特卡洛Simulation做新任務(wù)資源需求的預(yù)測(cè)了)。
3.面向異構(gòu)硬件的調(diào)度支持:眾核架構(gòu)的ARM成為通用計(jì)算領(lǐng)域的熱點(diǎn),GPU/TPU等AI加速芯片也成為主流,調(diào)度系統(tǒng)需要更好支持多種異構(gòu)硬件,并抽象簡(jiǎn)單的接口,這方面K8S插件式設(shè)計(jì)有明顯的優(yōu)勢(shì)。
2.3 元數(shù)據(jù)服務(wù)統(tǒng)一化
元數(shù)據(jù)服務(wù)支撐了大數(shù)據(jù)平臺(tái)及其之上的各個(gè)計(jì)算引擎及框架的運(yùn)行,元數(shù)據(jù)服務(wù)是在線服務(wù),具有高頻、高吞吐的特性,需要具備提供高可用性、高穩(wěn)定性的服務(wù)能力,需要具備持續(xù)兼容、熱升級(jí)、多集群(副本)管理等能力。主要包括以下三方面的功能:
DDL/DML的業(yè)務(wù)邏輯,保障ACID特性,保障數(shù)據(jù)完整性和一致性
授權(quán)與鑒權(quán)能力,保證數(shù)據(jù)訪問的安全性
Meta(元數(shù)據(jù)) 的高可用存儲(chǔ)和查詢能力,保障作業(yè)的穩(wěn)定性
第一代數(shù)據(jù)平臺(tái)的元數(shù)據(jù)系統(tǒng),是Hive的Hive MetaStore(HMS)。在早期版本中HMS元數(shù)據(jù)服務(wù)是Hive的內(nèi)置服務(wù),元數(shù)據(jù)更新(DDL)以及DML作業(yè)數(shù)據(jù)讀寫的一致性和Hive的引擎強(qiáng)耦合,元數(shù)據(jù)的存儲(chǔ)通常托管在MySQL等關(guān)系數(shù)據(jù)庫(kù)引擎。
隨著客戶對(duì)數(shù)據(jù)加工處理的一致性(ACID),開放性(多引擎,多數(shù)據(jù)源),實(shí)時(shí)性,以及大規(guī)模擴(kuò)展能力的要求越來越高,傳統(tǒng)的HMS逐步局限于單集群,單租戶,Hive為主的單個(gè)企業(yè)內(nèi)部使用,為保障數(shù)據(jù)的安全可靠,運(yùn)維成本居高不下。這些缺點(diǎn)在大規(guī)模生產(chǎn)環(huán)境逐步暴露出來。
第二代元數(shù)據(jù)系統(tǒng)的代表,有開源體系的Apache IceBerg,和云原生體系的阿里巴巴大數(shù)據(jù)平臺(tái)MaxCompute的元數(shù)據(jù)系統(tǒng)。
IceBerg是開源大數(shù)據(jù)平臺(tái)最近兩年出現(xiàn)的獨(dú)立于引擎和存儲(chǔ)的“元數(shù)據(jù)系統(tǒng)”,其要解決的核心問題是大數(shù)據(jù)處理的ACID,以及表和分區(qū)的元數(shù)據(jù)的規(guī)模化之后性能瓶頸。在實(shí)現(xiàn)方法上IceBerg的ACID依托了文件系統(tǒng)POSIX的語義,分區(qū)的元數(shù)據(jù)采用了文件方式存儲(chǔ),同時(shí),IceBerg的Table Format獨(dú)立于Hive MetaStore的元數(shù)據(jù)接口,因此在引擎的adoption上成本很高,需要各個(gè)引擎改造。
基于未來的熱點(diǎn)和趨勢(shì)的分析,開放的,托管的統(tǒng)一元數(shù)據(jù)服務(wù)越來越重要,多家云廠商,都開始提供了DataCatalog服務(wù),支持多引擎對(duì)湖和倉(cāng)數(shù)據(jù)存儲(chǔ)層的訪問。
對(duì)比第一代與第二代元數(shù)據(jù)系統(tǒng):
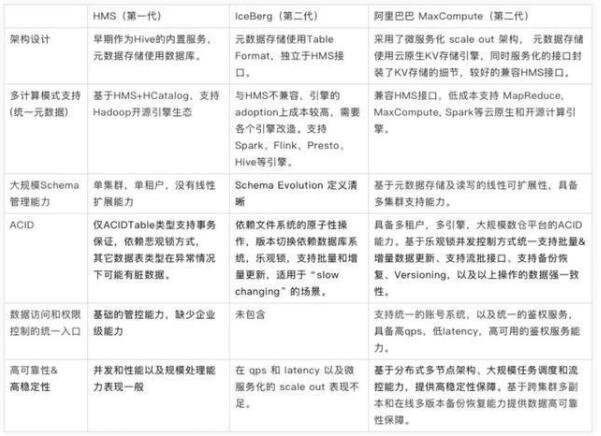
展望未來,我們看到可能的發(fā)展方向/趨勢(shì)主要有:
1.趨勢(shì)一:湖倉(cāng)一體進(jìn)一步發(fā)展下,元數(shù)據(jù)的統(tǒng)一化,以及對(duì)湖上元數(shù)據(jù)和數(shù)據(jù)的訪問能力建設(shè)。如基于一套賬號(hào)體系的統(tǒng)一的元數(shù)據(jù)接口,支持湖和倉(cāng)的元數(shù)據(jù)的訪問能力。以及多種表格式的ACID的能力的融合,這個(gè)在湖上數(shù)據(jù)寫入場(chǎng)景越來越豐富時(shí),支持Delta,Hudi,IceBerg表格式會(huì)是平臺(tái)型產(chǎn)品的一個(gè)挑戰(zhàn)。
2.趨勢(shì)二:元數(shù)據(jù)的權(quán)限體系轉(zhuǎn)向企業(yè)租戶身份及權(quán)限體系,不再局限于單個(gè)引擎的限制。
3.趨勢(shì)三:元數(shù)據(jù)模型開始突破關(guān)系范式的結(jié)構(gòu)化模型,提供更豐富的元數(shù)據(jù)模型,支持標(biāo)簽,分類以及自定義類型和元數(shù)據(jù)格式的表達(dá)能力,支持AI計(jì)算引擎等等。
本文詳細(xì)闡述了后紅海時(shí)代,當(dāng)下大數(shù)據(jù)體系的演進(jìn)熱點(diǎn)是什么,以及大數(shù)據(jù)體系下部分子領(lǐng)域架構(gòu)的技術(shù)解讀。

















