啥是 MySQL 事務隔離級別?
本文轉載自微信公眾號「SH的全棧筆記」,作者SH的全棧筆記。轉載本文請聯系SH的全棧筆記公眾號。
之前發過一篇文章,簡單了解 MySQL 中相關的鎖,里面提到了,如果我們使用的 MySQL 存儲引擎為 InnoDB ,并且其事務隔離級別是 RR 可重復讀的話,是可以避免幻讀的。
但是沒想到,都 1202 年了都還有人杠,說 InnoDB 的 RR 隔離級別下會出現幻讀,只能依靠 gap 和 next-key 這兩個鎖來防止幻讀 ,最開始我還以為是他真的不知道這個點,就跟他聊,最后聊下來發現,發現是在鉆牛角尖。
這個在下面講到 可重復讀 的隔離級別時會講。
本來我覺得事務隔離級別這玩意兒太簡單沒啥可講的,但是經過了上面這件事,我打算詳細的把事務隔離給講講。接下來順便就把 InnoDB 所有的事務隔離級別給摟一遍。
ACID
在聊事務隔離級別之前,我們需要知道 ACID 模型。
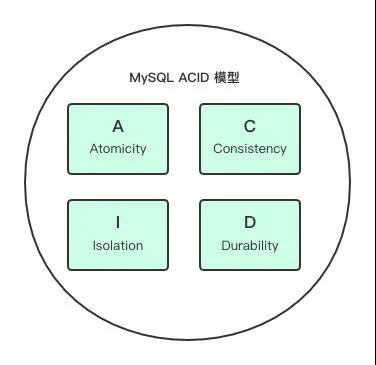
ACID 模型
- 分別代表:
- Atomicity 原子性
- Consistency 一致性
- Isolation 隔離型
- Durability 持久性
原子性,代表 InnoDB 事務中,所有的操作要么全部成功,要么全部失敗,不會處于某個中間狀態。說的更通俗一點,如果事務 A 失敗,其所做的所有的更改應該全部回滾。
一致性,主要是保護數據的一致性,防止由于數據庫的崩潰而導致的數據一致性問題。舉個例子,我們更新 MySQL 的數據,更新的數據會先到 InnoDB 的 Buffer Pool 中,如果此時 MySQL 所在的機器突然意外重啟了,如果 InnoDB 沒有崩潰恢復機制,之前更新的數據就會丟失,數據的一致性問題就出現了。
很多其他的博客寫的是事務開要始前后,數據的完整性沒有被破壞。我表示看了根本看不懂,太抽象了。
隔離性,主要是指事務之間的隔離,再具體一點,就是我們本篇文章要討論的事務隔離級別了。
持久性,主要是指我們新增或者刪除了某些數據,一旦成功,這些操作應該需要被持久化到磁盤上去。
ACID 模型可以理解成數據庫的設計范式,主要關注點在數據數據、及其本身的可靠性。而 MySQL 中的 InnoDB 就完全遵守 ACID 模型,并且在存儲引擎層就支持數據一致性的校驗和崩潰恢復的機制。
而 ACID 中的隔離型,就是我們這篇文章中討論的重點。
事務隔離級別
有很多文章上來就直接介紹事務隔離級別的種類,這個種類啥意思,那個種類怎么用。但我認為應該先了解為什么需要事務隔離級別,以及事務隔離級別到底解決了什么問題,這才是關鍵。
我們知道 InnoDB 中同時會有多個事務對數據進行操作,舉一些例子:
- 假如事務A需要查詢 id=1 的數據,但是事務A查詢完畢之后,事務B對 id=1 的數據做了更新,那此時事務A再次執行查詢,應該看到更新前的數據還是更新后的數據?
- 或者還是上面那個例子,事務A讀取了事務B的數據,但是如果事務B進行回滾了怎么辦?事務A的數據不就變成了臟數據?
- 又或者事務A讀取了 1-3點 的日程安排,有4條,但是事務A讀取完成后事務B又向 1-3 點這個時間段插入了一條新的安排,那么事務A如果再次讀取,應該顯示4條日程安排還是5條?
以上的這些問題,就需要事務隔離級別來回答了。其實以上的三種情況分別對應不可重復讀、臟讀和幻讀。InnoDB 通過事務隔離級別分別的解決了上面的問題。所有的事務隔離級別如下:
- READ UNCOMMITTED 讀未提交
- READ COMMITTED 讀已提交
- REPEATABLE READ 可重復讀
- SERIALIZABLE 串行化
InnoDB 默認的事務隔離級別為 REPEATABLE READ 。
讀未提交
事務A讀取了事務B還未提交的數據
如果事務B此時出錯了進行了回滾,那么事務A讀取到的數據就成為了臟數據,從而造成臟讀。
如果事務B又更新事務A讀取的數據,那么事務A再次讀取,讀取到了事務B修改的結果,這造成了不可重復讀。
而如果事務B又新增了數據,事務A再次讀取,會讀取到事務B新增的數據,這造成了幻讀。
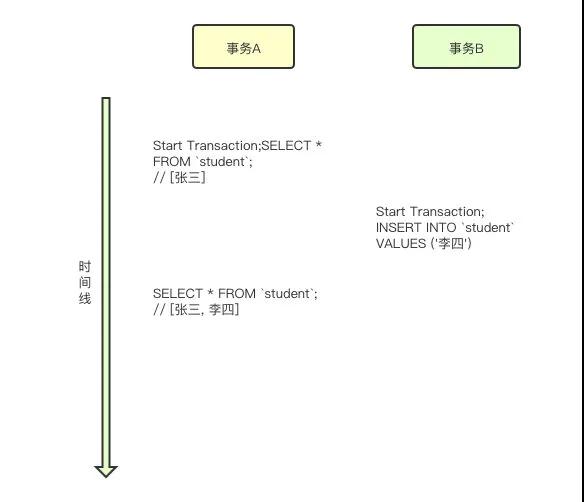
所以總結來說,在讀未提交這個隔離級別下,會造成以下的問題:
- 臟讀
- 不可重復讀
- 幻讀
讀已提交
事務A讀取了事務B已經提交的數據
如果事務B更新了事務A讀取到的數據,并且提交,那么當事務A再次進行讀取,就會讀取到其他事務的變更,就造成了不可重復讀。
同理,如果事務B新增了數據并且提交,事務A再次進行讀取時拿到了事務B剛剛提交的數據,這就造成了幻讀。
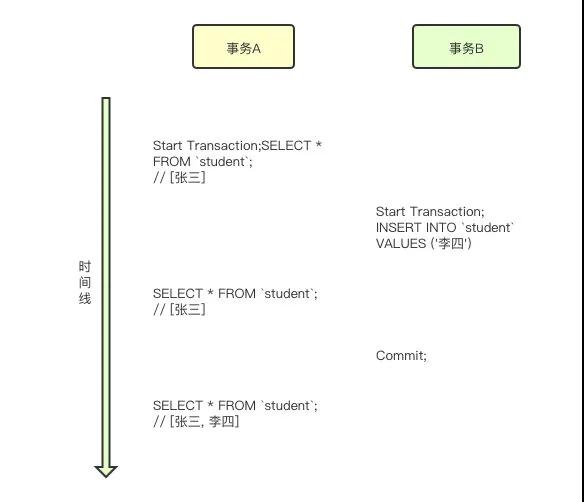
所以總結來說,在讀已提交的隔離級別下,會造成:
- 不可重復讀
- 幻讀
可重復讀
事務A不會讀取到事務B更新的數據,也不會讀到事務B新增的數據
在可重復讀場景下,不會出現臟讀、不會出現不可重復讀,可能會出現幻讀。
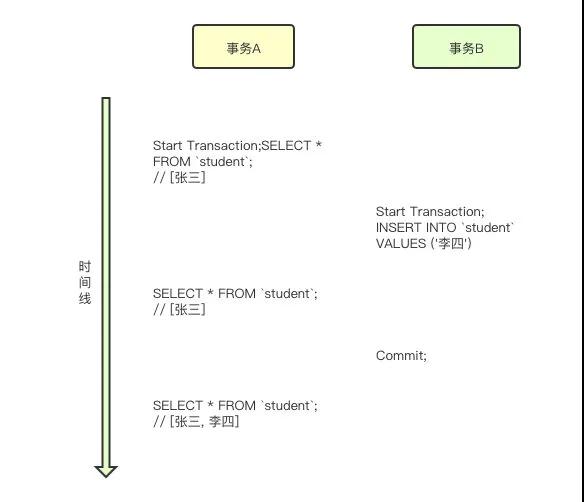
無論事務B做了什么操作,事務A查詢到的 id=1 的數據都是張三。
但是,在某些情況下,還是可能會出現 幻讀。可重復讀 只是在某些情況下會產生幻讀,但絕對不是 InnoDB 無法避免幻讀。首先,InnoDB 在 RR 隔離級別下有很明確的解決幻讀的方式,那就是——臨鍵鎖,一種組合了 gap 鎖和記錄鎖的鎖。
接下來舉個例子來看在 RR 隔離級別下,什么情況會出現幻讀,什么情況下不會出現幻讀。首先是 可能會出現幻讀。
- SELECT * FROM `student` WHERE `id` > 1;
由于 InnoDB 有 MVCC 來進行多事務的并發,此時 SELECT 走的是快照讀,不會加鎖,所以無論插入多少 id > 1 的數據,在同一個事物內執行上述的 SQL 是不會出現幻讀的。
但是如果顯示的進行加鎖,就會出現問題。
- SELECT * FROM `student` WHERE `id` > 1 FOR UPDATE
為啥這樣就會有問題呢?對 SELECT 顯示的進行加鎖之后,無論是加的共享鎖還是排他鎖,都會進行 當前讀,而一旦執行了當前讀,就能夠讀取到其他事物提交的 id > 1 的數據。
串行化
所以事務被強制的串行執行
這樣從根本上就避免了并發的問題,但是這樣會使得 MySQL 的性能下降。因為現在同一時間只能有一個事務在運行。
EOF
關于事務隔離級別就先介紹到這,之后有時間了就把 事務隔離級別 的底層原理給摟一遍。