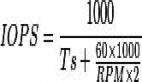分布式存儲(chǔ)系統(tǒng)可靠性:系統(tǒng)量化估算
一、引言
我們常常聽到衡量分布式存儲(chǔ)系統(tǒng)好壞的兩個(gè)指標(biāo):可用性和可靠性指標(biāo)。
可用性指的是系統(tǒng)服務(wù)的可用性。一般按全年可用時(shí)間除以全年時(shí)間來衡量可用性的好壞,平常我們說的 SLA指標(biāo)就是可用性指標(biāo),這里就不展開細(xì)說。
可靠性指標(biāo)指的是數(shù)據(jù)的可靠性。我們常說的數(shù)據(jù)可靠性11個(gè)9,在對(duì)象存儲(chǔ)中就意味著存儲(chǔ)一千億個(gè)對(duì)象大概會(huì)有1個(gè)文件是不可讀的。由此可見,數(shù)據(jù)可靠性指標(biāo)給分布式存儲(chǔ)系統(tǒng)帶來的挑戰(zhàn)不言而喻。
本文就重點(diǎn)來分析一下分布式系統(tǒng)的數(shù)據(jù)可靠性的量化模型。
二、背景
數(shù)據(jù)的重要性不必多說,基本上數(shù)據(jù)可以稱得上是企業(yè)生命力的核心,是企業(yè)賴以生存的根本。因此數(shù)據(jù)的可靠性是基礎(chǔ)的基礎(chǔ),任何數(shù)據(jù)的丟失都會(huì)給企業(yè)造成無法計(jì)算和彌補(bǔ)的損失。
隨著數(shù)據(jù)規(guī)模的日益增大,環(huán)境更加復(fù)雜,我們大體可以把威協(xié)數(shù)據(jù)可靠性的因素歸為幾大類:
-
硬件故障:主要是磁盤故障、還有網(wǎng)絡(luò)故障、服務(wù)器故障、IDC故障;
-
軟件隱患:內(nèi)核BUG,軟件設(shè)計(jì)上的BUG等;
-
運(yùn)維故障:人為誤操作。
其中,第1類的硬件故障中又以磁盤故障最為頻繁,壞盤對(duì)于從事分布式存儲(chǔ)運(yùn)維的同學(xué)來說再正常不過了。
因此,我們接下來從磁盤故障這個(gè)維度來嘗試量化一下一個(gè)分布式系統(tǒng)的數(shù)據(jù)可靠性。
三、數(shù)據(jù)可靠性量化
為了提高數(shù)據(jù)的可靠性,數(shù)據(jù)副本技術(shù)和EC編碼冗余技術(shù)是分布式系統(tǒng)可靠性最常用的手段了。以多副本為例,副本數(shù)越多,數(shù)據(jù)的可靠性肯定越高。
為了對(duì)分布式系統(tǒng)的數(shù)據(jù)可靠性作一個(gè)量化估算,進(jìn)一步分析得到影響存儲(chǔ)數(shù)據(jù)可靠性的因素主要有:
-
N:分布式系統(tǒng)磁盤的總數(shù),可以很直觀理解,磁盤的數(shù)量是和可靠性強(qiáng)相關(guān),N的大小與數(shù)據(jù)的打散程度有很大關(guān)系。
-
R:副本數(shù),副本數(shù)越高數(shù)據(jù)的可靠性肯定越高,但同時(shí)也會(huì)帶來更大的存儲(chǔ)成本。
-
T:RecoveryTime出現(xiàn)壞盤情況下數(shù)據(jù)恢復(fù)的時(shí)間,這個(gè)也很好理解,恢復(fù)時(shí)間越短,數(shù)據(jù)的可靠性越高。
-
AFR:Annualized Failure Rate磁盤的年度故障率,這個(gè)和磁盤本身的質(zhì)量相關(guān),質(zhì)量越好,AFR越低,數(shù)據(jù)的可靠性越高。
-
S:CopySet數(shù)量,一個(gè)盤上的數(shù)據(jù)的冗余在集群中的打散程度,打得越散,則有可能任意壞3塊盤就剛好有數(shù)據(jù)的冗余數(shù)據(jù)都丟失。所以,僅從打散程度這個(gè)維度看,打散程度越小越好。
因此,我們可以用一個(gè)公式表示分布式系統(tǒng)的全年數(shù)據(jù)可靠性:
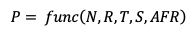
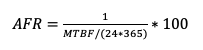
3.1 磁盤年故障率:AFR
AFR:Annualized Failure Rate又稱為硬盤年度失敗概率,一般用來反映一個(gè)設(shè)備在全年的使用出故障的概率,可以很直觀的理解,AFR越低,系統(tǒng)的可靠性越高,因?yàn)锳FR與系統(tǒng)的數(shù)據(jù)可靠性強(qiáng)相關(guān);而這個(gè)指標(biāo)通常又是由另一個(gè)磁盤質(zhì)量指標(biāo)MTBF(Mean Time Before Failure)推算出來,而MTBF各大硬盤廠商都是有出廠指標(biāo)的,比如說希捷的硬盤出廠的MTBF指標(biāo)為120W個(gè)小時(shí)。以下為AFR的計(jì)算公式:
但是實(shí)際使用當(dāng)中往往MTBF會(huì)低于硬盤出廠指標(biāo)。Google就根據(jù)他們的線上集群的硬盤情況進(jìn)行了統(tǒng)計(jì)計(jì)算AFR如下:
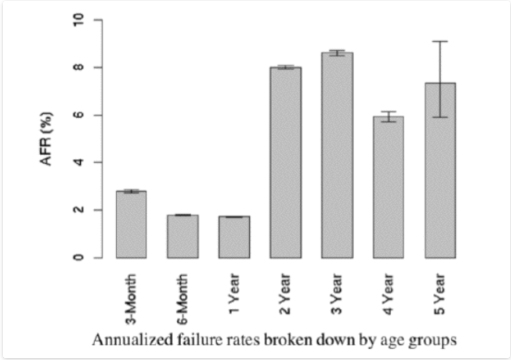
( 5年內(nèi)硬盤AFR統(tǒng)計(jì)情況 )
(圖片來自 http://oceanbase.org.cn )
3.2 副本數(shù)據(jù)復(fù)制組:CopySet
副本數(shù)據(jù)復(fù)制組CopySet:用通俗的話說就是,包含一個(gè)數(shù)據(jù)的所有副本的節(jié)點(diǎn),也就是一個(gè)copyset損壞的情況下,數(shù)據(jù)會(huì)丟失。
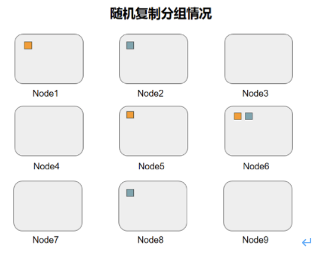
(單個(gè)數(shù)據(jù)隨機(jī)復(fù)制分組示意圖)
(圖片來自 https://www.dazhuanlan.com )
如圖2所示,以9塊盤為例,這9塊盤的copyset就是:{1,5,6},{2,6,8},如果不做任何特殊處理,數(shù)據(jù)多了之后,數(shù)據(jù)的隨機(jī)分布如下:
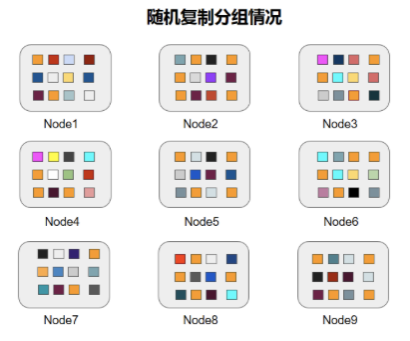
(海量數(shù)據(jù)隨機(jī)分布示意圖)
(圖片來自 https://www.dazhuanlan.com )
最大CopySet:如上圖所示,12個(gè)數(shù)據(jù)的多副本隨機(jī)打散到9塊盤上,從上圖中任決意挑3塊盤都可以挑出包含某個(gè)數(shù)據(jù)的三個(gè)副本,就相當(dāng)于從n個(gè)元素中取出k個(gè)元素的組合數(shù)量為:
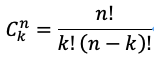
最大的CopySet配置下一旦有三塊磁盤壞了,丟數(shù)據(jù)的概率是100%。另外一種情況,數(shù)據(jù)的分布是有規(guī)律的,比如一塊盤上的數(shù)據(jù)只會(huì)在另外一塊盤上備份,如下圖所示,在這種情況下數(shù)據(jù)覆蓋的CopySet只有(1,5,7)、(2,4,9)、(3,6,8)也就是說這種情況下CopySet為3。我們不難理解,9塊盤的最小CopySet為3。也就是N/R。
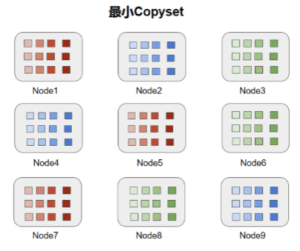
(磁盤粒度冗余分布示意圖)
因此,CopySet數(shù)量S符合以下:
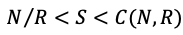
既然CopySet數(shù)據(jù)可以最小為N/R,能不能把CopySet數(shù)量調(diào)到最小,答案當(dāng)然是不行的,因?yàn)椋环矫嫒绻鸆opySet調(diào)到最小,當(dāng)有一個(gè)盤壞了后,只有其它2塊盤進(jìn)行這塊盤的恢復(fù)操作,這樣數(shù)據(jù)的恢復(fù)時(shí)間又變長(zhǎng)了,恢復(fù)時(shí)間變長(zhǎng)也會(huì)影響數(shù)據(jù)的可靠性;而且一旦命中了CopySet中的一個(gè),則丟失的數(shù)據(jù)量規(guī)模非常大。因此,分布式系統(tǒng)中的CopySet的量和恢復(fù)速度RecoveryTime是一個(gè)均衡整個(gè)系統(tǒng)數(shù)據(jù)可靠性和集群可用性的參數(shù)。
文獻(xiàn)【1】Copysets: Reducing the Frequency of Data Loss in Cloud Storage提供了一種分布式系統(tǒng)的CopySet Replication的選擇策略,在分布式存儲(chǔ)系統(tǒng)當(dāng)中比如對(duì)象存儲(chǔ)和文件存儲(chǔ)當(dāng)中,還有一種方式可以根據(jù)系統(tǒng)的可靠性和可用性進(jìn)行調(diào)整系統(tǒng)CopySets的數(shù)量,就是在隨機(jī)放置情況下,使用小文件合并成大文件的存儲(chǔ)策略,可以通過控制大文件的大小從而控制每個(gè)磁盤上大文件的數(shù)量,比如100G一個(gè)文件,8T盤上的最大文件存儲(chǔ)數(shù)量也就是8T/100G = 80個(gè)文件,也就是說一個(gè)8T的盤的數(shù)據(jù)最多打散到了80塊其它的盤上,對(duì)于集群盤遠(yuǎn)大于80的系統(tǒng)顯然也能夠很好的控制一個(gè)數(shù)據(jù)盤的數(shù)據(jù)打散程度。
因此,在磁盤上的分片是隨機(jī)打散的情況下,CopySets數(shù)量可以量化為以下公式:
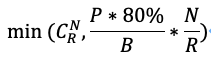
其中,P為磁盤的容量,B為分片大小,N為系統(tǒng)磁盤的數(shù)據(jù),R為副本數(shù)。80%為使用率。
3.3 數(shù)據(jù)恢復(fù)時(shí)間:Recovery Time
數(shù)據(jù)恢復(fù)時(shí)間對(duì)數(shù)據(jù)可靠性影響很大,這個(gè)很好理解,因此縮短數(shù)據(jù)恢復(fù)時(shí)間可以有效降低數(shù)據(jù)丟失的風(fēng)險(xiǎn)。前面已經(jīng)介紹數(shù)據(jù)恢復(fù)時(shí)間和磁盤上數(shù)據(jù)打散程度強(qiáng)相關(guān),同時(shí)數(shù)據(jù)恢復(fù)時(shí)間也與服務(wù)本身的可用性相關(guān)。
比如磁盤帶寬為200MB/s,假設(shè)留給恢復(fù)可用的帶寬為20%就是40MB/s,磁盤容量為P,使用率為80%,B為BlockSize大小,則恢復(fù)速度可按以下方式計(jì)算:
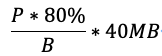
四、可靠性模型推導(dǎo)
4.1 磁盤故障與泊松分布
泊松分布:泊松分布其實(shí)是二項(xiàng)分布的極限情況,泊松分布公式如下:
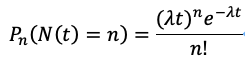
(圖片來自 知乎 )
其中,t為時(shí)間周期(小時(shí)為單位),n為故障的盤的塊數(shù),N為整個(gè)集群的盤的數(shù)量,為單位時(shí)間1小時(shí)內(nèi)出故障的磁盤平均數(shù)。
從3.1節(jié)我們已經(jīng)介紹過了磁盤一年之內(nèi)出故障的概率為AFR,那么單位時(shí)間1個(gè)小時(shí)的時(shí)間周期磁盤出故障的概率為FIT(Failures in Time):
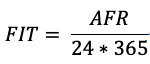
那么N塊盤的集群在單位時(shí)間1小時(shí)內(nèi)出故障的盤的數(shù)量為FIT*N,換句話說,也就是單位時(shí)間1小時(shí)內(nèi)出故障的磁盤平均數(shù)。因此可以得到:
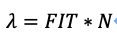
4.2 系統(tǒng)全年可靠性計(jì)算推導(dǎo)
由4.1我們得到磁盤故障是符合泊松分布,N塊盤的集群中在t小時(shí)內(nèi)有n塊盤故障的概率:
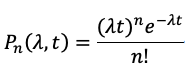
接下來我們以3副本為例,來推導(dǎo)一下全年集群沒有數(shù)據(jù)丟失的概率的量化模型,3副本情況下,全年集群沒有數(shù)據(jù)丟失的概率不太好量化,我們可以通過計(jì)算全年集群出現(xiàn)數(shù)據(jù)丟失的概率,然后全年集群沒有數(shù)據(jù)丟失的概率就以計(jì)算出來:
全年集群出現(xiàn)數(shù)據(jù)丟失的概率:只有在t(1年)的時(shí)間內(nèi)有第一塊磁盤出現(xiàn)故障之后,然后系統(tǒng)進(jìn)入數(shù)據(jù)恢復(fù)階段,在數(shù)據(jù)恢復(fù)的時(shí)間tr內(nèi)又有第二塊磁盤出現(xiàn)故障,我們先不考慮數(shù)據(jù)恢復(fù)了多少,然后在tr內(nèi)又有第三塊磁盤出現(xiàn)故障,但是這三個(gè)磁盤不一定剛好命中了我們?cè)?.2介紹的copyset復(fù)制組如果命中了copyset,那么集群在全年就真的有出現(xiàn)數(shù)據(jù)丟失了。因?yàn)槿昙撼霈F(xiàn)數(shù)據(jù)丟失的概率和P1,P2,P3,以及Copyset命中概率Pc相關(guān)。
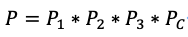
1年時(shí)間t內(nèi)有任意一塊磁盤出現(xiàn)故障的概率為:
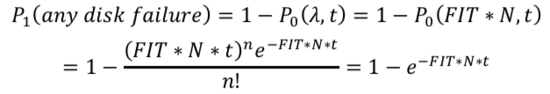
上面這塊磁盤出現(xiàn)問題后,需要馬上恢復(fù),在恢復(fù)時(shí)間tr內(nèi)有另外一塊盤出現(xiàn)故障概率:
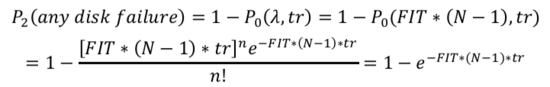
在恢復(fù)時(shí)間tr內(nèi)有第三塊任意盤出現(xiàn)故障的概率:
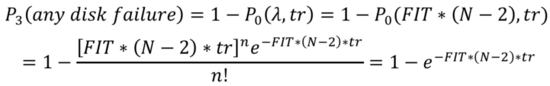
而這三塊出現(xiàn)故障的磁盤剛好命中集群的CopySets的概率為:
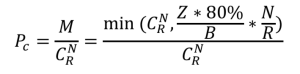
因此,不難得到全年集群出現(xiàn)數(shù)據(jù)丟失的概率P:
然后全年集群不出現(xiàn)數(shù)據(jù)丟失的概率1-P就可以計(jì)算得到了。
4.3 EC冗余全年可靠性計(jì)算推導(dǎo)
EC冗余機(jī)制相對(duì)于三副本機(jī)制是用額外的校驗(yàn)塊來達(dá)到當(dāng)有一些塊出現(xiàn)故障的情況下數(shù)據(jù)不會(huì)丟,按(D,E)數(shù)據(jù)塊進(jìn)行EC編碼,那么在計(jì)算EC冗余下的全年集群數(shù)據(jù)丟失概率的時(shí)候,EC模式下的恢復(fù)速度tr和三副本肯定是不一樣的,另外,EC模式下的copysets是不一樣的,EC模式是允許E個(gè)數(shù)據(jù)塊丟失,而且是在D個(gè)數(shù)據(jù)塊有任意的E個(gè)數(shù)據(jù)塊丟失數(shù)據(jù)都找不回來了,因此,不難得出,EC模式的全年集群出現(xiàn)數(shù)據(jù)丟失的概率P,以下公式,默認(rèn)E為4,也就是丟失4個(gè)數(shù)據(jù)塊:
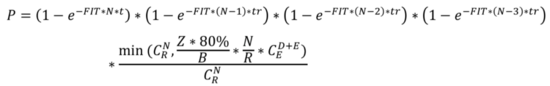
相對(duì)于三副本模式來說,EC模式的copyset需要考慮在D+E個(gè)塊當(dāng)中丟失其中任意E個(gè)塊,則EC模式下的copyset數(shù)為:
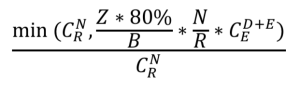
五、可靠性模型估算
5.1 量化模型影響因素
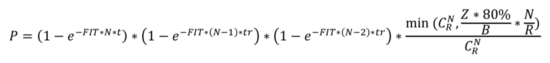
以三副本為例,從以上量化的全集群出故障的概率計(jì)算公式可以得到影響的因素有:
-
N:集群的盤的個(gè)數(shù);
-
FIT:就也是1小時(shí)磁盤的故障率,可以由AFR得到;
-
t:這個(gè)是固定1年;
-
tr:恢復(fù)時(shí)間,單位為小時(shí),和恢復(fù)速度W和磁盤存儲(chǔ)量、分片大小相關(guān);
-
R:副本數(shù);
-
Z:磁盤的存儲(chǔ)總空間;
-
B:分片或者Block的大小,小文件合并成大文件的最大Size。
5.2 可靠性量化計(jì)算
接下來我們把影響可靠性計(jì)算的幾個(gè)因素根據(jù)生產(chǎn)集群的現(xiàn)狀帶入模型計(jì)算可靠性計(jì)算:
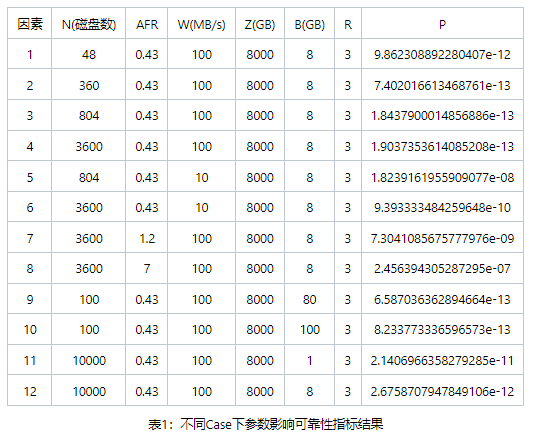
結(jié)合4.2的磁盤故障與可靠性的推導(dǎo),通過表格中10個(gè)case的計(jì)算,可以看到:
Case 1,2,3通過擴(kuò)展磁盤的數(shù)量從48塊盤到804再到3600塊盤,可靠性從11個(gè)9提高到接近13個(gè)9,然后804塊盤到3600塊盤還是維護(hù)在13個(gè)9,按理說,集群的規(guī)模增大,增3塊盤的概率會(huì)提高,但是由于恢復(fù)速度也隨著磁盤的增加而線性增加,因此,可靠性一直在提升,而從804到3600塊盤,可靠性沒有增加,是因?yàn)檫@時(shí)候恢復(fù)速度已經(jīng)不隨磁盤增加而線性增大,因?yàn)樵诖疟P量很大后,決定恢復(fù)速度因素就變?yōu)閱伪P分片個(gè)數(shù)。
Case 5,6比較好理解,恢復(fù)速度由100M/S變?yōu)?0M/S,可靠性降低2個(gè)以上數(shù)量級(jí);
Case 7,8也比較好理解,AFR由0.43提高到1.2再提高到7,可靠性降低了3個(gè)數(shù)量級(jí);
Case 9,10比較繞,磁盤數(shù)在100的情況下,Block大小由80G一個(gè)提高到100G一個(gè),可靠性降低了,這種情況下是因?yàn)榛謴?fù)速度提高,CopySet也提高,但速度影響更大導(dǎo)致。
Case 11,12也比較繞,由于我們限定了恢復(fù)速度不能超過5分鐘(模擬線上,因?yàn)橄到y(tǒng)檢測(cè)壞盤,自動(dòng)踢盤等操作也需要時(shí)間),這兩個(gè)Case下的CopySet都超級(jí)大,所以恢復(fù)的并發(fā)度都非常高,但受限于5分鐘限定,所以兩個(gè)Case的恢復(fù)速度一樣,所以PK CopySet的數(shù)量,Case12的CopySet比Case11的CopySet要小,所以更不容易丟失,所以可靠性更高。
六、總結(jié)
-
首先AFR越低越好,AFR是直接決定整個(gè)集群磁盤故障引起的數(shù)據(jù)丟失概率的最大因素;
-
其次是恢復(fù)速度:在不影響服務(wù)可用性指標(biāo)的前提下,最大限度的提高磁盤故障的恢復(fù)帶寬是提高集群數(shù)據(jù)可靠性的另一個(gè)重要因素;
-
如果在恢復(fù)速度受限的前提下,比如系統(tǒng)架構(gòu)設(shè)計(jì)導(dǎo)致的相關(guān)發(fā)現(xiàn)壞盤到踢盤到進(jìn)行數(shù)據(jù)恢復(fù)操作啟動(dòng)為5分鐘,那么可以通過合理降低磁盤數(shù)據(jù)的分散程度降低CopySet,如果系統(tǒng)是按分片粒度或Block粒度,則相應(yīng)的以提高Block粒度來降低數(shù)據(jù)分散程度的方式來提高數(shù)據(jù)的可靠性。