分布式系統(tǒng)的“腦裂”到底是個什么玩意?
本文轉(zhuǎn)載自微信公眾號「程序新視界」,作者丑胖俠二師兄 。轉(zhuǎn)載本文請聯(lián)系程序新視界公眾號。
目前大多數(shù)項(xiàng)目都在往分布式上發(fā)展,一旦系統(tǒng)采用分布式系統(tǒng),便會引入更多復(fù)雜場景和解決方案。比如,當(dāng)你在系統(tǒng)中使用了Elasticsearch、ZooKeeper集群時,你是否了解過集群的“腦裂”現(xiàn)象?又是否知道它們是如何解決腦裂問題的?
如果這些都還未了解,那么你對分布式的了解過于表象了,推薦你讀一讀這篇文章。
下面就以zookeeper為例,帶大家了解一下分布式系統(tǒng)中的腦裂現(xiàn)象及如何解決。
什么是腦裂?
在Elasticsearch、ZooKeeper這些集群環(huán)境中,有一個共同的特點(diǎn),就是它們有一個“大腦”。比如,Elasticsearch集群中有Master節(jié)點(diǎn),ZooKeeper集群中有Leader節(jié)點(diǎn)。
集群中的Master或Leader節(jié)點(diǎn)往往是通過選舉產(chǎn)生的。在網(wǎng)絡(luò)正常的情況下,可以順利的選舉出Leader(后續(xù)以Zookeeper命名為例)。但當(dāng)兩個機(jī)房之間的網(wǎng)絡(luò)通信出現(xiàn)故障時,選舉機(jī)制就有可能在不同的網(wǎng)絡(luò)分區(qū)中選出兩個Leader。當(dāng)網(wǎng)絡(luò)恢復(fù)時,這兩個Leader該如何處理數(shù)據(jù)同步?又該聽誰的?這也就出現(xiàn)了“腦裂”現(xiàn)象。
通俗的講,腦裂(split-brain)就是“大腦分裂”,本來一個“大腦”被拆分成兩個或多個。試想,如果一個人有多個大腦,且相互獨(dú)立,就會導(dǎo)致人體“手舞足蹈”,“不聽使喚”。
了解了腦裂的基本概念,下面就以zookeeper集群的場景為例,來分析一下腦裂的發(fā)生。
zookeeper集群中的腦裂
我們在使用zookeeper時,很少遇到腦裂現(xiàn)象,是因?yàn)閦ookeeper已經(jīng)采取了相應(yīng)的措施來減少或避免腦裂的發(fā)生,這個后面會講到Zookeeper的具體解決方案。現(xiàn)在呢,先假設(shè)zookeeper沒有采取這些防止腦裂的措施。在這種情況下,看看腦裂問題是如何發(fā)生的。
現(xiàn)有6臺zkServer服務(wù)組成了一個集群,部署在2個機(jī)房:
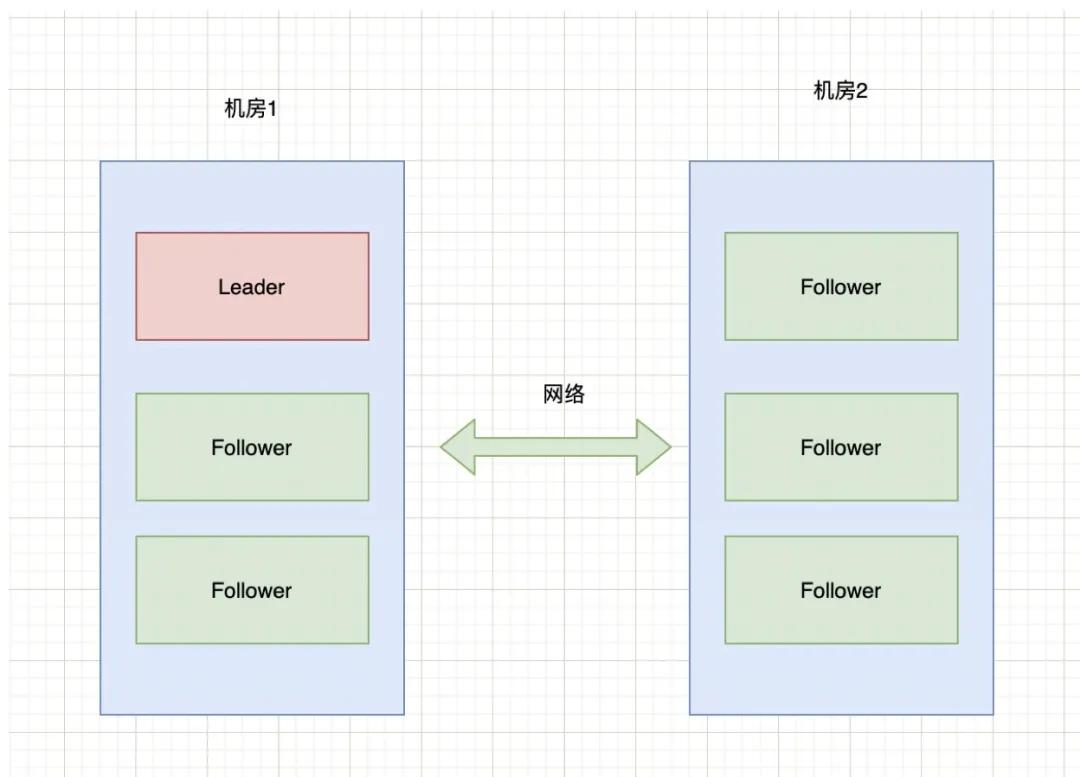
腦裂
正常情況下,該集群只有會有個Leader,當(dāng)Leader宕掉時,其他5個服務(wù)會重新選舉出一個新的Leader。
如果機(jī)房1和機(jī)房2之間的網(wǎng)絡(luò)出現(xiàn)故障,暫時不考慮Zookeeper的過半機(jī)制,那么就會出現(xiàn)下圖的情況:
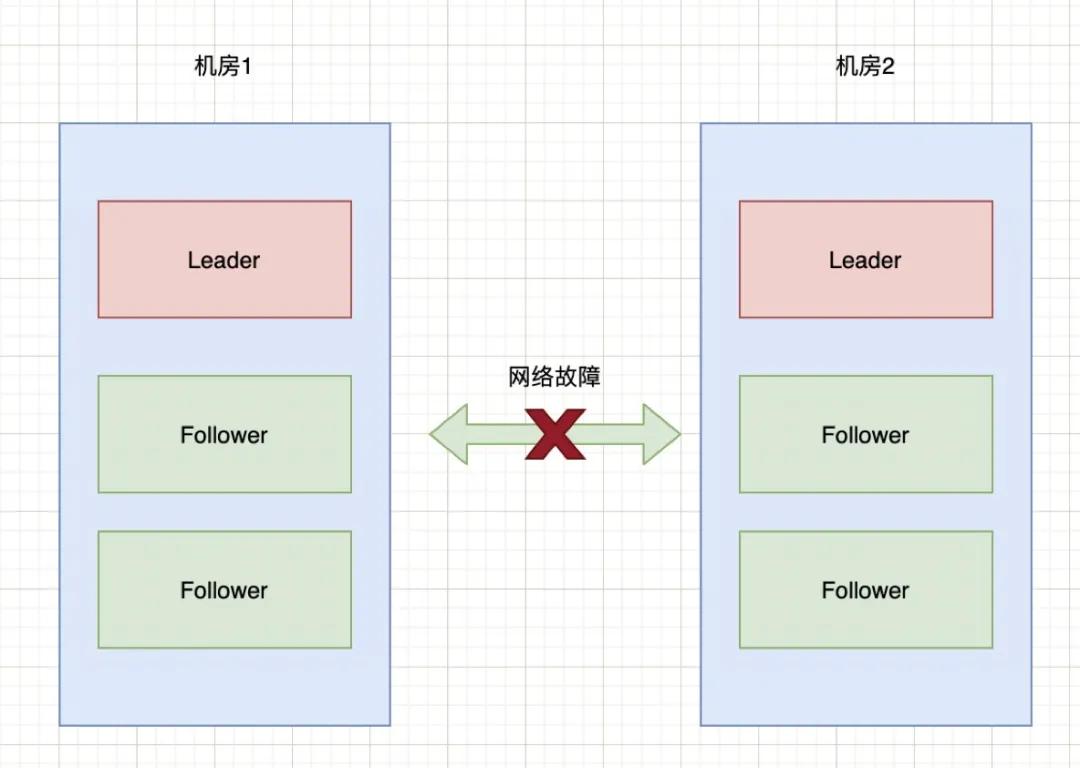
腦裂
也就是說機(jī)房2的三臺服務(wù)檢測到?jīng)]有Leader了,于是開始重新選舉,選舉出一個新Leader來。原本一個集群,被分成了兩個集群,同時出現(xiàn)了兩個“大腦”,這就是所謂的“腦裂”現(xiàn)象。
由于原本的一個集群變成了兩個,都對外提供服務(wù)。一段時間之后,兩個集群之間的數(shù)據(jù)可能會變得不一致了。當(dāng)網(wǎng)絡(luò)恢復(fù)時,就面臨著誰當(dāng)Leader,數(shù)據(jù)怎么合并,數(shù)據(jù)沖突怎么解決等問題。
當(dāng)然,上面的過程只是我們假設(shè)Zookeeper不做任何預(yù)防腦裂措施時會出現(xiàn)的問題。那么,針對腦裂問題,Zookeeper是如何進(jìn)行處理的呢?
Zookeeper的過半原則
防止腦裂的措施有多種,Zookeeper默認(rèn)采用的是“過半原則”。所謂的過半原則就是:在Leader選舉的過程中,如果某臺zkServer獲得了超過半數(shù)的選票,則此zkServer就可以成為Leader了。
底層源碼實(shí)現(xiàn)如下:
- public class QuorumMaj implements QuorumVerifier {
- int half;
- // QuorumMaj構(gòu)造方法。
- // 其中,參數(shù)n表示集群中zkServer的個數(shù),不包括觀察者節(jié)點(diǎn)
- public QuorumMaj(int n){
- this.half = n/2;
- }
- // 驗(yàn)證是否符合過半機(jī)制
- public boolean containsQuorum(Set<Long> set){
- // half是在構(gòu)造方法里賦值的
- // set.size()表示某臺zkServer獲得的票數(shù)
- return (set.size() > half);
- }
- }
上述代碼在構(gòu)建QuorumMaj對象時,傳入了集群中有效節(jié)點(diǎn)的個數(shù);containsQuorum方法提供了判斷某臺zkServer獲得的票數(shù)是否超過半數(shù),其中set.size表示某臺zkServer獲得的票數(shù)。
上述代碼核心點(diǎn)兩個:第一,如何計(jì)算半數(shù);第二,投票屬于半數(shù)的比較。
以上圖6臺服務(wù)器為例來進(jìn)行說明:half = 6 / 2 = 3,也就是說選舉的時候,要成為Leader至少要有4臺機(jī)器投票才能夠選舉成功。那么,針對上面2個機(jī)房斷網(wǎng)的情況,由于機(jī)房1和機(jī)房2都只有3臺服務(wù)器,根本無法選舉出Leader。這種情況下整個集群將沒有Leader。
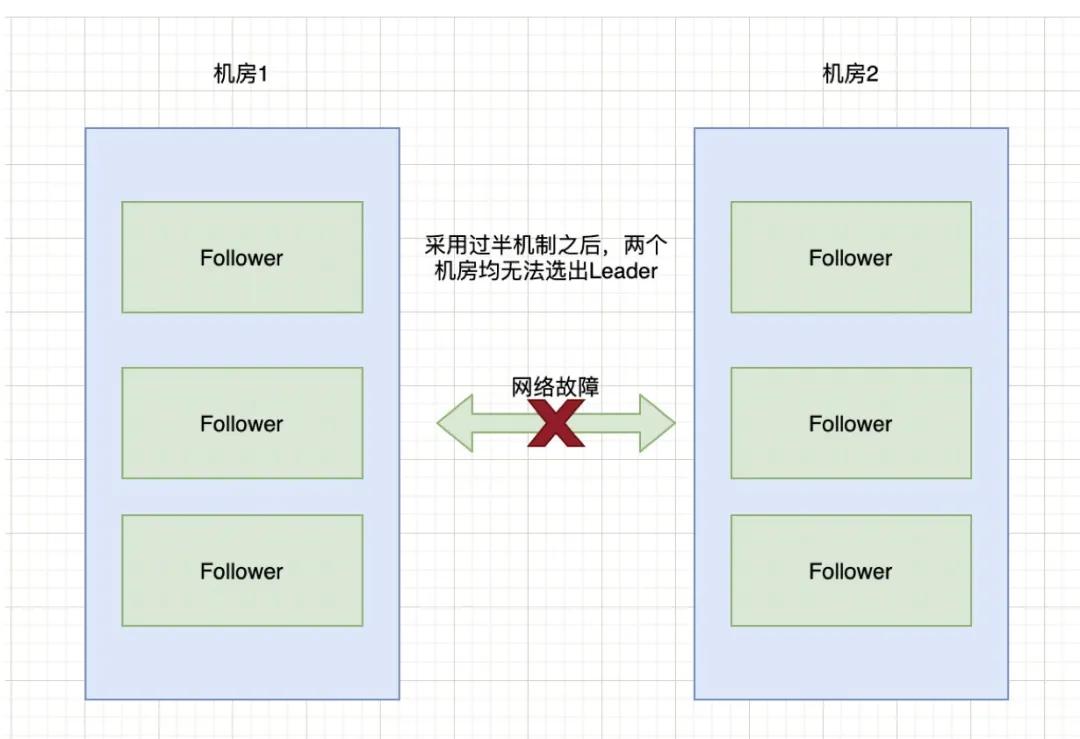
腦裂
在沒有Leader的情況下,會導(dǎo)致Zookeeper無法對外提供服務(wù),所以在設(shè)計(jì)的時候,我們在集群搭建的時候,要避免這種情況的出現(xiàn)。
如果兩個機(jī)房的部署請求部署3:3這種狀況,而是3:2,也就是機(jī)房1中三臺服務(wù)器,機(jī)房2中兩臺服務(wù)器:
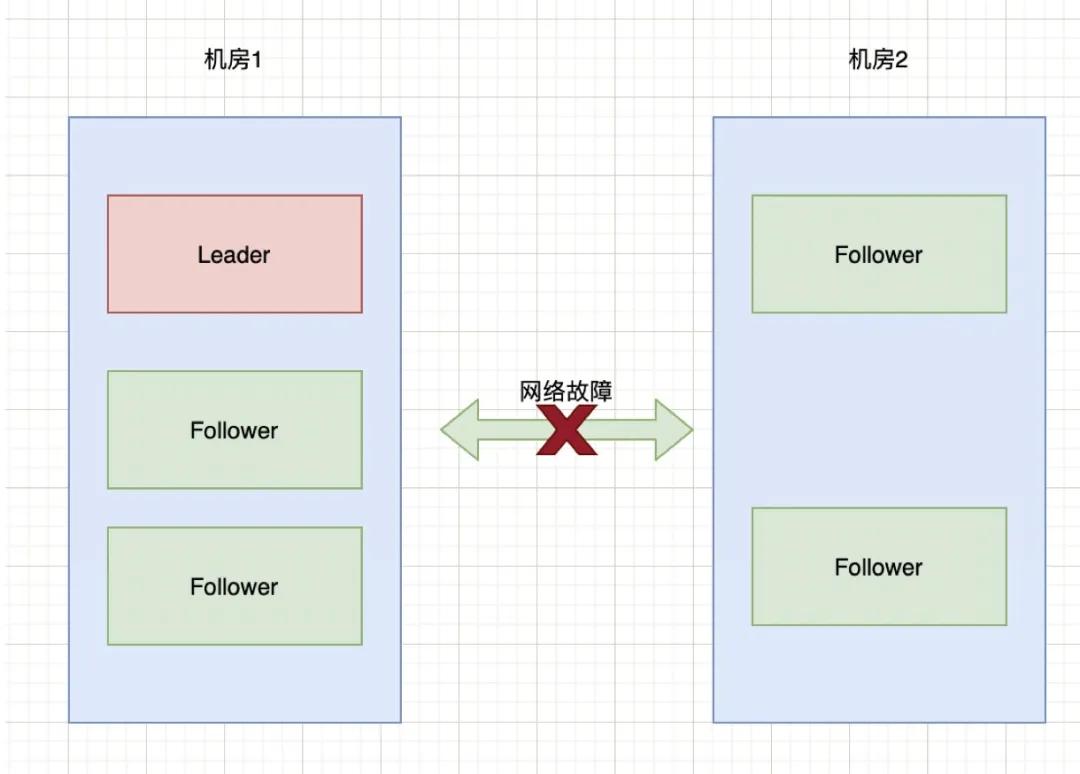
在上述情況下,先計(jì)算half = 5 / 2 = 2,也就是需要大于2臺機(jī)器才能選舉出Leader。那么此時,對于機(jī)房1可以正常選舉出Leader。對于機(jī)房2來說,由于只有2臺服務(wù)器,則無法選出Leader。此時整個集群只有一個Leader。
對于上圖,顛倒過來也一樣,比如機(jī)房1只有2臺服務(wù)器,機(jī)房2有三臺服務(wù)器,當(dāng)網(wǎng)絡(luò)斷開時,選舉情況如下:
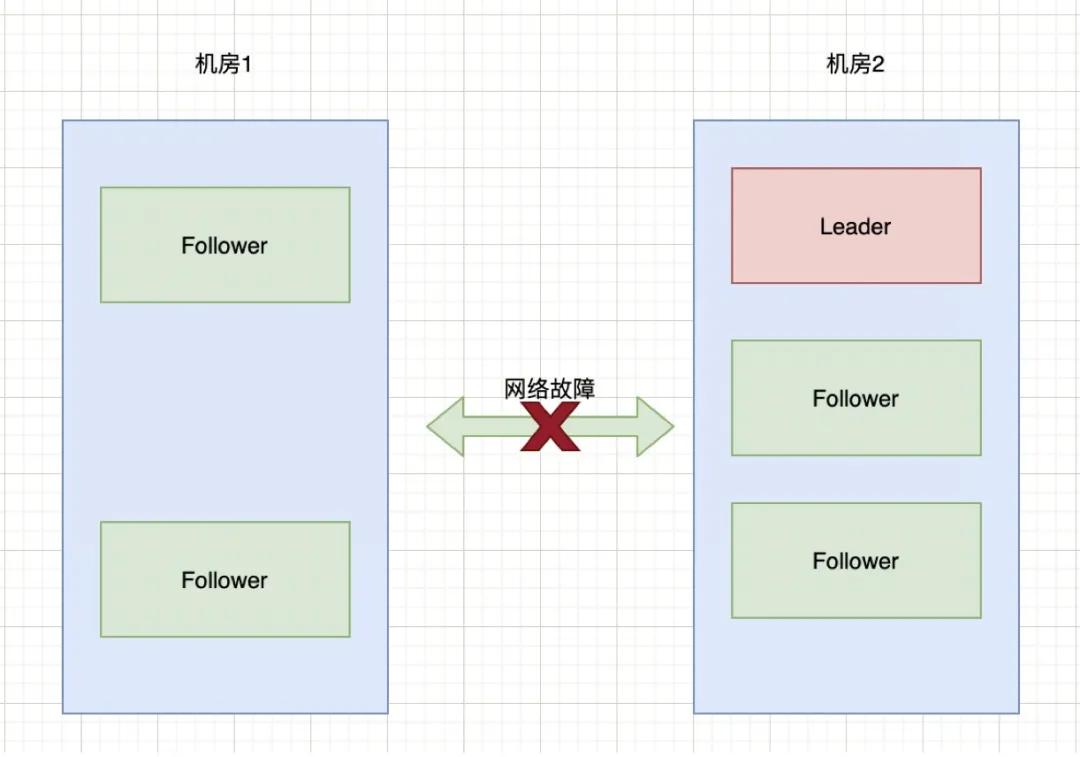
Zookeeper集群通過過半機(jī)制,達(dá)到了要么沒有Leader,要沒只有1個Leader,這樣就避免了腦裂問題。
對于過半機(jī)制除了能夠防止腦裂,還可以實(shí)現(xiàn)快速的選舉。因?yàn)檫^半機(jī)制不需要等待所有zkServer都投了同一個zkServer就可以選舉出一個Leader,所以也叫快速領(lǐng)導(dǎo)者選舉算法。
新舊Leader爭奪
通過過半原則可以防止機(jī)房分區(qū)時導(dǎo)致腦裂現(xiàn)象,但還有一種情況就是Leader假死。
假設(shè)某個Leader假死,其余的followers選舉出了一個新的Leader。這時,舊的Leader復(fù)活并且仍然認(rèn)為自己是Leader,向其他followers發(fā)出寫請求也是會被拒絕的。
因?yàn)閆ooKeeper維護(hù)了一個叫epoch的變量,每當(dāng)新Leader產(chǎn)生時,會生成一個epoch標(biāo)號(標(biāo)識當(dāng)前屬于那個Leader的統(tǒng)治時期),epoch是遞增的,followers如果確認(rèn)了新的Leader存在,知道其epoch,就會拒絕epoch小于現(xiàn)任leader epoch的所有請求。
那有沒有follower不知道新的Leader存在呢,有可能,但肯定不是大多數(shù),否則新Leader無法產(chǎn)生。ZooKeeper的寫也遵循quorum機(jī)制,因此,得不到大多數(shù)支持的寫是無效的,舊leader即使各種認(rèn)為自己是Leader,依然沒有什么作用。
ZooKeeper集群節(jié)點(diǎn)為什么要部署成奇數(shù)
上面講了過半原則,由于Zookeeper默認(rèn)采用的就是這種策略,那就帶來另外一個問題。集群的數(shù)量設(shè)置為多少合適呢?而我們所看到的Zookeeper節(jié)點(diǎn)數(shù)一般都是奇數(shù),這是為什么呢?
首先,只要集群中有過半的機(jī)器是正常工作的,那么整個集群就可對外服務(wù)。那么我們列舉一些情況,來看看在這些情況下集群的容錯性。
如果有2個節(jié)點(diǎn),那么只要掛掉1個節(jié)點(diǎn),集群就不可用了。此時,集群對的容忍度為0;
如果有3個節(jié)點(diǎn),那么掛掉1個節(jié)點(diǎn),還有剩下2個正常節(jié)點(diǎn),超過半數(shù),可以重新選舉,正常服務(wù)。此時,集群的容忍度為1;
如果有4個節(jié)點(diǎn),那么掛掉1個節(jié)點(diǎn),剩下3個,超過半數(shù),可以重新選舉。但如果再掛掉1個,只剩下2個,就無法正常選舉和服務(wù)了。此時,集群的容忍度為1;
依次類推,5個節(jié)點(diǎn),容忍度為2;6個節(jié)點(diǎn)容忍度同樣為2;
既然3個節(jié)點(diǎn)和4個節(jié)點(diǎn)、5個節(jié)點(diǎn)和6個節(jié)點(diǎn),也就是2n和2n-1的容忍度是一樣的,都是n-1。那么,為了節(jié)省資源,為了更加高效(更多節(jié)點(diǎn)參與選舉和通信),為什么不少一個節(jié)點(diǎn)呢?這就是為什么集群要部署成奇數(shù)的原因。
解決腦裂的常見方法
上面提到了Zookeeper使用的過半原則,這里再把解決腦裂問題的場景方式總結(jié)一下。
方法一,Quorums(法定人數(shù))方式
比如3個節(jié)點(diǎn)的集群,Quorums = 2,也就是說集群可以容忍1個節(jié)點(diǎn)失效,這時候還能選舉出1個lead,集群還可用。比如4個節(jié)點(diǎn)的集群,它的Quorums = 3,Quorums要超過3,相當(dāng)于集群的容忍度還是1,如果2個節(jié)點(diǎn)失效,那么整個集群還是無效的。這是ZooKeeper防止“腦裂”默認(rèn)采用的方法。
方法二,添加心跳線
集群中采用多種通信方式,防止一種通信方式失效導(dǎo)致集群中的節(jié)點(diǎn)無法通信。
比如,添加心跳線。原來只有一條心跳線路,此時若斷開,則接收不到心跳報告,判斷對方已經(jīng)死亡。若有2條心跳線路,一條斷開,另一條仍然能夠接收心跳報告,能保證集群服務(wù)正常運(yùn)行。心跳線路之間也可以 HA(高可用),這兩條心跳線路之間也可以互相檢測,若一條斷開,則另一條馬上起作用。正常情況下,則不起作用,節(jié)約資源。
方法三,啟動磁盤鎖定方式。
使用磁盤鎖的形式,保證集群中只能有一個Leader獲取磁盤鎖,對外提供服務(wù),避免數(shù)據(jù)錯亂發(fā)生。但是,也會存在一個問題,若該Leader節(jié)點(diǎn)宕機(jī),則不能主動釋放鎖,那么其他的Follower就永遠(yuǎn)獲取不了共享資源。于是有人在HA中設(shè)計(jì)了"智能"鎖。正在服務(wù)的一方只有在發(fā)現(xiàn)心跳線全部斷開(察覺不到對端)時才啟用磁盤鎖。平時就不上鎖了
方法四,仲裁機(jī)制方式。
腦裂導(dǎo)致的后果是從節(jié)點(diǎn)不知道該連接哪一臺Leader,此時有一個仲裁方就可以解決此問題。比如提供一個參考的IP地址,心跳機(jī)制斷開時,節(jié)點(diǎn)各自ping一下參考IP,如果ping不通,那么表示該節(jié)點(diǎn)網(wǎng)絡(luò)已經(jīng)出現(xiàn)問題,則該節(jié)點(diǎn)需要自行退出爭搶資源,釋放占有的共享資源,將服務(wù)的提供功能讓給功能更全面的節(jié)點(diǎn)。
以上方式可以同時使用,可以減少集群中腦裂情況的發(fā)生,但不能完全保證,比如仲裁機(jī)制中2臺機(jī)器同時宕機(jī),那么此時集群中沒有Leader 可以使用。此時就需要人工干預(yù)了。
小結(jié)
我們經(jīng)常在說,我們的系統(tǒng)使用了分布式,但我們真的了解分布式中場景的一些場景和解決方案嗎?通過本文對腦裂場景的分析及解決方案介紹,你學(xué)到了嗎?來一起學(xué)習(xí)吧。