MaxCompute Spark 資源使用優(yōu)化祥解
1. 概述
本文主要講解MaxCompute Spark資源調(diào)優(yōu),目的在于在保證Spark任務(wù)正常運行的前提下,指導(dǎo)用戶更好地對Spark作業(yè)資源使用進行優(yōu)化,極大化利用資源,降低成本。
2. Sensor
Sensor提供了一種可視化的方式監(jiān)控運行中的Spark進程,每個worker(Executor)及master(Driver)都具有各自的狀態(tài)監(jiān)控圖,可以通過Logview中找到入口,如下圖所示:
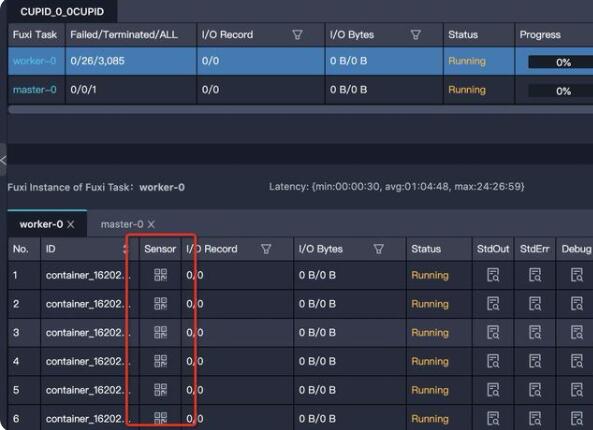
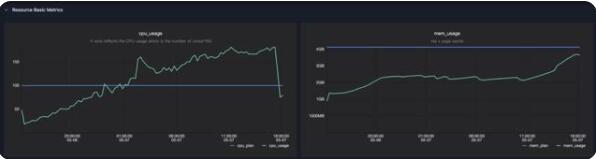
打開Sensor之后,可以看到下圖提供了Driver/Executor在其生命周期內(nèi)的CPU和內(nèi)存的使用情況:
cpu_plan/mem_plan(藍線)代表了用戶申請的CPU和內(nèi)存計劃量
用戶可以直觀地從cpu_usage圖中看出任務(wù)運行中的CPU利用率
mem_usage代表了任務(wù)運行中的內(nèi)存使用,是mem_rss和page cache兩項之和,詳見下文
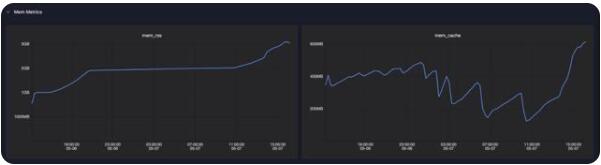
Memory Metrics
mem_rss 代表了進程所占用了常駐內(nèi)存,這部分內(nèi)存也就是Spark任務(wù)運行所使用的實際內(nèi)存,通常需要用戶關(guān)注,如果該內(nèi)存超過用戶申請的內(nèi)存量,就可能會發(fā)生OOM,導(dǎo)致Driver/Executor進程終止。此外,該曲線也可以用于指導(dǎo)用戶進行內(nèi)存優(yōu)化,如果實際使用量遠遠小于用戶申請量,則可以減少內(nèi)存申請,極大化利用資源,降低成本。
mem_cache(page_cache)用于將磁盤中的數(shù)據(jù)緩存到內(nèi)存中,從而減少磁盤I/O操作,通常由系統(tǒng)進行管理,如果物理機內(nèi)存充足,那么mem_cache可能會使用很多,用戶可以不必關(guān)心該內(nèi)存的分配和回收。
3. 資源參數(shù)調(diào)優(yōu)
(1)Executor Cores
相關(guān)參數(shù):spark.executor.cores
每個Executor的核數(shù),即每個Executor中的可同時運行的task數(shù)目
Spark任務(wù)的最大并行度是num-executors * executor-cores
Spark任務(wù)執(zhí)行的時候,一個CPU core同一時間最多只能執(zhí)行一個Task。如果CPU core數(shù)量比較充足,通常來說,可以比較快速和高效地執(zhí)行完這些Task。同時也要注意,每個Executor的內(nèi)存是多個Task共享的,如果單個Executor核數(shù)太多,內(nèi)存過少,那么也很可能發(fā)生OOM。
(2)Executor Num
相關(guān)參數(shù):spark.executor.instances
該參數(shù)用于設(shè)置Spark作業(yè)總共要用多少個Executor進程來執(zhí)行
通常用戶可以根據(jù)任務(wù)復(fù)雜度來決定到底需要申請多少個Executor
此外,需要注意,如果出現(xiàn)Executor磁盤空間不足,或者部分Executor OOM的問題,可以通過減少單個Executor的cores數(shù),增加Executor的instances數(shù)量來保證任務(wù)總體并行度不變,同時降低任務(wù)失敗的風(fēng)險。
(3)Executor Memory
相關(guān)參數(shù):spark.executor.memory
該參數(shù)用于設(shè)置每個Executor進程的內(nèi)存。Executor內(nèi)存的大小,很多時候直接決定了Spark作業(yè)的性能,而且JVM OOM在Executor中更為常見。
相關(guān)參數(shù)2:spark.executor.memoryOverhead
設(shè)置申請Executor的堆外內(nèi)存,主要用于JVM自身,字符串, NIO Buffer等開銷,注意memoryOverhead 這部分內(nèi)存并不是用來進行計算的,用戶代碼及spark都無法直接操作。
如果不設(shè)置該值,那么默認為spark.executor.memory * 0.10,最小為384 MB
Executor 內(nèi)存不足的表現(xiàn)形式:
在Executor的日志(Logview->某個Worker->StdErr)中出現(xiàn)Cannot allocate memory

在任務(wù)結(jié)束的Logview result的第一行中出現(xiàn):The job has been killed by "OOM Killer", please check your job's memory usage.
在Sensor中發(fā)現(xiàn)內(nèi)存使用率非常高
在Executor的日志中出現(xiàn)java.lang.OutOfMemoryError: Java heap space
在Executor的日志中出現(xiàn)GC overhead limit exceeded
Spark UI中發(fā)現(xiàn)頻繁的GC信息
可能出現(xiàn)OOM的間接表現(xiàn)形式:部分Executor出現(xiàn)No route to host: workerd********* / Could not find CoarseGrainedScheduler等錯誤
可能原因及解決方案:
限制executor 并行度,將cores 調(diào)小:多個同時運行的 Task 會共享一個Executor 的內(nèi)存,使得單個 Task 可使用的內(nèi)存減少,調(diào)小并行度能緩解內(nèi)存壓力增加單個Executor內(nèi)存
增加分區(qū)數(shù)量,減少每個executor負載
考慮數(shù)據(jù)傾斜問題,因為數(shù)據(jù)傾斜導(dǎo)致某個 task 內(nèi)存不足,其它 task 內(nèi)存足夠
如果出現(xiàn)了上文所述的Cannot allocate memory或The job has been killed by "OOM Killer", please check your job's memory usage,這種情況通常是由于系統(tǒng)內(nèi)存不足,可以適當(dāng)增加一些堆外內(nèi)存來緩解內(nèi)存壓力,通常設(shè)置spark.executor.memoryOverhead為1g/2g就足夠了
(4)Driver Cores
相關(guān)參數(shù)spark.driver.cores
通常Driver Cores不需要太大,但是如果任務(wù)較為復(fù)雜(如Stage及Task數(shù)量過多)或者Executor數(shù)量過多(Driver需要與每個Executor通信并保持心跳),在Sensor中看到Cpu利用率非常高,那么可能需要適當(dāng)調(diào)大Driver Cores
另外要注意,在Yarn-Cluster模式運行Spark任務(wù),不能直接在代碼中設(shè)置Driver的資源配置(core/memory),因為在JVM啟動時就需要該參數(shù),因此需要通過--driver-memory命令行選項或在spark-defaults.conf文件/Dataworks配置項中進行設(shè)置。
(5)Driver Memory
相關(guān)參數(shù)1:spark.driver.memory
設(shè)置申請Driver的堆內(nèi)內(nèi)存,與executor類似
相關(guān)參數(shù)2:spark.driver.maxResultSize
代表每個Spark的action(例如collect)的結(jié)果總大小的限制,默認為1g。如果總大小超過此限制,作業(yè)將被中止,如果該值較高可能會導(dǎo)致Driver發(fā)生OOM,因此用戶需要根據(jù)作業(yè)實際情況設(shè)置適當(dāng)值。
相關(guān)參數(shù)3:spark.driver.memoryOverhead
設(shè)置申請Driver的堆外內(nèi)存,與executor類似
Driver的內(nèi)存通常不需要太大,如果Driver出現(xiàn)內(nèi)存不足,通常是由于Driver收集了過多的數(shù)據(jù),如果需要使用collect算子將RDD的數(shù)據(jù)全部拉取到Driver上進行處理,那么必須確保Driver的內(nèi)存足夠大。
表現(xiàn)形式:
Spark應(yīng)用程序無響應(yīng)或者直接停止
在Driver的日志(Logview->Master->StdErr)中發(fā)現(xiàn)了Driver OutOfMemory的錯誤
Spark UI中發(fā)現(xiàn)頻繁的GC信息
在Sensor中發(fā)現(xiàn)內(nèi)存使用率非常高
在Driver的日志中出現(xiàn)Cannot allocate memory
可能原因及解決方案:
代碼可能使用了collect操作將過大的數(shù)據(jù)集收集到Driver節(jié)點
在代碼創(chuàng)建了過大的數(shù)組,或者加載過大的數(shù)據(jù)集到Driver進程匯總
SparkContext,DAGScheduler都是運行在Driver端的。對應(yīng)rdd的Stage切分也是在Driver端運行,如果用戶自己寫的程序有過多的步驟,切分出過多的Stage,這部分信息消耗的是Driver的內(nèi)存,這個時候就需要調(diào)大Driver的內(nèi)存。有時候如果stage過多,Driver端甚至?xí)袟R绯?/p>
(6)本地磁盤空間
相關(guān)參數(shù):spark.hadoop.odps.cupid.disk.driver.device_size:
該參數(shù)代表為單個Driver或Executor申請的磁盤空間大小,默認值為20g,最大支持100g
Shuffle數(shù)據(jù)以及BlockManager溢出的數(shù)據(jù)均存儲在磁盤上
磁盤空間不足的表現(xiàn)形式:
在Executor/Driver的日志中發(fā)現(xiàn)了No space left on device錯誤
解決方案:
最簡單的方法是直接增加更多的磁盤空間,調(diào)大spark.hadoop.odps.cupid.disk.driver.device_size
如果增加到100g之后依然出現(xiàn)該錯誤,可能是由于存在數(shù)據(jù)傾斜,shuffle或者cache過程中數(shù)據(jù)集中分布在某些block,也可能是單個Executor的shuffle數(shù)據(jù)量確實過大,可以嘗試:
對數(shù)據(jù)重分區(qū),解決數(shù)據(jù)傾斜問題
縮小單個Executor的任務(wù)并發(fā)spark.executor.cores
縮小讀表并發(fā)spark.hadoop.odps.input.split.size
增加executor的數(shù)量spark.executor.instances
需要注意:
同樣由于在JVM啟動前就需要掛載磁盤,因此該參數(shù)必須配置在spark-defaults.conf文件或者dataworks的配置項中,不能配置在用戶代碼中
此外需要注意該參數(shù)的單位為g,不能省略g
很多時候由于用戶配置位置有誤或者沒有帶單位g,導(dǎo)致參數(shù)實際并沒有生效,任務(wù)運行依然失敗
4. 總結(jié)
上文主要介紹了MaxCompute Spark在使用過程中可能遇到的資源不足的問題及相應(yīng)的解決思路,為了能夠最大化利用資源,首先建議按照1: 4的比例來申請單個worker資源,即1 core: 4 gb memory,如果出現(xiàn)OOM,那么需要查看日志及Sensor對問題進行初步定位,再進行相應(yīng)的優(yōu)化和資源調(diào)整。不建議單個Executor Cores 設(shè)置過多,通常單個Executor在2-8 core是相對安全的,如果超過8,那么建議增加instance數(shù)量。適當(dāng)增加堆外內(nèi)存(為系統(tǒng)預(yù)留一些內(nèi)存資源)也是一個常用的調(diào)優(yōu)方法,通常在實踐中可以解決很多OOM的問題。最后,用戶可以參考官方文檔https://spark.apache.org/docs/2.4.5/tuning.html,包含更多的內(nèi)存調(diào)優(yōu)技巧,如gc優(yōu)化,數(shù)據(jù)序列化等。