













Python靜態類型解析工具簡介和實踐
一、背景
Python是一門強類型的動態類型語言,開發者可以給對象動態指定類型(動態),但類型不匹配的操作是不被允許的(強類型,如str和int兩個變量無法相加)。
動態類型幫助開發者寫代碼輕松愉快,然而,俗話說:動態一時爽,重構火葬場。動態類型也帶來了許多麻煩,如果動態語言能加入靜態類型標記的話,主要有以下幾點好處:
-
編寫更便捷。配合各種IDE工具,可以實現定義跳轉,類型提示等。
-
編碼更可靠。既然有了類型定義的加持,許多工具能夠在靜態編碼階段就能提前發現語義錯誤。
-
重構更放心。明確了接口的出入參,使代碼重構更明確更穩定。
目前主流語言大多數是支持靜態類型的,如Java,Go,Rust。而動態語言(Python,JS)也在擁抱靜態類型,如TypeScript。
本文主要介紹一下Python對靜態類型的支持、社區發展的現狀、類型檢查工具介紹與對比,以及類型解析的實戰。
二、Python的靜態類型支持
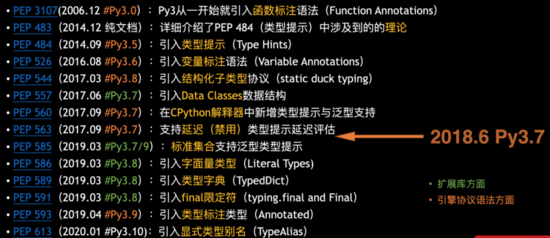
早在06年的Python3.0就引入了類型annotation的語法,并列出了許多改進項。
- # 加類型前
- def add(a, b):
- return a + b
- # 加類型后
- def add(a:int, b:int) -> int:
- return a + b
隨著持續的演進,到Python3.5,能夠做到Type Hints,配合類型標注,IDE可以做Type Checking。

進而到Python3.7,靜態類型支持基本完善。
下面我來具體介紹下類型檢查工具和一些基礎概念。
三、類型檢查工具簡介
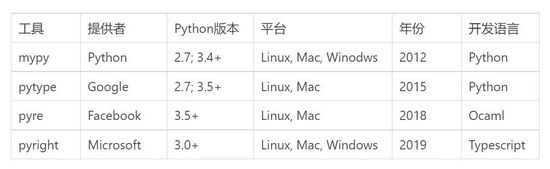
Python作者和主流大廠都陸續推出了Python類型檢查工具:
這些類型解析工具的功能大同小異,下面簡單介紹下:
1.mypy
最早的官方推出的mypy是由Python之父Guido van Rossum親自開發,被各種主流編輯器所集成(如PyCharm, Emacs, Sublime Text, VS Code等),用戶基礎和文檔經驗都很豐富。
2.pytype
谷歌的pytype可以做類型檢查,并且提供了一些實用小工具,下文會簡單介紹下其應用:
-
annotate-ast,過程中的AST樹標記工具。
-
merge-pyi,把生成的 pyi 文件合并回原文件中,甚至還能做到隱藏類型,在類型檢查時再加載。
-
pytd-tool,解析 pyi 文件的工具,解析成pytype自定義的PYTD文件。
-
pytype-single,再給定所有依賴的 pyi 文件的前提下,可以解析單個Python文件。
-
pyxref,交叉引用的生成器。
3.pyre
臉書的pyre-check有兩個特別的功能:
-
Watchman功能, 可以監聽代碼文件,追蹤改動。
-
Query功能,可以對源碼做局部區域性的檢查,例如查詢某行中一個表達式的類型、查詢一個類的全部方法并返回成列表等,避免了全局檢查。
4.pyright
微軟的pyright是最晚開源推出的,宣稱有以下優點:
-
速度快。相較于 mypy 及其它用 Python 寫的檢查工具,它的速度是 5 倍甚至更多。
-
不依賴 Python 環境。它用 TypeScript 寫成,運行于 node 上,不依賴 Python 環境或第三方包。
-
可配置性強。支持自由地配置,支持指定不同的運行環境(PYTHONPATH 設置、Python 版本、平臺目標)。
-
檢查項齊全。支持類型檢查及其它語法項的檢查(如 PEP-484、PEP-526、PEP-544),以及函數返回值、類變量、全局變量的檢查,甚至可以檢查條件循環語句。
-
命令行工具。它包含兩個 VS Code 插件:一個命令行工具和一個語言服務器協議(Language Server Protocol)。
-
內置 Stubs 。使用的是 Typeshed 的副本(注:使用靜態的 pyi 文件,檢查內置模塊、標準庫和三方件 ) 。
-
語言服務特性。懸停提示信息、符號定義的跳轉、實時的編輯反饋。
四、Pytype使用介紹
接下來重點介紹一下pytype。為什么選取pytype呢,首先mypy比較古老,很多功能沒有新出的工具新穎和實用。計劃使用Python LSP來處理Python文件提供一些語法服務的功能,pyre-check用的是Ocamel,所以我們就拿Python語言的pytype來實現想要的功能,而且pytype提供了一些實用工具,比如解析一個pyi文件,基于Python文件生成pyi文件等。
1.基本概念
pyi 文件
pyi 的“ i ”指的是interfiace,將 Python 文件的類型定義用接口的形式存儲到pyi文件里,來輔助類型檢查。
大家常用的Pycharm,可以關注下項目空間的External Libraries > Python 3.6 > Typeshed Stubs里面就有許多內置的 pyi 文件,來輔助編碼過程的類型提示和定位。
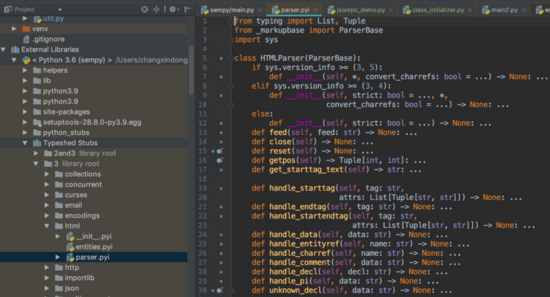
Typeshed Stubs
上面提到了typeshed stubs,這相當于是提前集成的pyi集合,pycharm似乎自己維護了一份數據。 許多比較大的開源項目也在陸續提供stubs, 比如pyTorch。 Tensorflow也正在考慮。
很多Python大庫去制作pyi工程量比較大,而且還有很多C的API調用,大家還需要耐心等待。
2.實戰
我翻閱了pytype的源碼,把比較實用的代碼和需求做了結合,下面介紹幾個示例:
總體效果
- import logging
- import sys
- import os
- import importlab.environment
- import importlab.fs
- import importlab.graph
- import importlab.output
- from importlab import parsepy
- from sempy import util
- from sempy import environment_util
- from pytype.pyi import parser
示例Demo,通過Importlab工具,解析項目空間的依賴關系,以及對應的pyi文件:
- def main():
- # 指定要解析的目錄
- ROOT = '/path/to/demo_project'
- # 指定TYPESHED目錄,可以從這里下載:https://github.com/python/typeshed
- TYPESHED_HOME = '/path/to/typeshed_home'
- util.setup_logging()
- # 載入typeshed,如果TYPESHED_HOME配置的不對,會返回None
- typeshed = environment_util.initialize_typeshed_or_return_none(TYPESHED_HOME)
- # 載入目標目錄有效文件
- inputs = util.load_all_py_files(ROOT)
- # 生成用于生成import_graph的環境
- env = environment_util.create_importlab_environment(inputs, typeshed)
- # 基于pyi和工程文件生成import graph
- import_graph = importlab.graph.ImportGraph.create(env, inputs, trim=True)
- # 打印整個依賴樹
- logging.info('Source tree:\n%s', importlab.output.formatted_deps_list(import_graph))
- # import模塊的別名 e.g. import numpy as np -> {'np': 'numpy'}
- alias_map = {}
- # 引入模塊的名稱和具體pyi文件的映射 e.g. import os -> {'os': '/path/to/os/__init__.pyi'}
- import_path_map = {}
- # alias_map的value,可以和import_path_map的key對應,通過alias_map的key這個變量名去找真正的實現文件
- for file_name in inputs:
- # 如果有pyi文件匹配,則會放入resolved
- # 如果依賴了Build_in依賴,會被跳過,不返回
- # 如果依賴了自定義依賴,會放入unresolved,需要自己進一步解析,定位到項目工程文件
- (resolved, unresolved) = import_graph.get_file_deps(file_name)
- for item in resolved:
- item_name = item.replace('.pyi', '') \
- .replace('.py', '') \
- .replace('/__init__', '').split('/')[-1]
- import_path_map[item_name] = item
- for item in unresolved:
- file_path = os.path.join(ROOT, item.new_name + '.py')
- import_path_map[item.name] = file_path
- import_stmts = parsepy.get_imports(file_name, env.python_version)
- for import_stmt in import_stmts:
- alias_map[import_stmt.new_name] = import_stmt.name
- print('以下為通過importlab解析方式獲取的import關系\n\n')
- # 對于代碼搜索場景,只需要alias_map,既可以通過正在使用的對象關聯到引入的模塊
- print('\n\n#################################\n\n')
- print('對于代碼搜索場景,只需要alias_map,既可以通過正在使用的對象關聯到引入的模塊')
- print('alias_map: ', alias_map)
- # 對于代碼補全場景,需要進一步解析當前文件以及引用的pyi文件,如果當前文件是__init__文件,則要進一步去該目錄下的所有文件方法中全局搜索
- print('\n\n#################################\n\n')
- print('對于代碼補全場景,需要進一步解析當前文件以及引用的pyi文件,如果當前文件是__init__文件,則要進一步去該目錄下的所有文件方法中全局搜索')
- print('import_path_map: ', import_path_map)
- print('\n\n\n以下為通過pytype工具,解析pyi文件AST來分析三方依賴返回類型,從而解析出當前變量的類型\n\n')
- # 通過pytype的解析,去解析依賴的pyi文件,獲得調用方法的返回值
- fname = '/path/to/parsed_file'
- with open(fname, 'r') as reader:
- lines = reader.readlines()
- sourcecode = '\n'.join(lines)
- ret = parser.parse_string(sourcecode, filename=fname, python_version=3)
- constant_map = dict()
- function_map = dict()
- for key in import_path_map.keys():
- v = import_path_map[key]
- with open(v, 'r') as reader:
- lines = reader.readlines()
- src = '\n'.join(lines)
- try:
- res = parser.parse_pyi(src, v, key, 3)
- except:
- continue
- # Alias
- # Classes
- for constant in res.constants:
- constant_map[constant.name] = constant.type.name
- for function in res.functions:
- signatures = function.signatures
- sig_list = []
- for signature in signatures:
- sig_list.append((signature.params, signature.return_type))
- function_map[function.name] = sig_list
- var_type_from_pyi_list = []
- for alias in ret.aliases:
- variable_name = alias.name
- if alias.type is not None:
- typename_in_source = alias.type.name
- typename = typename_in_source
- # 引入別名的case,把它轉化回來
- if '.' not in typename:
- # 只是普通的別名,不是函數調用的返回值,忽略
- continue
- if typename.split('.')[0] in alias_map:
- real_module_name = alias_map[typename.split('.')[0]]
- typename = real_module_name + typename[typename.index('.'):]
- if typename in function_map:
- possible_return_types = [item[1].name for item in function_map[typename]]
- var_type_from_pyi_list.append((variable_name, possible_return_types))
- if typename in constant_map:
- possible_return_type = constant_map[typename]
- var_type_from_pyi_list.append((variable_name, possible_return_type))
- pass
- print('\n\n#################################\n\n')
- print('這些都是從PYI文件中分析出來的返回值類型')
- for item in var_type_from_pyi_list:
- print('變量名:', item[0], '返回類型:', item[1])
- if __name__ == '__main__':
- sys.exit(main())
被 解析的示例代碼:
- # demo.py
- import os as abcdefg
- import re
- from demo import utils
- from demo import refs
- cwd = abcdefg.getcwd()
- support_version = abcdefg.supports_bytes_environ
- pattern = re.compile(r'.*')
- add_res = utils.add(1, 3)
- mul_res = refs.multi(3, 5)
- c = abs(1)
具體步驟
首先pytype利用了Google另一個開源項目:ImportLab。
用于分析文件間的依賴關系,此時可以把typeshed目錄下的文件也放入環境中,importlab能夠生成依賴圖。
- env = environment_util.create_importlab_environment(inputs, typeshed)
- import_graph = importlab.graph.ImportGraph.create(env, inputs, trim=True)
- # 如果有pyi文件匹配,則會放入resolved
- # 如果依賴了Build_in依賴,會被跳過,不返回
- # 如果依賴了自定義依賴,會放入unresolved,需要自己進一步解析,定位到項目工程文件
- (resolved, unresolved) = import_graph.get_file_deps(file_name)
通過import graph我們拿到了變量的來源(包括引用別名,方法調用返回值):
- {'ast': 'ast', 'astpretty': 'astpretty', 'abcdefg': 'os', 're': 're', 'utils': 'demo.utils', 'refs': 'demo.refs', 'JsonRpcStreamReader': 'pyls_jsonrpc.streams.JsonRpcStreamReader'}
通過依賴圖,還能直接引用的依賴在具體哪個位置:
- import_path_map: {'ast': '/Users/zhangxindong/Desktop/search/code/sempy/sempy/typeshed/stdlib/ast.pyi', 'astpretty': '/Users/zhangxindong/Desktop/search/code/sempy/venv/lib/python3.9/site-packages/astpretty.py', 'os': '/Users/zhangxindong/Desktop/search/code/sempy/sempy/typeshed/stdlib/os/__init__.pyi', 're': '/Users/zhangxindong/Desktop/search/code/sempy/sempy/typeshed/stdlib/re.pyi', 'utils': '/Users/zhangxindong/Desktop/search/code/sempy/sempy/demo/utils.py', 'refs': '/Users/zhangxindong/Desktop/search/code/sempy/sempy/demo/refs/__init__.py', 'streams': '/Users/zhangxindong/Desktop/search/code/sempy/venv/lib/python3.9/site-packages/pyls_jsonrpc/streams.py'}
接下來,就是去具體解析對應的文件了。我的需求是獲取一些方法的返回值類型,對于 pyi 文件,pytype能夠幫助我們解析,然后我們通過調用關系去匹配。
- print('\n\n\n以下為通過pytype工具,解析pyi文件AST來分析三方依賴返回類型,從而解析出當前變量的類型\n\n')
- # 通過pytype的解析,去解析依賴的pyi文件,獲得調用方法的返回值
- fname = '/path/to/parsed_file'
- with open(fname, 'r') as reader:
- lines = reader.readlines()
- sourcecode = '\n'.join(lines)
- ret = parser.parse_string(sourcecode, filename=fname, python_version=3)
- constant_map = dict()
- function_map = dict()
- for key in import_path_map.keys():
- v = import_path_map[key]
- with open(v, 'r') as reader:
- lines = reader.readlines()
- src = '\n'.join(lines)
- try:
- res = parser.parse_pyi(src, v, key, 3)
- except:
- continue
- # Alias
- # Classes
- for constant in res.constants:
- constant_map[constant.name] = constant.type.name
- for function in res.functions:
- signatures = function.signatures
- sig_list = []
- for signature in signatures:
- sig_list.append((signature.params, signature.return_type))
- function_map[function.name] = sig_list
- var_type_from_pyi_list = []
- for alias in ret.aliases:
- variable_name = alias.name
- if alias.type is not None:
- typename_in_source = alias.type.name
- typename = typename_in_source
- # 引入別名的case,把它轉化回來
- if '.' not in typename:
- # 只是普通的別名,不是函數調用的返回值,忽略
- continue
- if typename.split('.')[0] in alias_map:
- real_module_name = alias_map[typename.split('.')[0]]
- typename = real_module_name + typename[typename.index('.'):]
- if typename in function_map:
- possible_return_types = [item[1].name for item in function_map[typename]]
- # print('The possible return type of', typename_in_source, 'is', possible_return_types)
- var_type_from_pyi_list.append((variable_name, possible_return_types))
- if typename in constant_map:
- possible_return_type = constant_map[typename]
- var_type_from_pyi_list.append((variable_name, possible_return_type))
- pass
比如:
- pattern = re.compile(r'.*')
從/Users/zhangxindong/Desktop/search/code/sempy/sempy/typeshed/stdlib/re.pyi文件中,我們載入了兩個方法都是re.compile,只是入參不同,返回值都是Pattern類型。
于是我們就知道了pattern變量的類型是re.Pattern。
-
這些都是從 pyi 文件中分析出來的返回值類型。
-
變量名 cwd 返回類型:['str']
-
變量名 support_version 返回類型:bool
-
變量名 pattern 返回類型:['typing.Pattern', 'typing.Pattern']
五、應用
Python語法分析的功能有一部分已經應用在了阿里云Dev Studio的代碼文檔搜索推薦和代碼智能補全中。
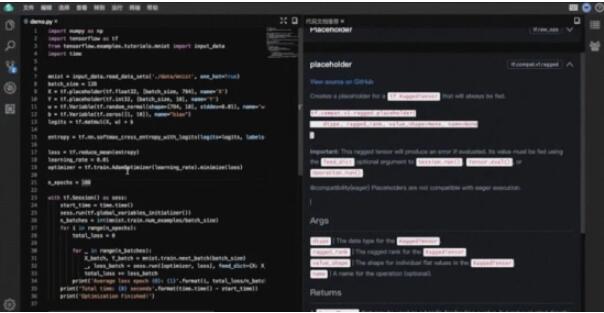
1.代碼文檔搜索推薦
當開發者不知道如何使用某個 API 時(如調用方式或方法入參等),可以將鼠標移動到指定 API 上,即可展示智能編碼插件提供的 API 概要信息。開發者點擊“ API 文檔詳情”,能在右側欄看到 API 的官方文檔、代碼示例等詳細信息,也可以直接搜索所需的 API 代碼文檔。目前支持 JavaScript、Python 語言的代碼文檔搜索推薦。
文檔采集過程中,我們能夠拿到API名稱和API所對應的class,在實際代碼中,我們通過語法分析就能基于調用的方法對應到調用的類信息,從而用于文檔搜索。
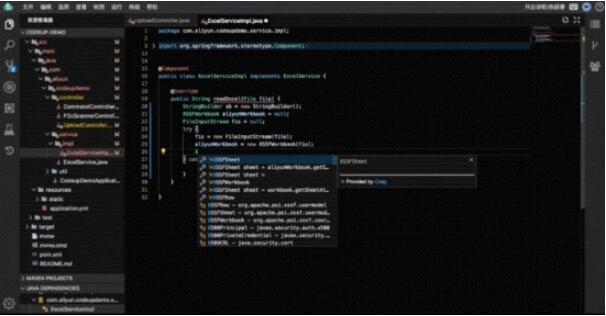
2.代碼智能補全
開發者在編寫代碼時,智能編碼插件會自動感知代碼上下文,為開發者提供精準的代碼補全候選項,代碼補全候選項中標記有 :sparkles: 符號的為代碼智能補全結果。目前支持 Java、JavaScript、Python 語言的代碼智能補全。
代碼補全過程中,通過語法分析,能夠更加精準地獲悉用戶使用變量的類信息,幫助過濾掉深度學習模型推薦的不合理選項,也能夠基于類的內部方法集合,召回一些合理的補全項。
六、總結
Python靜態類型支持的理念和工具均以完善,但由于歷史包袱太重,社區推動力不足,實際能達到的效果比較有限。另外官方、各大廠以及本地IDE都有自己的實現和分析方式,還沒有達到統一的標準和格式。大家可以根據上述的優劣勢以及配合的工具集與數據集,選擇適合自己的方式做解析。期待Python社區對靜態類型的支持能越來越完善。

















