













Flink 1.12 資源管理新特性回顧
本文由社區(qū)志愿者陳政羽整理,Apache Flink Committer、阿里巴巴技術(shù)專家宋辛童,Apache Flink Contributor、阿里巴巴高級(jí)開發(fā)工程師郭旸澤分享,主要介紹 Flink 1.12 資源管理的一些特性。內(nèi)容主要分為 4 部分:
1.內(nèi)存管理
2.資源調(diào)度擴(kuò)展
3.資源框架
4.未來規(guī)劃
一、內(nèi)存管理
首先回顧 Flink 的內(nèi)存模型變遷。下圖左邊分別為 Flink 1.10、Flink 1.11 引入的新的內(nèi)存模型。盡管涉及的模塊較多,但 80% - 90% 的用戶僅需關(guān)注真正用于任務(wù)執(zhí)行的 Task Heap Memory、Task Off-Heap Memory、Network Memory、Managed Memory 四部分。
其它模塊大部分是 Flink 的框架內(nèi)存,正常不需要調(diào)整,即使遇到問題也可以通過社區(qū)文檔來解決。除此之外,“一個(gè)作業(yè)究竟需要多少內(nèi)存才能滿足實(shí)際生產(chǎn)需求” 也是大家不得不面臨的問題,比如其他指標(biāo)的功能使用、作業(yè)是否因?yàn)閮?nèi)存不足影響了性能,是否存在資源浪費(fèi)等。
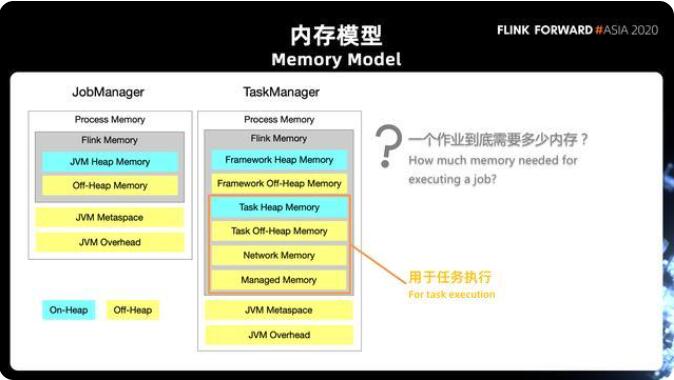
針對(duì)上述內(nèi)容,社區(qū)在 Flink 1.12 版本提供了一個(gè)全新的, 關(guān)于 Task manager 和 Job
manager 的 Web UI。

在新的 Web UI 中,可以直接將每一項(xiàng)監(jiān)控指標(biāo)配置值、實(shí)際使用情況對(duì)應(yīng)到內(nèi)存模型中進(jìn)行直觀的展示。在此基礎(chǔ)上,可以更清楚的了解到作業(yè)的運(yùn)行情況、該如何調(diào)整、用哪些配置參數(shù)調(diào)整等 (社區(qū)也有相應(yīng)的文檔提供支持)。通過新的 Web UI,大家能更好的了解作業(yè)的使用情況,內(nèi)存管理也更方便。
1. 本地內(nèi)存(Managed Memory)
Flink 托管內(nèi)存實(shí)際上是 Flink 特有的一種本地內(nèi)存,不受 JVM 和 GC 的管理,而是由 Flink 自行進(jìn)行管理。
本地內(nèi)存的特點(diǎn)主要體現(xiàn)在兩方面:
一方面是 slot 級(jí)別的預(yù)算規(guī)劃,它可以保證作業(yè)運(yùn)行過程中不會(huì)因?yàn)閮?nèi)存不足,造成某些算子或者任務(wù)無法運(yùn)行;也不會(huì)因?yàn)轭A(yù)留了過多的內(nèi)存沒有使用造成資源浪費(fèi)。 同時(shí) Flink 能保證當(dāng)任務(wù)運(yùn)行結(jié)束時(shí)準(zhǔn)確將內(nèi)存釋放,確保 Task Manager 執(zhí)行新任務(wù)時(shí)有足夠的內(nèi)存可用。
另一方面,資源適應(yīng)性也是托管內(nèi)存很重要的特性之一,指算子對(duì)于內(nèi)存的需求是動(dòng)態(tài)可調(diào)整的。具備了適應(yīng)性,算子就不會(huì)因?yàn)榻o予任務(wù)過多的內(nèi)存造成資源使用上的浪費(fèi),也不會(huì)因?yàn)樘峁┑膬?nèi)存相對(duì)較少導(dǎo)致整個(gè)作業(yè)無法運(yùn)行,使內(nèi)存的運(yùn)用保持在一定的合理范圍內(nèi)。當(dāng)然,在內(nèi)存分配相對(duì)比較少情況下,作業(yè)會(huì)受到一定限制,例如需要通過頻繁的落盤保證作業(yè)的運(yùn)行,這樣可能會(huì)影響性能。
當(dāng)前,針對(duì)托管內(nèi)存,F(xiàn)link 的使用場(chǎng)景如下:
RocksDB 狀態(tài)后端:在流計(jì)算的場(chǎng)景中,每個(gè) Slot 會(huì)使用 State 的 Operator,從而共享同一底層 的 RocksDB 緩存;
Flink 內(nèi)置算子:包含批處理、Table SQL、DataSet API 等算子,每個(gè)算子有獨(dú)立的資源預(yù)算,不會(huì)相互共享;
Python 進(jìn)程:用戶使用 PyFlink,使用 Python 語言定義 UDF 時(shí)需要啟動(dòng) Python 的虛擬機(jī)進(jìn)程。
2. Job Graph 編譯階段
Flink 對(duì)于 management memory 的管理主要分為兩個(gè)階段。
2.1 作業(yè)的 Job Graph 編譯階段
在這個(gè)階段需要注意三個(gè)問題:
第一個(gè)問題是:slot 當(dāng)中到底有哪些算子或者任務(wù)會(huì)同時(shí)執(zhí)行。這個(gè)問題關(guān)系到在一個(gè)查詢作業(yè)中如何對(duì)內(nèi)存進(jìn)行規(guī)劃,是否還有其他的任務(wù)需要使用 management memory,從而把相應(yīng)的內(nèi)存留出來。 在流式的作業(yè)中,這個(gè)問題是比較簡(jiǎn)單的,因?yàn)槲覀冃枰械乃阕油瑫r(shí)執(zhí)行,才能保證上游產(chǎn)出的數(shù)據(jù)能被下游及時(shí)的消費(fèi)掉,這個(gè)數(shù)據(jù)才能夠在整個(gè) job grep 當(dāng)中流動(dòng)起來。 但是如果我們是在批處理的一些場(chǎng)景當(dāng)中,實(shí)際上我們會(huì)存在兩種數(shù)據(jù) shuffle 的模式,一種是 pipeline 的模式,這種模式跟流式是一樣的,也就是我們前面說到的 bounded stream 處理方式,同樣需要上游和下游的算子同時(shí)運(yùn)行,上游隨時(shí)產(chǎn)出,下游隨時(shí)消費(fèi)。另外一種是所謂的 batch 的 blocking的方式,它要求上游把數(shù)據(jù)全部產(chǎn)出,并且落盤結(jié)束之后,下游才能開始讀數(shù)據(jù)。這兩種模式會(huì)影響到哪些任務(wù)可以同時(shí)執(zhí)行。目前在 Flink 當(dāng)中,根據(jù)作業(yè)拓?fù)鋱D中的一個(gè)邊的類型 (如圖上)。我們劃分出了定義的一個(gè)概念叫做 pipelined region,也就是全部都由 pipeline 的邊鎖連通起來的一個(gè)子圖,我們把這個(gè)子圖識(shí)別出來,用來判斷哪些 task 會(huì)同時(shí)執(zhí)行。
第二個(gè)問題是:slot 當(dāng)中到底有哪些使用場(chǎng)景?我們剛才介紹了三種 manage memory 的使用場(chǎng)景。在這個(gè)階段,對(duì)于流式作業(yè),可能會(huì)出現(xiàn) Python UDF 以及 Stateful Operator。這個(gè)階段當(dāng)中我們需要注意的是,這里并不能肯定 State Operator 一定會(huì)用到 management memory,因?yàn)檫@跟它的狀態(tài)類型是相關(guān)的。如果它使用了 RocksDB State Operator,是需要使用 manage memory 的;但是如果它使用的是 Heap State Backend,則并不需要。然而,作業(yè)在編譯的階段,其實(shí)并不知道狀態(tài)的類型,這里是需要去注意的地方。
第三個(gè)問題:對(duì)于 batch 的作業(yè),我們除了需要清楚有哪些使用場(chǎng)景,還需要清楚一件事情,就是前面提到過 batch 的 operator。它使用 management memory 是以一種算子獨(dú)享的方式,而不是以 slot 為單位去進(jìn)行共享。我們需要知道不同的算子應(yīng)該分別分配多少內(nèi)存,這個(gè)事情目前是由 Flink 的計(jì)劃作業(yè)來自動(dòng)進(jìn)行設(shè)置的。
2.2 執(zhí)行階段
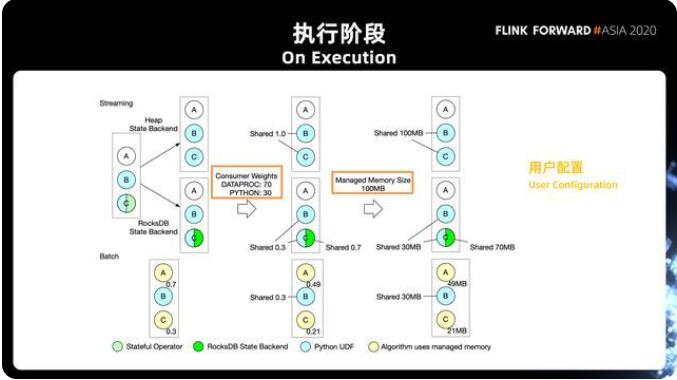
第一個(gè)步驟是根據(jù) State Backend 的類型去判斷是否有 RocksDB。如上圖所示,比如一個(gè) slot,有 ABC 三個(gè)算子,B 跟 C 都用到了 Python,C 還用到了 Stateful 的 Operator。這種情況下,如果是在 heap 的情況下,我們走上面的分支,整個(gè) slot 當(dāng)中只有一種在使用,就是Python。之后會(huì)存在兩種使用方式:
其中一個(gè)是 RocksDB State Backend,有了第一步的判斷之后,第二步我們會(huì)根據(jù)用戶的配置,去決定不同使用方式之間怎么樣去共享 slot 的 management memory。
在這個(gè) Steaming 的例子當(dāng)中,我們定義的 Python 的權(quán)重是 30%,State Backend 的權(quán)重是 70%。在這樣的情況下,如果只有 Python,Python 的部分自然是使用 100% 的內(nèi)存(Streaming 的 Heap State Backend 分支);
而對(duì)于第二種情況(Streaming 的 RocksDB State Backend 分支),B、C 的這兩個(gè) Operator 共用 30% 的內(nèi)存用于 Python 的 UDF,另外 C 再獨(dú)享 70% 的內(nèi)存用于 RocksDB State Backend。最后 Flink 會(huì)根據(jù) Task manager 的資源配置,一個(gè) slot 當(dāng)中有多少 manager memory 來決定每個(gè) operator 實(shí)際可以用的內(nèi)存的數(shù)量。
批處理的情況跟流的情況有兩個(gè)不同的地方,首先它不需要去判斷 State Backend 的類型,這是一個(gè)簡(jiǎn)化; 其次對(duì)于 batch 的算子,上文提到每一個(gè)算子有自己獨(dú)享的資源的預(yù)算,這種情況下我們會(huì)去根據(jù)使用率算出不同的使用場(chǎng)景需要多少的 Shared 之后,還要把比例進(jìn)一步的細(xì)分到每個(gè) Operator。
3. 參數(shù)配置
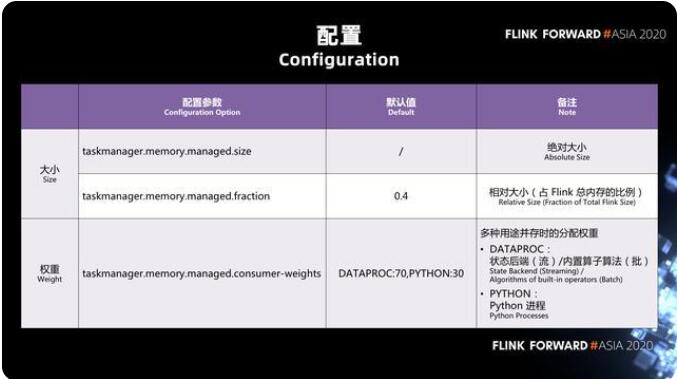
上方圖表展示了我們需要的是 manager,memory 大小有兩種配置方式:
一種是絕對(duì)值的配置方式,
還有一種是作為 Task Manager 總內(nèi)存的一個(gè)相對(duì)值的配置方式。
taskmanager.memory.managed.consumer-weight 是一個(gè)新加的配置項(xiàng),它的數(shù)據(jù)類型是 map 的類型,也就是說我們?cè)谶@里面實(shí)際上是給了一個(gè) key 冒號(hào) value,然后逗號(hào)再加上下一組 key 冒號(hào) value 的這樣的一個(gè)數(shù)據(jù)的結(jié)構(gòu)。這里面我們目前支持兩種 consumer 的 key:
一個(gè)是 DATAPROC, DATAPROC 既包含了流處理當(dāng)中的狀態(tài)后端 State Backend 的內(nèi)存,也包含了批處理當(dāng)中的 Batch Operator;
另外一種是 Python。
二、 資源調(diào)度
部分資源調(diào)度相關(guān)的 Feature 是其他版本或者郵件列表里面大家詢問較多的,這里我們也做對(duì)應(yīng)的介紹。
1. 最大 Slot 數(shù)
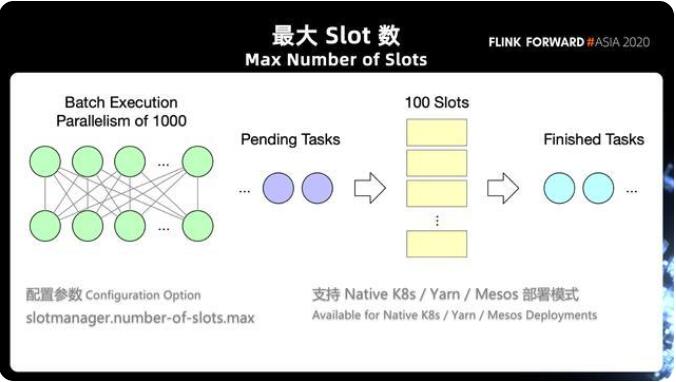
Flink 在 1.12 支持了最大 slot 數(shù)的一個(gè)限制(slotmanager.number-of-slots.max),在之前我們也有提到過對(duì)于流式作業(yè)我們要求所有的 operator 同時(shí)執(zhí)行起來,才能夠保證數(shù)據(jù)的順暢的運(yùn)行。在這種情況下,作業(yè)的并發(fā)度決定了我們的任務(wù)需要多少個(gè) slot 和資源去執(zhí)行作業(yè)。
然而對(duì)于批處理其實(shí)并不是這樣的,批處理作業(yè)往往可以有一個(gè)很大的并發(fā)度,但實(shí)際并不需要這么多的資源,批處理用很少的資源,跑完前面的任務(wù)騰出 Slot 給后續(xù)的任務(wù)使用。通過這種串行的方式去執(zhí)行任務(wù)能避免 YARN/K8s 集群的資源過多的占用。目前這個(gè)參數(shù)支持在 yarn/mesos/native k8 使用。
2. TaskManager 容錯(cuò)
在我們實(shí)際生產(chǎn)中有可能會(huì)有程序的錯(cuò)誤、網(wǎng)絡(luò)的抖動(dòng)、硬件的故障等問題造成 TaskManager 無法連接,甚至直接掛掉。我們?cè)谌罩局谐R姷木褪?TaskManagerLost 這樣的報(bào)錯(cuò)。對(duì)于這種情況需要進(jìn)行作業(yè)重啟,在重啟的過程中需要重新申請(qǐng)資源和重啟 TaskManager 進(jìn)程,這種性能消耗代價(jià)是非常高昂的。
對(duì)于穩(wěn)定性要求相對(duì)比較高的作業(yè),F(xiàn)link1.12 提供了一個(gè)新的 feature,能夠支持在 Flink 集群當(dāng)中始終持有少量的冗余的 TaskManager,這些冗余的 TaskManager 可以用于在單點(diǎn)故障的時(shí)候快速的去恢復(fù),而不需要等待一個(gè)重新的資源申請(qǐng)的過程。
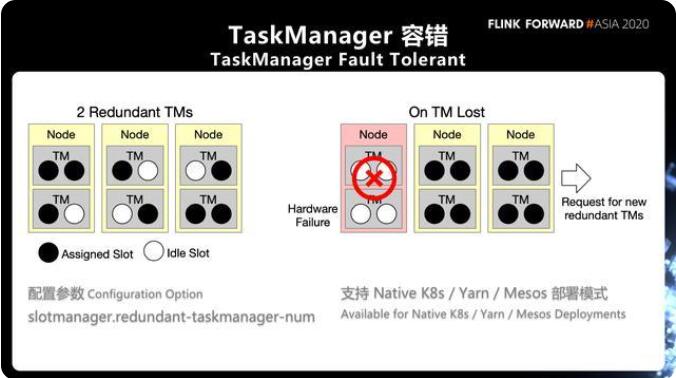
通過配置 slotmanager.redundant-taskmanager-num 可以實(shí)現(xiàn)冗余 TaskManager。這里所謂的冗余 TaskManager 并不是完完全全有兩個(gè) TaskManager 是空負(fù)載運(yùn)行的,而是說相比于我所需要的總共的資源數(shù)量,會(huì)多出兩個(gè) TaskManager。
任務(wù)可能是相對(duì)比較均勻的分布在上面,在能夠在利用空閑 TaskManager 的同時(shí),也能夠達(dá)到一個(gè)相對(duì)比較好的負(fù)載。 一旦發(fā)生故障的時(shí)候,可以去先把任務(wù)快速的調(diào)度到現(xiàn)有的還存活的 TaskManager 當(dāng)中,然后再去進(jìn)行新一輪的資源申請(qǐng)。目前這個(gè)參數(shù)支持在 yarn/mesos/native k8 使用。
3. 任務(wù)平鋪分布
任務(wù)平鋪問題主要出現(xiàn)在 Flink Standalone 模式下或者是比較舊版本的 k8s 模式部署下的。在這種模式下因?yàn)槭孪榷x好了有多少個(gè) TaskManager,每個(gè) TaskManager 上有多少 slot,這樣會(huì)導(dǎo)致經(jīng)常出現(xiàn)調(diào)度不均的問題,可能部分 manager 放的任務(wù)很滿,有的則放的比較松散。
在 1.11 的版本當(dāng)中引入了參數(shù) cluster.evenly-spread-out-slots,這樣的參數(shù)能夠控制它,去進(jìn)行一個(gè)相對(duì)比較均衡的調(diào)度。

注意:
第一,這個(gè)參數(shù)我們只針對(duì) Standalone 模式,因?yàn)樵?yarn 跟 k8s 的模式下,實(shí)際上是根據(jù)你作業(yè)的需求來決定起多少 task manager 的,所以是先有了需求再有 TaskManager,而不是先有 task manager,再有 slot 的調(diào)度需求。在每次調(diào)度任務(wù)的時(shí)候,實(shí)際上只能看到當(dāng)前注冊(cè)上來的那一個(gè) TaskManager,F(xiàn)link 沒辦法全局的知道后面還有多少 TaskManager 會(huì)注冊(cè)上來,這也是很多人在問的一個(gè)問題,就是為什么特性打開了之后好像并沒有起到一個(gè)很好的效果,這是第一件事情。
第二個(gè)需要注意的點(diǎn)是,這里面我們只能決定每一個(gè) TaskManager 上有多少空閑 slot,然而并不能夠決定每個(gè) operator 有不同的并發(fā)數(shù),F(xiàn)link 并不能決定說每個(gè) operator 是否在 TaskManager 上是一個(gè)均勻的分布,因?yàn)樵?flink 的資源調(diào)度邏輯當(dāng)中,在整個(gè) slot 的 allocation 這一層是完全看不到 task 的。
三、擴(kuò)展資源框架
1. 背景
近年來,隨著人工智能領(lǐng)域的不斷發(fā)展,深度學(xué)習(xí)模型已經(jīng)被應(yīng)用到了各種各樣的生產(chǎn)需求中,比較典型的場(chǎng)景如推薦系統(tǒng),廣告推送,智能風(fēng)險(xiǎn)控制。這些也是 Flink 一直以來被廣泛使用的場(chǎng)景,因此,支持人工智能一直以來都是 Flink 社區(qū)的長(zhǎng)遠(yuǎn)目標(biāo)之一。針對(duì)這個(gè)目標(biāo),目前已經(jīng)有了很多第三方的開源擴(kuò)展工作。由阿里巴巴開源的工作主要有兩個(gè):
一個(gè)是 Flink AI Extended 的項(xiàng)目,是基于 Flink 的深度學(xué)習(xí)擴(kuò)展框架,目前支持 TensorFlow、PyTorch 等框架的集成,它使用戶可以將 TensorFlow 當(dāng)做一個(gè)算子,放在 Flink 任務(wù)中。
另一個(gè)是 Alink,它是一個(gè)基于 Flink 的通用算法平臺(tái),里面也內(nèi)置了很多常用的機(jī)器學(xué)習(xí)算法。
以上的兩個(gè)工作都是從功能性上對(duì) Flink 進(jìn)行擴(kuò)展,然而從算力的角度上講,深度學(xué)習(xí)模型亦或機(jī)器學(xué)習(xí)算法,通常都是整個(gè)任務(wù)的計(jì)算瓶頸所在。GPU 則是這個(gè)領(lǐng)域被廣泛使用用來加速訓(xùn)練或者預(yù)測(cè)的資源。因此,支持 GPU 資源來加速計(jì)算是 Flink 在 AI 領(lǐng)域的發(fā)展過程中必不可少的功能。
2. 使用擴(kuò)展資源
目前 Flink 支持用戶配置的資源維度只有 CPU 與內(nèi)存,而在實(shí)際使用中,不僅是 GPU,我們還會(huì)遇到其他資源需求,如 SSD 或 RDMA 等網(wǎng)絡(luò)加速設(shè)備。因此,我們希望提供一個(gè)通用的擴(kuò)展資源框架,任何擴(kuò)展資源都可以以插件的形式來加入這個(gè)框架,GPU 只是其中的一種擴(kuò)展資源。
對(duì)于擴(kuò)展資源的使用,可以抽象出兩個(gè)通用需求:
需要支持該類擴(kuò)展資源的配置與調(diào)度。用戶可以在配置中指明對(duì)這類擴(kuò)展資源的需求,如每個(gè) TaskManager 上需要有一塊 GPU 卡,并且當(dāng) Flink 被部署在 Kubernetes/Yarn 這類資源底座上時(shí),需要將用戶對(duì)擴(kuò)展資源的需求進(jìn)行轉(zhuǎn)發(fā),以保證申請(qǐng)到的 Container/Pod 中存在對(duì)應(yīng)的擴(kuò)展資源。
需要向算子提供運(yùn)行時(shí)的擴(kuò)展資源信息。用戶在自定義算子中可能需要一些運(yùn)行時(shí)的信息才能使用擴(kuò)展資源,以 GPU 為例,算子需要知道它內(nèi)部的模型可以部署在那一塊 GPU 卡上,因此,需要向算子提供這些信息。
3. 擴(kuò)展資源框架使用方法
使用資源框架我們可以分為以下這 3 個(gè)步驟:
首先為該擴(kuò)展資源設(shè)置相關(guān)配置;
然后為所需的擴(kuò)展資源準(zhǔn)備擴(kuò)展資源框架中的插件;
最后在算子中,從 RuntimeContext 來獲取擴(kuò)展資源的信息并使用這些資源
3.1 配置參數(shù)
- # 定義擴(kuò)展資源名稱,“gpu”external-resources: gpu# 定義每個(gè) TaskManager 所需的 GPU 數(shù)量external-resource.gpu.amount: 1 # 定義Yarn或Kubernetes中擴(kuò)展資源的配置鍵external-resource.gpu.yarn.config-key: yarn.io/gpuexternal-resource.gpu.kubernetes.config-key: nvidia.com/gpu# 定義插件 GPUDriver 的工廠類。external-resource.gpu.driver-factory.class: org.apache.flink.externalresource.gpu.GPUDriverFactory
以上是使用 GPU 資源的配置示例:
對(duì)于任何擴(kuò)展資源,用戶首先需要將它的名稱加入 "external-resources" 中,這個(gè)名稱也會(huì)被用作該擴(kuò)展資源其他相關(guān)配置的前綴來使用。示例中,我們定義了一種名為 "gpu" 的資源。
在調(diào)度層,目前支持用戶在 TaskManager 的粒度來配置擴(kuò)展資源需求。示例中,我們定義每個(gè) TaskManager 上的 GPU 設(shè)備數(shù)為 1。
將 Flink 部署在 Kubernetes 或是 Yarn 上時(shí),我們需要配置擴(kuò)展資源在對(duì)應(yīng)的資源底座上的配置鍵,以便 Flink 對(duì)資源需求進(jìn)行轉(zhuǎn)發(fā)。示例中展示了 GPU 對(duì)應(yīng)的配置。
如果提供了插件,則需要將插件的工廠類名放入配置中。
3.2 前置準(zhǔn)備
在實(shí)際使用擴(kuò)展資源前,還需要做一些前置準(zhǔn)備工作,以 GPU 為例:
在 Standalone 模式下,集群管理員需要保證 GPU 資源對(duì) TaskManager 進(jìn)程可見。
在 Kubernetes 模式下,需要集群支持 Device Plugin[6],對(duì)應(yīng)的 Kubernetes 版本為 1.10,并且在集群中安裝了 GPU 對(duì)應(yīng)的插件。
在 Yarn 模式下,GPU 調(diào)度需要集群 Hadoop 版本在 2.10 或 3.1 以上,并正確配置了 resource-types.xml 等文件。
3.3 擴(kuò)展資源框架插件
完成了對(duì)擴(kuò)展資源的調(diào)度后,用戶自定義算子可能還需要運(yùn)行時(shí)擴(kuò)展資源的信息才能使用它。擴(kuò)展資源框架中的插件負(fù)責(zé)完成該信息的獲取,它的接口如下:
- public interface ExternalResourceDriverFactory { /** * 根據(jù)提供的設(shè)置創(chuàng)建擴(kuò)展資源的Driver */ ExternalResourceDriver createExternalResourceDriver(Configuration config) throws Exception;}public interface ExternalResourceDriver { /** * 獲取所需數(shù)量的擴(kuò)展資源信息 */ Set<? extends ExternalResourceInfo> retrieveResourceInfo(long amount) throws Exception;}
ExternalResourceDriver 會(huì)在各個(gè) TaskManager 上啟動(dòng),擴(kuò)展資源框架會(huì)調(diào)用各個(gè) Driver 的 retrieveResourceInfo 接口來獲得 TaskManager 上的擴(kuò)展資源信息,并將得到的信息傳到算子的 RuntimeContext。ExternalResourceDriverFactory 則為插件的工廠類。
4. GPU 插件
Flink 目前內(nèi)置了針對(duì) GPU 資源的插件,其內(nèi)部通過執(zhí)行名為 Discovery Script 的腳本來獲取當(dāng)前環(huán)境可用的 GPU 信息,目前信息中包含了 GPU 設(shè)備的 Index。
Flink 提供了一個(gè)默認(rèn)腳本,位于項(xiàng)目的 "plugins/external-resource-gpu/" 目錄,用戶也可以實(shí)現(xiàn)自定義的 Discovery Script 并通過配置來指定使用自定義腳本。該腳本與 GPU 插件的協(xié)議為:
當(dāng)調(diào)用腳本時(shí),所需要的 GPU 數(shù)量將作為第一個(gè)參數(shù)輸入,之后為用戶自定義參數(shù)列表。
若腳本執(zhí)行正常,則輸出 GPU Index 列表,以逗號(hào)分隔。
若腳本出錯(cuò)或執(zhí)行結(jié)果不符合預(yù)期,則腳本以非零值退出,這會(huì)導(dǎo)致 TaskManager 初始化失敗,并在日志中打印腳本的錯(cuò)誤信息。
Flink 提供的默認(rèn)腳本是通過 "nvidia-smi" 工具來獲取當(dāng)前的機(jī)器中可用的 GPU 數(shù)量以及 index,并根據(jù)所需要的 GPU 數(shù)量返回對(duì)應(yīng)數(shù)量的 GPU Index 列表。當(dāng)無法獲取到所需數(shù)量的 GPU 時(shí),腳本將以非零值退出。
GPU 設(shè)備的資源分為兩個(gè)維度,流處理器與顯存,其顯存資源只支持獨(dú)占使用。因此,當(dāng)多個(gè) TaskManager 運(yùn)行在同一臺(tái)機(jī)器上時(shí),若一塊 GPU 被多個(gè)進(jìn)程使用,可能導(dǎo)致其顯存 OOM。因此,Standalone 模式下,需要 TaskManager 級(jí)別的資源隔離機(jī)制。
默認(rèn)腳本提供了 Coordination Mode 來支持單機(jī)中多個(gè) TaskManager 進(jìn)程之間的 GPU 資源隔離。該模式通過使用文件鎖來實(shí)現(xiàn)多進(jìn)程間 GPU 使用信息同步,協(xié)調(diào)同一臺(tái)機(jī)器上多個(gè) TaskManager 進(jìn)程對(duì) GPU 資源的使用。
5. 在算子中獲取擴(kuò)展資源信息
在用戶自定義算子中,可使用在 "external-resources" 中定義的資源名稱來調(diào)用 RuntimeContext 的 getExternalResourceInfos 接口獲取對(duì)應(yīng)擴(kuò)展資源的信息。以 GPU 為例,得到的每個(gè) ExternalResourceInfo 代表一塊 GPU 卡,而其中包含名為 "index" 的字段代表該 GPU 卡的設(shè)備 Index。
- public class ExternalResourceMapFunction extends RichMapFunction<String, String> { private static finalRESOURCE_NAME="gpu"; @Override public String map(String value) { Set<ExternalResourceInfo> gpuInfos = getRuntimeContext().getExternalResourceInfos(RESOURCE_NAME); List<String> indexes = gpuInfos.stream() .map(gpuInfo -> gpuInfo.getProperty("index").get()).collect(Collectors.toList()); // Map function with GPU// ... }}
6. MNIST Demo
下圖以 MNIST 數(shù)據(jù)集的識(shí)別任務(wù)來演示使用 GPU 加速 Flink 作業(yè)。
MNIST 如上圖所示,為手寫數(shù)字圖片數(shù)據(jù)集,每個(gè)圖片可表示為為 28*28 的矩陣。在該任務(wù)中,我們使用預(yù)訓(xùn)練好的 DNN 模型,圖片輸入經(jīng)過一層全連接網(wǎng)絡(luò)得到一個(gè) 10 維向量,該向量最大元素的下標(biāo)即為識(shí)別結(jié)果。
我們?cè)谝慌_(tái)擁有兩塊 GPU 卡的 ECS 上啟動(dòng)一個(gè)有兩個(gè) TaskManager 進(jìn)程的 Standalone 集群。借助默認(rèn)腳本提供的 Coordination Mode 功能,我們可以保證每個(gè) TaskManager 各使用其中一塊 GPU 卡。
該任務(wù)的核心算子為圖像識(shí)別函數(shù) MNISTClassifier,核心實(shí)現(xiàn)如下所示
- class MNISTClassifier extends RichMapFunction<List<Float>, Integer> { @Override public void open(Configuration parameters) { //獲取GPU信息并且選擇第一塊GPU Set<ExternalResourceInfo> externalResourceInfos = getRuntimeContext().getExternalResourceInfos(resourceName); final Optional<String> firstIndexOptional = externalResourceInfos.iterator().next().getProperty("index"); // 使用第一塊GPU的index初始化JCUDA組件 JCuda.cudaSetDevice(Integer.parseInt(firstIndexOptional.get())); JCublas.cublasInit(); }}
在 Open 方法中,從 RuntimeContext 獲取當(dāng)前 TaskManager 可用的 GPU,并選擇第一塊來初始化 JCuda 以及 JCublas 庫。
- class MNISTClassifier extends RichMapFunction<List<Float>, Integer> { @Override public Integer map(List<Float> value) { // 使用Jucblas做矩陣算法 JCublas.cublasSgemv('n', DIMENSIONS.f1, DIMENSIONS.f0, 1.0f, matrixPointer, DIMENSIONS.f1, inputPointer, 1, 0.0f, outputPointer, 1); // 獲得乘法結(jié)果并得出該圖所表示的數(shù)字 JCublas.cublasGetVector(DIMENSIONS.f1, Sizeof.FLOAT, outputPointer, 1, Pointer.to(output), 1); JCublas.cublasFree(inputPointer); JCublas.cublasFree(outputPointer); int result = 0; for (int i = 0; i < DIMENSIONS.f1; ++i) { result = output[i] > output[result] ? i : result; } return result; }}
在 Map 方法中,將預(yù)先訓(xùn)練好的模型參數(shù)與輸入矩陣放入 GPU 顯存,使用 JCublas 進(jìn)行 GPU 中的矩陣乘法運(yùn)算,最后將結(jié)果向量從 GPU 顯存中取出并得到識(shí)別結(jié)果數(shù)字。
具體案例演示流程可以前往觀看視頻或者參考 Github 上面的鏈接動(dòng)手嘗試。
四、未來計(jì)劃
除了上文介紹的這些已經(jīng)發(fā)布的特性外,Apache Flink 社區(qū)也正在積極準(zhǔn)備更多資源管理方面的優(yōu)化特性,在未來的版本中將陸續(xù)和大家見面。
被動(dòng)資源調(diào)度模式:托管內(nèi)存使得 Flink 任務(wù)可以靈活地適配不同的 TaskManager/Slot 資源,充分利用可用資源,為計(jì)算任務(wù)提供給定資源限制下的最佳算力。但用戶仍需指定計(jì)算任務(wù)的并行度,F(xiàn)link 需要申請(qǐng)到滿足該并行度數(shù)量的 TaskManager/Slot 才能順利執(zhí)行。被動(dòng)資源調(diào)度將使 Flink 能夠根據(jù)可用資源動(dòng)態(tài)改變并行度,在資源不足時(shí)能夠 best effort 進(jìn)行數(shù)據(jù)處理,同時(shí)在資源充足時(shí)恢復(fù)到指定的并行度保障處理性能。
細(xì)粒度資源管理:Flink 目前基于 Slot 的資源管理與調(diào)度機(jī)制,認(rèn)為所有的 Slot 都具有相同的規(guī)格。對(duì)于一些復(fù)雜的規(guī)模化生產(chǎn)任務(wù),往往需要將計(jì)算任務(wù)拆分成多個(gè)子圖,每個(gè)子圖單獨(dú)使用一個(gè) Slot 執(zhí)行。當(dāng)子圖間的資源需求差異較大時(shí),使用相同規(guī)格的 Slot 往往難以滿足資源效率方面的需求,特別是對(duì)于 GPU 這類成本較高的擴(kuò)展資源。細(xì)粒度資源管理允許用戶為作業(yè)的子圖指定資源需求,F(xiàn)link 會(huì)根據(jù)資源需求使用不同規(guī)格的 TaskManager/Slot 執(zhí)行計(jì)算任務(wù),從而優(yōu)化資源效率。
五、總結(jié)
通過文章的介紹,相信大家對(duì) Flink 內(nèi)存管理有了更加清晰的認(rèn)知。
首先從本地內(nèi)存、Job Graph 編譯階段、執(zhí)行階段來解答每個(gè)流程的內(nèi)存管理以及內(nèi)存分配細(xì)節(jié),通過新的參數(shù)配置控制 TaskManager的內(nèi)存分配;
然后從大家平時(shí)遇到資源調(diào)度相關(guān)問題,包括最大 Slot 數(shù)使用,如何進(jìn)行 TaskManager 進(jìn)行容錯(cuò),任務(wù)如何通過任務(wù)平鋪均攤?cè)蝿?wù)資源;
最后在機(jī)器學(xué)習(xí)和深度學(xué)習(xí)領(lǐng)域常常用到 GPU 進(jìn)行加速計(jì)算,通過解釋 Flink 在 1.12 版本如何使用擴(kuò)展資源框架和演示 Demo, 給我們展示了資源擴(kuò)展的使用。再針對(duì)資源利用率方面提出 2 個(gè)社區(qū)未來正在做的計(jì)劃,包括被動(dòng)資源模式和細(xì)粒度的資源管理。


















