B站崩了,如何防止類似事故的出現?
大家都知道雖然我是一個程序員,但是我非常熱愛運動,比如跳舞,這不每天回家睡前我都會在B站舞蹈區學習相關的舞蹈。
昨天也不例外,我一洗漱完就飛奔坐在電腦前,打開B站舞蹈區準備學習咬人喵,欣小萌、小仙若他們新的舞蹈動作,不得不說老婆們跳的真好,連我這種內向的人也不自覺的跟著扭動了起來。
正當我準備學下一個動作的時候,我發現怎么404 NOT found了。
壞了,作為開發的我第一直覺是系統崩了,我甚至懷疑是我網的問題,我發現手機網絡正常電腦訪問其他網頁也正常,我就知道開發要背鍋了。
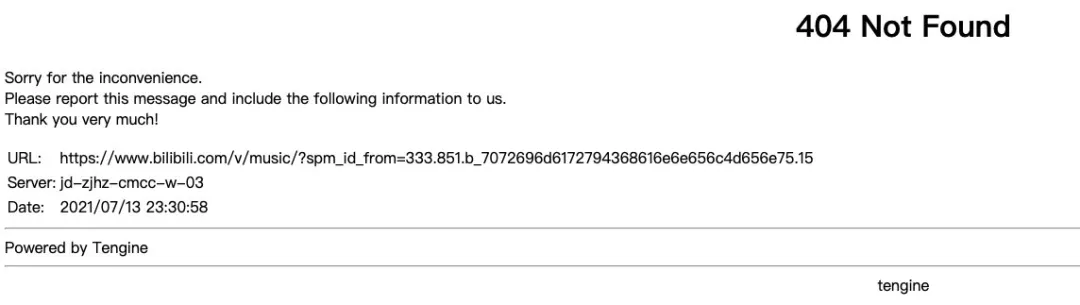
我刷新了幾次,發現還是這樣,我就有點同情對應的開發同學了,年終應該沒了。(到我寫這個文章的時候網站還沒恢復)
作為前程序員的我,就習慣性的去想B站的網站架構組成,以及這次事故復盤下來,可能會出問題的點。(老職業習慣了)
首先我們可以大致畫一下簡單的一個網站組成的架構圖,我們再去猜想這次問題可能出在什么地方。
因為熬夜寫文章哈,我也沒在這種主要靠視頻直播的公司呆過,技術棧也不是很了解,所以就用電商的大概邏輯,畫了一個草圖,大家輕點噴。
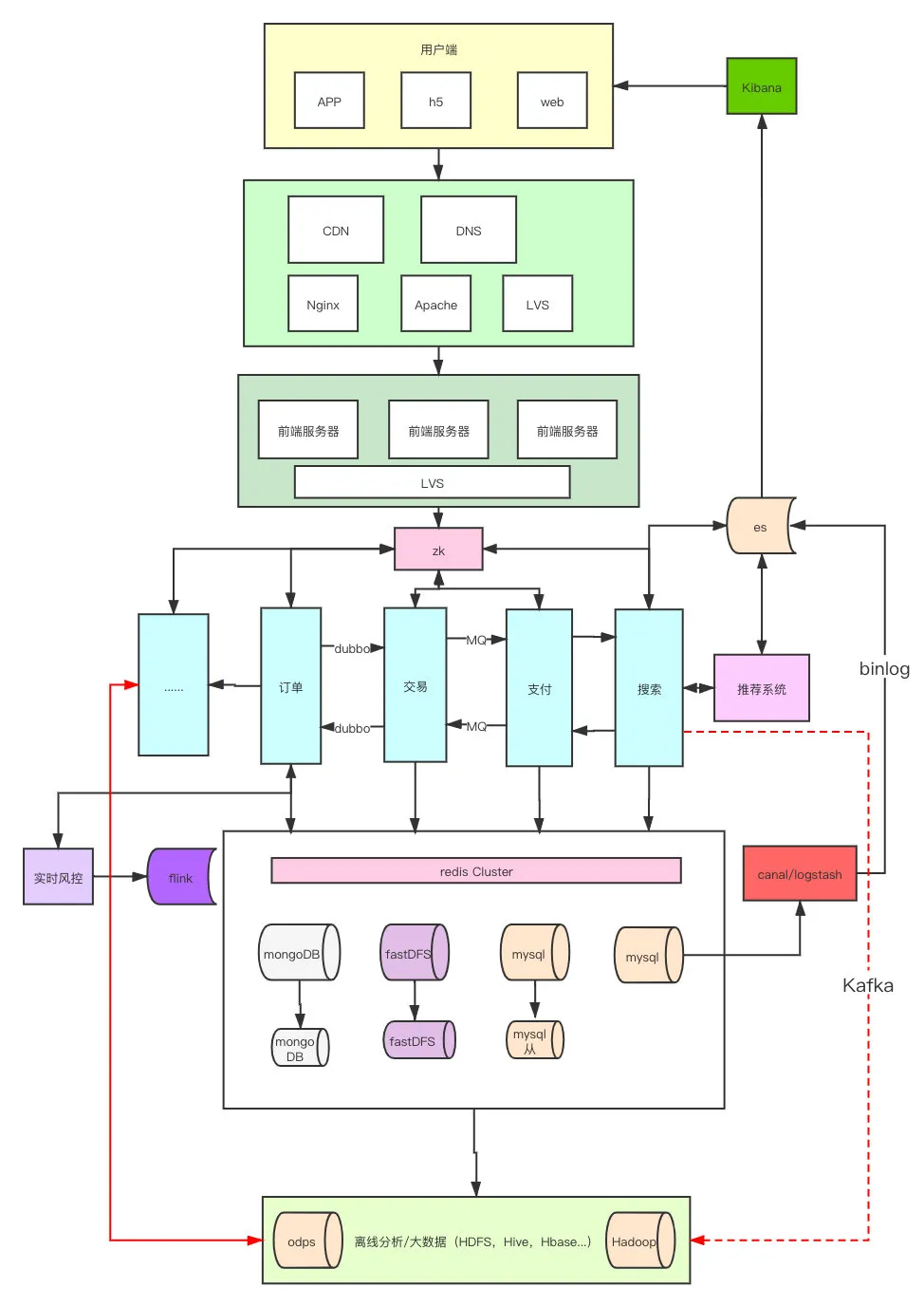
從上到下,從入口到cdn內容分發,到前端服務器,后端服務器,分布式存儲,大數據分析,風控到搜索引擎推薦這我就隨便畫了一下,我想整體架構應該不會差異特別大。
我去網上隨便查了一些類似斗魚,B站,a站這樣的公司,主要技術棧和技術難點主要有:
視頻訪問存儲
- 流
- 就近節點
- 視頻編解碼
- 斷點續傳(跟我們寫的io例子差多)
- 數據庫系統&文件系統隔離
并發訪問
- 流媒體服務器(各大廠商都有,帶寬成本較大)
- 數據集群,分布式存儲、緩存
- CDN內容分發
- 負載均衡
- 搜索引擎(分片)
彈幕系統
- 并發、線程
- kafka
- nio框架(netty)
其實跟我們大家學的技術都差不多,不過他們的對應微服務的語言組成可能go、php、vue、node占比比較大。
我們分析下這次事故可能出事的原因和地方:
1.刪庫跑路
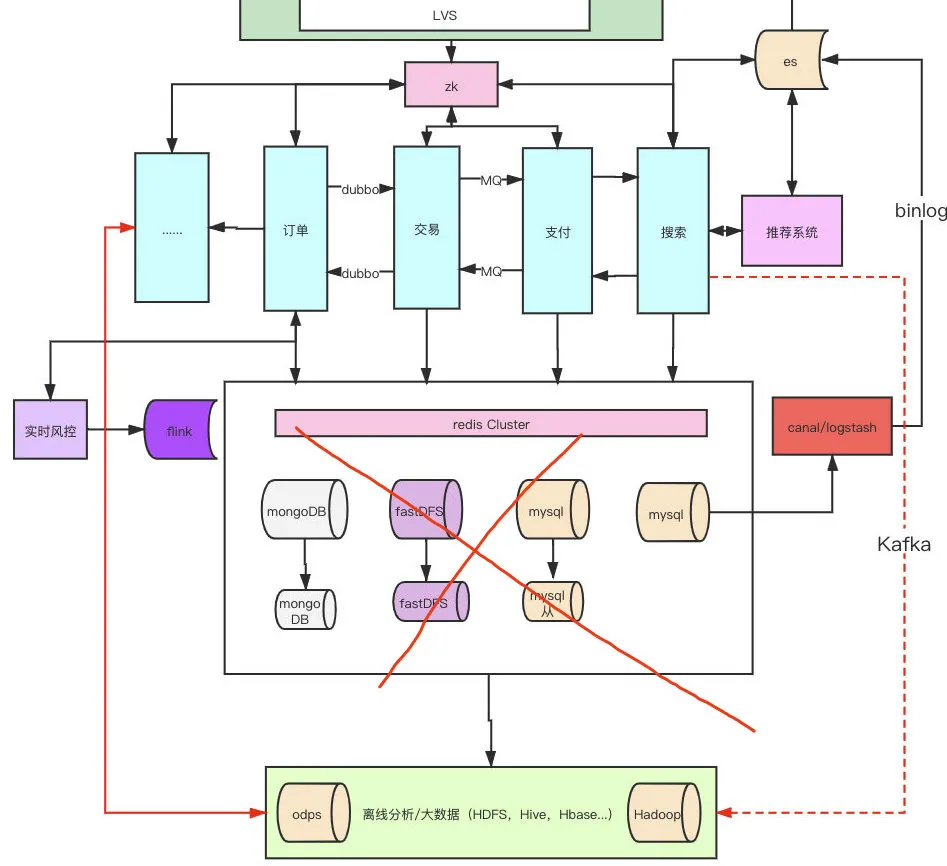
之前微盟發生過這個事情,我覺得各個公司應該都不會把運維的權限給這么大了,比如主機權限直接禁止了rm-rf、fdisk、drop這樣的命令。
而且數據庫現在大概率都是多主多從,多地備份的,容災也應該是做的很好的,而且光是數據庫炸了,那cdn的很多靜態資源應該也不會加載不出,整個頁面直接404了。
2.單微服務掛掉拖垮大集群
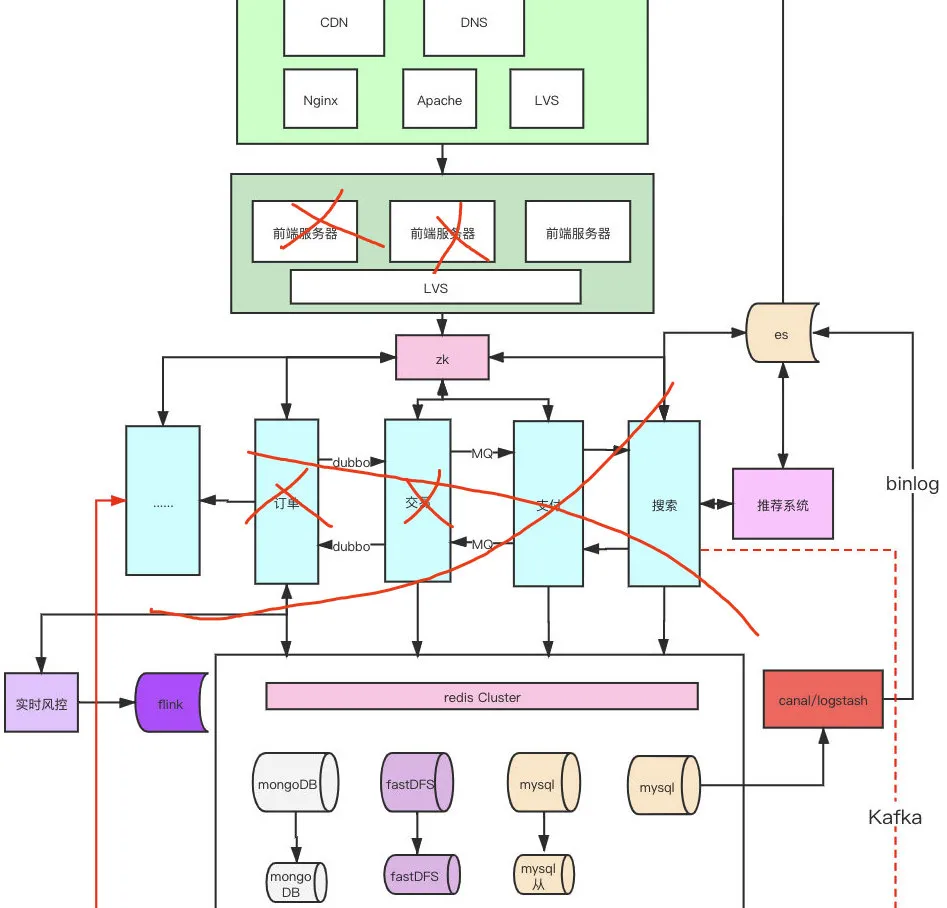
現在都是前后端分離的,如果是后端掛了,前端很多東西依然是能加載只是數據出不來報錯,所以集群要掛也可能是前端掛了,或者前后端一起掛了,但是還是那個問題,現在看起來是所有靜態資源都無法訪問了。
不過這個點我覺得也有一點可能,因為部分服務掛了,導致大量報錯,拉掛了集群,而且越是這樣大家越會不斷刷新頁面,給其他服務重啟增加難度,但是這個可能性沒我最后說的可能性大。
3.服務器廠商出問題了
這種大網站都是cdn+slb+站集群,各種限流降級、負載均衡按道理都會做的很好,而且他們按道理不會不做容災。
所以只有可能是這些前置服務的服務器廠商出問題了,CDN如果掛了那網關負載均衡啥的壓力都大了,最后導致連鎖的雪崩效應打掛了整套系統。
但是我比較疑惑的是B站的BFF應該會路由到一些接入節點比較近的機房,這樣全國各地的小伙伴刷的時候,應該是有些人好,有些人壞,有些人時好時壞才對,但是現在看來是全壞了,難道他們押寶了一個廠商的一個節點片區?
我看網上也在傳云海數據中心起火了,不知道真假,只能等醒來看看B站官宣了,B站原則上,理論上,從CDN、分布式存儲、大數據、搜索引擎都應該做了很多保證措施才對,如果真all in了一個地方那確實不太明智。
我的感覺就是沒做好全部上云,線下的服務器出了問題,剛好是沒上云的是關鍵業務,現在公司都是公有云+私有云這樣的混合云搭配用的,但是私有云部分都是B站自己的內部業務,所以應該不會他自己的機房出問題。
如果真像我說的,押寶了一個服務器廠商,只是cdn出問題還好,如果物理機還出問題了,那數據恢復可能就慢了,我自己之前做大數據的,我知道數據備份都是增量+全量,恢復的時候真的好了一部分還可以從其他地區節點拉,但是如果是放在一個地方了,那就麻煩了。
復盤
我想不管最后是什么原因造成的,我們技術人和公司應該思考的就是怎么去避免這樣事情的發生。
數據備份: 備份一定要做,不然如果真發生什么自然災害,那是很難受的,所以很多云廠商現在都選在貴州我老家這樣自然災害比較少的地方、或者湖底、海底(比較涼快成本能下去不少)。
全量、增量基本上都是一直要做的,分天、周、月不斷的增量數據,以及按時的全量數據備份,這樣可以讓損失降低很多,就怕所有地區的機械盤都壞了(異地容災除了地球毀滅不然都能找回來)。
運維權限收斂,還是怕刪庫跑路,反正我是經常在服務器上rm-rf,不過一般有跳板機才能進去的都可以做命令禁止。
上云+云原生: 云產品的各種能力現在很成熟的,企業應該對對應的云廠商有足夠的信任,當然也得選對才行,云產品的各種能力是其一,還有關鍵時刻的容災、應急響應機制都是很多公司不具備的。
云原生是近些年大家才重視的技術,docker+k8s這對應的一些組合,加上云計算的各種能力,其實可以做到無人值守,動態縮擴容,以及上面說的應急響應,但是技術本身是需要一些嘗試成本的,而且我也不知道B站這樣視頻為主的體系,適不適合。
kubernetes的設計上也會存在一些編排、通信的問題。
自身實力打造: 其實我覺得不管是上云,還是不上云,都不能太依賴很多云廠商,自己的核心技術體系和應急機制還是要有,如果云廠商真的靠不住怎么辦?怎么去做真正的高可用,這我覺得是企業技術人員需要去思考的。
舉個例子,很多云廠商都是一個物理機隔成多個虛擬機售賣,然后就會存在單物理機多宿主的情況,假如其中一方是電商玩雙十一,一方是游戲廠商,對方大量占用網絡帶寬,你就可能存在丟包的情況,這對游戲用戶來說是體驗極差的,這樣就是我說為啥不要過于信任和依賴云廠商的原因。
對方萬一買了去挖礦,那更過分,把算力榨干,滿負荷跑更難受。
B站這次,好在這樣的問題提前暴露了,而且是晚上,應該有不少流量低谷的時間去恢復,我寫到這里的時候,網頁大部分恢復了,但是我發現還是部分恢復。
不管怎么說下次就可以完全杜絕了,相信B站后面很長一段時間都會忙于架構體系改造,去保證自己真正的高可用。
希望以后能讓我穩定的在晚上看看舞蹈區,而不是盯著502、404的2233娘發呆,嘻嘻