













兼具CNNTransformer優勢,靈活使用歸納偏置,Facebook提出ConViT
AI 研究人員在構建新的機器學習模型和訓練范式時,通常會使用一組被稱為歸納偏置(inductive biases)的特定假設,來幫助模型從更少的數據中學到更通用的解決方案。近十年來,深度學習的巨大成功在一定程度上歸功于強大的歸納偏置,基于其卷積架構已被證實在視覺任務上非常成功,它們的 hard 歸納偏置使得樣本高效學習成為可能,但代價是可能會降低性能上限。而視覺 Transformer(如 ViT)依賴于更加靈活的自注意力層,最近在一些圖像分類任務上性能已經超過了 CNN,但 ViT 對樣本的需求量更大。
來自 Facebook 的研究者提出了一種名為 ConViT 的新計算機視覺模型,它結合了兩種廣泛使用的 AI 架構——卷積神經網絡 (CNN) 和 Transformer,該模型取長補短,克服了 CNN 和 Transformer 本身的一些局限性。同時,借助這兩種架構的優勢,這種基于視覺 Transformer 的模型可以勝過現有架構,尤其是在小數據的情況下,同時在大數據的情況下也能實現類似的優秀性能。

- 論文地址:https://arxiv.org/pdf/2103.10697.pdf
- GitHub 地址:https://github.com/facebookresearch/convit
在視覺任務上非常成功的 CNN 依賴于架構本身內置的兩個歸納偏置:局部相關性:鄰近的像素是相關的;權重共享:圖像的不同部分應該以相同的方式處理,無論它們的絕對位置如何。
相比之下,基于自注意力機制的視覺模型(如 DeiT 和 DETR)最小化了歸納偏置。當在大數據集上進行訓練時,這些模型的性能已經可以媲美甚至超過 CNN 。但在小數據集上訓練時,它們往往很難學習有意義的表征。
這就存在一種取舍權衡:CNN 強大的歸納偏置使得即使使用非常少的數據也能實現高性能,但當存在大量數據時,這些歸納偏置就可能會限制模型。相比之下,Transformer 具有最小的歸納偏置,這說明在小數據設置下是存在限制的,但同時這種靈活性讓 Transformer 在大數據上性能優于 CNN。
為此,Facebook 提出的 ConViT 模型使用 soft 卷積歸納偏置進行初始化,模型可以在必要時學會忽略這些偏置。
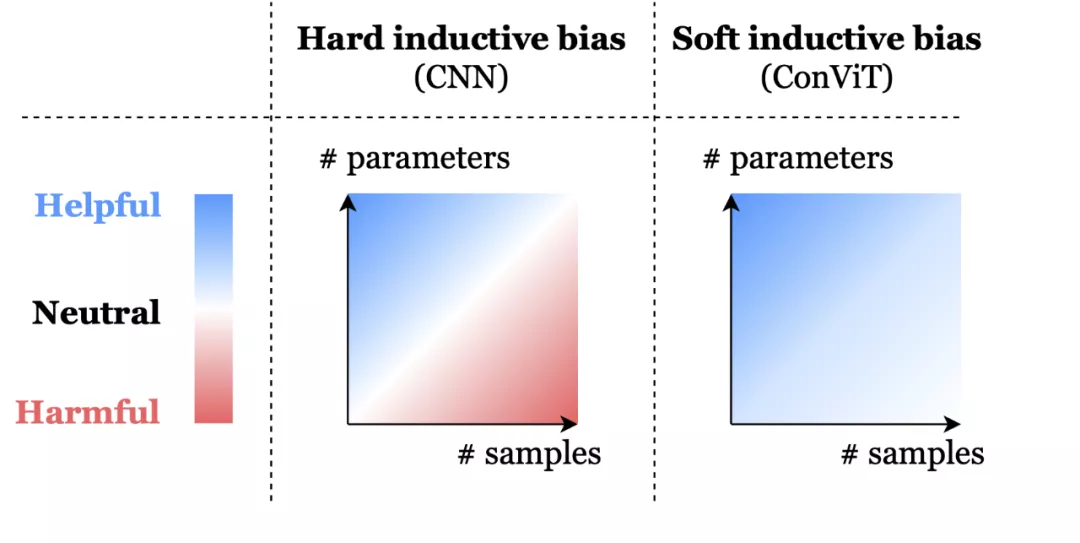
soft 歸納偏置可以幫助模型不受限制地學習。hard 歸納偏置,例如 CNN 的架構約束,可以極大地提高學習的樣本效率,但當數據集大小不確定時可能就會成為約束。ConViT 中的 soft 歸納偏置能夠在不需要時被忽略,以避免模型受到約束限制。
ConViT 工作原理
ConViT 在 vision Transformer 的基礎上進行了調整,以利用 soft 卷積歸納偏置,從而激勵網絡進行卷積操作。同時最重要的是,ConViT 允許模型自行決定是否要保持卷積。為了利用這種 soft 歸納偏置,研究者引入了一種稱為「門控位置自注意力(gated positional self-attention,GPSA)」的位置自注意力形式,其模型學習門控參數 lambda,該參數用于平衡基于內容的自注意力和卷積初始化位置自注意力。
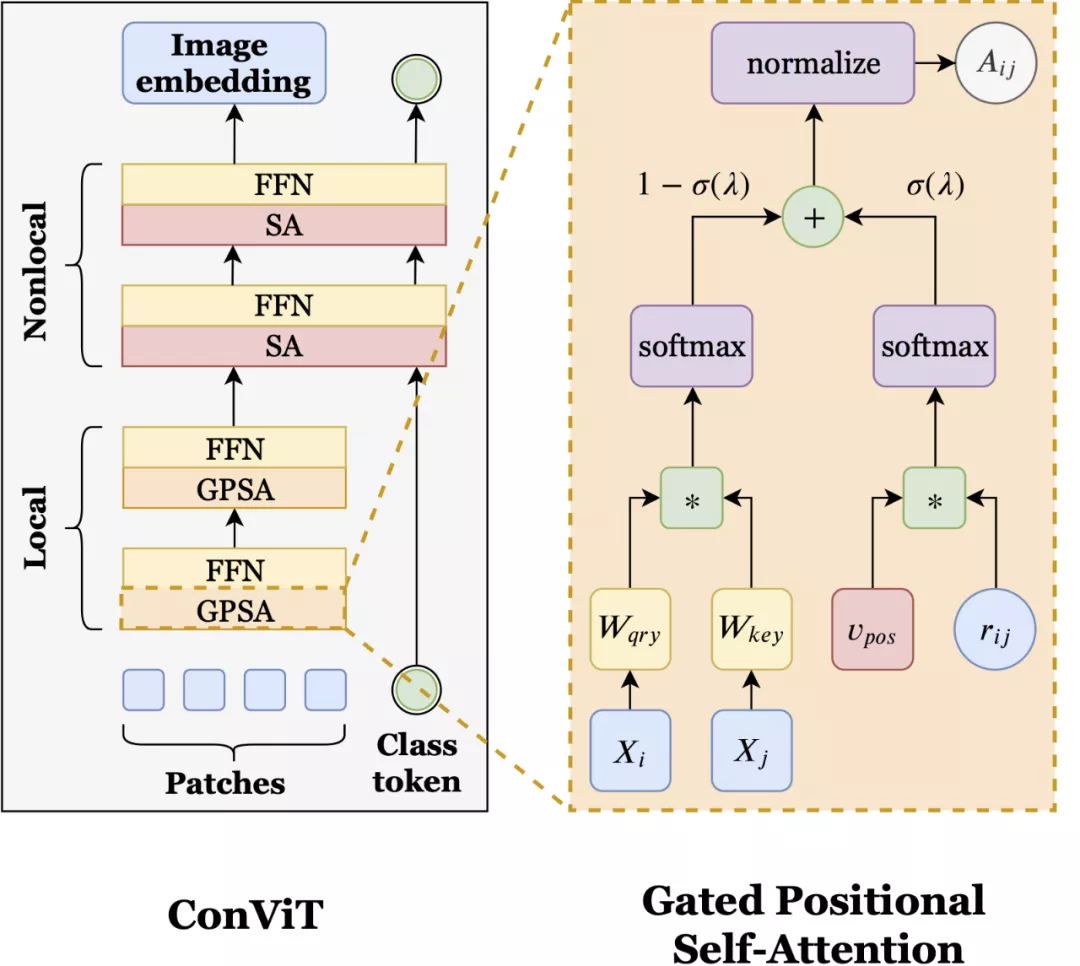
如上圖所示,ConViT(左)在 ViT 的基礎上,將一些自注意力(SA)層用門控位置自注意力層(GPSA,右)替代。因為 GPSA 層涉及位置信息,因此在最后一個 GPSA層之后,類 token 會與隱藏表征聯系到一起。
有了 GPSA 層加持,ConViT 的性能優于 Facebook 去年提出的 DeiT 模型。例如,ConViT-S+ 性能略優于 DeiT-B(對比結果為 82.2% vs. 81.8%),而 ConViT-S + 使用的參數量只有 DeiT-B 的一半左右 (48M vs 86M)。而 ConViT 最大的改進是在有限的數據范圍內,soft 卷積歸納偏置發揮了重要作用。例如,僅使用 5% 的訓練數據時,ConViT 的性能明顯優于 DeiT(對比結果為 47.8% vs. 34.8%)。
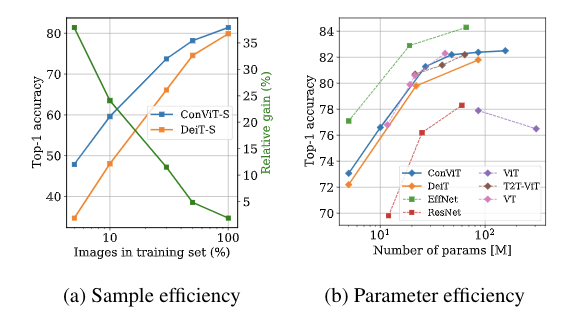
此外,ConViT 在樣本效率和參數效率方面也都優于 DeiT。如上圖所示,左圖為 ConViT-S 與 DeiT-S 的樣本效率對比結果,這兩個模型是在相同的超參數,且都是在 ImageNet-1k 的子集上訓練完成的。圖中綠色折線是 ConViT 相對于 DeiT 的提升。研究者還在 ImageNet-1k 上比較了 ConViT 模型與其他 ViT 以及 CNN 的 top-1 準確率,如上右圖所示。
除了 ConViT 的性能優勢外,門控參數提供了一種簡單的方法來理解模型訓練后每一層的卷積程度。查看所有層,研究者發現 ConViT 在訓練過程中對卷積位置注意力的關注逐漸減少。對于靠后的層,門控參數最終會收斂到接近 0,這表明卷積歸納偏置實際上被忽略了。然而,對于起始層來說,許多注意力頭保持較高的門控值,這表明該網絡利用早期層的卷積歸納偏置來輔助訓練。
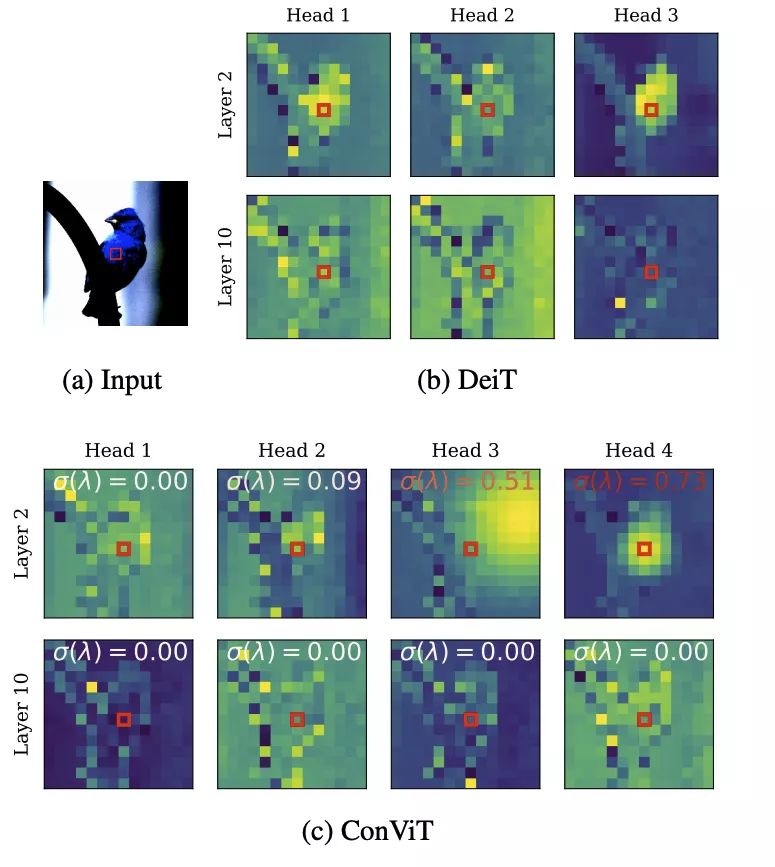
上圖展示了 DeiT (b) 及 ConViT (c) 注意力圖的幾個例子。σ(λ) 表示可學習的門控參數。接近 1 的值表示使用了卷積初始化,而接近 0 的值表示只使用了基于內容的注意力。注意,早期的 ConViT 層部分地維護了卷積初始化,而后面的層則完全基于內容。
測試是在 ImageNet-1K 上進行的,沒有進行知識蒸餾,結果如下:

AI 模型的性能在很大程度上取決于訓練這些模型所用的數據類型和數據規模。在學術研究和現實應用中,模型經常受到可用數據的限制。ConViT 提出的這種 soft 歸納偏置,在適當的時候能夠被忽略,這種創造性的想法讓構建更靈活的人工智能系統前進了一步。

















