基于實(shí)時(shí)深度學(xué)習(xí)的推薦系統(tǒng)架構(gòu)設(shè)計(jì)和技術(shù)演進(jìn)
本文整理自 5 月 29 日阿里云開(kāi)發(fā)者大會(huì),大數(shù)據(jù)與 AI 一體化平臺(tái)分論壇,秦江杰和劉童璇帶來(lái)的《基于實(shí)時(shí)深度學(xué)習(xí)的推薦系統(tǒng)架構(gòu)設(shè)計(jì)和技術(shù)演進(jìn)》。分享內(nèi)容如下:
1.實(shí)時(shí)推薦系統(tǒng)的原理以及什么是實(shí)時(shí)推薦系統(tǒng)
2.整體系統(tǒng)的架構(gòu)及如何在阿里云上面實(shí)現(xiàn)
3.關(guān)于深度學(xué)習(xí)的細(xì)節(jié)介紹。
一、實(shí)時(shí)推薦系統(tǒng)的原理
在介紹實(shí)時(shí)推薦系統(tǒng)的原理之前,先來(lái)看一個(gè)傳統(tǒng)、經(jīng)典的靜態(tài)推薦系統(tǒng)。
用戶(hù)的行為日志會(huì)出現(xiàn)在消息隊(duì)列里,然后被ETL到特征生成和模型訓(xùn)練中。這部分的數(shù)據(jù)是離線的,離線的模型更新和特征更新會(huì)被推到在線系統(tǒng)里面,比如特征庫(kù)和在線推理的服務(wù)中,然后去服務(wù)在線的搜索推廣應(yīng)用。這個(gè)推薦系統(tǒng)本身是一個(gè)服務(wù),前端展示的服務(wù)推廣應(yīng)用可能有搜索推薦、廣告推薦等。那么這個(gè)靜態(tài)系統(tǒng)到底是怎么工作的?我們來(lái)看下面的例子。
1. 靜態(tài)推薦系統(tǒng)
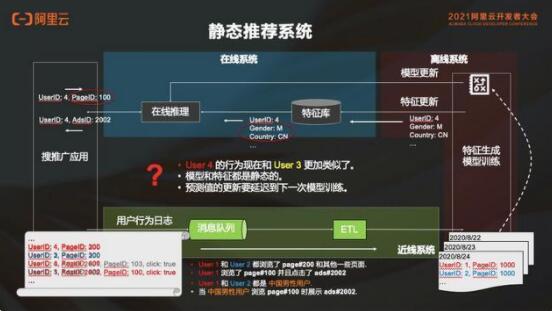
截取現(xiàn)在用戶(hù)的行為日志,倒入離線系統(tǒng)中去做特征生成和模型訓(xùn)練,這段日志表示用戶(hù) 1 和用戶(hù) 2 同時(shí)瀏覽了 page#200 這個(gè)頁(yè)面和其他一些頁(yè)面,其中用戶(hù) 1 瀏覽了 page#100 并且點(diǎn)擊了 ads#2002。那么這個(gè)日志會(huì)被 ETL 到離線,然后送去做特征生成和模型訓(xùn)練。生成的特征和模型里面會(huì)看到,用戶(hù) 1 和用戶(hù) 2 都是中國(guó)男性用戶(hù),“中國(guó)男性”是這兩個(gè)用戶(hù)的一個(gè)特征,這個(gè)學(xué)習(xí)模型最終結(jié)果是:中國(guó)男性用戶(hù)瀏覽了 page#100 的時(shí)候,需要給他推 ads#2002。這里面的邏輯就是把相似用戶(hù)的行為歸到一起,說(shuō)明這類(lèi)用戶(hù)應(yīng)該有同樣的行為。
用戶(hù)特征推進(jìn)特征庫(kù)建立的模型,在推送至在線服務(wù)里的時(shí)候如果有一個(gè)用戶(hù) 4 出現(xiàn),在線推理的服務(wù)就會(huì)到特征庫(kù)里面去查這個(gè)用戶(hù)的特征,查到的特征可能是這個(gè)用戶(hù)正好是中國(guó)的男性用戶(hù),模型之前學(xué)到了中國(guó)男性用戶(hù)訪問(wèn) page#100 時(shí)候要推 ads#2002,所以會(huì)根據(jù)學(xué)習(xí)模型給用戶(hù) 4 推薦了 ads#2002。以上就是靜態(tài)推薦系統(tǒng)的基本工作流程。
但是這個(gè)系統(tǒng)也有一些問(wèn)題,比如第一天的模型訓(xùn)練完成后,發(fā)現(xiàn)用戶(hù) 4 第二天的行為其實(shí)跟用戶(hù) 3 更像,不是和用戶(hù) 1、用戶(hù) 2 類(lèi)似 。但是之前模型訓(xùn)練的結(jié)果是中國(guó)男性用戶(hù)訪問(wèn) page#100 時(shí)候要推 ads#2002,并且會(huì)默認(rèn)進(jìn)行這種推薦。只有經(jīng)過(guò)第二次模型計(jì)算后才能發(fā)現(xiàn)用戶(hù) 4 和用戶(hù) 3 比較像,這時(shí)再進(jìn)行新的推薦,是有延遲的。這是因?yàn)槟P秃吞卣鞫际庆o態(tài)的。
對(duì)于靜態(tài)推薦系統(tǒng)來(lái)講,特征和模型都是靜態(tài)生成的。比如以分類(lèi)模型為例,根據(jù)用戶(hù)的相似度進(jìn)行分類(lèi),然后假設(shè)同類(lèi)用戶(hù)都有相似的行為興趣和特征,一旦用戶(hù)被化成了某一類(lèi),那么他就一直在這個(gè)類(lèi)別中,直到模型被重新訓(xùn)練。
2. 靜態(tài)推薦系統(tǒng)問(wèn)題
第一,用戶(hù)行為其實(shí)是非常多元化的,沒(méi)有辦法用一個(gè)靜態(tài)的事情去描述這個(gè)用戶(hù)的行為。
第二,某一類(lèi)用戶(hù)的行為可能比較相似,但是行為本身發(fā)生了變化。例如中國(guó)男性用戶(hù)訪問(wèn)page#100時(shí)候要推ads#2002,這是昨天的行為規(guī)律;但是到了第二天的時(shí)候發(fā)現(xiàn)不是所有的中國(guó)男性用戶(hù)看到page#100時(shí)候都會(huì)點(diǎn)擊ads#2002。
3. 解決方案
3.1 加入實(shí)時(shí)特征工程后能夠靈活推薦
在推薦系統(tǒng)中加入實(shí)時(shí)特征工程,把消息隊(duì)列里面的消息讀一份出來(lái),然后去做近線的特征生成。舉個(gè)例子,中國(guó)男性用戶(hù)最近訪問(wèn) page#100 的時(shí)候點(diǎn)擊最多的 10 個(gè)廣告,這件事情是實(shí)時(shí)去追蹤的。就是說(shuō)中國(guó)男性用戶(hù)最近 10 分鐘或者半個(gè)小時(shí)之內(nèi)訪問(wèn) page#100 的時(shí)候點(diǎn)的最多 10 個(gè)廣告,個(gè)事情不是從昨天的歷史數(shù)據(jù)里面得到的信息,而是今天的用戶(hù)實(shí)時(shí)行為的數(shù)據(jù),這就是實(shí)時(shí)特征。
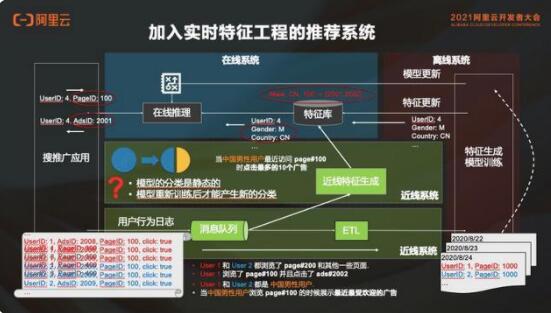
有了這個(gè)實(shí)時(shí)特征以后,就能解決剛才那個(gè)隨大流的問(wèn)題。同樣的,如果這里的特征是對(duì)某一個(gè)用戶(hù)最近 3 分鐘或者 5 分鐘的行為采集的,就能夠更加準(zhǔn)確的追蹤到這個(gè)用戶(hù)當(dāng)時(shí)當(dāng)刻的意圖,并且給這個(gè)用戶(hù)去做更準(zhǔn)確的推薦。
所以說(shuō),在推薦系統(tǒng)中加入實(shí)時(shí)特征后能精準(zhǔn)推薦。比如剛才的例子,如果用戶(hù) 4 在這個(gè)情況下訪問(wèn) page#100,新的學(xué)習(xí)內(nèi)容為:中國(guó)男性用戶(hù)最近訪問(wèn) page#100 的時(shí)候,點(diǎn)的最多的是 ads#2001。那我們會(huì)直接推薦 ads#2001,而不是按照昨天的信息給他推 ads#2002。
3.2 實(shí)時(shí)特征推薦體系的局限性
之前的用戶(hù) 1 和用戶(hù) 2 的行為是非常相似的,加了實(shí)時(shí)特征就能知道它當(dāng)前的意圖。但是,如果用戶(hù) 1 和用戶(hù) 2 在做相同的特征時(shí),他們的行為產(chǎn)生了不一致;也就是說(shuō)在模型里面被認(rèn)為是同一類(lèi)的用戶(hù),他們的行為產(chǎn)生分化了,變成了兩類(lèi)用戶(hù)。如果是靜態(tài)的模型,即使加入了實(shí)時(shí)特征,也無(wú)法發(fā)現(xiàn)這一類(lèi)新的用戶(hù);需要對(duì)模型進(jìn)行重新訓(xùn)練以后,才能夠產(chǎn)生一個(gè)新的分類(lèi)。
加入實(shí)施特征工程推薦系統(tǒng)后,可以追蹤某一類(lèi)用戶(hù)的行為,貼合一個(gè)大流的變化;也可以實(shí)時(shí)追蹤用戶(hù)的表現(xiàn),了解用戶(hù)當(dāng)時(shí)的意圖。但是當(dāng)模型本身的分類(lèi)方式發(fā)生變化的時(shí)候,就沒(méi)有辦法找到最合適的分類(lèi)了,需要重新對(duì)訓(xùn)練模型進(jìn)行分類(lèi),這種情況會(huì)遇到很多。
比如說(shuō)當(dāng)有很多新產(chǎn)品上線時(shí),業(yè)務(wù)在高速增長(zhǎng),每天都會(huì)產(chǎn)生很多的新用戶(hù),或者說(shuō)用戶(hù)行為分布變化得比較快。這種情況下即使使用了實(shí)時(shí)特征系統(tǒng),由于模型本身是一個(gè)逐漸退化的過(guò)程,也會(huì)導(dǎo)致昨天訓(xùn)練的模型今天再放到線上去,不一定能夠 work 的很好。
3.3 解決方案
在推薦系統(tǒng)中新增兩個(gè)部分:近線訓(xùn)練和近線樣本生成。
假設(shè)有用戶(hù) 1 和用戶(hù) 2 分別是上海和北京的用戶(hù),這個(gè)時(shí)候會(huì)發(fā)現(xiàn)之前的模型不知道上海和北京的用戶(hù)是有區(qū)別的,它認(rèn)為都是中國(guó)男性用戶(hù)。而在加入實(shí)時(shí)訓(xùn)練這個(gè)模型后,就會(huì)逐漸的學(xué)習(xí)北京的用戶(hù)和上海的用戶(hù),兩者的行為是有區(qū)別的,確認(rèn)這一點(diǎn)后再進(jìn)行推薦就會(huì)有不一樣的效果。
再比如說(shuō),今天北京突然下暴雨了或者上海天氣特別熱,這個(gè)時(shí)候都會(huì)導(dǎo)致兩邊用戶(hù)的行為不太一樣。這時(shí)再有一個(gè)用戶(hù) 4 過(guò)來(lái),模型就會(huì)分辨這個(gè)用戶(hù)是上海還是北京的用戶(hù)。如果他是上海的用戶(hù),可能就會(huì)推薦上海用戶(hù)所對(duì)應(yīng)的內(nèi)容;如果不是的話,可以繼續(xù)推薦別的。
加入實(shí)時(shí)模型訓(xùn)練,最主要的目的是在動(dòng)態(tài)特征的基礎(chǔ)上,希望模型本身能夠盡可能的貼合此時(shí)此刻用戶(hù)行為的分布,同時(shí)希望能夠緩解模型的退化。
二、 阿里巴巴實(shí)時(shí)推薦方案
首先了解下阿里內(nèi)部實(shí)施完這套方案之后有什么好處:
第一個(gè)是時(shí)效性。目前阿里大促開(kāi)始常態(tài)化,在大促期間整個(gè)模型的時(shí)效性得到了很好的提升;
第二個(gè)是靈活性。可以根據(jù)需求隨時(shí)調(diào)整特征和模型;
第三個(gè)是可靠性。大家在使用整個(gè)實(shí)時(shí)推薦系統(tǒng)的時(shí)候會(huì)覺(jué)得不放心,沒(méi)有經(jīng)過(guò)離線當(dāng)天晚上大規(guī)模的計(jì)算驗(yàn)證,直接推上線,會(huì)覺(jué)得不夠可靠,其實(shí)已經(jīng)有一套完整的流程去保證這件事情的穩(wěn)定性和可靠性;
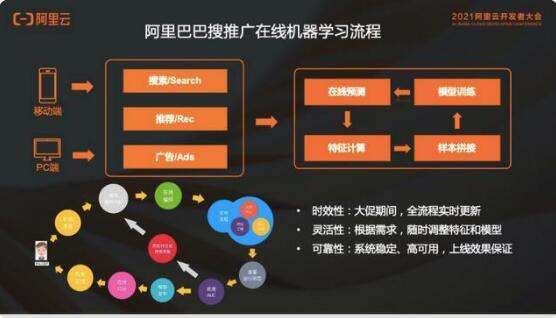
這個(gè)推薦模型從圖上看,從特征到樣本到模型,再到在線預(yù)測(cè)這個(gè)過(guò)程,和離線其實(shí)沒(méi)有區(qū)別。主要的區(qū)別就是整個(gè)的流程實(shí)時(shí)化,用這套實(shí)時(shí)化的流程去服務(wù)在線的搜索推廣應(yīng)用。
1. 如何實(shí)施
根據(jù)經(jīng)典離線架構(gòu)進(jìn)行演變。
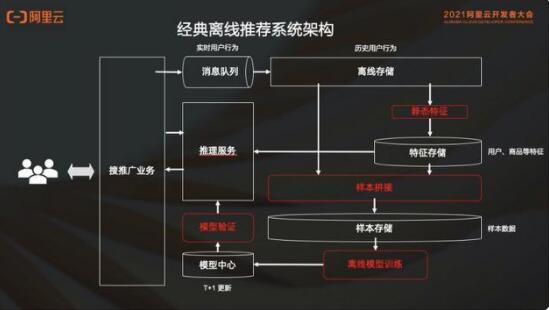
首先,用戶(hù)群行為會(huì)從消息隊(duì)列來(lái)走離線存儲(chǔ),然后這個(gè)離線存儲(chǔ)會(huì)存儲(chǔ)所有的歷史用戶(hù)行為;然后在這個(gè)離線存儲(chǔ)上面,通過(guò)靜態(tài)特征計(jì)算樣本;接下來(lái)把樣本存到樣本存儲(chǔ)里,去做離線模型訓(xùn)練;之后把離線的這個(gè)模型發(fā)布到模型中心,去做模型驗(yàn)證;最后把模型驗(yàn)證過(guò)的模型推到推理服務(wù)去服務(wù)在線業(yè)務(wù)。這個(gè)就是完整的離線體系。
我們將通過(guò)三件事情進(jìn)行實(shí)時(shí)化改造:
第一是特征計(jì)算;
第二是樣本生成;
第三是模型訓(xùn)練。
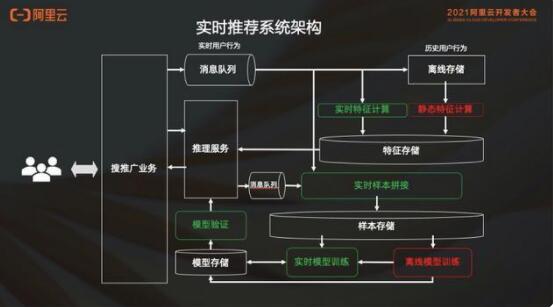
相比之前,消息隊(duì)列不僅僅存入離線存儲(chǔ),還要分出來(lái)兩鏈路:
第一鏈路會(huì)做實(shí)時(shí)的特征計(jì)算,比如說(shuō)最近幾分鐘之內(nèi)中國(guó)男性用戶(hù)看 page#100 的時(shí)候點(diǎn)了什么廣告,這個(gè)是實(shí)時(shí)計(jì)算算出來(lái)的,即最近一段時(shí)間的一些用戶(hù)可能產(chǎn)生的一些行為特征等。
另外一條鏈路是消息隊(duì)列,可以進(jìn)行實(shí)時(shí)樣本拼接,就是說(shuō)不需要手動(dòng)去打標(biāo)簽,因?yàn)橛脩?hù)自己會(huì)告訴我們標(biāo)簽。比如我們做了一個(gè)推薦,如果用戶(hù)點(diǎn)擊了,那么它一定是個(gè)正樣本;如果過(guò)了一段時(shí)間用戶(hù)沒(méi)有點(diǎn)擊,那我們認(rèn)為它就是個(gè)負(fù)樣本。所以不用人工去打標(biāo)簽,用戶(hù)會(huì)幫我們打標(biāo)簽,這個(gè)時(shí)候很容易就能夠得到樣本,然后這部分樣本會(huì)放到樣本存儲(chǔ)里面去,這個(gè)跟之前是一樣的。區(qū)別在于這個(gè)樣本存儲(chǔ)不僅服務(wù)離線的模型訓(xùn)練,還會(huì)去做實(shí)時(shí)的模型訓(xùn)練。
離線模型訓(xùn)練通常還是天級(jí)的 T+1 的,會(huì)訓(xùn)練出一個(gè) base model ,交給實(shí)時(shí)模型訓(xùn)練去做增量的訓(xùn)練。增量模型訓(xùn)練的模型產(chǎn)出就可能是 10 分鐘、15 分鐘這樣的級(jí)別,然后會(huì)送到模型存儲(chǔ)做模型驗(yàn)證,最后上線。
架構(gòu)圖中綠色的部分都是實(shí)時(shí)的,這部分有一些是新加出來(lái)的,有一些則是由原本的離線變成實(shí)時(shí)的。
2. 阿里云企業(yè)級(jí)實(shí)時(shí)推薦解決方案
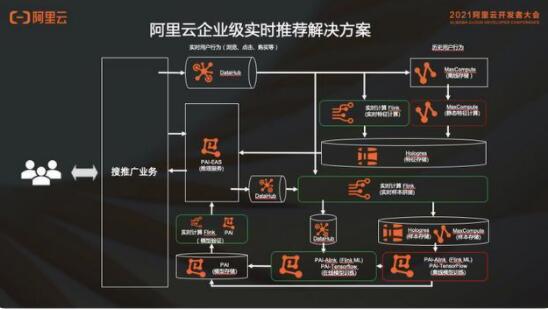
在阿里云企業(yè)級(jí)實(shí)時(shí)推薦解決方案中,如何使用阿里云產(chǎn)品搭建?
消息隊(duì)列會(huì)用 DataHub;實(shí)時(shí)的特征和樣本使用實(shí)時(shí)計(jì)算 Flink 版;離線的特征存儲(chǔ)和靜態(tài)特征計(jì)算都會(huì)用 MaxCompute;特征存儲(chǔ)和樣本中心使用 MaxCompute 交互式分析(Hologres);消息隊(duì)列的部分都是 DataHub;模型訓(xùn)練的部分會(huì)用到 PAI,模型存儲(chǔ)和驗(yàn)證,還有在線推理服務(wù)這一套流程都是 PAI 里面的。
2.1 實(shí)時(shí)特征計(jì)算及推理
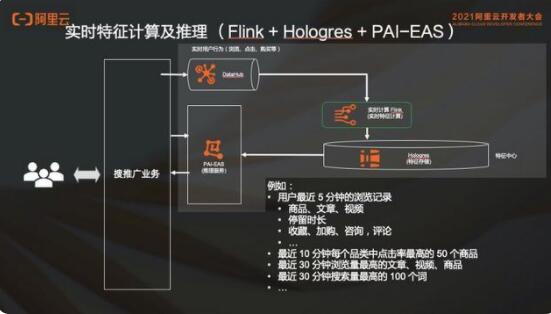
特征和推理就是把用戶(hù)日志實(shí)時(shí)采集過(guò)來(lái),導(dǎo)入實(shí)時(shí)計(jì)算 Flink 版里面去做實(shí)時(shí)特征計(jì)算。然后會(huì)送到 Hologres 里面去,利用 Hologres 流式的能力,拿它做特征中心。在這里,PAI 可以去直接查詢(xún) Hologres 里面的這些用戶(hù)特征,也就是點(diǎn)查的能力。
在實(shí)時(shí)計(jì)算 Flink 版計(jì)算特征的時(shí)候,比如說(shuō)用戶(hù)最近 5 分鐘的瀏覽記錄,包括商品、文章、視頻等,根據(jù)不同的業(yè)務(wù)屬性,實(shí)時(shí)特征是不一樣的。也可能包括比如最近 10 分鐘每個(gè)品類(lèi)點(diǎn)擊率最高的 50 個(gè)商品,最近 30 分鐘瀏覽量最高的文章、視頻、商品,最近 30 分鐘搜索量最高的是 100 個(gè)詞等。在這不同的場(chǎng)景,比如搜索推薦,有廣告、有視頻、有文本、有新聞等。這些數(shù)據(jù)拿來(lái)做實(shí)時(shí)特征計(jì)算的和推理的這一條鏈路,然后在這個(gè)鏈路基礎(chǔ)之上,有的時(shí)候也是需要靜態(tài)特征回填的。
2.2 靜態(tài)特征回填
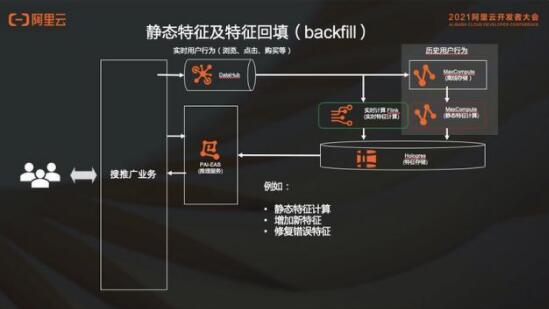
比如新上線一個(gè)特征,這個(gè)新的特征在實(shí)時(shí)鏈路上線了之后,如果需要最近 30 天用戶(hù)的行為,不可能等 30 天之后再計(jì)算。于是需要找到離線數(shù)據(jù),然后把最近 30 天的這個(gè)特征給它補(bǔ)上。這就叫特征回填,也就是 backfill 。通過(guò) MaxCompute 去算這個(gè)特征回填一樣也是寫(xiě)到 Hologres,同時(shí)實(shí)施起來(lái)也會(huì)把新的特征給加上,這是一個(gè)新特征的場(chǎng)景。
當(dāng)然還有一些其他場(chǎng)景,比如算一些靜態(tài)特征;再比如可能線上特征有一個(gè) bug 算錯(cuò)了,但是數(shù)據(jù)已經(jīng)落到離線去了,這時(shí)候?qū)﹄x線特征要做一個(gè)糾錯(cuò),也會(huì)用到 backfill 的過(guò)程。
2.3 實(shí)時(shí)樣本拼接
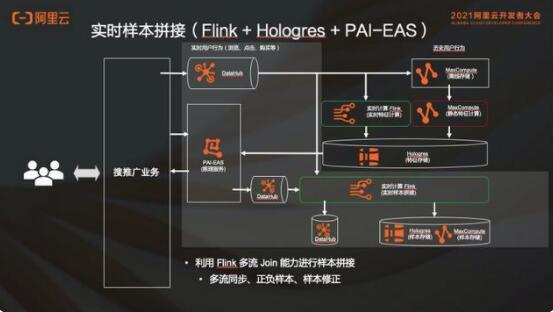
實(shí)時(shí)樣本拼接本質(zhì)上對(duì)于推薦場(chǎng)景來(lái)講,就是展示點(diǎn)擊流之后,樣本獲得一個(gè)正樣本或者負(fù)樣本。但是這個(gè) label 顯然是不夠的,還需要有特征,才能夠做訓(xùn)練。特征可以從 DataHub 中來(lái),在加入了實(shí)時(shí)特征以后,樣本的特征是時(shí)時(shí)刻刻在發(fā)生變化的。
舉一個(gè)例子,做出某一個(gè)商品的推薦行為的時(shí)候,是早上 10:00,用戶(hù)的實(shí)時(shí)特征是他 9:55 到 10:00 的瀏覽記錄。但是當(dāng)看到這個(gè)樣本流回來(lái)的時(shí)候,有可能是 10:15 的時(shí)候了。如果說(shuō)這個(gè)樣本是一個(gè)正樣本,當(dāng)給到用戶(hù)推薦的商品且他產(chǎn)生了購(gòu)買(mǎi)行為,這段時(shí)間我們是無(wú)法看到用戶(hù)實(shí)時(shí)特征的。
因?yàn)槟莻€(gè)時(shí)候的特征已經(jīng)變成了用戶(hù)從 10:10 瀏覽到 10:15 的時(shí)候的瀏覽記錄了。但是在做預(yù)測(cè)的時(shí)候,并不是根據(jù)這個(gè) 5 分鐘內(nèi)的瀏覽記錄來(lái)推薦的這個(gè)商品,所以需要把當(dāng)時(shí)做推薦的時(shí)候所采用的那些特征給它保存下來(lái),在這個(gè)樣本生成的時(shí)候給它加上,這就是 DataHub 在這里的作用。
當(dāng)使用 ES 做實(shí)時(shí)推薦的時(shí)候,需要把當(dāng)時(shí)用來(lái)做推薦的這些特征保存下來(lái),拿去做這個(gè)樣本的生成。樣本生成后,可以存儲(chǔ)到 Hologres 和 MaxCompute 里面去,把實(shí)時(shí)樣本存儲(chǔ)到 DataHub 里面。
2.4 實(shí)時(shí)深度學(xué)習(xí)和 Flink AI Flow
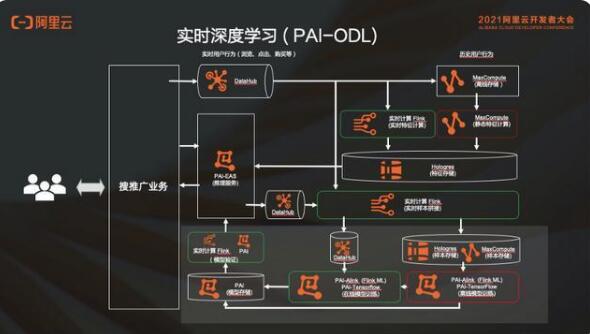
這個(gè)部分會(huì)有離線訓(xùn)練是以 “天“ 為級(jí)別的;也會(huì)有在線的實(shí)時(shí)訓(xùn)練是 “分鐘級(jí)” 的;有的可以做的比較極致,是按 “秒” 級(jí)的。不管是哪邊出來(lái)的模型,最后都會(huì)送到這個(gè)模型中去,進(jìn)行模型的驗(yàn)證以及上線。
這個(gè)其實(shí)是一個(gè)非常復(fù)雜的工作流。首先,靜態(tài)特征計(jì)算是周期性的,也可能是手動(dòng)的。當(dāng)需要做 backfill 的時(shí)候,有手動(dòng)觸發(fā)的一個(gè)過(guò)程。根據(jù)這個(gè)模型圖能看出它是批的訓(xùn)練,當(dāng)它訓(xùn)練完了之后,需要到線上去做一個(gè)實(shí)時(shí)模型驗(yàn)證。這個(gè)模型驗(yàn)證可能是一個(gè)流作業(yè),所以這里是從批到流的一個(gè)觸發(fā)過(guò)程,模型是從流作業(yè)里面出來(lái)的,它是一個(gè) long running 的作業(yè),每 5 分鐘產(chǎn)生一個(gè)模型,這每 5 分鐘的模型也需要送進(jìn)去做這個(gè)模型驗(yàn)證,所以這是一個(gè)流觸發(fā)流動(dòng)作的過(guò)程。
再比如說(shuō)這個(gè)實(shí)時(shí)樣本拼接,大家都知道 Flink 有一個(gè) watermark 的概念,比如說(shuō)到某一個(gè)時(shí)刻往前的數(shù)據(jù)都到收集齊了,可以去觸發(fā)一個(gè)批的訓(xùn)練,這個(gè)時(shí)候就會(huì)存在一個(gè)流作業(yè)。當(dāng)他到了某一個(gè)時(shí)刻,需要去觸發(fā)批訓(xùn)練的時(shí)候,這個(gè)工作流在傳統(tǒng)的工作流調(diào)度里面是做不到的,因?yàn)閭鹘y(tǒng)的工作流調(diào)度是基于一個(gè)叫做 job status change 的過(guò)程來(lái)做的,也就是作業(yè)狀態(tài)發(fā)生變化。
假設(shè)說(shuō)如果一個(gè)作業(yè)跑完了并且沒(méi)有出錯(cuò),那么這個(gè)作業(yè)所產(chǎn)生的數(shù)據(jù)就已經(jīng) ready 了,下游對(duì)這些數(shù)據(jù)有依賴(lài)的作業(yè)就可以跑了。所以簡(jiǎn)單來(lái)說(shuō),一個(gè)作業(yè)跑完了下一個(gè)作業(yè)延續(xù)上繼續(xù)跑,但是當(dāng)整個(gè)工作流里面只要有一個(gè)流作業(yè)的存在,那么這整個(gè)工作流就跑不了了,因?yàn)榱髯鳂I(yè)是跑不完的。
比如說(shuō)這個(gè)例子的實(shí)時(shí)計(jì)算,數(shù)據(jù)是不斷變化的跑動(dòng),但是也會(huì)存在隨時(shí)可能 ready 的,也就是說(shuō)可能跑到某一個(gè)程度的時(shí)候數(shù)據(jù)就 ready 了,但其實(shí)作業(yè)根本沒(méi)有跑完。所以需要引入一個(gè)工作流,這個(gè)工作流我們把它叫做 Flink AI Flow,去解決剛才那個(gè)圖里面各個(gè)作業(yè)之間的協(xié)同關(guān)系這個(gè)問(wèn)題。
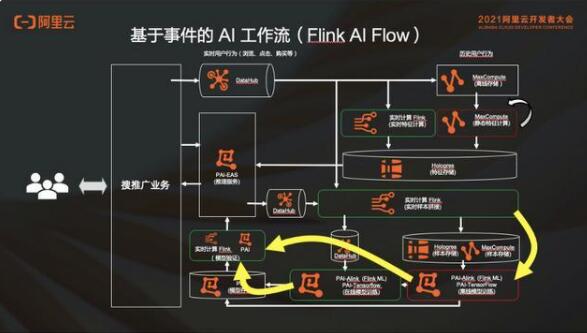
Flink AI Flow 本質(zhì)上是說(shuō)節(jié)點(diǎn)都是一個(gè) logical 的 processing unit,是一個(gè)邏輯處理節(jié)點(diǎn),節(jié)點(diǎn)和節(jié)點(diǎn)之間,不再是上一個(gè)作業(yè)跑完跑下一個(gè)作業(yè)的關(guān)系了,而是一個(gè) event driven 的 conditions,是一個(gè)事件觸發(fā)的一個(gè)概念。
同樣在工作流執(zhí)行層面,調(diào)度器也不再基于作業(yè)狀態(tài)發(fā)生變化去做調(diào)度動(dòng)作,而是基于事件的調(diào)度。比方說(shuō)事件調(diào)度這個(gè)例子,當(dāng)一個(gè)流作業(yè)的 water mark 到了的時(shí)候,就是說(shuō)這個(gè)時(shí)間點(diǎn)之前的所有數(shù)據(jù)都到全了,可以去觸發(fā)批作業(yè)去跑,并不需要流作業(yè)跑完。
對(duì)于每一個(gè)作業(yè)來(lái)講,通過(guò)調(diào)度器提作業(yè)或者停作業(yè)是需要條件的。當(dāng)這些事件滿足一個(gè)條件的時(shí)候,才會(huì)進(jìn)行調(diào)度動(dòng)作。比如說(shuō)有一個(gè)模型,當(dāng)模型生成的時(shí)候,會(huì)滿足一個(gè)條件,要求調(diào)度器把一個(gè) validation 的作業(yè)模型驗(yàn)證的作業(yè)給拉起來(lái),那這個(gè)就是由一個(gè) event 產(chǎn)生了一個(gè) condition,要求 schedule 去做一件事情的過(guò)程。
除此之外,F(xiàn)link AI Flow 除了調(diào)度的服務(wù)之外,還提供了三個(gè)額外的支持服務(wù)來(lái)滿足整個(gè) AI 工作流語(yǔ)義,分別是元數(shù)據(jù)服務(wù)、通知服務(wù)和模型中心。
元數(shù)據(jù)服,是幫大家管理數(shù)據(jù)集和整個(gè)工作流里面的一些狀態(tài);
通知服務(wù),是為了滿足基于事件調(diào)度語(yǔ)義;
模型中心,是去管理這個(gè)模型當(dāng)中的一些生命周期。
三、實(shí)時(shí)深度學(xué)習(xí)訓(xùn)練 PAI-ODL
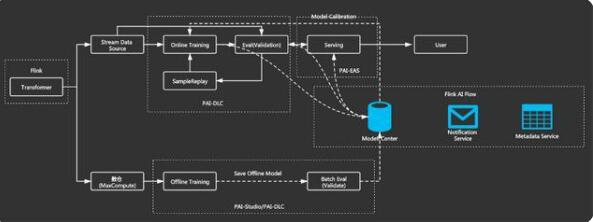
Flink 生成實(shí)時(shí)樣本之后,在 ODL 系統(tǒng)有兩個(gè)流。
第一個(gè)流是實(shí)時(shí)流,生成的實(shí)時(shí)樣本送到 stream data source 上面比如像 kafka,在 kafka 中的這個(gè)樣本會(huì)有兩個(gè)流向,一個(gè)是流到 online training 中,另一個(gè)是流到 online evaluation 。
第二個(gè)流是離線訓(xùn)練的數(shù)據(jù)流,拿離線的數(shù)據(jù)流向數(shù)倉(cāng)來(lái)做這種 offline T+1 的 training 。
在 online training 中支持用戶(hù)可配置生成模型的頻率,比如說(shuō)用戶(hù)配置 30 秒或者 1 分鐘生成一次模型更新到線上。這個(gè)滿足在實(shí)時(shí)推薦場(chǎng)景中,特別是時(shí)效性要求高的場(chǎng)景。
ODL 支持用戶(hù)設(shè)定一些指標(biāo)來(lái)自動(dòng)判斷生成的模型是否部署線上,當(dāng) evaluation 這邊達(dá)到這些指標(biāo)要求之后,這個(gè)模型會(huì)自動(dòng)推上線。因?yàn)槟P蜕傻念l率非常高,通過(guò)人工去干預(yù)不太現(xiàn)實(shí)。所以需要用戶(hù)來(lái)設(shè)定指標(biāo),系統(tǒng)自動(dòng)去判斷當(dāng)指標(biāo)達(dá)到要求,模型自動(dòng)回推到線上。
離線流這邊有一條線叫 model calibration,也就是模型的校正。離線訓(xùn)練生成 T+1 的模型會(huì)對(duì)在線訓(xùn)練進(jìn)行模型的校正。
PAI-ODL 技術(shù)點(diǎn)分析
1. 超大稀疏模型訓(xùn)練
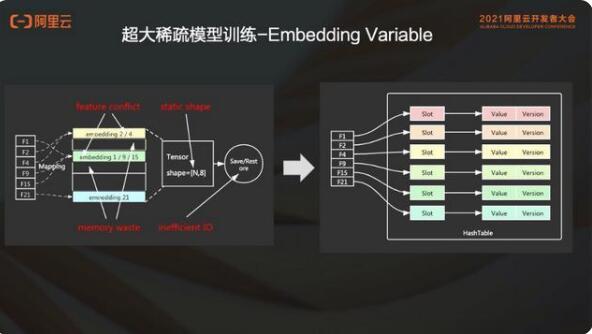
超大稀疏模型的訓(xùn)練,是推薦搜索廣告這類(lèi)稀疏場(chǎng)景里常用的一個(gè)功能。這里實(shí)際上是一個(gè)典型、傳統(tǒng)的深度學(xué)習(xí)引擎,比如像 TensorFlow,它原生的內(nèi)部實(shí)現(xiàn)的就是 fix size 這種固定 size variable,在稀疏場(chǎng)景使用中會(huì)有一些常見(jiàn)問(wèn)題。
就像 static shape,比如在通常的場(chǎng)景里邊,像手機(jī) APP 這種,每天都會(huì)有新用戶(hù)來(lái)加入,每天也會(huì)有新的商品,新聞和新的視頻等更新。如果是一個(gè)固定大小的 shape 的話,其實(shí)是無(wú)法表達(dá)稀疏場(chǎng)景中這種變化的語(yǔ)義的。而且這個(gè) static shape 會(huì)限制模型本身長(zhǎng)期的增量訓(xùn)練。如果說(shuō)一個(gè)模型可增量訓(xùn)練時(shí)長(zhǎng)是一兩年,那很可能之前設(shè)定的這個(gè)大小已經(jīng)遠(yuǎn)遠(yuǎn)不能滿足業(yè)務(wù)需求,有可能帶來(lái)嚴(yán)重的特征沖突,影響模型的效果。
如果在實(shí)際的模型中設(shè)置的 static shape 比較大,但是利用率很低,就會(huì)造成內(nèi)存的浪費(fèi),還有一些無(wú)效的 IO。包括生成全量模型的時(shí)候,造成磁盤(pán)的浪費(fèi)。
在 PAI-ODL 中基于 PAI-TF 引擎,PAI-TF 提供了 embedding variable 功能。這個(gè)功能提供動(dòng)態(tài)的彈性特征的能力。每個(gè)新的特征會(huì)新增加一個(gè) slot。并支持特征淘汰,比如說(shuō)下架一個(gè)商品,對(duì)應(yīng)的特征就會(huì)被刪掉。
增量模型是說(shuō)可以把一分鐘內(nèi)稀疏特征變化的部分記錄下來(lái),產(chǎn)生到這個(gè)增量模型中。增量模型記錄了稀疏的變化的特征和全量 Dense 的參數(shù)。
基于增量模型的導(dǎo)出,就可以實(shí)現(xiàn) ODL 場(chǎng)景下模型的快速更新。快速更新的增量模型是非常小的,可以做到頻繁的模型上線。
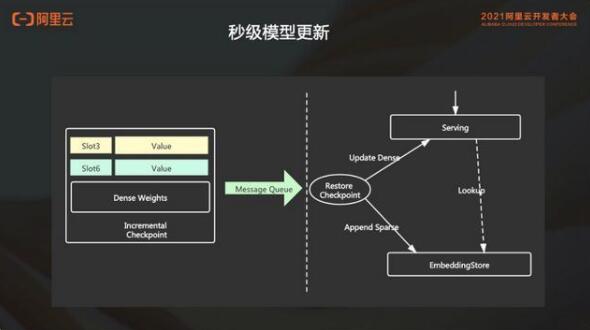
2. 支持秒級(jí)的模型熱更新
通常在我們接觸的用戶(hù)中,通常是關(guān)注的主要是三點(diǎn):
第一點(diǎn)就是模型的效果,我上線之后效果好不好?
第二點(diǎn)就是成本,我到底花多少錢(qián)。
第三點(diǎn)就是性能,能不能達(dá)到我對(duì)RT的要求。
embedding store 多級(jí)的混合存儲(chǔ)支持用戶(hù)可配置不同的存儲(chǔ)方式。可以在滿足用戶(hù)性能的前提下,更大程度的降低用戶(hù)的成本。
embedding 場(chǎng)景是非常有自己場(chǎng)景特點(diǎn)的,比如說(shuō)我們的特征存在很明顯的冷熱區(qū)別。有些商品或者視頻本身特別熱;有些則是用戶(hù)的點(diǎn)擊行為特別多,也會(huì)造成它特別熱。有些冷門(mén)的商品或者視頻就沒(méi)人點(diǎn),這是很明顯的冷熱分離,也是符合這種二八原則的。
EmbeddingStore 會(huì)把這些熱的特征存儲(chǔ)到 DRAM 上面,然后冷的特征存放在 PMEM 或者是 SSD 上。
3. 超大稀疏模型預(yù)測(cè)
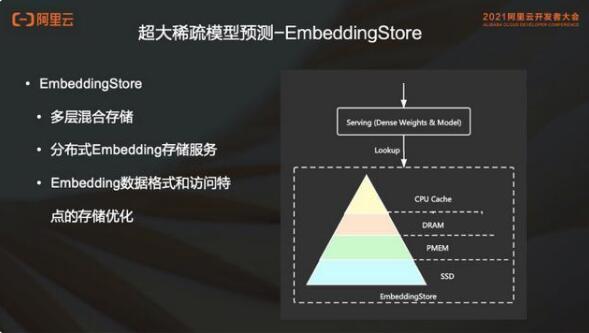
此外,EmbeddingStore 支持分布式存儲(chǔ) Service。在 serving 的時(shí)候,每個(gè) serving 的節(jié)點(diǎn)其實(shí)都需要去做一個(gè)全量的模型的加載。如果使用 EmbeddingStore 的分布式 service,就可以避免每個(gè) serving 節(jié)點(diǎn)加載全量模型。
EmbeddingStore 支持用戶(hù)可配置這種分布式的 embedding, 獨(dú)立的 isolated 這種 embedding store service。每個(gè) serving 節(jié)點(diǎn)查詢(xún)稀疏特征時(shí)從 EmbeddingStore Service 查詢(xún)。
EmbeddingStore 的設(shè)計(jì)充分的考慮了稀疏特征的數(shù)據(jù)格式和訪問(wèn)特點(diǎn)。舉個(gè)簡(jiǎn)單的例子:稀疏特征的 key 和 value ,key 是 int64 , value 就是一個(gè) float 數(shù)組。無(wú)論是在 serving 還是在 training,訪問(wèn)都是大批量的訪問(wèn)。此外 Inference 階段對(duì)稀疏特征的訪問(wèn)是無(wú)鎖化的只讀訪問(wèn)。這些都是促使我們?cè)O(shè)計(jì)基于 embedding 場(chǎng)景的稀疏特征存儲(chǔ)的原因。
4. 實(shí)時(shí)訓(xùn)練模型校正
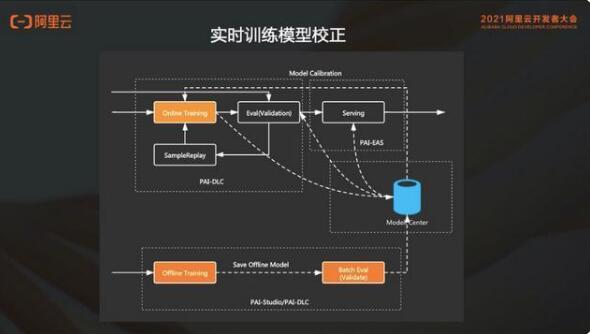
為什么 PAI-ODL 會(huì)支持離線訓(xùn)練模型對(duì) online training 有一個(gè)模型校正?
通常在實(shí)時(shí)訓(xùn)練過(guò)程中,會(huì)存在這種 label 不準(zhǔn)以及樣本分布的問(wèn)題。因此使用天級(jí)別的模型會(huì)自動(dòng)校正到 online training,增強(qiáng)模型的穩(wěn)定性。PAI-ODL 提供的模型校正用戶(hù)是無(wú)干預(yù)的,用戶(hù)基于自己業(yè)務(wù)特點(diǎn)配置相關(guān)配置后,每天自動(dòng)根據(jù)新產(chǎn)生的全量模型進(jìn)行 online training 端的 base 模型校正。當(dāng)離線訓(xùn)練生成 base 模型,online training 會(huì)自動(dòng)發(fā)現(xiàn) base model,并且在 data stream source 會(huì)自動(dòng)跳轉(zhuǎn)到對(duì)應(yīng)的樣本,基于最新的 base 模型和新的 online training 的訓(xùn)練樣本點(diǎn)開(kāi)始 online training。
5. 模型回退及樣本回放
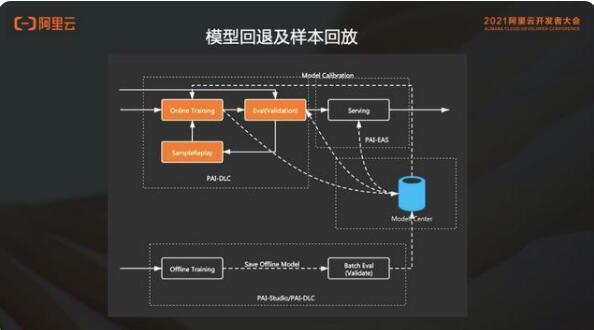
雖然有樣本的異常樣本檢測(cè)以及異常樣本處理,仍然無(wú)法避免線上的更新模型會(huì)有效果問(wèn)題。
當(dāng)用戶(hù)收到報(bào)警,線上的指標(biāo)下降。需要提供給用戶(hù)一個(gè)能力,可以回滾這個(gè)模型。
但是在 online training 的場(chǎng)景中,從發(fā)現(xiàn)問(wèn)題到去干預(yù)可能經(jīng)過(guò)了好幾個(gè)模型的迭代,產(chǎn)出了若干模型了。此時(shí)的回滾包含:
1)線上 serving 的模型回滾到問(wèn)題時(shí)間點(diǎn)的前一個(gè)模型;
2)同時(shí) online training 需要回跳到問(wèn)題模型的前一個(gè)模型;
3)樣本也要回跳到那個(gè)時(shí)間點(diǎn)來(lái)重新開(kāi)始進(jìn)行訓(xùn)練。