













GitHub Copilot抄襲實錘!GitHub:我們的AI沒有「背誦」代碼
GitHub Copilot憑借著自動生成代碼這個強有力的噱頭,推出之后就成為了討論的焦點。
Copilot建立在OpenAI全新的Codex算法之上,其中Codex接受了從GitHub中提取的TB級公開代碼以及英語語言示例的訓練。
因此,GitHub聲稱Copilot可以做到分析文檔中的字符串、注釋、函數名稱以及代碼本身,從而生成新的匹配代碼,包括之前調用的特定函數。
同時,Copilot支持多種編程語言:Python、JavaScript、TypeScript、Ruby和Go。
發布之后就有人把Copilot拉去刷Leetcode的題庫,并對這位「AI程序員」的表現十分滿意。
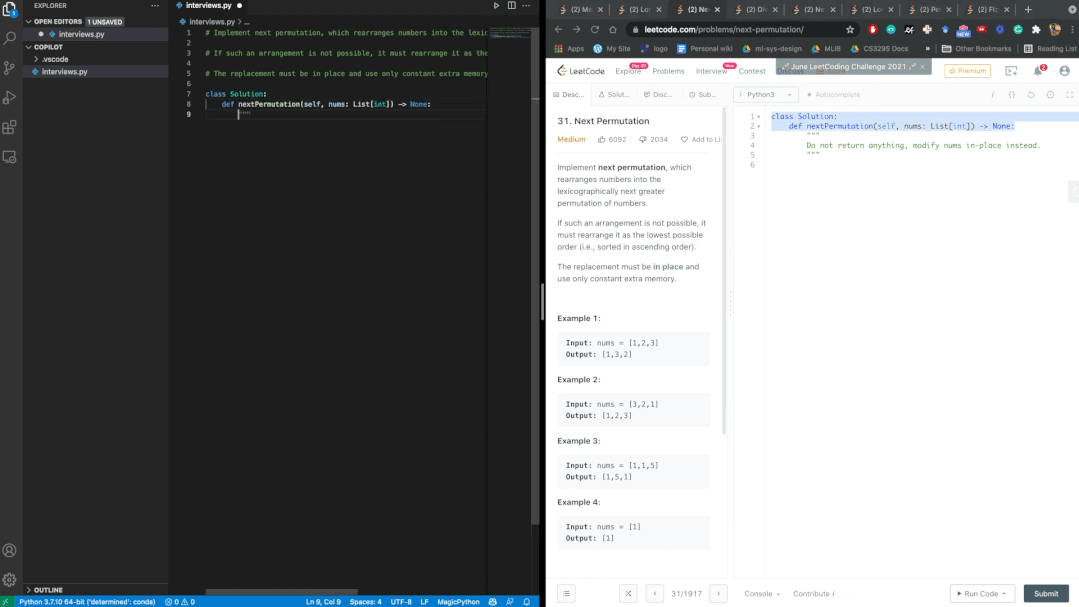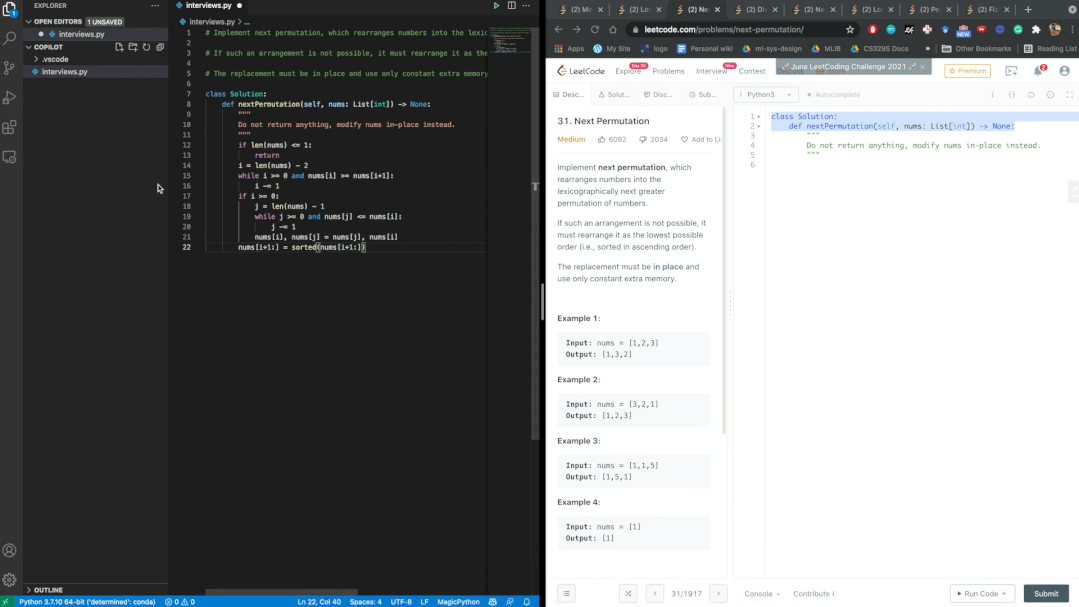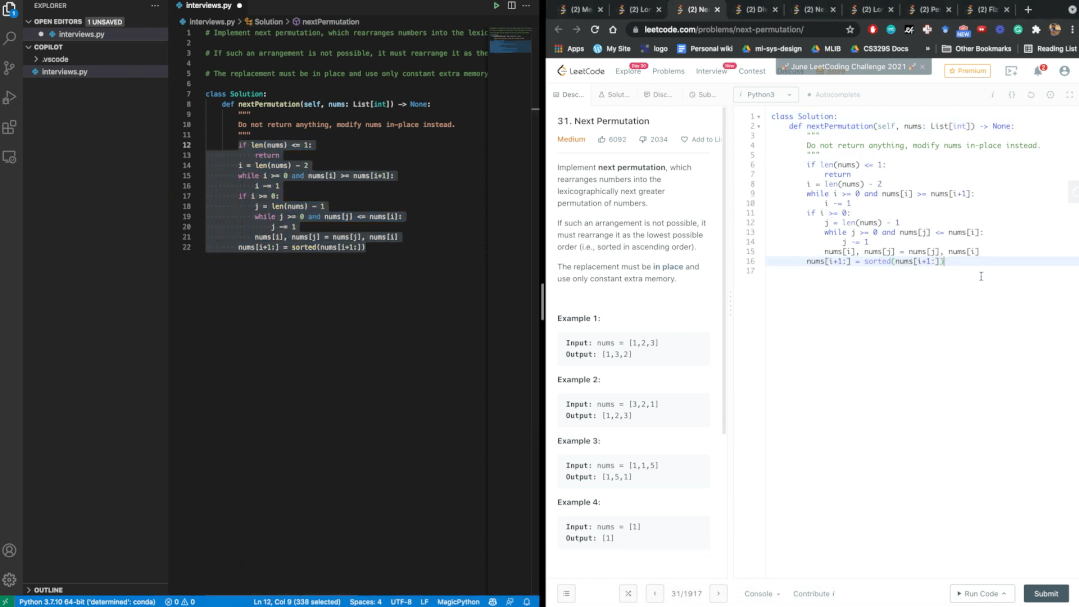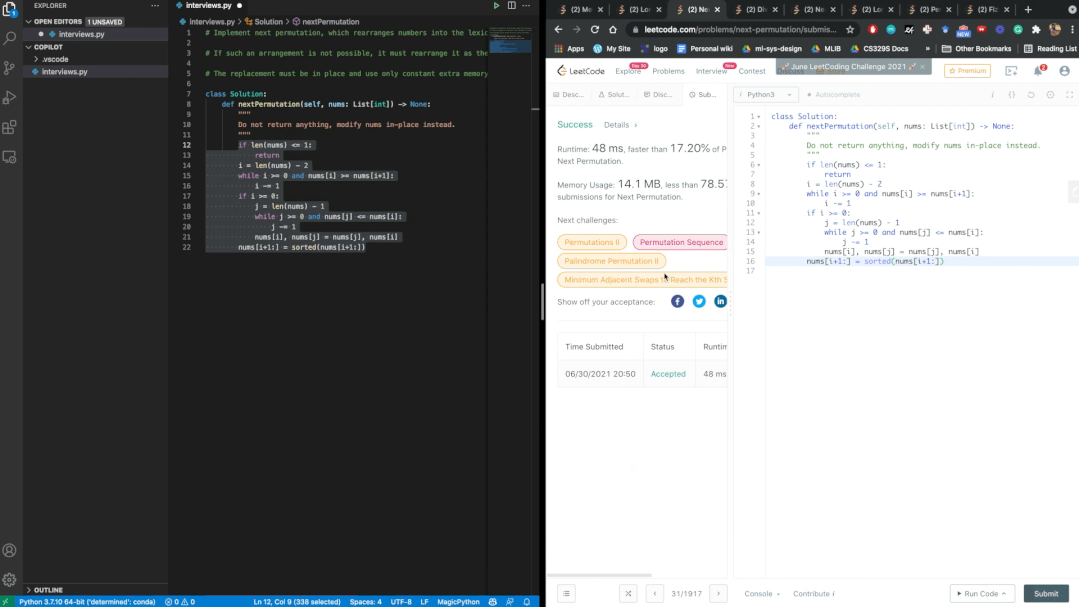
經過數個題目的驗證,Copilot每次都能通過Leetcode的測試。鑒于幾乎是實時的生成速度,博主表示,AI可能比我們更會編寫代碼。
不過網友懷疑Copilot已經在LeetCode數據庫上進行過了訓練,因為生成的注釋和Leetcode給的模板幾乎一模一樣。
針對這點,GitHub表示,雖然可能有0.1%的直接引用,但是Copilot生成的代碼大部分都會是原創的。
「復制-粘貼」成實錘
在發布的第二天,就有網友質疑GitHub Copilot是把免費開源的代碼清洗之后,搖身一變成了賺錢的工具。
而這些代碼本應該受到GPL(通用公共許可證)的保護,從而防止它們被用在商業項目中。
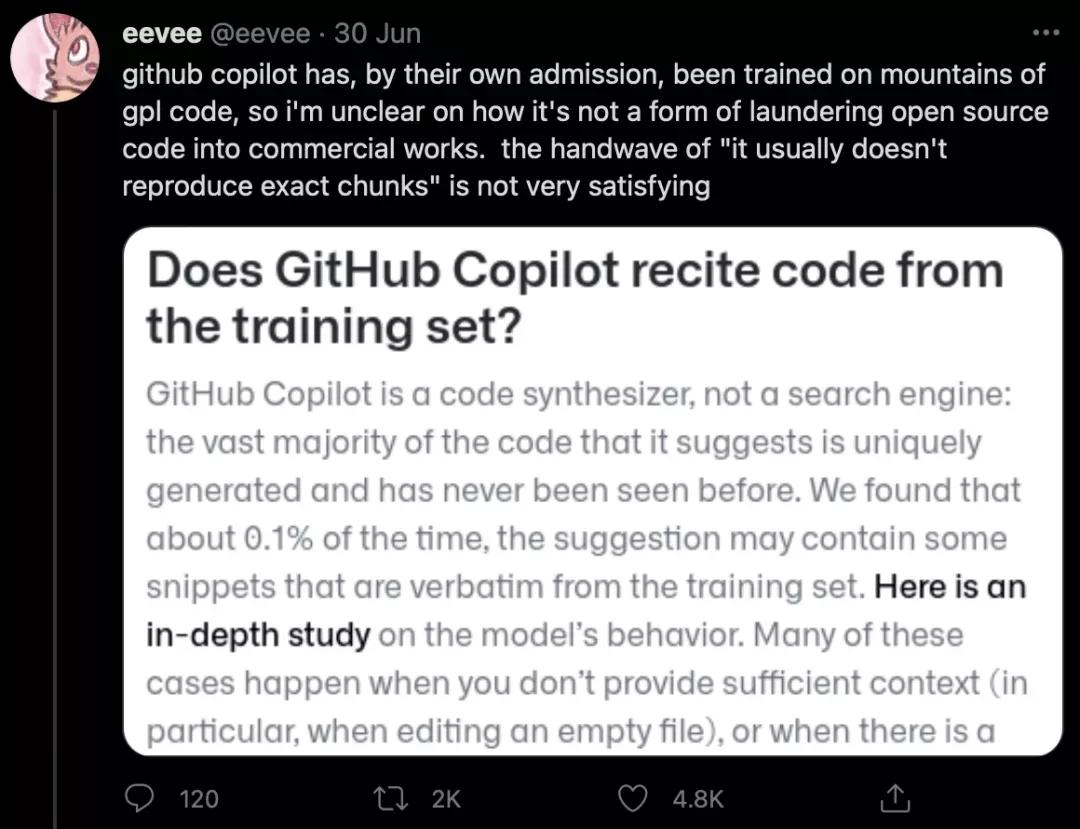
不出所料,這個懷疑沒過兩天就變成了實錘,有網友發現,Copilot直接「復制-粘貼」了最有名的「平方根倒數速算法」。
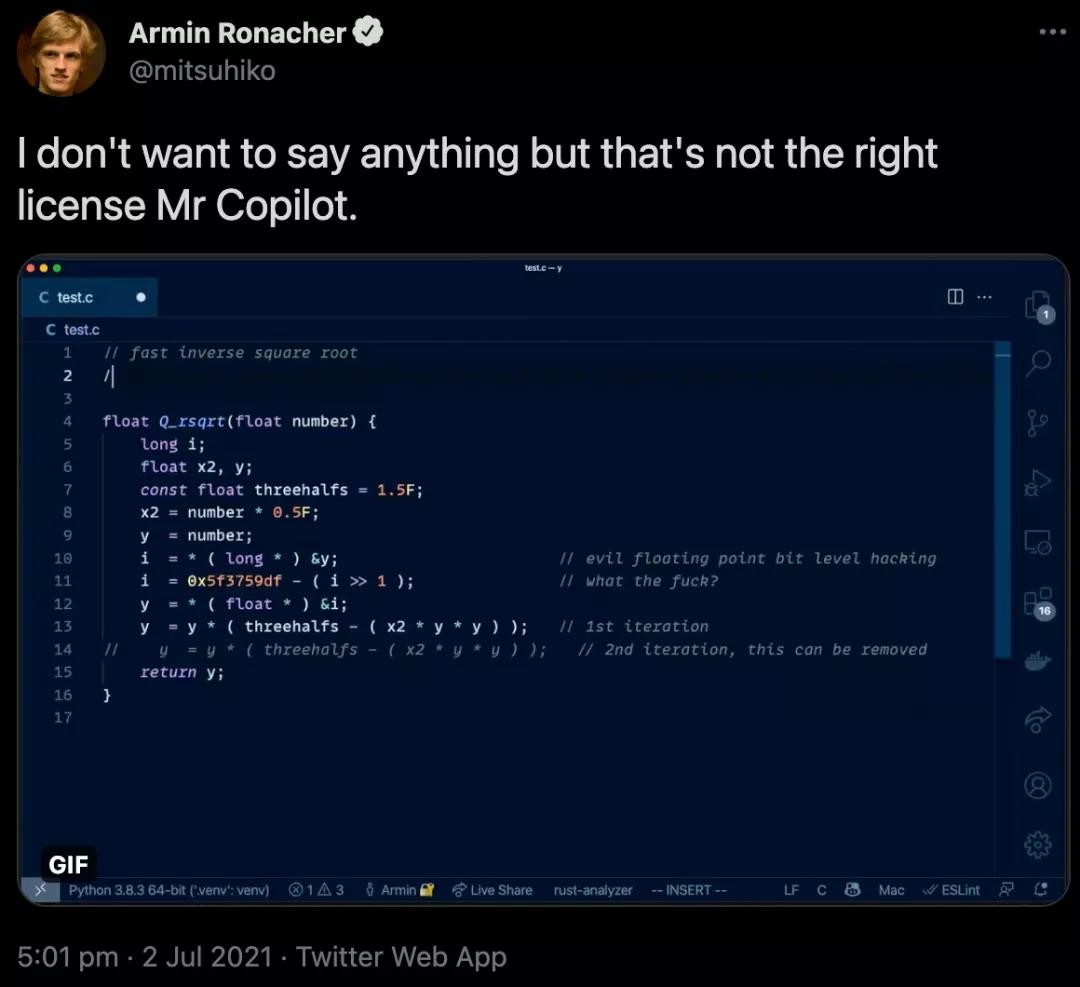
Copilot「生成」的這段代碼不僅用到了至今都沒有人能理解的magic number:0x5f3759df,同時還包含了對這段代碼的吐槽:what the f***?。

源代碼
這么看來,Copilot做的只是把訓練集中別人寫好的代碼重新組裝了一下而已。
我們的AI不「背誦」代碼
不過GitHub方面似乎早就已經做了應對的準備,一位名叫Albert Ziegler的團隊成員表示,截止2021年5月7日,他把Copilot對于Python的453780條建議都進行了收集,其中這些數據來自于300名員工在日常工作中的使用。
Albert針對這個數據集進行了分析整理,并寫了一篇看似十分完備的博客進行討論。
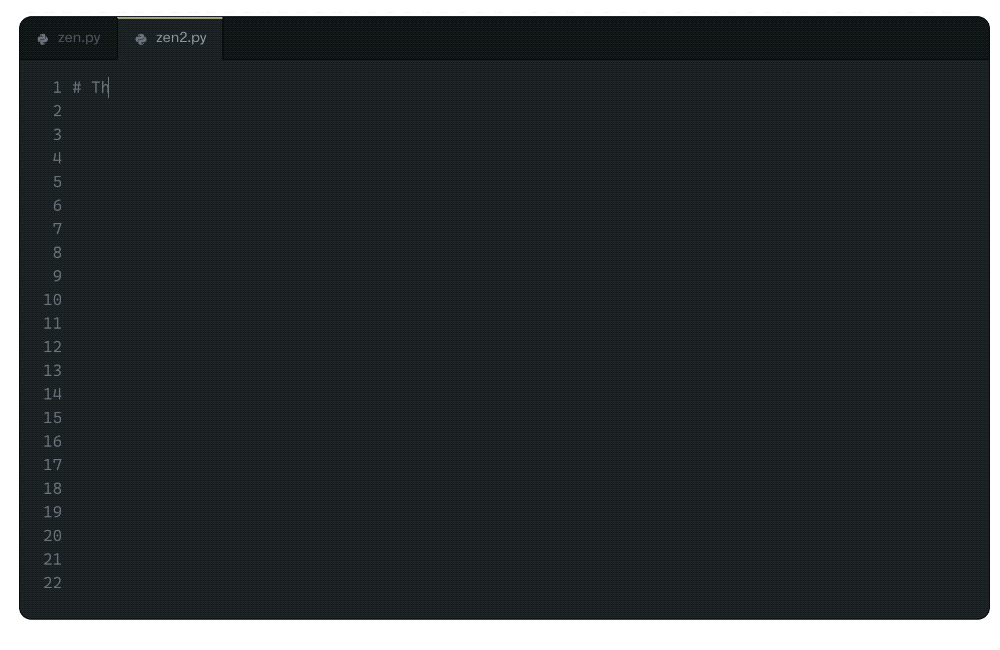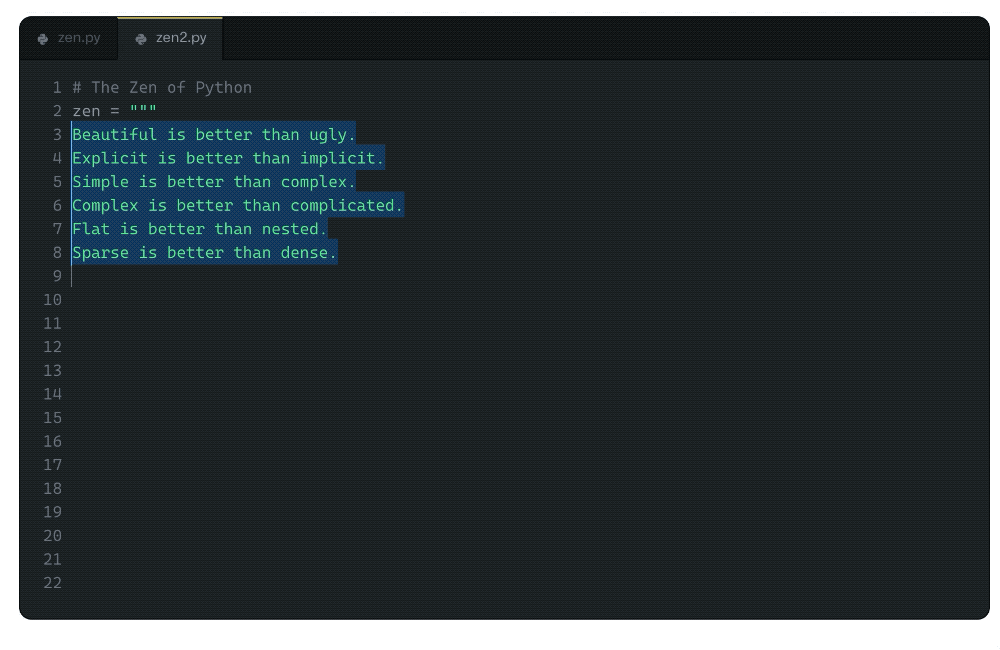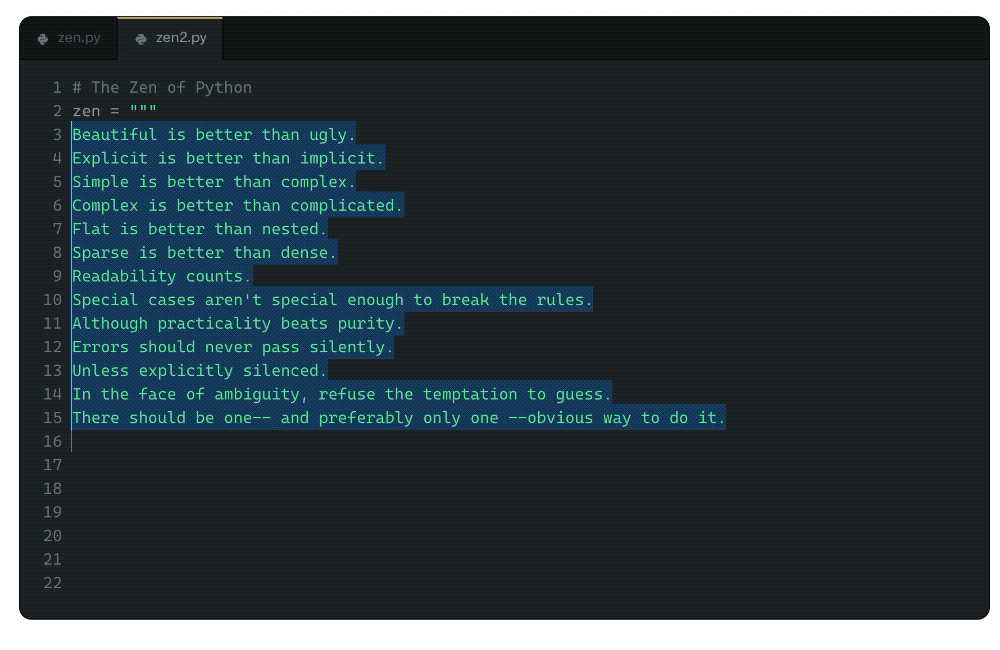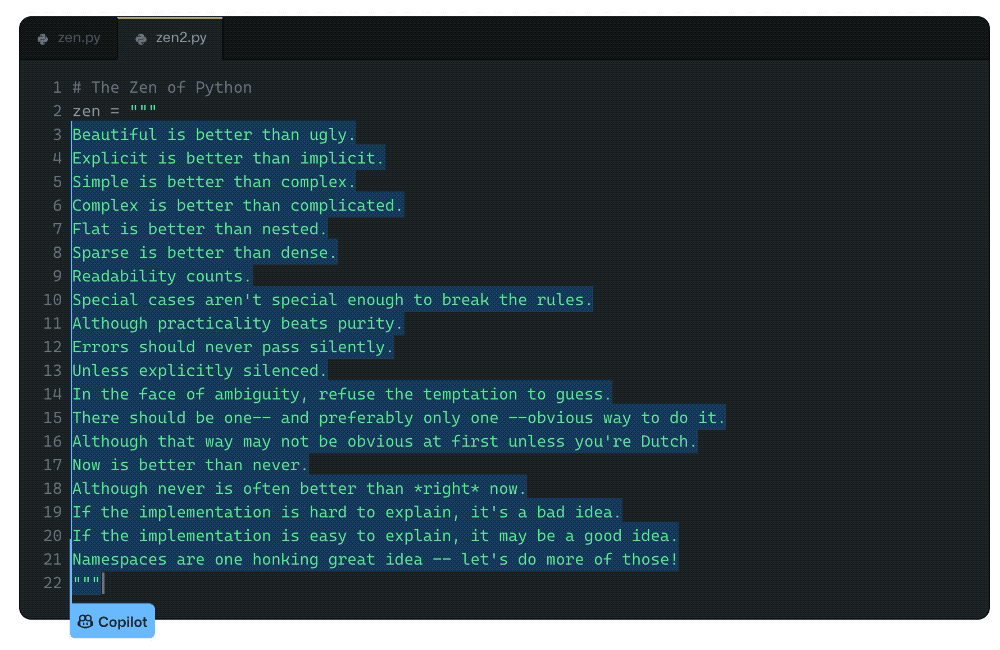
在文章的一開始,Albert便讓GitHub Copilot背誦了一篇眾所周知的文章,顯然,Copilot已經牢牢記住了文章的內容。
不過Albert認為,記住訓練集的內容不是什么問題,畢竟他自己也背誦過詩歌,而這并不會使他在日常的交流中被這些背誦的內容帶跑偏。
案例分類
類別1:Copilot有時會在某個被采納的建議之后,由于程序員新編寫的注釋,又提出了一個非常相似的建議。
Albert認為第二次只不過是重復了之前「成功」的案例,因此把它們從問題分析中刪除了出去。
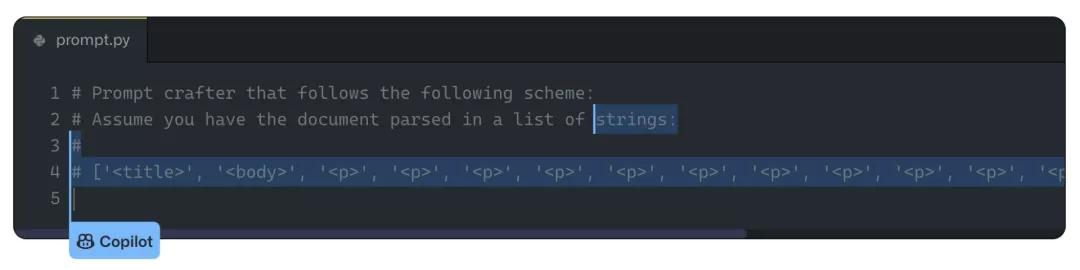
類別2:Copilot可能會提出長的、重復的序列。比如下面這個例子,其中重復的'<p>'最后在訓練集中被發現了。
類別3:Copilot給出比如自然數、素數、希臘字母表這種類似于標準清單的建議。有些建議可能是有幫助的,也可能是沒有幫助的。
不過Albert表示,這些并不符合他對「背誦」代碼的假設。
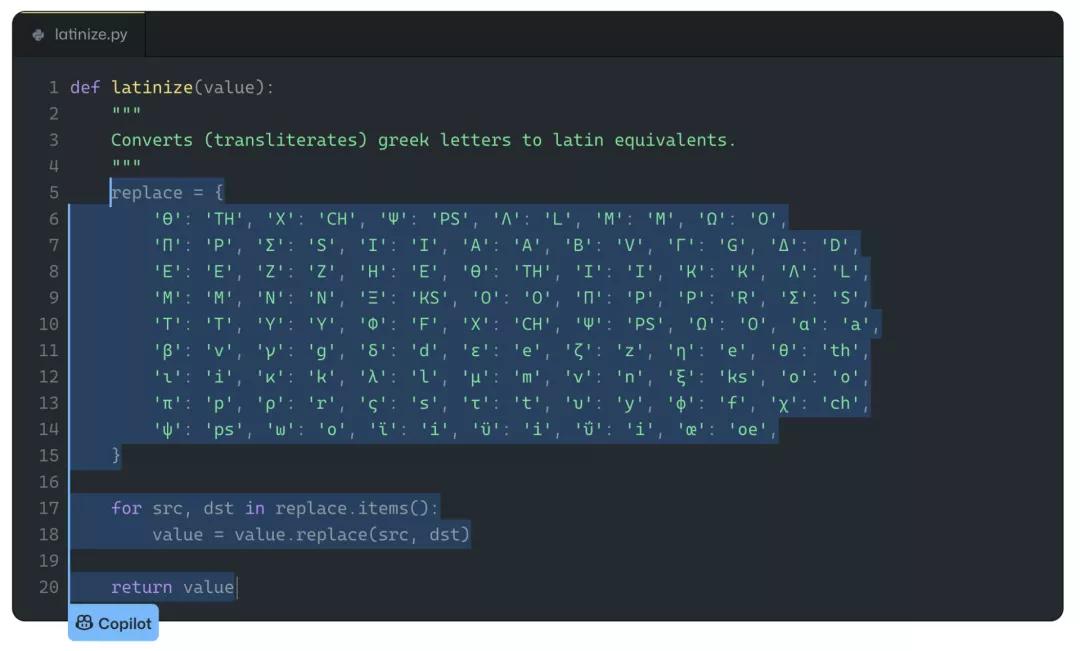
類別4:在做一些自由度很低的任務時,Copilot會給出的一些常見、或者普遍的解決方案。
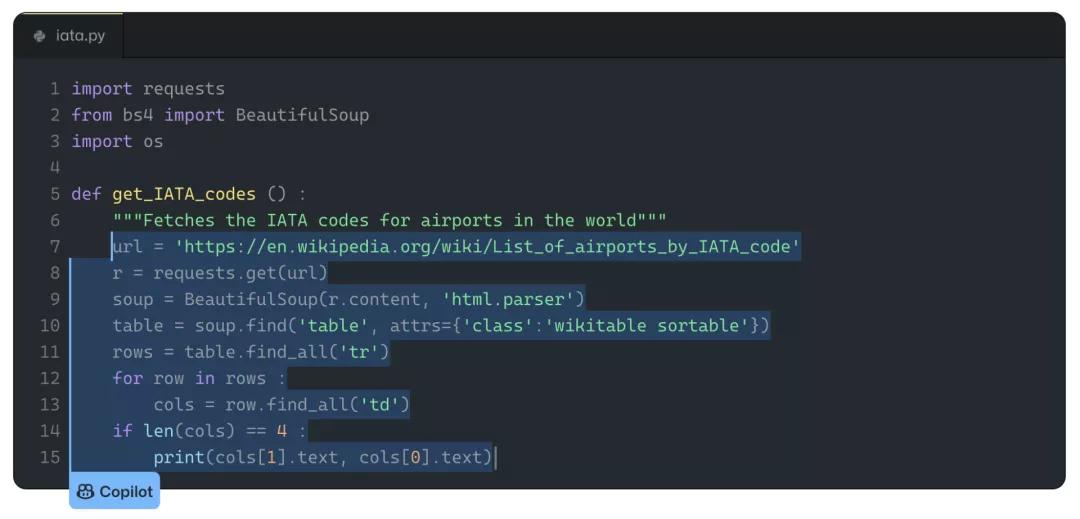
例如,下面的中間部分可以算做是使用BeautifulSoup包來解析維基百科列表的標準方法。
Albert表示,在訓練數據中發現的最佳匹配片段就是使用這樣的代碼來解析不同文章的。同樣,這不符合他對「背誦」代碼的定義。
類別5:最后這些案例符合Albert對「背誦代碼」的設想,其中,這些代碼或注釋中至少有一些具體的重疊。
測試結果
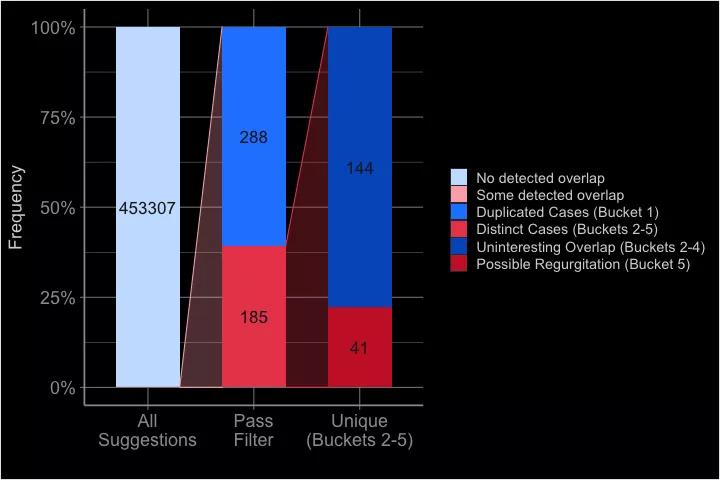
對于GitHub Copilot的大部分建議,Albert表示并沒有發現與訓練用的代碼有任何明顯的重疊。在去掉第一個類別后,可以得到了185條建議。
在這些案例中,有144個被分到了第2-4個類別中。這就在最后一個類別5里留下了41個案例,作者表示,這就是他心目中的代碼 「背誦」。
GitHub Copilot在缺乏具體語境時的引語
在人工標注時挑出的41個主要案例中,沒有一個出現在少于10個不同的文件中。大多數(35個案例)出現超過一百次。
有一次,GitHub Copilot建議從一個空文件開始,它在訓練期間甚至看到了超過700,000次的東西--那就是GNU通用公共許可證。
下面的圖表顯示了第5個類別的結果(每個結果底部有一個紅色標記)與第2-4個類別中的匹配文件數量。
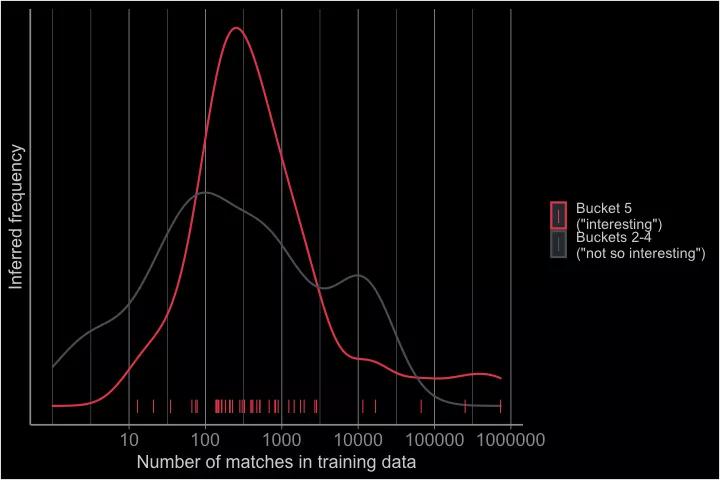
推斷出的分布圖顯示為一條紅線;它在100和1000個匹配之間達到峰值。
GitHub Copilot主要在一般情況下引證
隨著時間的推移,每個文件都變得獨一無二。但GitHub Copilot會將在你的文件非常通用時提供解決方案。
而此時,在沒有任何具體內容的情況下,它更有可能從其他地方引用。
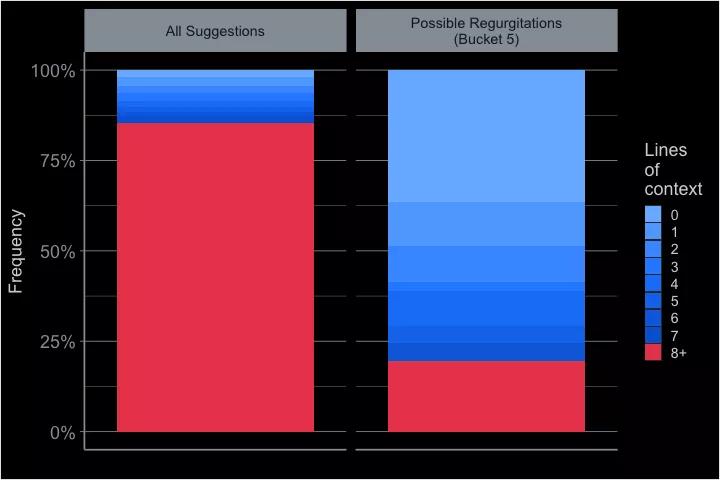
當然,軟件開發者大部分時間都在復雜的代碼中間,那里的上下文足夠獨特,GitHub Copilot會提供獨特的建議。
相比之下,一開始的建議就比較中規中矩,因為GitHub Copilot無法知道程序會是什么。
不過,在獨立的腳本中,適度的上下文就足以讓人合理地猜測出用戶想要做什么。
而有時,上下文仍然過于普遍,以至于Copilot認為它熟知的某個解決方案看起來很有希望。
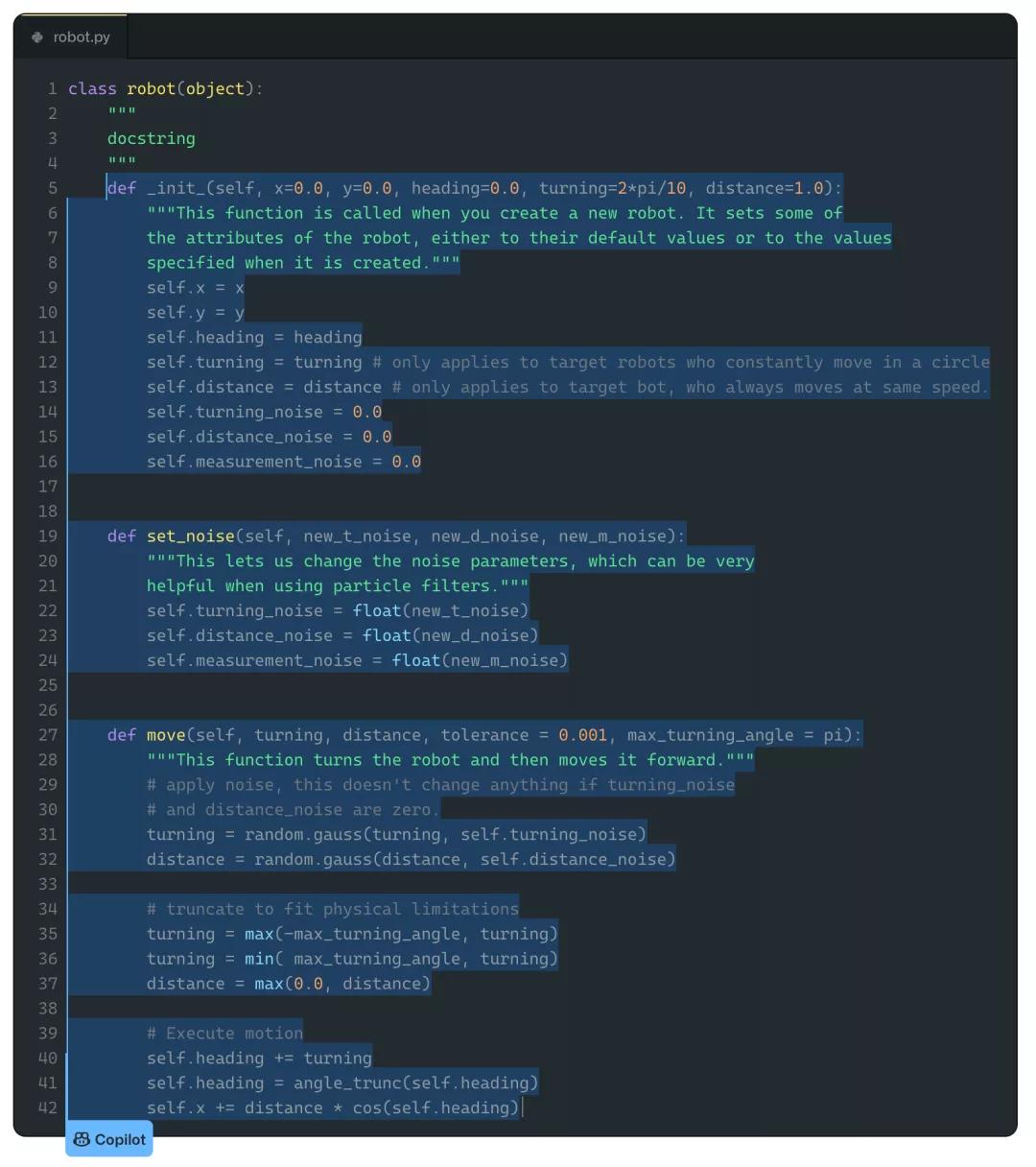
上面這個例子就是直接取自被上傳的機器人課的課件。
結論
Albert認為,雖然GitHub Copilot可以逐字逐句地引用一組代碼,但它很少這樣做,而且當它這樣做時,多數也都是所有人都會引用的代碼,而且大部分是在文件的開頭。
Albert表示,理想狀態下,當一個建議包含從訓練集復制的片段時,用戶界面應該簡單地告訴你它是從哪里引用的。然后,你可以包括適當的署名或決定不使用該代碼。而他的團隊也將努力去做到這一點。
網友評論
雖然網友在看到GitHub團隊有在關心「復制粘貼」的問題之后表示了欣慰,然而,這篇「調查」顯然很難讓人信服。
「這會導致每一個愛好者都面臨風險,同時,把『這東西可能會生成GPL的代碼?』這種擔憂推到任何一個在企業中工作的人的面前。」
「你不能僅僅依據 『嗯,它們略有不同』,從而推斷出『所以它們不是真正的相同的東西』, 如果它實質上是相似的,就需要被引用。」

對于Copilot來說,可能還有很長一段路要走。

























