20張圖帶你到HBase的世界遨游
本文轉(zhuǎn)載自微信公眾號「sowhat1412」,作者SoWhat1412 。轉(zhuǎn)載本文請聯(lián)系sowhat1412公眾號。
1 HBase 淺析
1.1 HBase 是啥
HBase 是一款面向列存儲,用于存儲處理海量數(shù)據(jù)的 NoSQL 數(shù)據(jù)庫。它的理論原型是Google 的 BigTable 論文。你可以認(rèn)為 HBase 是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統(tǒng)。
HBase 的存儲是基于HDFS的,HDFS 有著高容錯性的特點,被設(shè)計用來部署在低廉的硬件上,基于 Hadoop 意味著 HBase 與生俱來的超強的擴展性和吞吐量。
HBase 采用的時key/value的存儲方式,這意味著,即使隨著數(shù)據(jù)量的增大,也幾乎不會導(dǎo)致查詢性能的下降。HBase 又是一個面向列存儲的數(shù)據(jù)庫,當(dāng)表的字段很多時,可以把其中幾個字段獨立出來放在一部分機器上,而另外幾個字段放到另一部分機器上,充分分散了負(fù)載的壓力。如此復(fù)雜的存儲結(jié)構(gòu)和分布式的存儲方式,帶來的代價就是即便是存儲很少的數(shù)據(jù),也不會很快。
HBase 并不是足夠快,只是數(shù)據(jù)量很大的時候慢的不明顯。HBase主要用在以下兩種情況:
單表數(shù)據(jù)量超過千萬,而且并發(fā)量很大。
數(shù)據(jù)分析需求較弱,或者不需要那么實時靈活。
1.2 HBase 的由來
我們知道 Mysql 是一個關(guān)系型數(shù)據(jù)庫,學(xué)數(shù)據(jù)庫的時第一個接觸的就是 MySQL 了。但是 MySQL 的性能瓶頸是很大的,一般單個table行數(shù)不宜超過500萬行,大小不宜超過2G。
我們以互聯(lián)網(wǎng)公司最核心用戶表為例,當(dāng)數(shù)據(jù)量達到千萬甚至億級別時候,盡管你可以通過各種優(yōu)化來提速查詢,但是對單條數(shù)據(jù)的檢索耗時還是會超出你的預(yù)期!看下這個User表:
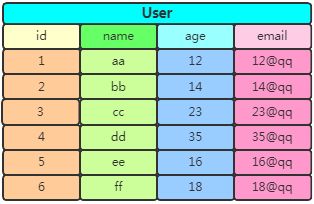
假如查詢 id=1 這條數(shù)據(jù)對應(yīng)的用戶name,系統(tǒng)會給我們返回aa。但由于MySQL是以行為位單位存儲的,當(dāng)查 name 時卻需要查詢一整行的數(shù)據(jù),連 age 和 email 也會被查出來!如果列非常多,那么查詢效率可想而知了。
我們稱列過多的表為寬表,優(yōu)化方法一般就是對列進行豎直拆分:
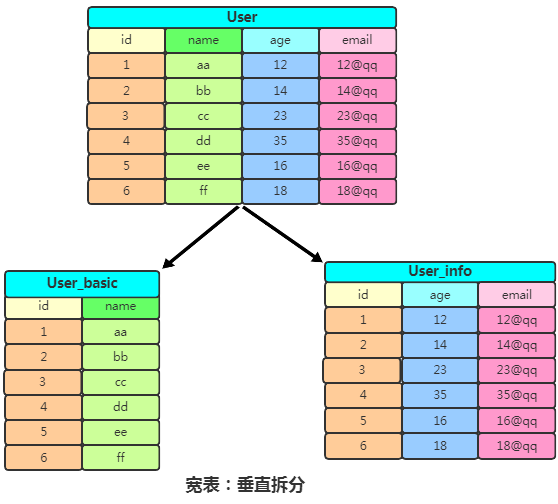
此時查找 name 時只需要查找 user_basic 表,沒有多余的字段,查詢效率就會很快。如果一張表的行過多,會影響查詢效率,我們將這樣的表稱之為高表,可以采用水平拆表的方式提高效率:
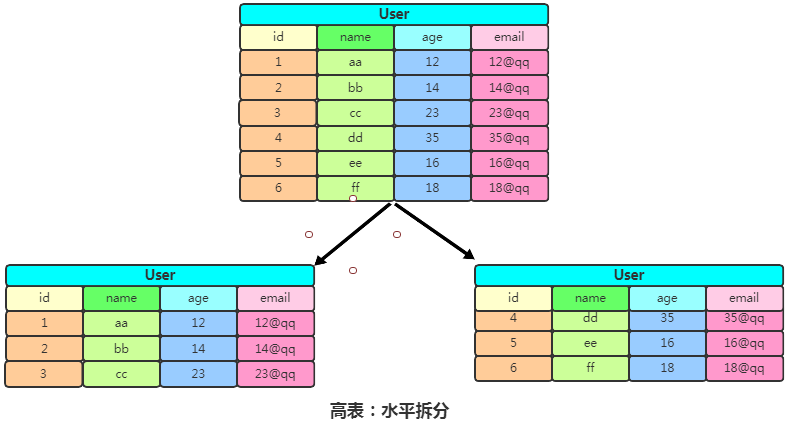
這種水平拆分應(yīng)用比較多的 場景就是日志表,日志信息每天產(chǎn)生很多,可以按月/按日進行水平拆分,這樣就實現(xiàn)了高表變矮。
上述的拆分方式貌似可以解決寬表跟高表問題,但是如果有一天公司業(yè)務(wù)變更,比如原來沒有微信,現(xiàn)在需加入用戶的微信字段。這時候需要改變表的結(jié)構(gòu)信息,該怎么辦?最簡單的想法是多加一列,像這樣:
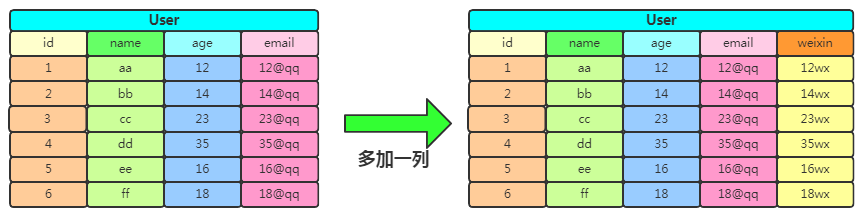
但是你要知道不是所有用戶都要微信號的,微信號這一列是設(shè)置默認(rèn)值還是采取其他的做法就得權(quán)衡一下了。如果需擴展很多列出來,但不是所有的用戶都有這些屬性,那么拓展起來就更加復(fù)雜了。這時可以用下JSON格式的字符串,將若干可選擇填寫信息匯總,而且屬性字段可以動態(tài)拓展,于是有了下邊做法:
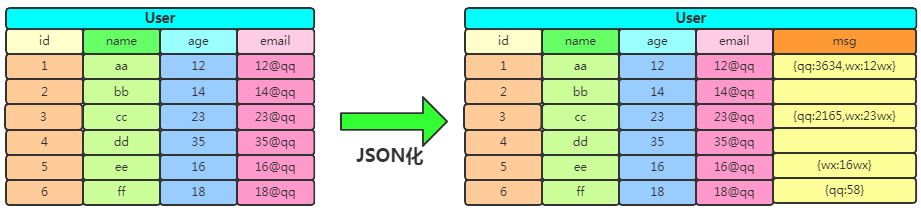
至此你可能認(rèn)為這樣存儲數(shù)據(jù)它不挺好的嘛,用 HBase 出來干嘛?Mysql 有個致命缺點,就是當(dāng)數(shù)據(jù)達到一定的閾值,無論怎么優(yōu)化,它都無法達到高性能的發(fā)揮。而大數(shù)據(jù)領(lǐng)域的數(shù)據(jù),動輒 PB 級數(shù)據(jù)量,這種存儲應(yīng)用明顯是不能很好的滿足需求的!并且針對上邊的問題,HBase 都有很好的解決方案~~。
1.3 HBase 設(shè)計思路
接著上邊說到的幾個問題:高表、寬表、數(shù)據(jù)列動態(tài)擴展,把提到的幾個解決辦法:水平切分、垂直切分、列擴展方法 雜糅在一起。
有張表,你怕它又寬又高跟動態(tài)擴展列,那么在設(shè)計之初,就把這個表給拆開,為了列的動態(tài)拓展,直接存儲JSON格式:
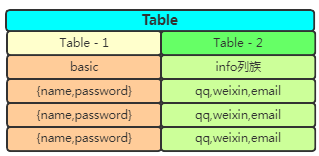
這樣就解決了寬表跟列擴展問題,高表怎么辦呢?一個表按行切分成partition,各存一部分行:
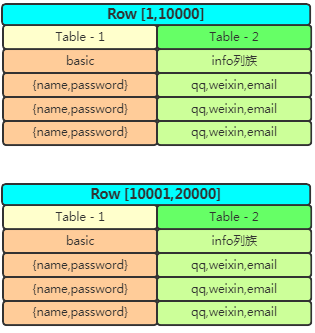
解決了高表、寬表、動態(tài)擴展列 的問題后你會發(fā)現(xiàn)數(shù)據(jù)量大了速度不夠快咋辦?用緩存唄,查詢出的數(shù)據(jù)放緩存中,下次直接從緩存拿數(shù)據(jù)。插入數(shù)據(jù)怎么辦呢?也可以這樣理解,我把要插入的數(shù)據(jù)放進緩存中,再也不用管了,直接由數(shù)據(jù)庫從緩存拿數(shù)據(jù)插入到數(shù)據(jù)庫。此時程序不需要等待數(shù)據(jù)插入成功,提高了并行工作的效率。
你用緩存的考慮服務(wù)器宕機后緩存中數(shù)據(jù)沒來得及插入到數(shù)據(jù)庫中造成丟數(shù)據(jù)咋辦?參考 Redis 的持久化策略,可以插入數(shù)據(jù)這個操作添加一個操作日志,用于持久化插入操作,宕機重啟后從日志恢復(fù)。這樣設(shè)計架構(gòu)就變成了這個樣子:
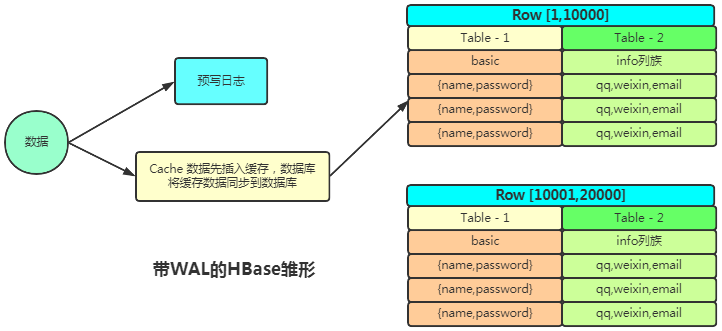
這就是 HBase 實現(xiàn)的大致思路。接下來正式進入 HBase 設(shè)計解析。
2 Hbase 簡介
Hbase 官網(wǎng):http://hbase.apache.org
2.1 HBase 特點
海量存儲
HBase適合存儲 PB 級別的海量數(shù)據(jù),能在幾十到百毫秒內(nèi)返回數(shù)據(jù)。
列式存儲
HBase是根據(jù)列族來存儲數(shù)據(jù)的。列族下面可以有非常多的列,在創(chuàng)建表的時候列族就必須指定。
高并發(fā)
在并發(fā)的情況下,HBase的單個IO延遲下降并不多,能獲得高并發(fā)、低延遲的服務(wù)。
稀疏性
HBase的列具有靈活性,在列族中,你可以指定任意多的列,在列數(shù)據(jù)為空的情況下,是不會占用存儲空間的。
極易擴展
基于 RegionServer 的擴展,通過橫向添加 RegionSever 的機器,進行水平擴展,提升 HBase 上層的處理能力,提升HBase服務(wù)更多 Region 的能力。
基于存儲的擴展(HDFS)。
2.2 HBase 邏輯結(jié)構(gòu)
邏輯思維層面 HBase的存儲模型如下:
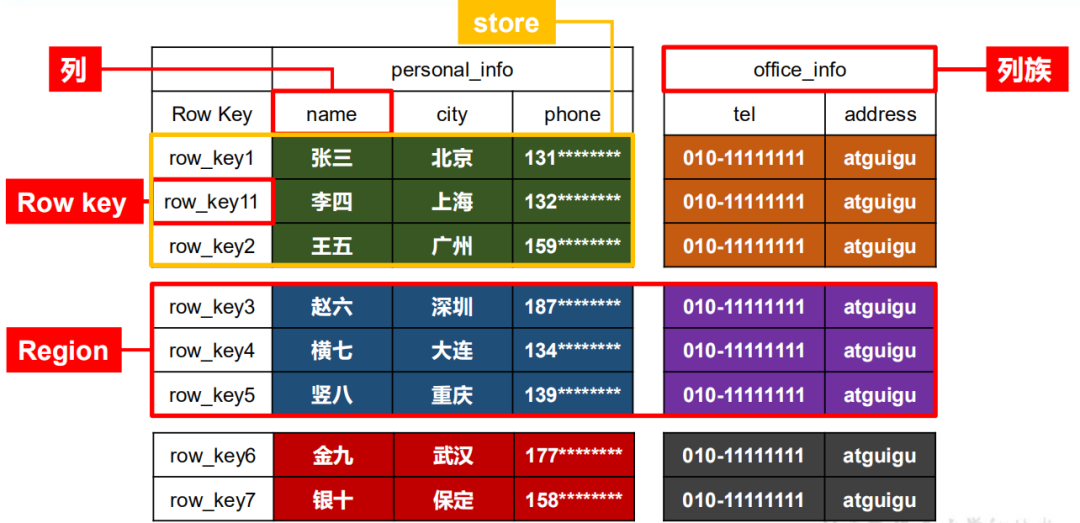
Table(表):
表由一個或者多個列族構(gòu)成。數(shù)據(jù)的屬性如name、age、TTL(超時時間)等都在列族里邊定義。定義完列族的表是個空表,只有添加了數(shù)據(jù)行以后,表才有數(shù)據(jù)。
Column (列):
HBase 中的每個列都由 Column Family(列族) 和 Column Qualifier(列限定符)進行限定,例如 info:name、info:age。建表時只需指明列族,而列限定符無需預(yù)先定義。
Column Family(列族):
多個列組合成一個列族。建表時不用創(chuàng)建列,在 HBase 中列是可增減變化的!唯一要確定的是列族,表有幾個列族在開始創(chuàng)建時就定好的。表的很多屬性,比如數(shù)據(jù)過期時間、數(shù)據(jù)塊緩存以及是否使用壓縮等都是定義在列族上的。
HBase 會把相同列族的幾個列數(shù)據(jù)盡量放在同一臺機器上。
Row(行):
一行包含多個列,這些列通過列族來分類。行中的數(shù)據(jù)所屬的列族從該表所定義的列族中選取。由于HBase是一個面向列存儲的數(shù)據(jù)庫,所以一個行中的數(shù)據(jù)可以分布在不同的服務(wù)器上。
RowKey(行鍵):
RowKey 類似 MySQL 中的主鍵,在 HBase 中 RowKey 必須有且 RowKey 是按照字典排序的,如果用戶不指定 RowKey 系統(tǒng)會自動生成不重復(fù)字符串。查詢數(shù)據(jù)時只能根據(jù) RowKey 進行檢索,所以 Table 的 RowKey 設(shè)計十分重要。
Region(區(qū)域):
Region 就是若干行數(shù)據(jù)的集合。HBase 中的 Region 會根據(jù)數(shù)據(jù)量的大小動態(tài)分裂,Region是基于HDFS實現(xiàn)的,關(guān)于Region的存取操作都是調(diào)用HDFS客戶端完成的。同一個行鍵的 Region 不會被拆分到多個 Region 服務(wù)器上。
Region 有一點像關(guān)系型數(shù)據(jù)的分區(qū),數(shù)據(jù)存放在Region中,當(dāng)然Region下面還有很多結(jié)構(gòu),確切來說數(shù)據(jù)存放在MemStore和HFile中。訪問HBase 時先去HBase 系統(tǒng)表查找定位這條記錄屬于哪個Region ,然后定位到這個Region 屬于哪個服務(wù)器,然后就到哪個服務(wù)器里面查找對應(yīng)Region 中的數(shù)據(jù)。
RegionServer:
RegionServer 就是存放Region的容器,直觀上說就是服務(wù)器上的一個服務(wù)。負(fù)責(zé)管理維護 Region。
2.3 HBase 物理存儲
以上只是一個基本的邏輯結(jié)構(gòu),底層的物理存儲結(jié)構(gòu)才是重中之重的內(nèi)容,看下圖
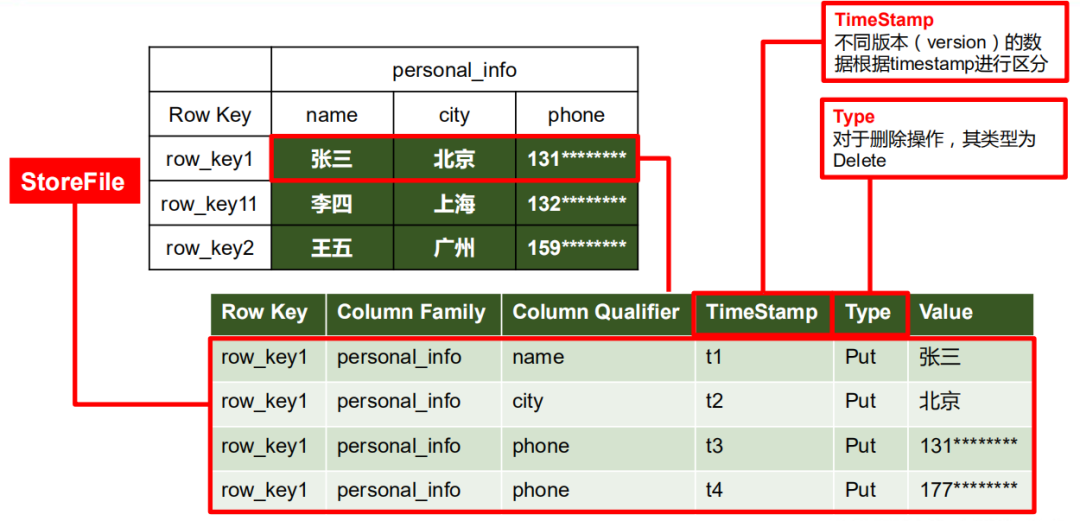
NameSpace:
命名空間,類似關(guān)系型數(shù)據(jù)庫 DatabBase 概念,每個命名空間下有多個表。HBase有兩個自帶的命名空間,分別是hbase和default,hbase 中存放的是 HBase 內(nèi)置的表,default 表是用戶默認(rèn)使用的命名空間。
TimeStamp:
時間戳,用于標(biāo)識數(shù)據(jù)的不同版本(version),每條數(shù)據(jù)寫入時如果不指定時間戳,系統(tǒng)會自動添加為其寫入 HBase 的時間。并且讀取數(shù)據(jù)的時候一般只拿出數(shù)據(jù)的Type符合,時間戳最新的數(shù)據(jù)。之所以按照Type取數(shù)據(jù)是因為HBase的底層HDFS支持增刪查,但不支持改。
Cell:
單元格,由 {rowkey, column Family:column Qualifier, time Stamp} 唯一確定的單元。cell 中的數(shù)據(jù)是沒有類型的,全部是字節(jié)碼形式存儲。
3 HBase 底層架構(gòu)
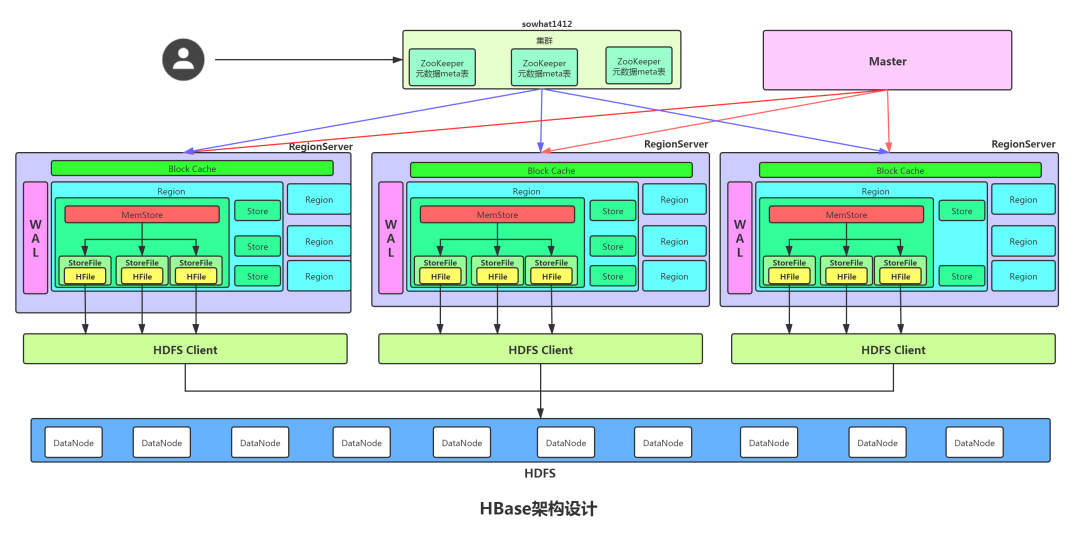
3.1 Client
Client 包含了訪問 Hbase 的接口,另外 Client 還維護了對應(yīng)的 cache 來加速 Hbase 的訪問,比如緩存元數(shù)據(jù)的信息。
3.2 Zookeeper
HBase 通過 Zookeeper 來做 Master 的高可用、RegionServer 的監(jiān)控、元數(shù)據(jù)的入口以及集群配置的維護等工作。Zookeeper 職責(zé)如下:
通過Zoopkeeper來保證集群中只有1個Master 在運行,如果Master 發(fā)生異常會通過競爭機制產(chǎn)生新的Master 來提供服務(wù)。
通過 Zoopkeeper 來監(jiān)控 RegionServer 的狀態(tài),當(dāng)RegionSevrer有異常的時候,通過回調(diào)的形式通知MasterRegionServer上下線的信息。
通過 Zoopkeeper 存儲元數(shù)據(jù) hbase:meata 的統(tǒng)一入口地址。
3.3 Master
Master 在 HBase 中的地位比其他類型的集群弱很多!數(shù)據(jù)的讀寫操作與他沒有關(guān)系,它掛了之后,集群照樣運行。但是Master 也不能宕機太久,有很多必要的操作,比如創(chuàng)建表、修改列族配置等DDL跟Region的分割與合并都需要它的操作。
- 負(fù)責(zé)啟動的時候分配Region到具體的 RegionServer。
- 發(fā)現(xiàn)失效的 Region,并將失效的 Region 分配到正常的 RegionServer 上。
- 管理HRegion服務(wù)器的負(fù)載均衡,調(diào)整HRegion分布。
- 在HRegion分裂后,負(fù)責(zé)新HRegion的分配。
HBase 中可以啟動多個Master,通過 Zookeeper 的 Master Election 機制保證總有一個 Master 運行。
3.4 RegionServer
HregionServer 直接對接用戶的讀寫請求,是真正的干活的節(jié)點。它的功能概括如下:
- 管理Master為其分配的Region。
- 處理來自客戶端的讀寫請求。
- 負(fù)責(zé)和底層HDFS的交互,存儲數(shù)據(jù)到HDFS。
- 負(fù)責(zé)Region變大以后的拆分。
- 負(fù)責(zé)StoreFile的合并工作。
ZooKeeper 會監(jiān)控 RegionServer 的上下線情況,當(dāng) ZK 發(fā)現(xiàn)某個 HRegionServer 宕機之后會通知 Master 進行失效備援。下線的 RegionServer 所負(fù)責(zé)的 Region 暫時停止對外提供服務(wù),Master 會將該 RegionServer 所負(fù)責(zé)的 Region 轉(zhuǎn)移到其他 RegionServer 上,并且會對 下線RegionServer 上存在 MemStore 中還未持久化到磁盤中的數(shù)據(jù)由 WAL重播進行恢復(fù)。
3.5 WAL
WAL (Write-Ahead-Log) 預(yù)寫日志是 HBase 的 RegionServer 在處理數(shù)據(jù)插入和刪除的過程中用來記錄操作內(nèi)容的一種日志。每次Put、Delete等一條記錄時,首先將其數(shù)據(jù)寫入到 RegionServer 對應(yīng)的HLog文件中去。只有當(dāng)WAL日志寫入成功的時候,客戶端才會被告訴提交數(shù)據(jù)成功。如果寫WAL失敗會告知客戶端提交失敗,這其實就是數(shù)據(jù)落地的過程。
WAL是保存在HDFS上的持久化文件。數(shù)據(jù)到達 Region 時先寫入WAL,然后被加載到MemStore中。這樣就算Region宕機了,操作沒來得及執(zhí)行持久化,也可以再重啟的時候從WAL加載操作并執(zhí)行。跟Redis的AOF類似。
- 在一個 RegionServer 上的所有 Region 都共享一個 HLog,一次數(shù)據(jù)的提交先寫入WAL,寫入成功后,再寫入MenStore之中。當(dāng)MenStore的值達到一定的時候,就會形成一個個StoreFile。
- WAL 默認(rèn)是開啟 的,也可以手動關(guān)閉它,這樣增刪改操作會快一點。但是這樣做犧牲的是數(shù)據(jù)的安全性。如果不想關(guān)閉WAL,又不想每次都耗費那么大的資源,每次改動都調(diào)用HDFS客戶端,可以選擇異步的方式寫入WAL(默認(rèn)間隔1秒寫入)
- 如果你學(xué)過 Hadoop 中的 Shuffle(edits文件) 機制的就可以猜測到 HBase 中的 WAL 也是一個滾動的日志數(shù)據(jù)結(jié)構(gòu),一個WAL實例包含多個WAL文件,WAL被觸發(fā)滾動的條件如下。
- WAL的大小超過了一定的閾值。
- WAL文件所在的HDFS文件塊快要滿了。
- WAL歸檔和刪除。
3.5 Region
每一個 Region 都有起始 RowKey 和結(jié)束 RowKey,代表了存儲的Row的范圍。從大圖中可知一個Region有多個Store,一個Store就是對應(yīng)一個列族的數(shù)據(jù),Store 由 MemStore 和 HFile 組成的。
3.6 Store
Store 由 MemStore 跟 HFile 兩個重要的部分。
3.6.1 MemStore
每個 Store 都有一個 MemStore 實例,數(shù)據(jù)寫入到 WAL 之后就會被放入 MemStore 中。MemStore是內(nèi)存的存儲對象,當(dāng) MemStore 的大小達到一個閥值(默認(rèn)64MB)時,MemStore 會被 flush到文件,即生成一個快照。目前HBase 會有一個線程來負(fù)責(zé)MemStore 的flush操作。
3.6.2 StoreFile
MemStore 內(nèi)存中的數(shù)據(jù)寫到文件后就是StoreFile,StoreFile底層是以 HFile 的格式保存。HBase以Store的大小來判斷是否需要切分Region。
3.6.3 HFile
在Store中有多個HFile,每次刷寫都會形成一個HFile文件落盤在HDFS上。HFile文件也會動態(tài)合并,它是數(shù)據(jù)存儲的實體。
這里提出一點疑問:操作到達Region時,數(shù)據(jù)進入HFile之前就已經(jīng)被持久化到WAL了,而WAL就是在HDFS上的,為什么還要從WAL加載到MemStore中,再刷寫成HFile呢?
由于HDFS支持文件創(chuàng)建、追加、刪除,但不能修改!但對數(shù)據(jù)庫來說,數(shù)據(jù)的順序非常重要!
第一次WAL的持久化是為了保證數(shù)據(jù)的安全性,無序的。
再讀取到MemStore中,是為了排序后存儲。
所以MemStore的意義在于維持?jǐn)?shù)據(jù)按照RowKey的字典序排列,而不是做一個緩存提高寫入效率。
3.7 HDFS
HDFS 為 HBase 提供最終的底層數(shù)據(jù)存儲服務(wù),HBase 底層用HFile格式 (跟hadoop底層的數(shù)據(jù)存儲格式類似) 將數(shù)據(jù)存儲到HDFS中,同時為HBase提供高可用(Hlog存儲在HDFS)的支持,具體功能概括如下:
提供元數(shù)據(jù)和表數(shù)據(jù)的底層分布式存儲服務(wù)
數(shù)據(jù)多副本,保證的高可靠和高可用性
4 HBase 讀寫
在HBase集群中如果我們做 DML 操作是不需要關(guān)心 HMaster 的,只需要從 ZooKeeper 中獲得hbase:meta 數(shù)據(jù)地址,然后從RegionServer中增刪查數(shù)據(jù)即可。
4.1 HBase 寫流程
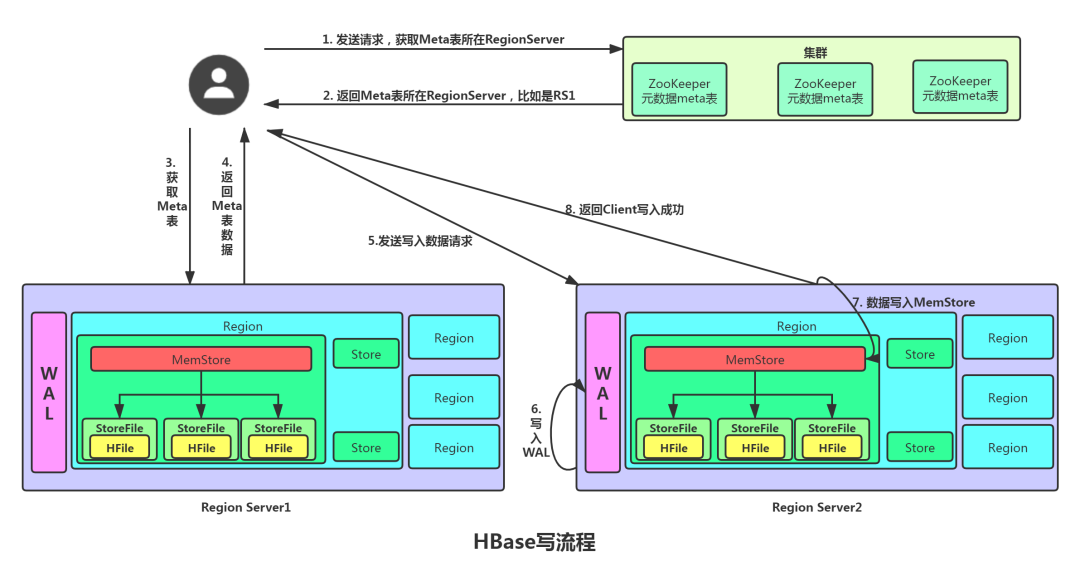
- Client 先訪問 zookeeper,訪問 /hbase/meta-region-server 獲取 hbase:meta 表位于哪個 Region Server。
- 訪問對應(yīng)的 Region Server,獲取 hbase:meta 表,根據(jù)讀請求的 namespace:table/rowkey,查詢出目標(biāo)數(shù)據(jù)位于哪個 Region Server 中的哪個 Region 中。并將該 table 的 Region 信息以及 meta 表的位置信息緩存在客戶端的 meta cache,方便下次訪問。
- 與目標(biāo) Region Server 進行通訊。
- 將數(shù)據(jù)順序?qū)懭?追加)到 WAL。
- 將數(shù)據(jù)寫入對應(yīng)的 MemStore,數(shù)據(jù)會在 MemStore 進行排序。
- 向客戶端發(fā)送 ack,此處可看到數(shù)據(jù)不是必須落盤的。
- 等達到 MemStore 的刷寫時機后,將數(shù)據(jù)刷寫到 HFile
- 在web頁面查看的時候會隨機的給每一個Region生成一個隨機編號。
4.2 HBase 讀流程
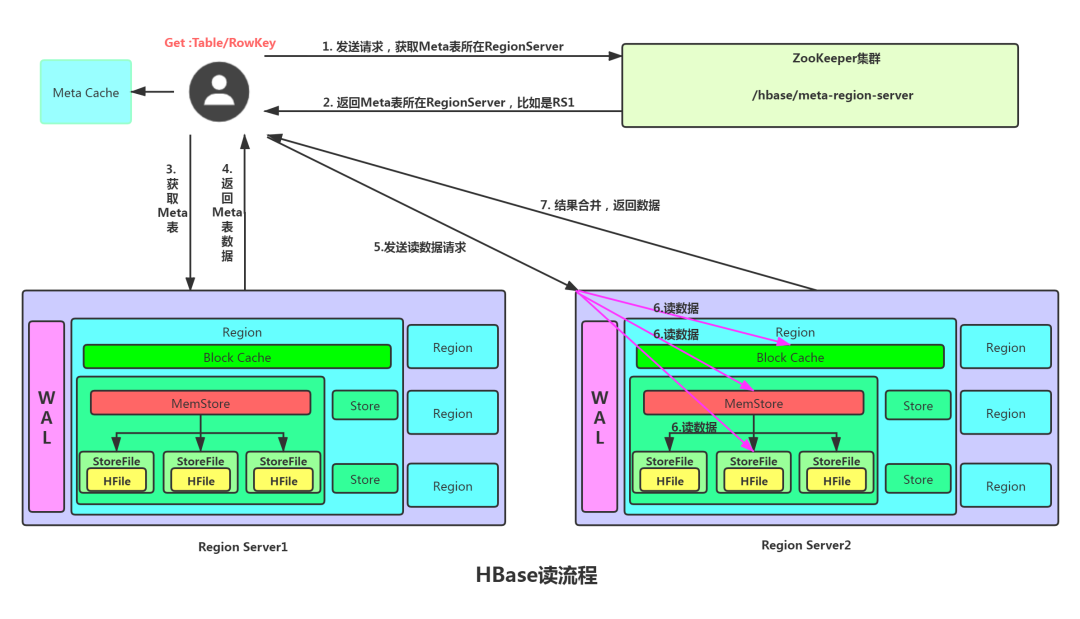
- Client 先訪問 ZooKeeper,獲取 hbase:meta 表位于哪個 Region Server。
- 訪問對應(yīng)的 Region Server,獲取 hbase:meta 表,根據(jù)讀請求的 namespace:table/rowkey, 查詢出目標(biāo)數(shù)據(jù)位于哪個 Region Server 中的哪個 Region 中。并將該 table 的 region 信息以 及 meta 表的位置信息緩存在客戶端的 meta cache,方便下次訪問。
- 與目標(biāo) Region Server 進行通訊。
- 分別在 Block Cache(讀緩存),MemStore 和 Store File(HFile)中查詢目標(biāo)數(shù)據(jù),并將 查到的所有數(shù)據(jù)進行合并。此處所有數(shù)據(jù)是指同一條數(shù)據(jù)的不同版本(time stamp)或者不同的類型(Put/Delete)。
- 將從文件HFile中查詢到的數(shù)據(jù)塊(Block,HFile 數(shù)據(jù)存儲單元,默認(rèn)大小為 64KB)緩存到 Block Cache。
- 將合并后的最終結(jié)果,然后返回時間最新的數(shù)據(jù)返回給客戶端。
4.2.1 Block Cache
HBase 在實現(xiàn)中提供了兩種緩存結(jié)構(gòu) MemStore(寫緩存) 和 BlockCache(讀緩存)。寫緩存前面說過不再重復(fù)。
HBase 會將一次文件查找的 Block塊 緩存到 Cache中,以便后續(xù)同一請求或者鄰近數(shù)據(jù)查找請求,可以直接從內(nèi)存中獲取,避免昂貴的IO操作。
BlockCache是Region Server級別的,
一個Region Server只有一個Block Cache,在 Region Server 啟動的時候完成 Block Cache 的初始化工作。
HBase對Block Cache的管理分為如下三種。
LRUBlockCache 是最初的實現(xiàn)方案,也是默認(rèn)的實現(xiàn)方案,將所有數(shù)據(jù)都放入JVM Heap中,交給JVM進行管理。
SlabCache 實現(xiàn)的是堆外內(nèi)存存儲,不再由JVM管理數(shù)據(jù)內(nèi)存。一般跟第一個組合使用,單它沒有改善 GC 弊端,引入了堆外內(nèi)存利用率低。
BucketCache 緩存淘汰不再由 JVM 管理 降低了Full GC 發(fā)生的頻率。
重點:
讀數(shù)據(jù)時不要理解為先從 MemStore 中讀取,讀不到再讀 BlockCache 中,還讀不到再從HFile中讀取,然后將數(shù)據(jù)寫入到 BlockCache 中。因為如果人為設(shè)置導(dǎo)致磁盤數(shù)據(jù)new,內(nèi)存數(shù)據(jù)old。你讀取的時候會出錯的!
結(jié)論:
HBase 把磁盤跟內(nèi)存數(shù)據(jù)一起讀,然后把磁盤數(shù)據(jù)放到 BlockCache中,BlockCache 是磁盤數(shù)據(jù)的緩存。HBase 是個讀比寫慢的工具。
4.3 HBase 為什么寫比讀快
HBase 能提供實時計算服務(wù)主要原因是由其架構(gòu)和底層的數(shù)據(jù)結(jié)構(gòu)決定的,即由LSM-Tree(Log-Structured Merge-Tree) + HTable(Region分區(qū)) + Cache決定的。
HBase 寫入速度快是因為數(shù)據(jù)并不是真的立即落盤,而是先寫入內(nèi)存,隨后異步刷入HFile。所以在客戶端看來,寫入速度很快。
HBase 存儲到內(nèi)存中的數(shù)據(jù)是有序的,內(nèi)存數(shù)據(jù)刷寫到HFile時也是有序的。并且多個有序的HFile還會進行歸并排序生成更大的有序HFile。性能測試發(fā)現(xiàn)順序讀寫磁盤速度比隨機讀寫磁盤快至少三個數(shù)量級!
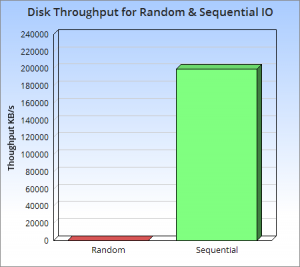
讀取速度快是因為它使用了LSM樹型結(jié)構(gòu),因為磁盤尋址耗時遠(yuǎn)遠(yuǎn)大于磁盤順序讀取的時間,HBase的架構(gòu)設(shè)計導(dǎo)致我們可以將磁盤尋址次數(shù)控制在性能允許范圍內(nèi)。
LSM 樹原理把一棵大樹拆分成N棵小樹,它首先寫入內(nèi)存中,隨著小樹越來越大,內(nèi)存中的小樹會flush到磁盤中,磁盤中的樹定期可以做merge操作來合并成一棵大樹,以優(yōu)化讀性能。
4.3.1查詢舉例
- 根據(jù)RowKey能快速找到行所在的Region,假設(shè)有10億條記錄,占空間1TB。分列成了500個Region,那讀取2G的記錄,就能找到對應(yīng)記錄。
- 數(shù)據(jù)是按照列族存儲的,假設(shè)分為3個列族,每個列族就是666M, 如果要查詢的東西在其中1個列族上,1個列族包含1個或者多個 HStoreFile,假設(shè)一個HStoreFile是128M, 該列族包含5個HStoreFile在磁盤上. 剩下的在內(nèi)存中。
- 內(nèi)存跟磁盤中數(shù)據(jù)是排好序的,你要的記錄有可能在最前面,也有可能在最后面,假設(shè)在中間,我們只需遍歷2.5個HStoreFile共300M。
- 每個HStoreFile(HFile的封裝),是以鍵值對(KV)方式存儲,只要遍歷一個個數(shù)據(jù)塊中的key的位置,并判斷符合條件可以了。一般key是有限的長度,假設(shè)KV比是1:19,最終只需要15M就可獲取的對應(yīng)的記錄,按照磁盤的訪問100M/S,只需0.15秒。加上Block Cache 會取得更高的效率。
- 大致理解讀寫思路后你會發(fā)現(xiàn)如果你在讀寫時設(shè)計的足夠巧妙當(dāng)然讀寫速度快的很咯。
5 HBase Flush
5.1 Flush
對于用戶來說數(shù)據(jù)寫到 MemStore 中就算OK,但對于底層代碼來說只有數(shù)據(jù)刷到硬盤中才算徹底搞定了!因為數(shù)據(jù)是要寫入到WAL(Hlog)中再寫入到MemStore中的,flush有如下幾個時機。
- 當(dāng) WAL 文件的數(shù)量超過設(shè)定值時 Region 會按照時間順序依次進行刷寫,直到 WAL 文件數(shù)量小于設(shè)定值。
- 當(dāng)Region Server 中 MemStore 的總大小達到堆內(nèi)存40%時,Region 會按照其所有 MemStore 的大小順序(由大到小)依次進行阻塞刷寫。直到Region Server中所有 MemStore 的總大小減小到上述值以下。當(dāng)阻塞刷寫到上個參數(shù)的0.95倍時,客戶端可以繼續(xù)寫。
- 當(dāng)某個 MemStore 的大小達到了128M時,其所在 Region 的所有 MemStore 都會阻塞刷寫。
- 到達自動刷寫的時間也會觸發(fā) MemStore 的 flush。自動刷新的時間間隔默認(rèn)1小時。
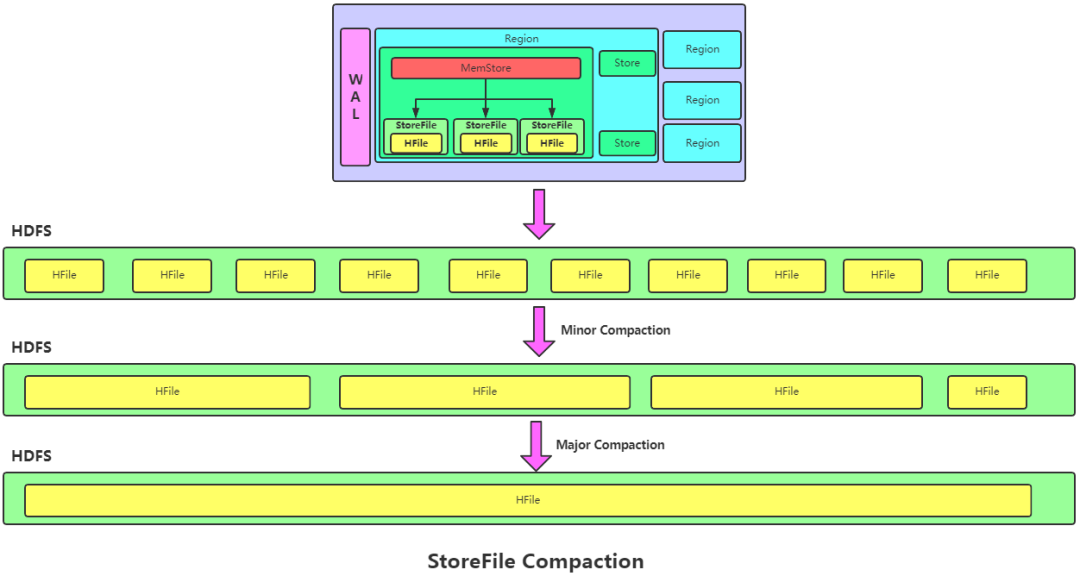
5.2 StoreFile Compaction
由于 MemStore 每次刷寫都會生成一個新的 HFile,且同一個字段的不同版本(timestamp) 和不同類型(Put/Delete)有可能會分布在不同的 HFile 中,因此查詢時需要遍歷所有的 HFile。為了減少 HFile 的個數(shù)跟清理掉過期和刪除的數(shù)據(jù),會進行 StoreFile Compaction。
Compaction 分為兩種,分別是 Minor Compaction 和 Major Compaction。
- Minor Compaction會將臨近的若干個較小的 HFile 合并成一個較大的 HFile,但不會清理過期和刪除的數(shù)據(jù)。
- Major Compaction 會將一個 Store 下的所有的 HFile 合并成一個大 HFile,并且會清理掉過期和刪除的數(shù)據(jù)。
5.3 Region Split
每個 Table 起初只有一個 Region,隨著不斷寫數(shù)據(jù) Region 會自動進行拆分。剛拆分時,兩個子 Region 都位于當(dāng)前的 Region Server,但出于負(fù)載均衡的考慮, HMaster 有可能會將某個 Region 轉(zhuǎn)移給其他的 Region Server。
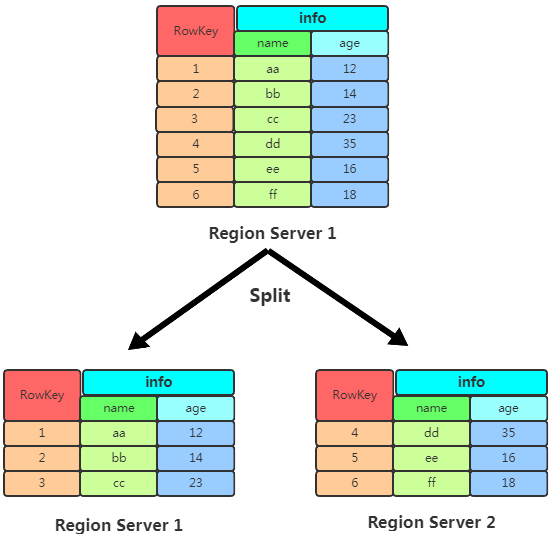
Region Split 時機:
0.94 版本之前:
- 當(dāng) 1 個 Region 中的某個 Store 下所有 StoreFile 的總大小超過 hbase.hregion.max.filesize(默認(rèn)10G), 該 Region 就會進行拆分。
0.94 版本之后:
- 當(dāng) 1 個 Region 中的某個 Store 下所有 StoreFile 的總大小超過 Min(R^2 * “hbase.hregion.memstore.flush.size=128M”,hbase.hregion.max.filesize"),該 Region 就會進行拆分,其 中 R 為當(dāng)前 Region Server 中屬于該 Table 的個數(shù)。
舉例:
- 第一次的閾值是128,切分后結(jié)果64 , 64。
- 第二次閾值512M,64,512 ⇒ 54 + 256 + 256
- 最后會形成一個 64M…10G 的這樣Region隊列,會產(chǎn)生數(shù)據(jù)傾斜問題。
- 解決方法:提前做好Region組的規(guī)劃,0-1k,1k-2k,2k-3k這樣的。
官方不建議用多個列族,比如有CF1,CF2,CF3,但是 CF1數(shù)據(jù)很多而CF2跟CF3數(shù)據(jù)很少,那么當(dāng)觸發(fā)了region切分的時候,會把CF2跟CF3分成若干小份,不利于系統(tǒng)維護。
6 HBase 常見面試題
6.1 Hbase 中 RowKey 的設(shè)計原則
RowKey 長度原則
二進制碼流RowKey 最大長度 64Kb,實際應(yīng)用中一般為 10-100bytes,以 byte[] 形式保存,一般設(shè)計定長。建議越短越好,因為HFile是按照KV存儲的Key太大浪費空間。
RowKey 散列原則
RowKey 在設(shè)計時候要盡可能的實現(xiàn)可以將數(shù)據(jù)均衡的分布在每個 RegionServer 上。
RowKey 唯一原則
RowKey 必須在設(shè)計上保證其唯一性,RowKey 是按照字典順序排序存儲的,因此設(shè)計 RowKey 時可以將將經(jīng)常讀取的數(shù)據(jù)存儲到一塊。
6.2 HBase 在大數(shù)據(jù)體系位置
其實就簡單的把HBase當(dāng)成大數(shù)據(jù)體系下的DataBase來用就行,任何可以分析HBase的引擎比如MR、Hive、Spark等框架連接上HBase都可以實現(xiàn)控制。比如你可以把Hive跟HBase進行關(guān)聯(lián),Hive中數(shù)據(jù)不再由HDFS存儲而是存儲到HBase中,并且關(guān)聯(lián)后Hive中添加數(shù)據(jù)在HBase中可看到,HBase中添加數(shù)據(jù)Hive也可看到。
6.3 HBase 優(yōu)化方法
6.3.1 減少調(diào)整
HBase中有幾個內(nèi)容會動態(tài)調(diào)整,如Region(分區(qū))、HFile。通過一些方法可以減少這些會帶來I/O開銷的調(diào)整。
Region
沒有預(yù)建分區(qū)的話,隨著Region中條數(shù)的增加,Region會進行分裂,這將增加I/O開銷,所以解決方法就是根據(jù)你的RowKey設(shè)計來進行預(yù)建分區(qū),減少Region的動態(tài)分裂。
HFile
MemStore執(zhí)行flush會生成HFile,同時HFilewe年過多時候也會進行Merge, 為了減少這樣的無謂的I/O開銷,建議估計項目數(shù)據(jù)量大小,給HFile設(shè)定一個合適的值。
6.3.2 減少啟停
數(shù)據(jù)庫事務(wù)機制就是為了更好地實現(xiàn)批量寫入,較少數(shù)據(jù)庫的開啟關(guān)閉帶來的開銷,那么HBase中也存在頻繁開啟關(guān)閉帶來的問題。
關(guān)閉 Compaction。
HBase 中自動化的Minor Compaction和Major Compaction會帶來極大的I/O開銷,為了避免這種不受控制的意外發(fā)生,建議關(guān)閉自動Compaction,在閑時進行compaction。
6.3.3 減少數(shù)據(jù)量
開啟過濾,提高查詢速度
開啟BloomFilter,BloomFilter是列族級別的過濾,在生成一個StoreFile同時會生成一個MetaBlock,用于查詢時過濾數(shù)據(jù)
使用壓縮
一般推薦使用Snappy和LZO壓縮
6.3.4 合理設(shè)計
HBase 表格中 RowKey 和 ColumnFamily 的設(shè)計是非常重要,好的設(shè)計能夠提高性能和保證數(shù)據(jù)的準(zhǔn)確性。
RowKey設(shè)計
- 散列性:散列性能夠保證相同相似的RowKey聚合,相異的RowKey分散,有利于查詢
- 簡短性:RowKey作為key的一部分存儲在HFile中,如果為了可讀性將rowKey設(shè)計得過長,那么將會增加存儲壓力.
- 唯一性:rowKey必須具備明顯的區(qū)別性。
- 業(yè)務(wù)性:具體情況具體分析。
列族的設(shè)計
- 優(yōu)勢:HBase中數(shù)據(jù)是按列進行存儲的,那么查詢某一列族的某一列時就不需要全盤掃描,只需要掃描某一列族,減少了讀I/O。
- 劣勢:多列族意味這一個Region有多個Store,一個Store就有一個MemStore,當(dāng)MemStore進行flush時,屬于同一個Region的Store中的MemStore都會進行flush,增加I/O開銷。
6.4 HBase 跟關(guān)系型數(shù)據(jù)庫區(qū)別
| 指標(biāo) | 傳統(tǒng)關(guān)系數(shù)據(jù)庫 | HBase |
|---|---|---|
| 數(shù)據(jù)類型 | 有豐富的數(shù)據(jù)類型 | 字符串 |
| 數(shù)據(jù)操作 | 豐富操作,復(fù)雜聯(lián)表查詢 | 簡單CRUD |
| 存儲模式 | 基于行存儲 | 基于列存儲 |
| 數(shù)據(jù)索引 | 復(fù)雜的多個索引 | 只有RowKey索引 |
| 數(shù)據(jù)維護 | 新覆蓋舊 | 多版本 |
| 可伸縮性 | 難實現(xiàn)橫向擴展 | 性能動態(tài)伸縮 |
6.5 HBase 批量導(dǎo)入
- 通過 HBase API進行批量寫入數(shù)據(jù)。
- 使用 Sqoop工具批量導(dǎo)數(shù)到HBase集群。
- 使用 MapReduce 批量導(dǎo)入。
- HBase BulkLoad的方式。
- HBase 通過 Hive 關(guān)聯(lián)導(dǎo)入數(shù)據(jù)。
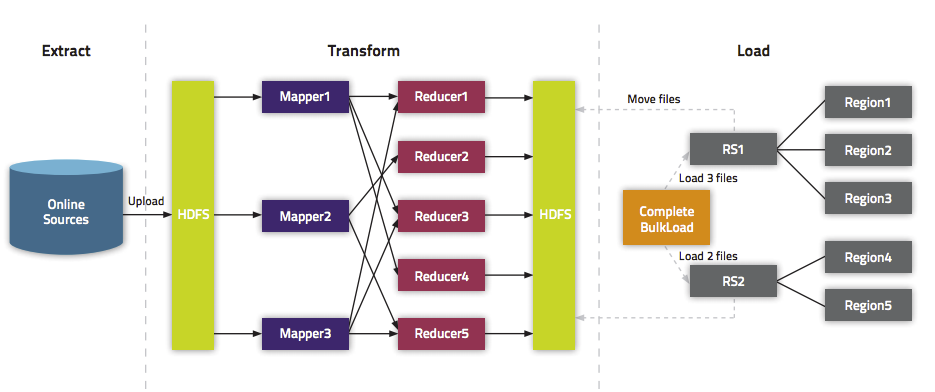
大數(shù)據(jù)導(dǎo)入用 HBase API 跟 MapReduce 寫入效率會很低,因為請求RegionServer 將數(shù)據(jù)寫入,這期間數(shù)據(jù)會先寫入 WAL 跟 MemStore,MemStore 達到閾值后會刷寫到磁盤生成 HFile文件,HFile文件過多時會發(fā)生Compaction,如果Region大小過大時也會發(fā)生Split。

BulkLoad 適合初次數(shù)據(jù)導(dǎo)入,以及HBase與Hadoop為同一集群。BulkLoad 是使用 MapReduce 直接生成 HFile 格式文件后,Region Servers 再將 HFile 文件移動到相應(yīng)的Region目錄下。
7 參考
BlockCache講解:https://blog.51cto.com/12445535/2363376?source=dra
LSM 原理:https://www.zhihu.com/question/19887265
HBase教程:http://c.biancheng.net/view/6499.html