分布式系統架構之一Master-Workers 架構
本文轉載自微信公眾號「木鳥雜記」,作者穆尼奧。轉載本文請聯系木鳥雜記公眾號。
分布式系統有很多經典的套路,也即設計模式。每個設計模式可以解決經典的一類問題,積累的多了,便可以稍加變化,進行取舍,設計出貼合需求的架構組織。但似乎大家在這方面經驗分享的不太多,因此之后打算總結一些工作和學習的經驗,既是備忘,也希望對大家有些助益。篇幅所限、能力所囿,難以面面俱到,又或疏于精確。不當之處,歡迎指正。
每篇將以概述背景、架構模塊、總結延伸來分別解析,本篇是第一篇:Master-Workers 架構。
概述
Master-Workers 架構(粗譯為主從架構)是分布式系統中常見的一種組織方式,如 GFS 中的 Master、ChunkServers;MapReduce 中的 Master、Workers。面對分布式系統中一堆分離的機器資源,主從架構是一種最自然、直白的組織方式——就像一群人,有個說了算 leader 進行組織、協調,才能最大化這群人的對外輸出能力。
這也是計算機系統中常見的一種分而治之思想的體現。即將一個復雜的系統,拆解成幾個相對高內聚、低耦合的子模塊,定義清楚其功能邊界和交互接口,使得系統易于理解、維護和擴展。對于主從架構來說,主(Master) 通常會維護集群元信息、進而依靠這些元信息進行調度,從(Workers) 通常負責具體數據切片(存儲系統)的讀寫或者作為子任務(計算系統)的執行單元。
架構模塊
主從架構系統,通常由單個 Master ,多個 Worker 組成。插一句,這里從英文翻譯沒有用 Slave 的原因是,我覺得 Worker 更中性一些。當然,單個 Master 會有性能瓶頸和可用性問題,通常也有多種解決方案,后面詳說。但單個 Master 的好處是顯而易見的:Master 作為一個控制節點,而不用處理由多副本帶來的一致性問題,大大降低實現難度。
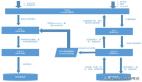
以我更熟悉一點的存儲系統架構為例,其架構圖通常長這樣。

master-workers architecture
除了系統內部的 Master 和 Worker 外,還有使用系統的外部用戶。我們通常稱之為**客戶端(Client),**Client 通過系統暴露的接口(如 RPC、HTTP)與系統進行交互。
Master
Master 通常會存儲系統的元信息,什么是元信息呢?可以理解為集群組織信息在 Master 腦中的一個倒影,或者說視圖(View):比如集群有多少 Worker、每個 Worker 有多少剩余容量、負載如何、哪些 Worker 存儲了哪些數據等等。
那元信息是怎么收集的呢?主要分兩種情況:
- 配置。可以理解為集群靜態信息,比如系統初始有多少個 Worker、Worker 的物理拓撲、每個 Worker 的容量等等,Master 會在啟動時加載這些配置信息。
- 匯報。主要是集群動態信息,Worker 在運行時,主動將自身狀態匯報給 Master,比如 Worker 是否存活、Worker 負載信息、Worker 存了哪些數據等等。在系統運行中,Worker 會定時地通過心跳(Heartbeat) 等方式,持續給 Master 匯報。
有了這些元信息,Master 就可以對整個集群情況有個掌握,從而做出一系列的決策,試舉幾例:
- 調度(Schedule)。一個新的寫數據請求來了,要分配給哪個 Worker 負責?通常會選擇一個負載小的。
- 均衡(Balance)。隨著 Worker 變動、數據增刪,數據在不同機器中分布可能不再均勻,在某些機器形成讀寫熱點、在另一些機器卻存在資源浪費,從而影響系統整體性能。因此需要實時監測,適時遷移。
- 路由(Locate/Route)。一個讀寫請求來了,不知道去找哪個 Worker?Master 便會查詢元信息,給出對應數據的 Worker 信息。
Master 的可用性
可以看出整個系統的可用性全系 Master 一身。業界也有很多解決辦法,比如:
- 使用主備。即給 Master 做個分身,備 Master 所有元信息要時刻跟主 Master 保持一致,一旦主 Master 掛掉,分身立刻跟上。Hadoop 后來這么干過。
- 使用共識算法(consensus algorithm)。簡單來說,就是由一堆 Master 機器來組成委員會,每個狀態變更都要通過某種算法達成共識。Google 的 Spanner 就是這么干的。
- 無主。系統中不再有 Master,人人平等,然后通過某種策略,比如說一致性哈希(consistent hash),來分活干。Amazon 的 Dynamo 是這么干的。
每種策略都是比較大的主題,以后可以分別單開一篇,本文限于篇幅不再展開。
Workers
在存儲系統中,Workers 會存儲實際數據,并對外提供數據 IO 服務。
從單機視角來看,Worker 需要設計一個貼合業務需求的單機引擎,高效的存儲數據。單機引擎設計也是一個很大的話題,這里簡要提一嘴:
- 索引設計:比如 B+ 樹、LSM-tree、哈希索引等等。
- 底層系統:是用裸盤還是文件系統。
- 存儲介質:使用可持久化內存、固態硬盤還是機械硬盤。
從多機視角來看,機器的數量一上去,系統中單臺機器出現故障的概率便大大提高。為了應對這種常態化的故障,需要:
運維的自動化。機器不可用后要自動剔除,修好后要便捷上線。
數據的冗余化。機器故障后數據不能丟,因此每份數據要多副本存放、使用 EC 算法做冗余。
小結
Master-Workers 架構是分布式系統中最常用的一種組織方式。該架構類似于人類社群的組織方式,將系統的職責進行拆解,Master 收集元信息,并據此進行任務調度;Workers 負責實際工作負載,需要設計高效的單機引擎,并配合全局做冗余。該架構簡單直接,但威力強大。