Kubernetes網絡技術解析之Pod基于路由模式的通信實現

前言
Kubernetes集群內,Pod之間可以通信,是Kubernetes網絡實現的重要場景之一。
Kubernetes通過CNI提供統一的接口和協議,使得我們在使用中可以根據需求自行選擇不同的網絡組件以及模式。比較常見的選型,如Flannel的VXLAN或者HostGW、Calico的IPIP或者BGP等等。
這些不同的網絡組件究竟是怎么實現Pod的通信的,底層的技術原理是什么,本篇文章就帶大家以Calico的BGP模式的通信模型(基于路由的純三層模型)為例,解析其底層的實現原理。
既然提到了容器網絡,就肯定繞不開Network Namespace。Network Namespace是實現虛擬網絡的核心技術(這里就不展開細說了,有興趣的同學可以自行了解一下Linux Namespaces),已被廣泛的運用在了容器相關的網絡場景中。一個docker創建的容器會有一個獨立的Network Namespace,一個Kubernetes的Pod里的N個容器也會共用一個獨立的Network Namespace。
那么Network Namespace之間是怎么實現通信的?
今天就來自己動手實現基于路由模式,多個可以跨主機通信的Network Namespace(網絡命名空間)。
動手創建一個Network Namespace
1、準備一臺Linux主機(node03--100.100.198.250),檢查 ip 命令是否有效(如果沒有需要安裝iproute2)
2、執行以下命令創建一個新的net-ns demo01
- ip netns add demo01 #創建demo01
- ip netns list #查看結果,返回中包含`demo01(id:xxx)`,說明創建成功
3、查看demo01下的網卡資源并開啟lo網卡
- ip netns exec demo01 ip addr #ip netns exec demo01 <需要執行的命令>可以實現對demo01的相關操作,也可以通過`ip netns exec demo01 /bin/bash`進入到demo01的虛擬網絡環境中之后,再直接通過執行命令的方式操作。操作完成需要退出至主機網絡空間,需執行exit
- ip netns exec demo01 ip link set lo up #開啟lo網卡,lo網卡自動綁定127.0.0.1
- #通過第一條命令可以看到該namespace下只有一塊lo網卡,且該網卡是關閉狀態(可以在host主機網絡空間直接執行`ip addr`觀察兩者區別)
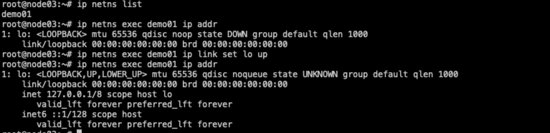
demo01-lo網卡已啟動
至此,一個新的Network Namespace demo01已經創建完成。
目前demo01只具有本地lo網卡,那該如何實現與Host主機網絡空間通信呢?
為demo01配置網卡對和路由
實現demo01與Host主機網絡空間通信,也可以理解成兩個獨立的Network Namespace之間通訊。所以我們要創建一個網卡對,且把兩端分別放在host主機網絡空間和demo01中,并啟動網卡。
- ip link add vethhost01 type veth peer name vethdemo01 #創建虛擬網卡對 ip link add <網卡名稱> type veth peer name <配對的網卡名稱>
- ip addr #查看網卡信息,可以看到host主機網絡空間下多了兩張新建的網卡
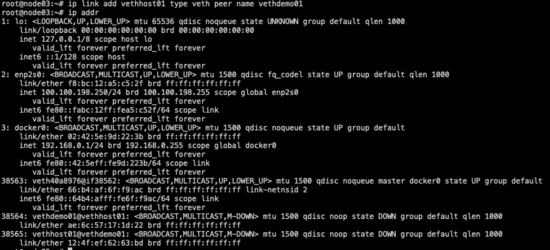
可以看到host主機網絡空間下創建的新網卡對
將網卡對的一端分配至demo01中,并將其開啟:
- ip link set vethdemo01 netns demo01 #將虛擬網卡vethdemo01分配到demo01中 ip link set <網卡名稱> netns <net-ns名稱>
- ip link set vethhost01 up #開啟host主機網絡空間端的網卡
- ip netns exec demo01 ip link set vethdemo01 up #開啟demo01端的網卡,至此兩張網卡已全部開啟,并且分別在兩個網絡命名空間下
要實現通訊,還需要給demo01的網卡一個IP地址(host主機網絡空間下的網卡vethhost01這里不需要設置IP):
- ip netns exec demo01 ip addr add 10.0.1.2/24 dev vethdemo01 #將vethdemo01的IP設置為10.0.1.2(地址可以隨便設置,只要不與主機網絡同一網段即可) 添加IP的命令格式-- `ip addr add <IP地址/子網掩碼> dev <網卡>`
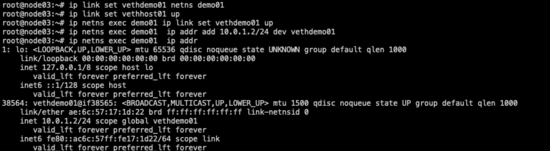
demo01-vethdemo01網卡IP已配置完成
設置好IP是不是就能實現通訊呢?比如ping通?
驗證
- 在Host主機網絡空間執行
ping 10.0.1.2,結果:并無響應,數據包全部丟失,通過mtr發現數據流向了主機的默認網關 - 在demo01反向請求
ping 100.100.198.250,結果:connect: Network is unreachable
為什么不通?
- 10.0.1.2
- 10.0.1.0/24
結論:缺少路由。
添加雙向路由
要實現能ping通,一定是雙向可達的,所以來去兩個方向都需要有路由指向才能通信。
1、在Host主機網絡空間添加通往 10.0.1.2 的路由指向,將固定IP 10.0.1.2 指向同一網絡空間下的網卡vethhost01(它的對端就是demo01的網卡)
2、在demo01添加通往 100.100.198.250 的指向,只需要添加默認路由網關指向自己的網卡vethdemo01(它的對端網卡vethhost01就在 100.100.198.252 的網絡空間下)
- route add -host 10.0.1.2 dev vethhost01 #host主機網絡空間添加-->demo01方向的路由 路由命令`route <動作-常用的add或者del> <目標地址類型-常用net或者host> <目標地址,如果是網段必須要加/子網掩碼> <下一跳的類型,網卡設備-dev、ip地址-gw> <下一條網卡名稱或者ip地址>` 這條路由的規則解讀是:當主機收到目的地址是10.0.1.2的數據包,將其轉發到本機的vethost1網卡上
- ip netns exec demo01 route add default dev vethdemo01 #demo01添加默認的路由,這條路由是為了下一條路由能生效
- ip netns exec demo01 route add -net 0.0.0.0 gw 100.100.198.250 #為了演示方便,這條路由是為了將Host主機網絡空間模擬成路由器的角色。將默認的下一跳指向100.100.198.250,讓其轉發請求。 這條路由的規則解讀是:當主機收到的數據包的目的地址在其他路由規則中匹配不到時,將默認都轉發到100.100.198.250
再次驗證,雙向已經實現互通。
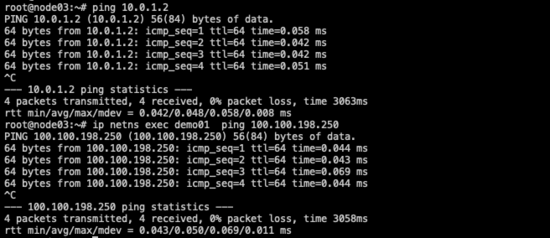
雙向互ping成功
到這里,一個可以能與Host主機網絡空間實現通信的Network Namespace就已經創建完成了。
創建demo02,實現demo01與其互通
參照demo01的步驟我們可以再創建一個Network Namespace。
- 命名為demo02
- IP地址設置為
10.0.2.2 - 添加雙向路由,實現
100.100.198.252與10.0.2.2互通
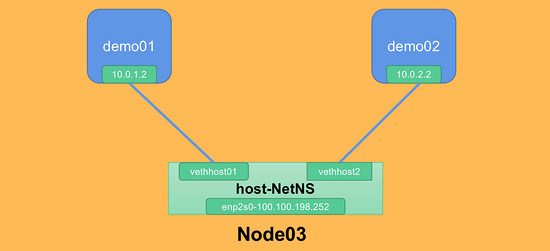
目前的網絡模型
以上都實現之后,驗證網絡聯通情況:
- 在Host主機網絡空間與demo01/02雙向互ping
- 預期結果都為通,說明demo02也順利創建完成
驗證demo01<---->demo02是否互通:
- 結果:并無響應,數據包全部丟失,通過mtr發現數據流向了主機的默認網關
100.100.198.250之后數據包就不知去向 - 現象與之前主機未添加到demo01的路由時很相似,但是目前Host主機網絡空間存在通往
10.0.1.2、10.0.2.2的路由,數據包是可以從100.100.198.250通往demo01/02的
- 唯一的不同是這次的數據包原地址是
10.0.1.2和10.0.2.2,數據包經過100.100.198.250網卡進行轉發
- 唯一的不同是這次的數據包原地址是
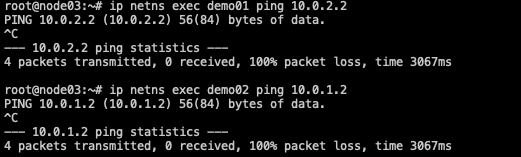
demo01/02的雙向互ping

demo01的mtr結果

demo02的mtr結果
數據包去哪了?
已經有了路由,為什么數據包沒有被Host主機網絡空間轉發?
要弄清楚報文是如何通過內核處理并最終抵達協議棧的,首先需要了解iptables對報文的處理流程。
什么是 4表5鏈 ?
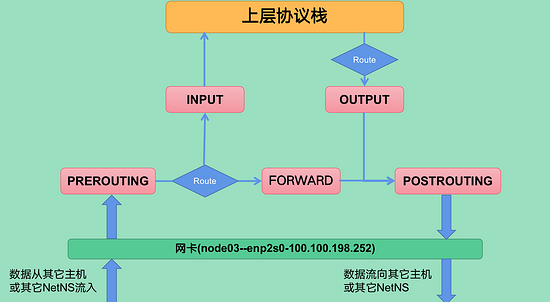
報文被內核基于iptables相關規則處理的邏輯走向
鏈
- 每一條鏈用通俗的話講就是一個
關卡(報文邏輯走向圖中的標紅部分,分別是PREROUTING、INPUT、OUTPUT、FORWARD、POSTROUTING) - 每一個
關卡里都可以配置相應的規則
- 一個
關卡上可能不止有一條規則,可能有很多條規則,把這些規則串成一個集合的時候,就形成了鏈 - 每個經過這個
關卡的報文,都要將這條鏈上的所有規則匹配一遍,如果有符合條件的規則,則執行規則對應的動作(可能被丟棄,可能被處理之后流向下游,也可能直接流向下游)
- 一個
表
- 相同功能的規則的集合叫做
表,不同功能的規則,我們可以放置在不同的表中進行管理 - 鏈中的這些規則基于功能的不同大概分為四類(過濾、網絡地址轉換、拆解報文\修改\重新封裝、關閉連接追蹤)
- filter表:負責過濾功能,防火墻。內核模塊:
iptables_filter,可以實現對報文的過濾,限制某些報文無法通行(相關使用場景:防火墻的黑名單功能,禁止某些IP不能訪問,或者限制主機對外通信) - nat表:network address translation,網絡地址轉換功能。內核模塊:
iptable_nat,可以實現對外發報文中的源、目的地址的轉換(相關使用場景:Docker的覆蓋網絡,Docker啟動的容器對外通信的源地址都不是容器的IP) - mangle表:拆解報文,做出修改,并重新封裝 的功能。內核模塊:
iptable_mangle,可以實現修改數據包的一些標志位,以便其他規則或程序可以利用這種標志對數據包進行過濾或策略路由(相關使用場景:Kubernetes-calico對集群容器網絡的policy實現) - raw表:關閉nat表上啟用的連接追蹤機制。內核模塊:
iptable_raw,可以實現對報文處理跳過NAT表和ip_conntrack處理,即不再做地址轉換和數據包的鏈接跟蹤處理了(相關使用場景:RAW表可以應用在那些不需要做nat的情況下,以提高性能。如大量訪問的web服務器,可以讓80端口不再讓iptables做數據包的鏈接跟蹤處理,以提高用戶的訪問速度)
- filter表:負責過濾功能,防火墻。內核模塊:
表和鏈的關系
- 5個鏈的職責不同,所以某些鏈中注定不會包含某類規則
- 在實際的使用過程中,是通過表作為操作入口,對規則進行定義。在表中添加的規則時需要指定其所在的鏈
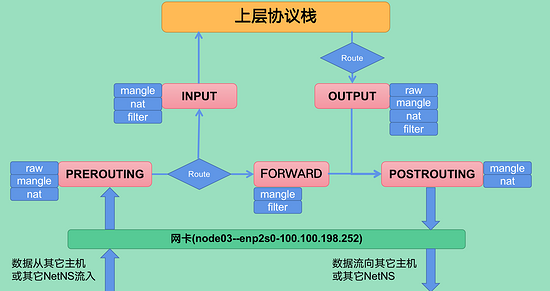
每個鏈中包含的規則類型
梳理報文走向
以Host主機網絡空間為分析對象,分析Host主機網絡空間主動發起ping的過程
Host主機網路空間---->demo01(發送數據):
1、當從 100.100.198.250 主動發起ping時,報文的起始位置在圖中的最上層的協議棧
2、經過路由表判斷--用目的地址匹配到路由(如果匹配不到路由,不知道下一條去哪里,那么直接丟棄),標記數據的下一跳--vethhost01
3、經過OUTPUT鏈檢查(4種類型的規則policy默認均為ACCEPT--不阻攔),由于也沒有其他規則,直接流轉到下游
- iptables -t raw --line-numbers -nvL OUTPUT #查看iptables指定表的指定鏈的相關規則命名 `riptables -t <表名> --line-numbers -nvL <鏈名稱>` 該命令的解讀:打印OUTPUT鏈中的所有raw類型的規則,并能從policy的值獲取該類規則集合的默認通行策略
- iptables -t mangle --line-numbers -nvL OUTPUT
- iptables -t nat --line-numbers -nvL OUTPUT
- iptables -t filter --line-numbers -nvL OUTPUT #該鏈功能最強大,四種類型的功能都有

OUTPUT鏈的規則
4、經過POSTROUTING鏈檢查(mangle和nat類型的規則policy默認為ACCEPT--不阻攔),由于也沒有其他規則,最終將報文發送給100.100.198.252的網卡enp2s0
- iptables -t mangle --line-numbers -nvL POSTROUTING #命令使用方式同上,POSTROUTING是網絡命名空間的`出口關卡`
- iptables -t nat --line-numbers -nvL POSTROUTING

POSTROUTING鏈的規則
5、網卡enp2s0將報文發送至路由標記的vethhost01,vethhost01會默認將報文流轉到自己的網卡對對端--vethdemo01,抵達demo01的內核
Host主機網路空間<----demo01(接收數據):
1、當從demo01收到報文并返回應答報文時,應答報文抵達 100.100.198.252 的網卡enp2s0(報文抵達網卡enp2s0前的過程,就是上述 發送數據 的過程,報文的起始位置就是demo01的協議棧)
2、內核接受到網卡的報文,先經過PREROUTING鏈檢查(policy默認為ACCEPT--不阻攔),由于也沒有其他規則,直接流轉到下游
- iptables -t raw --line-numbers -nvL PREROUTING #命令使用方式同上,PREROUTING是網絡命名空間的`入口關卡`
- iptables -t mangle --line-numbers -nvL PREROUTING
- iptables -t nat --line-numbers -nvL PREROUTING

PREROUTING鏈的規則
3、判斷報文目的地址是否是本機(目標地址是本機)
4、經過INPUT鏈檢查(policy默認為ACCEPT--不阻攔),由于也沒有其他規則,最終抵達協議棧,ping的發起端接收到返回報文,完成一次完整ICMP通訊
- iptables -t mangle --line-numbers -nvL INPUT #命令使用方式同上,經過INPUT鏈的報文就能進協議棧了
- iptables -t nat --line-numbers -nvL INPUT
- iptables -t filter --line-numbers -nvL INPUT

INPUT鏈的規則
以Host主機網絡空間作為 路由器 轉發ping包為例
demo01---->host主機網路空間---->demo02(轉發數據):
1、起始報文從demo01發出抵達 100.100.198.252 的網卡enp2s0
2、內核接受到網卡的報文,先經過PREROUTING鏈檢查(同上)
3、判斷報文目的地址是否是本機(目標地址不是本機),經過路由表判斷--用目的地址匹配到路由(如果匹配不到路由,不知道下一條去哪里,那么直接丟棄),標記數據的下一跳-- 10.1.2.2
4、經過FORWARD鏈檢查,(filter類型的規則policy默認為DROP--阻攔),只有當匹配到可以通行的規則,報文才能流轉到下游
- iptables -t mangle --line-numbers -nvL FORWARD #mangle類型的規則默認policy規則ACCEPT
- iptables -t filter --line-numbers -nvL FORWARD #filter類型的規則policy默認為DROP
- # 可以看到該類規則已經DROP了很多個packets,如果一直測試ping,能看到被DROP的包會一直增長

FORWARD鏈的filter類型規則
5、經過POSTROUTING鏈檢查(同上),最終將報文發送給 100.100.198.252 的網卡enp2s0
6、網卡enp2s0將報文發送至路由標記的vethhost02,vethhost02會默認將報文流轉到自己的網卡對對端--vethdemo02,抵達demo02的內核
7、demo02內核按照上述中的 接收數據 流程處理報文,并將ICMP的應答報文按照 發送數據 的流程,以demo01的IP地址 10.0.1.2 為目的地址反向發送數據
8、Host主機網路空間同樣按上述 轉發數據 的過程再轉發一次,只是這次轉發的是demo02發出的應答報文(Host主機網路空間,完成了兩個方向的報文轉發,去包方向和回包方向)
9、最終demo01的協議棧接收到應答報文,完成一次通過 100.100.198.252 轉發的ICMP通訊
內核處理的報文的三個鏈路
- 發送數據,內核處理協議棧的發送數據的鏈路:路由判斷(匹配下一跳)-->OUTPUT-->POSTROUTING-->網卡-->下一跳
- 接受數據,內核處理網卡接受的外部數據鏈路:PREROUTING-->路由判斷(是本機)-->INPUT-->協議棧
- 轉發數據,內核處理網卡接受的外部數據鏈路:PREROUTING-->路由判斷(不是本機,匹配下一跳)-->FORWARD-->POSTROUTING-->網卡-->下一跳
通過上述的信息我們可以梳理出,目前demo01/02無法實現互ping的原因,是被作為 路由器 角色的host主機網絡空間內核將相關的報文攔截并丟棄了。
攔截的 關卡 位于FORWARD鏈,FORWARD鏈中的 過濾 規則默認是不允許通過。
- 需要為來自demo01/02雙方都
頒發"通行證" - 互通是雙向的,需要為demo01/02分別配置
來和去兩條規則,一共四條規則
- iptables -t filter -A FORWARD -o vethhost01 -j ACCEPT #添加命令 `iptables -t <表> -A <鏈> -o <網卡> -j ACCEPT` 命令解讀:在FORWARD鏈添加一條類型為filter的規則,規則內容是--目的地址在路由表上的下一跳是vethhost01的報文,都放行
- iptables -t filter -A FORWARD -i vethhost01 -j ACCEPT #添加命令 `iptables -t <表> -A <鏈> -i <網卡> -j ACCEPT` 命令解讀:在FORWARD鏈添加一條類型為filter的規則,規則內容是--只要是從vethhost01傳來的報文,都放行
- iptables -t filter -A FORWARD -i vethhost02 -j ACCEPT #同上
- iptables -t filter -A FORWARD -o vethhost02 -j ACCEPT

FORWARD鏈的filter類型規則已添加
驗證:
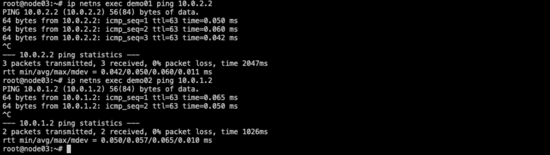
demo01/02雙向已互通
跨主機通信(實現demo01/02與其他主機互通)
準備一臺Linux主機(node02--100.100.198.253)。
- node02并不知道要訪問10.0.1.2/10.0.2.2在node03上,需要在node02上添加相關路由,將目的地址的下一跳指向node03(100.100.198.250)
- node02和node03本就互通(且在同一網段),所以node03上不用添加任何路由和iptables相關配置

node02的路由
驗證:
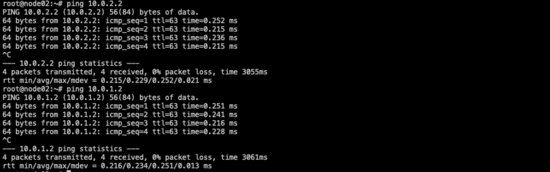
node02-->demo01/02
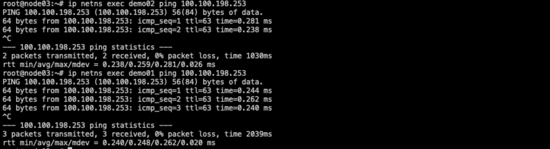
demo01/02-->node02
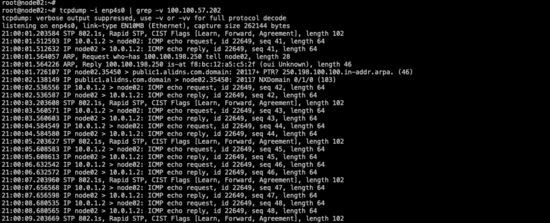
在node02上抓包,顯示的源地址就是10.0.1.2
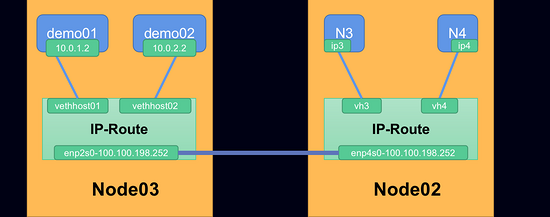
目前的網絡模型
至此,可以跨主機通信的Network Namespace就已經創建并配置完成了。
Node02上的N3和N4的創建以及配置過程就不做演示了,操作步驟參考以上即可。
結語
Network Namespace通訊模型不止一種,每種模型也有各自的優缺點。此次實現的Network Namespace間的通信模型,是基于路由模式實現的( 純三層 的實現)。
該種通訊模型的相關網絡方案性能更接近于主機網絡,Kubernetes網絡組件Calico的BGP模式的實現就是基于此種模型,性能較IPIP模式(Overlay類型的網絡)有很大提升。
此類的方案明顯的特征是終端收到的包并未被nat處理過,比如從node02的抓包顯示,報文的源地址就是發起端demo01的IP: 10.0.1.2 。在一些需求場景下,請求的接收端是必須要獲取到源IP的。這種場景下,Overlay類型的網絡方案就無法滿足。
希望這篇文章能幫助到大家了解Kubernetes網絡底層的一些技術實現。