如何用Netty寫一個高性能的分布式服務框架?
一 什么是 Netty? 能做什么?
-
Netty 是一個致力于創(chuàng)建高性能網(wǎng)絡應用程序的成熟的 IO 框架。
-
相比較與直接使用底層的 Java IO API,你不需要先成為網(wǎng)絡專家就可以基于 Netty 去構(gòu)建復雜的網(wǎng)絡應用。
-
業(yè)界常見的涉及到網(wǎng)絡通信的相關(guān)中間件大部分基于 Netty 實現(xiàn)網(wǎng)絡層。
二 設計一個分布式服務框架
1 Architecture
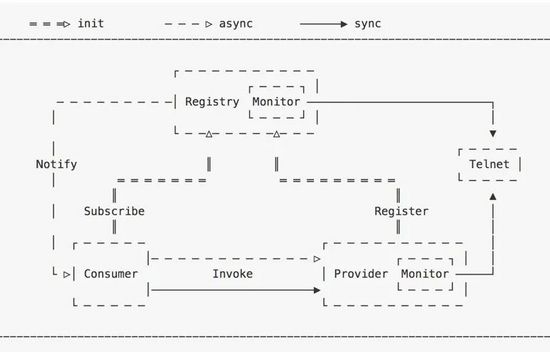
2 遠程調(diào)用的流程
-
啟動服務端(服務提供者)并發(fā)布服務到注冊中心。
-
啟動客戶端(服務消費者)并去注冊中心訂閱感興趣的服務。
-
客戶端收到注冊中心推送的服務地址列表。
-
調(diào)用者發(fā)起調(diào)用,Proxy從服務地址列表中選擇一個地址并將 請求信息 <group,providerName,version>,methodName,args[] 等信息 序列化為字節(jié)數(shù)組并通過網(wǎng)絡發(fā)送到該地址上。
-
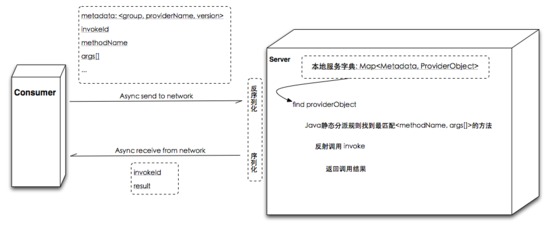
服務端收到收到并反序列化請求信息,根 據(jù) <group,providerName,version> 從本地服務 字典里查找到對應 provid erObject,再根據(jù) <methodName,args[]> 通過反射調(diào)用指定 方法,并將方法返回值序列化為字節(jié)數(shù)組返回給客戶端。
-
客戶端收到響應信息再反序列化為 Java 對象后由 Proxy 返回給方法調(diào)用者。
以上流程對方法調(diào)用者是透明的,一切看起來就像本地調(diào)用一樣。
3 遠程調(diào)用客戶端圖解
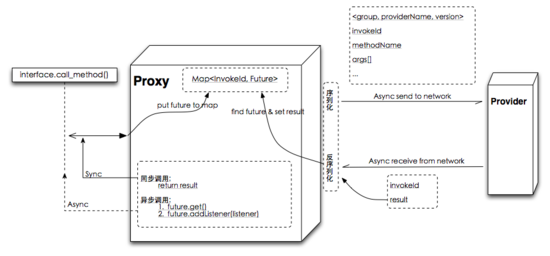
重要概念:RPC三元 組 <ID,Request,Response>。
PS: 若是 netty4.x 的線程模型,IO Thread(worker) —> Map<InvokeId,F(xiàn)uture> 代替全局 Map 能更好的避免線程競爭。
4 遠程調(diào)用服務端圖解
5 遠程調(diào)用傳輸層圖解
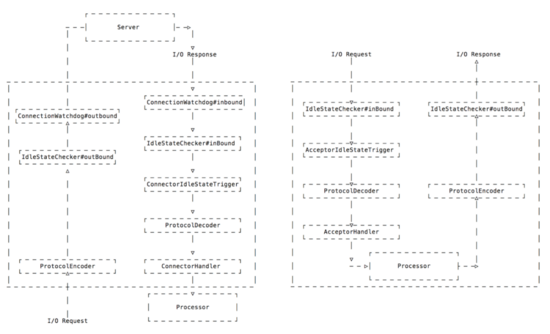
6 設計傳輸層協(xié)議棧
協(xié)議頭

協(xié)議體
1)metadata: <group,providerName,version>
2)methodName
3)parameterTypes[] 真的需要嗎?
(a)有什么問題?
-
反序列化 時 ClassLoader.loadClass() 潛在鎖 競爭。
-
協(xié)議體碼流大小。
-
泛化調(diào)用多了參數(shù)類型。
( b)能解決嗎?
-
Java方法靜態(tài)分派規(guī)則參考JLS <Java語言規(guī)范> $15.12.2.5 Choosing the Most Specific Method 章節(jié)。
( c)args[]
( d)其他:traceId,appName…
三 一些Features&好的實踐&壓榨性能
1 創(chuàng)建客戶端代理對象
1)Proxy 做什么?
-
集群容錯 —> 負載均衡 —> 網(wǎng)絡
2)有哪些創(chuàng)建 Proxy 的方式?
-
jdk proxy/javassist/cglib/asm/bytebuddy
3)要注意的:
-
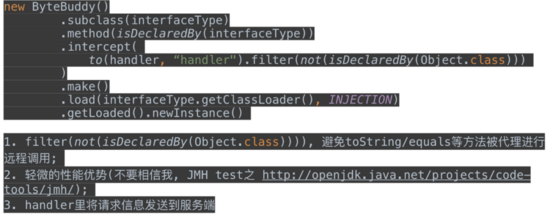
注意攔截toString,equals,hashCode等方法避免遠程調(diào)用。
4)推薦的(bytebuddy):
2 優(yōu)雅的同步/異步調(diào)用
-
先往上翻再看看“ 遠程調(diào)用客戶端圖解 ”
-
再往下翻翻看看 Failover 如何處理更好
-
思考下如何拿到 future?
3 單播/組播
-
消息派發(fā)器
-
FutureGroup
4 泛化調(diào)用
-
Object $invoke(String methodName,Object... args)
-
parameterTypes[]
5 序列化/反序列化
協(xié)議 header 標記 serializer type,同時支持多種。
6 可擴展性
Java SPI:
-
java.util.ServiceLoader
-
META-INF/services/com.xxx.Xxx
7 服務級別線程池隔離
要掛你先掛,別拉著我。
8 責任鏈模式的攔截器
太多擴展需要從這里起步。
9 指標度量(Metrics)
10 鏈路追蹤
OpenTracing
11 注冊中心
12 流控(應用級別/服務級別)
要有能方便接入第三方流控中間件的擴展能力。
13 Provider線程池滿了怎么辦?

14 軟負載均衡
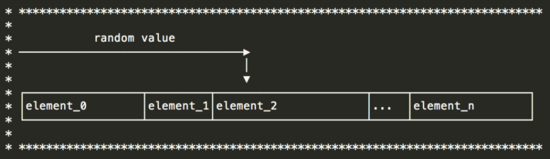
1)加權(quán)隨機 (二分法,不要遍歷)
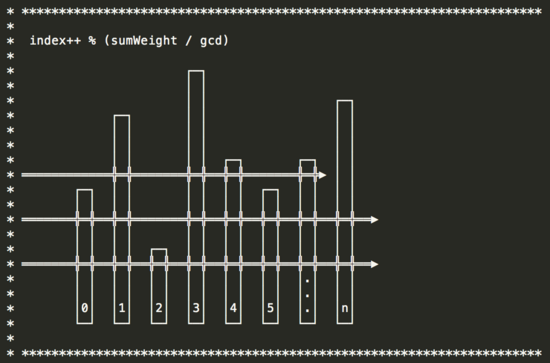
2)加權(quán)輪訓(最大公約數(shù))
3)最小負載
4)一致性 hash (有狀態(tài)服務場景)
5)其他
注意:要有預熱邏輯。
15 集群容錯
1)Fail-fast
2)Failover
異步調(diào)用怎么處理?
-
Bad

-
Better

3)Fail-safe
4)Fail-back
5)Forking
6)其他
16 如何壓榨性能(Don’t trust it,Test it)
1)ASM 寫個 FastMethodAccessor 來代替服務端那個反射調(diào)用

2)序列化/反序列化
在業(yè)務線程中序列化/反序列化,避免占用 IO 線程:
-
序列化/反序列化占用數(shù)量極少的 IO 線程時間片。
-
反序列化常常會涉及到 Class 的加載,loadClass 有一把鎖競爭嚴重(可通過 JMC 觀察一下)。
選擇高效的序列化/反序列化框架:
-
如 kryo/protobuf/protostuff/hessian/fastjson/…
選擇只是第一步,它(序列化框架)做的不好的,去擴展和優(yōu)化之:
-
傳統(tǒng)的序列化/反序列化+寫入/讀取網(wǎng)絡的流程: java對象--> byte[] -->堆外內(nèi)存 / 堆外內(nèi)存--> byte[] -->java對象。
-
優(yōu)化: 省去 byte[] 環(huán)節(jié),直接 讀/寫 堆外內(nèi)存,這需要擴展對應的序列化框架。
-
String 編碼/解碼優(yōu)化。
-
Varint 優(yōu)化: 多次 writeByte 合并為 writeShort/writeInt/writeLong。
-
Protostuff 優(yōu)化舉例: UnsafeNioBufInput 直接讀堆外內(nèi)存/ UnsafeNioBufOutput 直接寫堆外內(nèi)存。
3)IO 線程綁定 CPU
4)同步阻塞調(diào)用的客戶端和容易成為瓶頸,客戶端協(xié)程:
-
Java層面可選的并不多,暫時也都不完美。
| name | description |
| kilim | 編譯期間字節(jié) 碼增強 |
| quasar agent | 動 態(tài)字節(jié)碼增強 |
| ali_wisp | ali_jvm 在底層直接實現(xiàn) |
5)Netty Native Transport & PooledByteBufAllocator:
-
減小GC帶來的波動。
6)盡快釋放 IO 線程去做他該做的事情,盡量減少線程上下文切換。
四 Why Netty?
1 BIO vs NIO
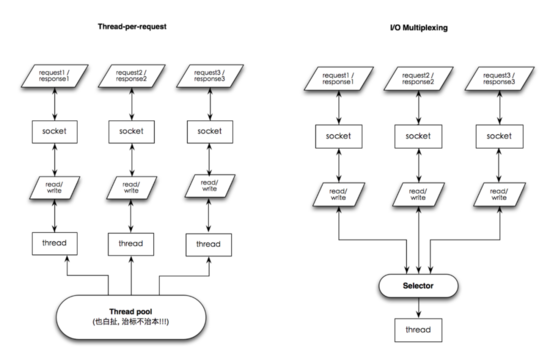
2 Java 原生 NIO API 從入門到放棄
復雜度高
-
API復雜難懂,入門困。
-
粘包/半包問題費神。
-
需超強的并發(fā)/異步編程功底,否則很難寫出高效穩(wěn)定的實現(xiàn)。
穩(wěn)定性差,坑多且深
-
調(diào)試困難,偶爾遭遇匪夷所思極難重現(xiàn)的bug,邊哭邊查是常有的事兒。
-
linux 下 EPollArrayWrapper.epollWait 直接返回導致空輪訓進而導致 100% cpu 的 bug 一直也沒解決利索,Netty幫你 work around (通過rebuilding selector)。
NIO代碼實現(xiàn)方面的一些缺點
1)Selector.selectedKeys() 產(chǎn)生太多垃圾
Netty 修改了 sun.nio.ch.SelectorImpl 的實現(xiàn),使用雙數(shù)組代替 HashSet 存儲來 selectedKeys:
-
相比HashSet(迭代器,包裝對象等)少了一些垃圾的產(chǎn)生(help GC)。
-
輕微的性能收益(1~2%)。
Nio 的代碼到處是 synchronized (比如 allocate direct buffer 和 Selector.wakeup() ):
-
對于 allocate direct buffer,Netty 的 pooledBytebuf 有前置 TLAB(Thread-local allocation buffer)可有效的減少去競爭鎖。
-
wakeup 調(diào)用多了鎖競爭嚴重并且開銷非常大(開銷大原因: 為了在 select 線程外跟 select 線程通信,linux 平臺上用一對 pipe,windows 由于 pipe 句柄不能放入 fd_set,只能委曲求全用兩個 tcp 連接模擬),wakeup 調(diào)用少了容易導致 select 時不必要的阻塞(如果懵逼了就直接用 Netty 吧,Netty中有對應的優(yōu)化邏輯)。
-
Netty Native Transport 中鎖少了很多。
2)fdToKey 映射
-
EPollSelectorImpl#fdToKey 維持著所有連接的 fd(描述符)對應 SelectionKey 的映射,是個 HashMap。
-
每個 worker 線程有一個 selector,也就是每個 worker 有一個 fdToKey,這些 fdToKey 大致均分了所有連接。
-
想象一下單機 hold 幾十萬的連接的場景,HashMap 從默認 size=16,一步一步 rehash...
3)Selector在linux 平臺是 Epoll LT 實現(xiàn)
-
Netty Native Transport支持Epoll ET。
4)Direct Buffers 事實上還是由 GC 管理
-
DirectByteBuffer.cleaner 這個虛引用負責 free direct memory,DirectByteBuffer 只是個殼子,這個殼子如果堅強的活下去熬過新生代的年齡限制最終晉升到老年代將是一件讓人傷心的事情…
-
無法申請到足夠的 direct memory 會顯式觸發(fā) GC,Bits.reserveMemory() -> { System.gc() },首先因為 GC 中斷整個進程不說,代碼中還 sleep 100 毫秒,醒了要是發(fā)現(xiàn)還不行就 OOM。
-
更糟的是如果你聽信了個別<XX優(yōu)化寶典>讒言設置了-XX:+DisableExplicitGC 參數(shù),悲劇會靜悄悄的發(fā)生...
-
Netty的UnpooledUnsafeNoCleanerDirectByteBuf 去掉了 cleaner,由 Netty 框架維護引用計數(shù)來實時的去釋放。
五 Netty 的真實面目
1 Netty 中幾個重要概念及其關(guān)系
EventLoop
-
一個 Selector。
-
一個任務隊列(mpsc_queue: 多生產(chǎn)者單消費者 lock-free)。
-
一個延遲任務隊列(delay_queue: 一個二叉堆結(jié)構(gòu)的優(yōu)先級隊列,復雜度為O(log n))。
-
EventLoop 綁定了一個 Thread,這直接避免了pipeline 中的線程競爭。
Boss: mainReactor 角色,Worker: subReactor 角色
-
Boss 和 Worker 共用 EventLoop 的代碼邏輯,Boss 處理 accept 事件,Worker 處理 read,write 等事件。
-
Boss 監(jiān)聽并 accept 連接(channel)后以輪訓的方式將 channel 交給 Worker,Worker 負責處理此 channel 后續(xù)的read/write 等 IO 事件。
-
在不 bind 多端口的情況下 BossEventLoopGroup 中只需要包含一個 EventLoop,也只能用上一個,多了沒用。
-
WorkerEventLoopGroup 中一般包含多個 EventLoop,經(jīng)驗值一般為 cpu cores * 2(根據(jù)場景測試找出最佳值才是王道)。
-
Channel 分兩大類 ServerChannel 和 Channel,ServerChannel 對應著監(jiān)聽套接字(ServerSocketChannel),Channel 對應著一個網(wǎng)絡連接。
2 Netty4 Thread Model
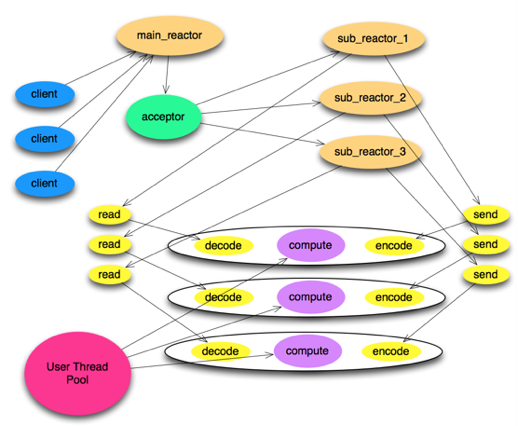
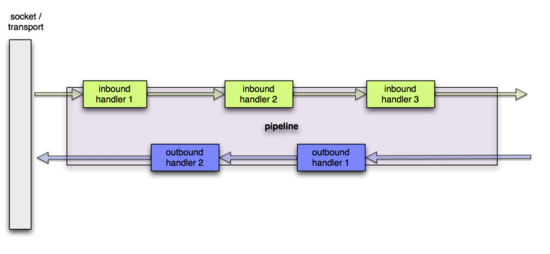
3 ChannelPipeline
4 Pooling&reuse
PooledByteBufAllocator
-
基于 jemalloc paper (3.x)
-
ThreadLocal caches for lock free: 這個做法導致曾經(jīng)有坑——申請(Bytebuf)線程與歸還(Bytebuf)線程不是同一個導致內(nèi)存泄漏,后來用一個mpsc_queue解決,代價就是犧牲了一點點性能。
-
Different size classes。
Recycler
-
ThreadLocal + Stack。
-
曾經(jīng)有坑,申請(元素)線程與歸還(元素)線程不是同一個導致內(nèi)存泄漏。
-
后來改進為不同線程歸還元素的時候放入一個 WeakOrderQueue 中并關(guān)聯(lián)到 stack 上,下次 pop 時如果 stack 為空則先掃描所有關(guān)聯(lián)到當前 stack 上的 weakOrderQueue。
-
WeakOrderQueue 是多個數(shù)組的鏈表,每個數(shù)組默認size=16。
-
存在的問題:思考一下老年代對象引用新生代對象對 GC 的影響?
5 Netty Native Transport
相比 Nio 創(chuàng)建更少的對象,更小的 GC 壓力。
針對 linux 平臺優(yōu)化,一些 specific features:
-
SO_REUSEPORT - 端口復用(允許多個 socket 監(jiān)聽同一個 IP+端口,與 RPS/RFS 協(xié)作,可進一步提升性能 ):可把 RPS/RFS 模糊的理解為在軟件層面模擬多隊列網(wǎng)卡,并提供負載均衡能力,避免網(wǎng)卡收包發(fā)包的中斷集中的一個 CPU core 上而影響性能。
-
TCP_FASTOPEN - 3次握手時也用來交換數(shù)據(jù)。
-
EDGE_TRIGGERED (支持Epoll ET是重點)。
-
Unix 域套接字(同一臺機器上的進程間通信,比如Service Mesh)。
6 多路復用簡介
select/poll
-
本身的實現(xiàn)機制上的限制(采用輪詢方式檢測就緒事件,時間復雜度: O(n),每次還要將臃腫的 fd_set 在用戶空間和內(nèi)核空間拷貝來拷貝去),并發(fā)連接越大,性能越差。
-
poll 相比 select 沒有很大差異,只是取消了最大文件描述符個數(shù)的限制。
-
select/poll 都是 LT 模式。
epoll
-
采用回調(diào)方式檢測就緒事件,時間復雜度: O(1),每次 epoll_wait 調(diào)用只返回已就緒的文件描述符。
-
epoll 支持 LT 和 ET 模式。
7 稍微深入了解一點 Epoll
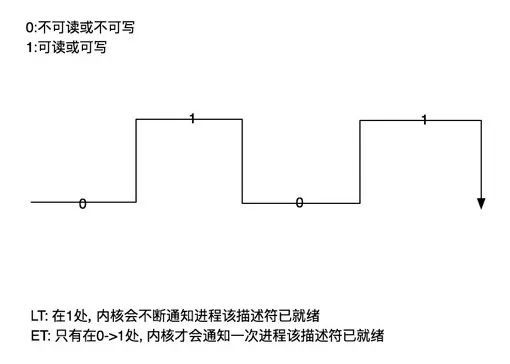
LT vs ET
概念:
-
LT:level-triggered 水平觸發(fā)
-
ET:edge-triggered 邊沿觸發(fā)
可讀:
-
buffer 不為空的時候 fd 的 events 中對應的可讀狀態(tài)就被置為1,否則為0。
可寫:
-
buffer 中有空間可寫的時候 fd 的 events 中對應的可寫狀態(tài)就被置為1,否則為0。
圖解:
epoll 三個方法簡介
1)主要代碼:linux-2.6.11.12/fs/eventpoll.c
2)int epoll_create(int size)
創(chuàng)建 rb-tree(紅黑樹)和 ready-list (就緒鏈表):
-
紅黑樹O(logN),平衡效率和內(nèi)存占用,在容量需求不能確定并可能量很大的情況下紅黑樹是最佳選擇。
-
size參數(shù)已經(jīng)沒什么意義,早期epoll實現(xiàn)是hash表,所以需要size參數(shù)。
3)int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event)
-
把epitem放入rb-tree并向內(nèi)核中斷處理程序注冊ep_poll_callback,callback觸發(fā)時把該epitem放進ready-list。
4)int epoll_wait(int epfd,struct epoll_event * events,int maxevents,int timeout)
-
ready-list —> events[]。
epoll 的數(shù)據(jù)結(jié)構(gòu)
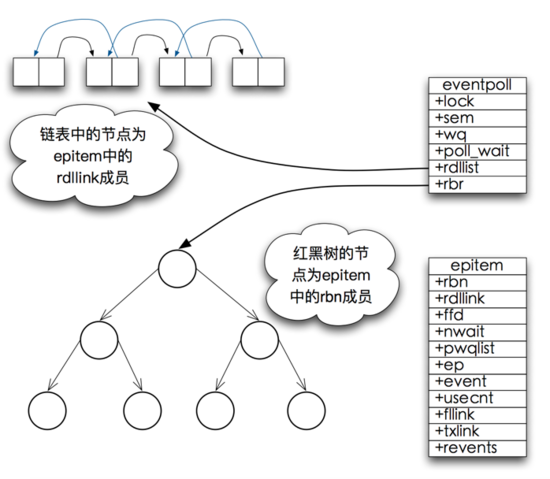
epoll_wait 工作流程概述
對照代碼:linux-2.6.11.12/fs/eventpoll.c:
1)epoll_wait 調(diào)用 ep_poll
-
當 rdlist(ready-list) 為空(無就緒fd)時掛起當前線程,直到 rdlist 不為空時線程才被喚醒。
2)文件描述符 fd 的 events 狀態(tài)改變
-
buffer由不可讀變?yōu)榭勺x或由不可寫變?yōu)榭蓪懀瑢е孪鄳猣d上的回調(diào)函數(shù)ep_poll_callback被觸發(fā)。
3)ep_poll_callback 被觸發(fā)
-
將相應fd對應epitem加入rdlist,導致rdlist不空,線程被喚醒,epoll_wait得以繼續(xù)執(zhí)行。
4)執(zhí)行 ep_events_transfer 函數(shù)
-
將rdlist中的epitem拷貝到txlist中,并將rdlist清空。
-
如果是epoll LT,并且fd.events狀態(tài)沒有改變(比如buffer中數(shù)據(jù)沒讀完并不會改變狀態(tài)),會再重新將epitem放回rdlist。
5)執(zhí)行 ep_send_events 函數(shù)
-
掃描txlist中的每個epitem,調(diào)用其關(guān)聯(lián)fd對應的poll方法取得較新的events。
-
將取得的events和相應的fd發(fā)送到用戶空間。
8 Netty 的最佳實踐
1)業(yè)務線程池必要性
-
業(yè)務邏輯尤其是阻塞時間較長的邏輯,不要占用netty的IO線程,dispatch到業(yè)務線程池中去。
2)WriteBufferWaterMark
-
注意默認的高低水位線設置(32K~64K),根據(jù)場景適當調(diào)整(可以思考一下如何利用它)。
3)重寫 MessageSizeEstimator 來反應真實的高低水位線
-
默認實現(xiàn)不能計算對象size,由于write時還沒路過任何一個outboundHandler就已經(jīng)開始計算message size,此時對象還沒有被encode成Bytebuf,所以size計算肯定是不準確的(偏低)。
4)注意EventLoop#ioRatio的設置( 默認50)
-
這是EventLoop執(zhí)行IO任務和非IO任務的一個時間比例上的控制。
5)空閑鏈路檢測用誰調(diào)度?
-
Netty4.x默認使用IO線程調(diào)度,使用eventLoop的delayQueue,一個二叉堆實現(xiàn)的優(yōu)先級隊列,復雜度為O(log N),每個worker處理自己的鏈路監(jiān)測,有助于減少上下文切換,但是網(wǎng)絡IO操作與idle會相互影響。
-
如果總的連接數(shù)小,比如幾萬以內(nèi),上面的實現(xiàn)并沒什么問題,連接數(shù)大建議用HashedWheelTimer實現(xiàn)一個IdleStateHandler,HashedWheelTimer復雜度為 O(1),同時可以讓網(wǎng)絡IO操作和idle互不影響,但有上下文切換開銷。
6)使用ctx.writeAndFlush還是channel.writeAndFlush?
-
ctx.write直接走到下一個outbound handler,注意別讓它違背你的初衷繞過了空閑鏈路檢測。
-
channel.write從末尾開始倒著向前挨個路過pipeline中的所有outbound handlers。
7)使用Bytebuf.forEachByte() 來代替循環(huán) ByteBuf.readByte()的遍歷操作,避免rangeCheck()
8)使用CompositeByteBuf來避免不必要的內(nèi)存拷貝
-
缺點是索引計算時間復雜度高,請根據(jù)自己場景衡量。
9)如果要讀一個int,用Bytebuf.readInt(),不要Bytebuf.readBytes(buf,0,4)
-
這能避免一次memory copy (long,short等同理)。
10)配置
UnpooledUnsafeNoCleanerDirectByteBuf來代替jdk的DirectByteBuf,讓netty框架基于引用計數(shù)來釋放堆外內(nèi)存
io.netty.maxDirectMemory:
-
< 0: 不使用cleaner,netty方面直接繼承jdk設置的最大direct memory size,(jdk的direct memory size是獨立的,這將導致總的direct memory size將是jdk配置的2倍)。
-
== 0: 使用cleaner,netty方面不設置最大direct memory size。
0:不使用cleaner,并且這個參數(shù)將直接限制netty的最大direct memory size,(jdk的direct memory size是獨立的,不受此參數(shù)限制)。
11)最佳連接數(shù)
-
一條連接有瓶頸,無法有效利用cpu,連接太多也白扯,最佳實踐是根據(jù)自己場景測試。
12)使用PooledBytebuf時要善于利用 -Dio.netty.leakDetection.level 參數(shù)
-
四種級別:DISABLED(禁用),SIMPLE(簡單),ADVANCED(高級),PARANOID(偏執(zhí))。
-
SIMPLE,ADVANCED采樣率相同,不到1%(按位與操作 mask ==128 - 1)。
-
默認是SIMPLE級別,開銷不大。
-
出現(xiàn)泄漏時日志會出現(xiàn)“LEAK: ” 字樣,請時不時grep下日志,一旦出現(xiàn)“LEAK: ”立刻改為ADVANCED級別再跑,可以報告泄漏對象在哪被訪問的。
-
PARANOID:測試的時候建議使用這個級別,100%采樣。
13)Channel.attr(),將自己的對象attach到channel上
-
拉鏈法實現(xiàn)的線程安全的hash表,也是分段鎖(只鎖鏈表頭),只有hash沖突的情況下才有鎖競爭(類似ConcurrentHashMapV8版本)。
-
默認hash表只有4個桶,使用不要太任性。
9 從 Netty 源碼中學到的代碼技巧
1)海量對象場景中
AtomicIntegerFieldUpdater --> AtomicInteger
-
Java中對象頭12 bytes(開啟壓縮指針的情況下),又因為Java對象按照8字節(jié)對齊,所以對象最小16 bytes,AtomicInteger大小為16 bytes,AtomicLong大小為 24 bytes。
-
AtomicIntegerFieldUpdater作為static field去操作volatile int。
2)FastThreadLocal,相比jdk的實現(xiàn)更快
-
線性探測的Hash表 —> index原子自增的裸數(shù)組存儲。
3)IntObjectHashMap / LongObjectHashMap …
-
Integer—> int
-
Node[] —> 裸數(shù)組
4)RecyclableArrayList
-
基于前面說的Recycler,頻繁new ArrayList的場景可考慮。
5)JCTools
-
一些jdk沒有的 SPSC/MPSC/SPMC/MPMC 無鎖并發(fā)隊以及NonblockingHashMap(可以對比ConcurrentHashMapV6/V8)