













會說話的頭像!新框架LipSync3D,未來或?qū)崿F(xiàn)動態(tài)口型再同步

谷歌人工智能研究人員和印度卡哈拉格普爾理工學(xué)院(Indian Institute of Technology Kharagpur)一起合作開發(fā)了一個新的框架,可以從音頻內(nèi)容中綜合有聲頭像。
該項目的目的是開發(fā)出經(jīng)過優(yōu)化且資源合理的方法,實現(xiàn)根據(jù)音頻創(chuàng)造「會說話的頭像」視頻,在交互式應(yīng)用程序和其他實時環(huán)境中實現(xiàn)同步口型動作的配音或機(jī)器翻譯的音頻,并添加到頭像。

論文地址:https://arxiv.org/pdf/2106.04185.pdf
機(jī)器學(xué)習(xí)模型LipSync3D
在這個過程中訓(xùn)練的機(jī)器學(xué)習(xí)模型LipSync3D,只需要一個目標(biāo)人臉識別的視頻作為輸入數(shù)據(jù)。
數(shù)據(jù)準(zhǔn)備管道將面部幾何的提取與輸入視頻的燈光和其他方面的評估分離開來,允許更經(jīng)濟(jì)合算和更集中的訓(xùn)練。
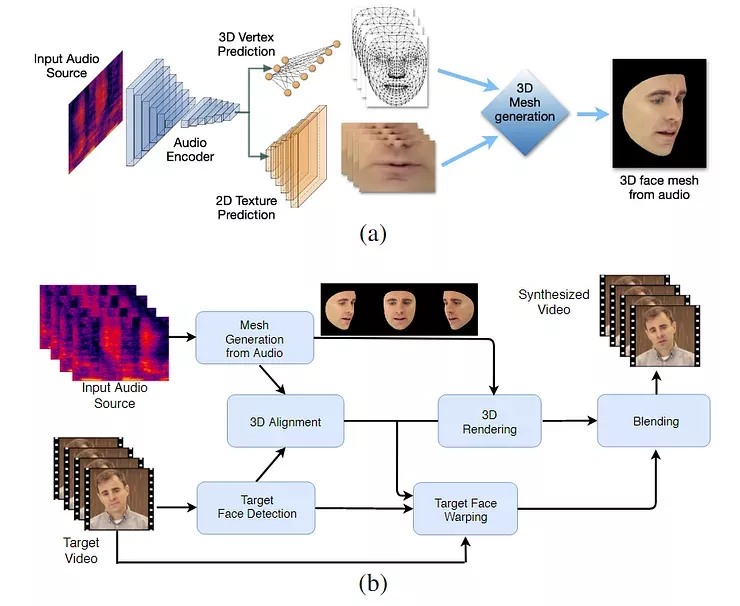
LipSync3D的兩階段工作流程。上圖是從「目標(biāo)」音頻生成的動態(tài)紋理三維人臉; 下圖是將生成的網(wǎng)格插入到目標(biāo)視頻中。
事實上,LipSync3D對這一領(lǐng)域研究工作最顯著的貢獻(xiàn)可能是其照明歸一化算法(lighting normalization algorithm),該算法將訓(xùn)練和推斷照明解耦。

從一般幾何解耦照明數(shù)據(jù)有助于LipSync3D在具有挑戰(zhàn)性的條件下產(chǎn)生更真實的口型變化。最近幾年的其他方法已經(jīng)將自己限制在「固定」的照明條件下,這樣就不會暴露出它們在這方面的有限。
在輸入數(shù)據(jù)幀的預(yù)處理過程中,系統(tǒng)必須識別和刪除鏡像點,因為這些鏡像點是特定于拍攝視頻光照條件的,否則會干擾重現(xiàn)過程。
LipSync3D,顧名思義,不僅僅是對它評估的面孔進(jìn)行像素分析,而是積極地使用已確定的面部標(biāo)志來生成運動的CGI風(fēng)格的網(wǎng)格,以及通過傳統(tǒng)CGI管道包裹在它們周圍的「展開」(unfolded)紋理。

LipSync3D 中的姿勢歸一化。左邊是輸入幀和檢測特征; 中間是生成的網(wǎng)格評估的規(guī)范化頂點; 右邊是相應(yīng)的紋理圖譜,為紋理預(yù)測提供了基礎(chǔ)真實性。來源: https://arxiv.org/pdf/2106.04185.pdf
除了這種新穎的照明重現(xiàn)方法,研究人員聲稱,LipSync3D在以前的工作中提供了三個主要創(chuàng)新: 將幾何、光照、姿態(tài)和紋理分離到規(guī)范化空間中的離散數(shù)據(jù)流中; 一個易于訓(xùn)練的自回歸紋理預(yù)測模型,可以生成時間上一致的視頻合成; 以及通過人類評級和客觀度量來增加真實感。

分裂出的視頻面部圖像的各個方面允許在視頻合成中實現(xiàn)更大的控制。
通過分析語音的音素和其他方面,LipSync3D可以直接從音頻中推導(dǎo)出適當(dāng)?shù)拇讲繋缀芜\動,并將其轉(zhuǎn)化為嘴部周圍已知的相應(yīng)肌肉姿勢。

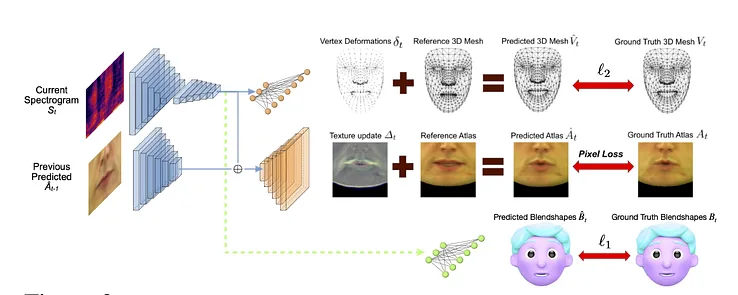
這個過程使用一個聯(lián)合預(yù)測管道,其中推斷的幾何形狀和紋理在自動編碼器設(shè)置中有專門的編碼器,但與打算施加在模型上的語音共享一個音頻編碼器:
LipSync3D 的動作合成也助力提升程式化的CGI頭像,實際上它們只是和真實世界的圖像一樣的網(wǎng)格和紋理信息:
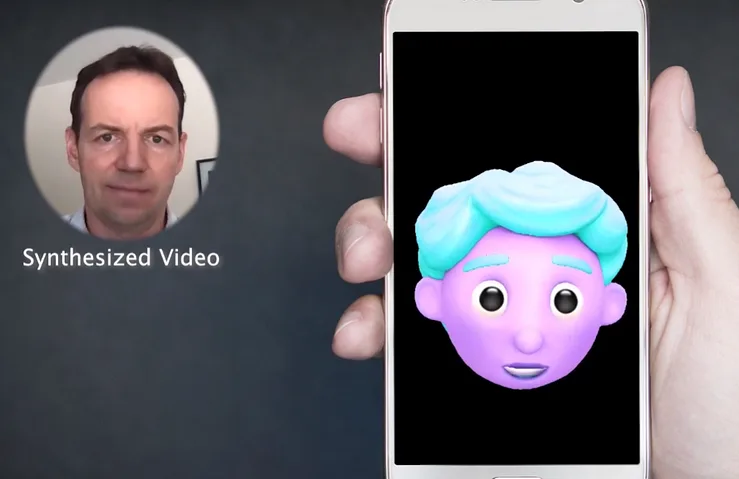
一個個性的3D頭像的嘴唇動作實時動力源揚聲器視頻。在這種情況下,最優(yōu)結(jié)果將通過個性化的預(yù)訓(xùn)練獲得。
研究人員還希望使用更加真實的頭像:

在 GeForce GTX 1080上使用 TensorFlow、 Python 和 C + + 的管道中,視頻的示例訓(xùn)練時間從2-5分鐘的視頻所需3-5小時不等。訓(xùn)練課程使用了一批大小為128幀超過500-1000epoch,每個epoch代表一個完整的視頻評估。
未來:動態(tài)的口型再同步
過去幾年,口型再同步適應(yīng)新的音軌已經(jīng)在計算機(jī)視覺研究中吸引了大量的關(guān)注,尤其是它還是有爭議的deepfake技術(shù)的副產(chǎn)品。
2017年,華盛頓大學(xué)展示了一項能夠通過音頻學(xué)習(xí)對口型的研究,還用當(dāng)時的總統(tǒng)奧巴馬的圖片做了視頻。

https://grail.cs.washington.edu/projects/AudioToObama/siggraph17_obama.pdf
2018年,馬克斯·普朗克計算機(jī)科學(xué)研究所進(jìn)行了另一項研究計劃,實現(xiàn)了身份 > 身份視頻轉(zhuǎn)換(identity>identity video transfer),還帶來了口型同步; 2021年5月,人工智能初創(chuàng)公司 FlawlessAI 發(fā)布了其專有的對口型同步技術(shù) TrueSync,該技術(shù)被媒體廣泛認(rèn)可為跨語言的主要電影的發(fā)行改進(jìn)配音技術(shù)。
當(dāng)然,deepfake開源資源庫的持續(xù)發(fā)展也為面部圖像合成這一領(lǐng)域提供了另一個活躍的用戶貢獻(xiàn)的研究分支。
























