值得推薦的七種優秀開源AI庫
譯文【51CTO.com快譯】在人工智能(AI)研究領域,除了使用TensorFlow和PyTorch等流行平臺,目前還有許多出色的、略顯小眾的開源工具與資源。在本文中,我們將和您討論七種可用于各種前沿研究的開源AI庫。它們所涉及到的領域包括量子機器學習(ML)、加密計算等方面。由于它們提供了開源的許可證,因此您可以對其內容進行增加,分叉,或修改,以滿足實際的項目需求。
DiffEqFlux.jl:用Julia語言實現神經微分方程
- MIT許可證
- GitHub星數:481
- 存儲庫地址:https://github.com/SciML/DiffEqFlux.jl/
專為科學計算而設計的Julia編程語言,是一種相對年輕的編程語言(目前只有“9歲”,而Python已有“30歲”了)。Julia旨在彌合Python等高級生產力語言與C++等高速語言之間的差距。它更接近于在硬件中執行各種機器類操作。Julia語言可以將即時編譯與動態編程的范式相結合。雖然這會讓首次執行需要長時間的編譯,但隨著時間的推移,它會以接近C語言的速度,去運行各種算法。
雖然該語言是專為科學計算與研究而設計的,但是它往往被人們用于機器學習和人工智能領域。借助Flux.jl(下文將會介紹到)等可用于微編程的軟件包,Julia語言正在通過打造其社區和生態系統,以實現快速的迭代、推理和訓練。
作為圍繞著Julia語言開發的一種軟件包,DiffEqFlux.jl通過與DifferentialEquations.jl和Flux.jl工具包相結合,以促進神經微分方程的構建。
當然,除了神經微分方程,DiffEqFlux.jl還支持隨機微分方程、以及通用偏微分方程等。同時,它還通過支持GPU,以滿足前沿生產系統的性能需求。您可以通過鏈接--https://julialang.org/blog/2019/01/fluxdiffeq/,了解更多有關DiffEqFlux.jl的信息。
PennyLane:一個同時適合機器學習和量子計算的庫
- Apache 2.0
- GitHub星數:817
- 存儲庫地址:https://github.com/PennyLaneAI/pennylane
PennyLane利用自動化微分技術,在深度學習和量子電路模擬方面取得了巨大成功。最初,PennyLane基于Autograd庫實現了大部分自動化微分的功能。之后,它又添加了其他的后端庫。目前,PennyLane能夠支持使用PyTorch和TensorFlow后端,以及不同的量子模擬器和設備。作為一個通用庫,它主要用于構建那些可以通過反向傳播,進行訓練和更新的量子與混合電路。
PennyLane團隊對其采用了一流的編碼和單元測試風格。由于是開源的(持有Apache 2.0許可證),因此它在GitHub上擁有大量的貢獻者,并能緊跟量子機器學習領域。
Flux.jl:一種自動化微分的新方法
- MIT“Expat”許可證
- GitHub星級:2.9k
- 存儲庫地址:https://github.com/FluxML/Flux.jl
Flux.jl是一個功能強大的軟件庫,可被用于自動化微分類機器學習和一般性微分編程。它既支持Julia編程語言,又持有開源的MIT許可證。
通常,PyTorch的fast.ai和TensorFlow的Keras都采用的是較高級別的應用程序庫接口,而Flux.jl采用支持各種數學與科學計算的編碼與方程模式,來實現機器學習。
Flux.jl可被用在許多涉及到Julia語言的機器學習項目里,其中就包含了前文討論過的DiffEqFlux.jl。不過,對于那些希望從Python中獲得與Autograd或JAX最相似體驗的初學者來說,Zygote.jl(一個基于Flux的高級自動化微分庫)才是最好的起點。
Tensorflow Probability:正確并不意味著確定
- Apache 2.0
- GitHub星級:3.3k
- 存儲庫地址:https://github.com/tensorflow/probability
TensorFlow Probability提供了可用于推理不確定性、概率和統計分析的工具。這些功能都有助于我們建立針對模型預測的信心,以避免分布外(out-of-distribution)輸入數據對于推理輸出的影響。這正是傳統深度學習模型所無法做到的。
下面我將通過TensorFlow Probability文檔中的一個示例,和您討論在未考慮到不確定性或隨機過程時,可能導致的錯誤。該示例是一個關于回歸問題的簡單案例。我們將定義和討論不確定性的兩大類:任意性(aleatoric)和認知性(epistemic)。
首先,讓我們來看如何使用簡單的線性回歸模型,來擬合數據。此處并未用到任何一種不確定性。
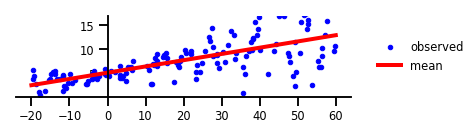
毫無疑問,我們得到了一條線段,它是遵循所有觀察所得出的中心趨勢線。雖然該線段能夠告訴我們一些關于數據的信息,但是它只是其中的一部分。如果真實情況變化過快,那么模型輸出和觀察之間的差異會存在偏離,該線段也就無法很好地解釋真實數據了。接下來,讓我們看看模型在應用認知的不確定性情況下,會發生什么改變。
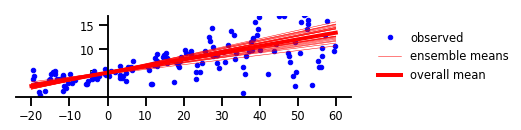
其實,認知的不確定性往往來自缺乏經驗。也就是說,認知不確定性會隨著對給定類型訓練樣本量的增加而減少。畢竟,在機器學習的模型中,基于稀有樣本類型和邊緣情況的預測,可能會導致危險的錯誤結果。
此處任意不確定性代表了事件或預測的內在隨機性,就像擲骰子一樣。如果我們將其應用到該示例的回歸問題中,就會得到如下圖所示的線段。
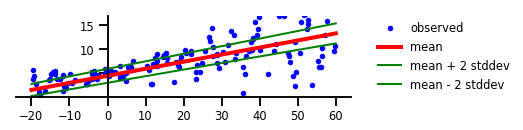
其中的任意不確定性是由統計誤差的范圍所表示的。我們可以看到,盡管認知不確定性似乎捕獲了數據與y軸交叉的樞軸點,但是任意不確定性產生了一個緩慢變化的誤差范圍。該誤差范圍會在數據分布上逐漸擴大,并在右側呈現出松散的沙粒點。
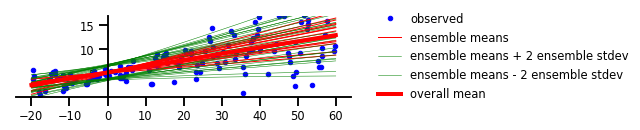
那么,如果將任意和認知的不確定性方法,同時應用到該回歸問題的示例中呢?我們將可以對高度不確定性區域,通過預測來檢驗直覺的觀察。該模型估計可以同時捕獲樞軸區域和數據中的潛在隨機性。不過,TensorFlow Probability在基于具有徑向基函數核的變分高斯過程層,展示了“功能上的不確定性”。
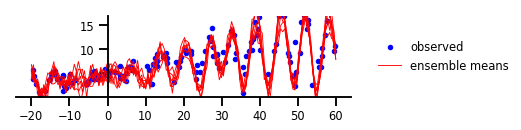
如上圖所示,該自定義的不確定性模型,捕獲了數據中從未被發現到的周期性。如果您對此方面感興趣的話,請參見2019年TensorFlow開發者峰會上,有關TensorFlow Probability的公開演示--https://www.youtube.com/watch?v=BrwKURU-wpk。
TensorFlow Probability所提供的工具,可被用于為機器學習模型注入對于已知未知性參數(任意不確定性)、和未知未知性參數(認知性)的洞見,以及針對概率和統計推理的應用。隨著AI和ML模型在日常生活中的廣泛應用,我們更需要通過此類軟件庫,來構建一個“知道什么時候不知道”的模型。
PySyft:深挖背后的數據
- Apache 2.0
- GitHub星級:7k
- 存儲庫地址:https://github.com/OpenMined/PySyft
如今,人們在日常生活中所產生的敏感數據,包括健康記錄、約會偏好、以及財務記錄等。人們通常希望僅出于非常特定的目的,并且僅由非常特定的人員或算法,來訪問這些數據,同時僅將它們用于預期的目的。例如,人們可能會讓他們的醫生能夠訪問其醫療掃描記錄,但不允許當地藥房(或者更糟的是快餐配送應用)作為廣告營銷的來源。而當人們談論AI安全時,他們往往會將此類風險歸咎于公司、政府、或其他機構缺乏隱私保護的技術應用和政策。
PySyft是一個針對尊重隱私的機器學習,而構建的軟件庫。通過相關工具,PySyft能夠協助用戶在機器學習和計算中,合理地處理那些他們“并不擁有、且無法看到的數據”,進而實現了一種罕見的、尊重隱私的機器學習方式。
AutoKeras:教機器去自行調整超級參數
- Apache 2.0
- GitHub星級:7.9k
- 存儲庫地址:https://github.com/keras-team/autokeras
隨著深度學習已經成為人工智能的重要方法,將深度神經網絡組合在一起,來解決諸如:圖像分割、分類或預測偏好與行為等典型問題,已變得越來越容易。通過Keras和PyTorch的fast.ai等高級庫,我們可以將多個層次連接在一起,并輕松地將它們擬合成有價值的數據集。使用Keras,就像使用model.fit的API一樣簡單。由于AutoKeras添加了一個額外的簡單自動化層,因此它在運行時,您甚至無需指定模型的架構。
如今,我們既不需要通過定制CUDA代碼和自定義的梯度檢查,才能構建深度神經網絡,也不必再使用TensorFlow 1.x版繁雜的圖形會話編程模式。我們只需仔細調整超級參數,便可通過自動化的方式,實現數據集的最佳模型。盡管簡單的網格搜索并非設置超級參數的最佳方法(甚至用隨機搜索通常會更好),但它確實很常見。
作為一個自動化的機器學習庫,AutoKeras將Keras的簡便實用程序與自動化的超級參數,甚至是架構調整的便利性相結合。其中最為實用的是AutoKerasAutoModel類,它可以被用于僅通過其輸入和輸出,來定義“超級模型”。與普通Keras的訓練模型類的方式類似,我們可以通過調用fit()方法,來訓練AutoKerasAutoModel。它不僅會自動調整超級參數,而且還能開發出已優化的內部架構。總之,像AutoKeras之類的自動化機器學習(AutoML)工具,能夠大幅節省開發人員的寶貴時間。
JAX,一個新型快速的自動化微分庫
- Apache 2.0
- GitHub星數:12.3k
- 存儲庫地址:https://github.com/google/jax
作為世界頂級AI研究機構之一,Google DeepMind不僅將JAX作為功能性自動化微分工具納入其工作流程,而且他們一直在開發著一套完整的、以JAX為中心的生態系統。該生態系統包括了:用于深度強化學習的RLax、用于在函數式和面向對象編程范式之間組合與轉換的Haiku、用于圖形深度學習的Jraph、以及許多其他基于JAX的工具,所有這些都持有開源且友好的Apache 2.0許可證。
值得一提的是,對于那些有興趣利用JAX的實時編譯、硬件加速(包括對最新GPU的支持)、以及純JAX的功能,進行AI研究的人員來說,DeepMind JAX生態系統是一個不錯的起點。
小結
在許多時候,AI研究人員可能只會關注鮮少的常用專業工具。盡管他們往往無需從頭開始每個項目,但是確切地知道哪個開源庫適合哪一類項目,還是非常有必要的。通過上述討論,我們為您列出了用于AI研究的七種優秀的開源庫,它們涵括從自動化機器學習到微分量子電路。希望上述列表能夠為您提供豐富的功能、以及足夠的開發選擇。
原文標題:The 7 Best Open Source AI Libraries You May Not Have Heard Of,作者:Kevin Vu
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】