













Go 語言中的零拷貝優化
- 導言
- splice
- pipe pool for splice
- pipe pool in HAProxy
- pipe pool in Go
- 小結
- 參考&延伸
導言
相信那些曾經使用 Go 寫過 proxy server 的同學應該對 io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFrom 等接口和方法不陌生,它們是使用 Go 操作各類 I/O 進行數據傳輸經常需要使用到的 API,其中基于 TCP 協議的 socket 在使用上述接口和方法進行數據傳輸時利用到了 Linux 的零拷貝技術 sendfile 和 splice。
我前段時間為 Go 語言內部的 Linux splice 零拷貝技術做了一點優化:為 splice 實現了一個 pipe pool,復用管道,減少頻繁創建和銷毀 pipe buffers 所帶來的系統開銷,理論上來說能夠大幅提升 Go 的 io 標準庫中基于 splice 零拷貝實現的 API 的性能。因此,我想從這個優化工作出發,分享一些我個人對多線程編程中的一些不成熟的優化思路。
因本人才疏學淺,故行文之間恐有紕漏,望諸君海涵,不吝賜教,若能予以斧正,則感激不盡。
splice
縱觀 Linux 的零拷貝技術,相較于mmap、sendfile和 MSG_ZEROCOPY 等其他技術,splice 從使用成本、性能和適用范圍等維度綜合來看更適合在程序中作為一種通用的零拷貝方式。
splice() 系統調用函數定義如下:
- #include <fcntl.h>
- #include <unistd.h>
- int pipe(int pipefd[2]);
- int pipe2(int pipefd[2], int flags);
- ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
fd_in 和 fd_out 也是分別代表了輸入端和輸出端的文件描述符,這兩個文件描述符必須有一個是指向管道設備的,這算是一個不太友好的限制。
off_in 和 off_out 則分別是 fd_in 和 fd_out 的偏移量指針,指示內核從哪里讀取和寫入數據,len 則指示了此次調用希望傳輸的字節數,最后的 flags 是系統調用的標記選項位掩碼,用來設置系統調用的行為屬性的,由以下 0 個或者多個值通過『或』操作組合而成:
- SPLICE_F_MOVE:指示 splice() 嘗試僅僅是移動內存頁面而不是復制,設置了這個值不代表就一定不會復制內存頁面,復制還是移動取決于內核能否從管道中移動內存頁面,或者管道中的內存頁面是否是完整的;這個標記的初始實現有很多 bug,所以從 Linux 2.6.21 版本開始就已經無效了,但還是保留了下來,因為在未來的版本里可能會重新被實現。
- SPLICE_F_NONBLOCK:指示 splice() 不要阻塞 I/O,也就是使得 splice() 調用成為一個非阻塞調用,可以用來實現異步數據傳輸,不過需要注意的是,數據傳輸的兩個文件描述符也最好是預先通過 O_NONBLOCK 標記成非阻塞 I/O,不然 splice() 調用還是有可能被阻塞。
- SPLICE_F_MORE:通知內核下一個 splice() 系統調用將會有更多的數據傳輸過來,這個標記對于輸出端是 socket 的場景非常有用。
splice() 是基于 Linux 的管道緩沖區 (pipe buffer) 機制實現的,所以 splice() 的兩個入參文件描述符才要求必須有一個是管道設備,一個典型的 splice() 用法是:
- int pfd[2];
- pipe(pfd);
- ssize_t bytes = splice(file_fd, NULL, pfd[1], NULL, 4096, SPLICE_F_MOVE);
- assert(bytes != -1);
- bytes = splice(pfd[0], NULL, socket_fd, NULL, bytes, SPLICE_F_MOVE | SPLICE_F_MORE);
- assert(bytes != -1);
數據傳輸過程圖:
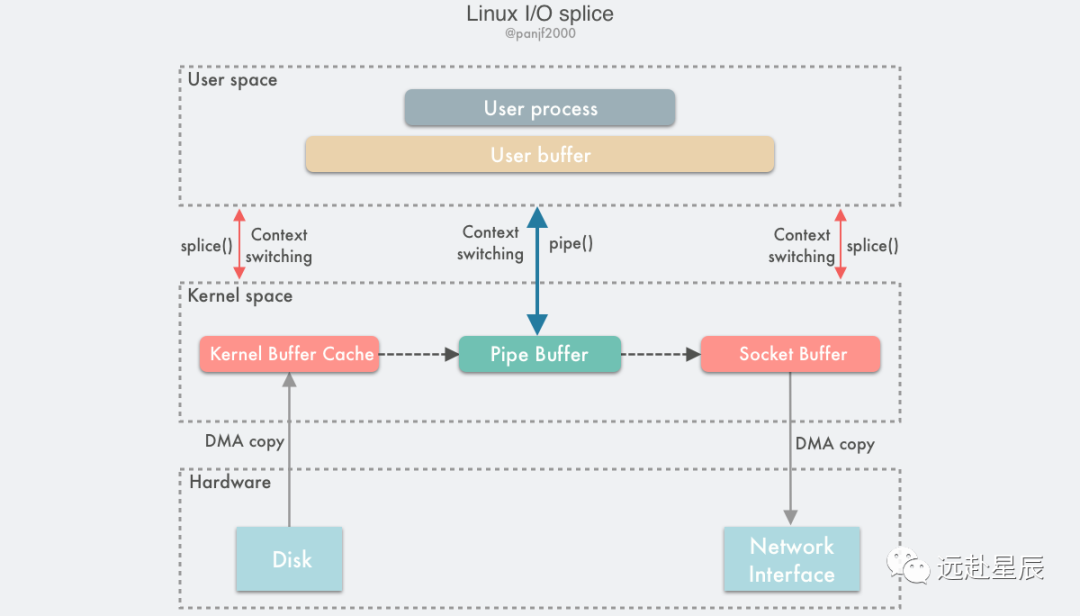
使用 splice() 完成一次磁盤文件到網卡的讀寫過程如下:
- 用戶進程調用 pipe(),從用戶態陷入內核態,創建匿名單向管道,pipe() 返回,上下文從內核態切換回用戶態;
- 用戶進程調用 splice(),從用戶態陷入內核態;
- DMA 控制器將數據從硬盤拷貝到內核緩沖區,從管道的寫入端"拷貝"進管道,splice() 返回,上下文從內核態回到用戶態;
- 用戶進程再次調用 splice(),從用戶態陷入內核態;
- 內核把數據從管道的讀取端"拷貝"到套接字緩沖區,DMA 控制器將數據從套接字緩沖區拷貝到網卡;
- splice() 返回,上下文從內核態切換回用戶態。
上面是 splice 的基本工作流程和原理,簡單來說就是在數據傳輸過程中傳遞內存頁指針而非實際數據來實現零拷貝,如果有意了解其更底層的實現原理請移步:《Linux I/O 原理和 Zero-copy 技術全面揭秘》。
pipe pool for splice
pipe pool in HAProxy
從上面對 splice 的介紹可知,通過它實現數據零拷貝需要利用到一個媒介 -- pipe 管道(2005 年由 Linus 引入),大概是因為在 Linux 的 IPC 機制中對 pipe 的應用已經比較成熟,于是借助了 pipe 來實現 splice,雖然 Linux Kernel 團隊曾在 splice 誕生之初便說過在未來可以移除掉 pipe 這個限制,但十幾年過去了也依然沒有付諸實施,因此 splice 至今還是和 pipe 死死綁定在一起。
那么問題就來了,如果僅僅是使用 splice 進行單次的大批量數據傳輸,則創建和銷毀 pipe 開銷幾乎可以忽略不計,但是如果是需要頻繁地使用 splice 來進行數據傳輸,比如需要處理大量網絡 sockets 的數據轉發的場景,則 pipe 的創建和銷毀的頻次也會隨之水漲船高,每調用一次 splice 都創建一對 pipe 管道描述符,并在隨后銷毀掉,對一個網絡系統來說是一個巨大的消耗。
對于這問題的解決方案,自然而然就會想到 -- 『復用』,比如大名鼎鼎的 HAProxy。
HAProxy 是一個使用 C 語言編寫的自由及開放源代碼軟件,其提供高可用性、負載均衡,以及基于 TCP 和 HTTP 的應用程序代理。它非常適用于那些有著極高網絡流量的 Web 站點。GitHub、Bitbucket、Stack Overflow、Reddit、Tumblr、Twitter 和 Tuenti 在內的知名網站,及亞馬遜網絡服務系統都在使用 HAProxy。
因為需要做流量轉發,可想而知,HAProxy 不可避免地要高頻地使用 splice,因此對 splice 帶來的創建和銷毀 pipe buffers 的開銷無法忍受,從而需要實現一個 pipe pool,復用 pipe buffers 減少系統調用消耗,下面我們來詳細剖析一下 HAProxy 的 pipe pool 的設計思路。
首先我們來自己思考一下,一個最簡單的 pipe pool 應該如何實現,最直接且簡單的實現無疑就是:一個單鏈表+一個互斥鎖。鏈表和數組是用來實現 pool 的最簡單的數據結構,數組因為數據在內存分配上的連續性,能夠更好地利用 CPU 高速緩存加速訪問,但是首先,對于運行在某個 CPU 上的線程來說,一次只需要取一個 pipe buffer 使用,所以高速緩存在這里的作用并不十分明顯;其次,數組不僅是連續而且是固定大小的內存區,需要預先分配好固定大小的內存,而且還要動態伸縮這個內存區,期間需要對數據進行搬遷等操作,增加額外的管理成本。鏈表則是更加適合的選擇,因為作為 pool 來說其中所有的資源都是等價的,并不需要隨機訪問去獲取其中某個特定的資源,而且鏈表天然是動態伸縮的,隨取隨棄。
鎖通常使用 mutex,在 Linux 上的早期實現是一種 sleep-waiting 也就是休眠等待的鎖,kernel 維護一個對所有進程/線程都可見的共享資源對象 mutex,多線程/進程的加鎖解鎖其實就是對這個對象的競爭。如果現在有 AB 兩個進程/線程,A 首先進入 kernel space 檢查 mutex,看看有沒有別的進程/線程正在占用它,搶占 mutex 成功之后則直接進入臨界區,B 嘗試進入臨界區的時候,檢測到 mutex 已被占用,就由運行態切換成睡眠態,等待該共享對象釋放,A 出臨界區的時候,需要再次進入 kernel space 查看有沒有別的進程/線程在等待進入臨界區,然后 kernel 會喚醒等待的進程/線程并在合適的時間把 CPU 切換給該進程/線程運行。由于最初的 mutex 是一種完全內核態的互斥量實現,在并發量大的情況下會產生大量的系統調用和上下文切換的開銷,在 Linux kernel 2.6.x 之后都是使用 futex (Fast Userspace Mutexes) 實現,也即是一種用戶態和內核態混用的實現,通過在用戶態共享一段內存,并利用原子操作讀取和修改信號量,在沒有競爭的時候只需檢查這個用戶態的信號量而無需陷入內核,信號量存儲在進程內的私有內存則是線程鎖,存儲在通過 mmap 或者 shmat 創建的共享內存中則是進程鎖。
即便是基于 futex 的互斥鎖,如果是一個全局的鎖,這種最簡單的 pool + mutex 實現在競爭激烈的場景下會有可預見的性能瓶頸,因此需要進一步的優化,優化手段無非兩個:降低鎖的粒度或者減少搶(全局)鎖的頻次。因為 pipe pool 中的資源本來就是全局共享的,也就是無法對鎖的粒度進行降級,因此只能是盡量減少多線程搶鎖的頻次,而這種優化常用方案就是在全局資源池之外引入本地資源池,對多線程訪問資源的操作進行錯開。
HAProxy 實現的 pipe pool 就是依據上述的思路進行設計的,將單一的全局資源池拆分成全局資源池+本地資源池。
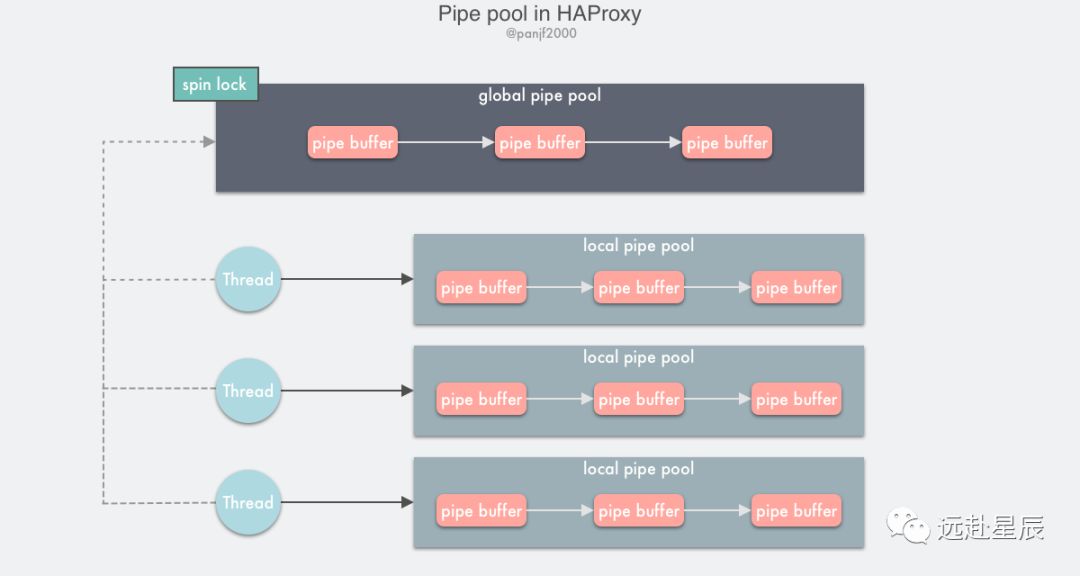
全局資源池利用單鏈表和自旋鎖實現,本地資源池則是基于線程私有存儲(Thread Local Storage, TLS)實現,TLS 是一種線程的私有的變量,它的主要作用是在多線程編程中避免鎖競爭的開銷。TLS 由編譯器提供支持,我們知道編譯 C 程序得到的 obj 或者鏈接得到的 exe,其中的 .text 段保存代碼文本,.data 段保存已初始化的全局變量和已初始化的靜態變量,.bss 段則保存未初始化的全局變量和未初始化的局部靜態變量。
而 TLS 私有變量則會存入 TLS 幀,也就是 .tdata 和 .tboss 段,與.data 和 .bss 不一樣的是,運行時程序不會直接訪問這些段,而是在程序啟動后,動態鏈接器會對這兩個段進行動態初始化 (如果有聲明 TLS 的話),之后這兩個段不會再改變,而是作為 TLS 的初始鏡像保存起來。每次啟動一個新線程的時候都會將 TLS 塊作為線程堆棧的一部分進行分配并將初始的 TLS 鏡像拷貝過來,也就是說最終每個線程啟動時 TLS 塊中的內容都是一樣的。
HAProxy 的 pipe pool 實現原理:
- 聲明 thread_local 修飾的一個單鏈表,節點是 pipe buffer 的兩個管道描述符,那么每個需要使用 pipe buffer 的線程都會初始化一個基于 TLS 的單鏈表,用以存儲 pipe buffers;
- 設置一個全局的 pipe pool,使用自旋鎖保護。
每個線程去取 pipe 的時候會先從自己的 TLS 中去嘗試獲取,獲取不到則加鎖進入全局 pipe pool 去找;使用 pipe buffer 過后將其放回:先嘗試放回 TLS,根據一定的策略計算當前 TLS 的本地 pipe pool 鏈表中的節點是否已經過多,是的話則放到全局的 pipe pool 中去,否則直接放回本地 pipe pool。
HAProxy 的 pipe pool 實現雖然只有短短的 100 多行代碼,但是其中蘊含的設計思想卻包含了許多非常經典的多線程優化思路,值得細讀。
pipe pool in Go
受到 HAProxy 的 pipe pool 的啟發,我嘗試為 Golang 的 io 標準庫里底層的 splice 實現了一個 pipe pool,不過熟悉 Go 的同學應該知道 Go 有一個 GMP 并發調度器,提供了強大并發調度能力的同時也屏蔽了操作系統層級的線程,所以 Go 沒有提供類似 TLS 的機制,倒是有一些開源的第三方庫提供了類似的功能,比如 gls,雖然實現很精巧,但畢竟不是官方標準庫而且會直接操作底層堆棧,所以其實也并不推薦在線上使用。
一開始,因為 Go 缺乏 TLS 機制,所以我提交的第一版 go pipe pool 就是一個很簡陋的單鏈表+全局互斥鎖的實現,因為這個方案在進程的生命周期中并不會去釋放資源池里的 pipe buffers(實際上 HAProxy 的 pipe pool 也會有這個問題),也就是說那些未被釋放的 pipe buffers 將一直存在于用戶進程的生命周期中,直到進程結束之后才由 kernel 進行釋放,這明顯不是一個令人信服的解決方案,結果不出意料地被 Go team 的核心大佬 Ian (委婉地)否決了,于是我馬上又想了兩個新的方案:
基于這個現有的方案加上一個獨立的 goroutine 定時去掃描 pipe pool,關閉并釋放 pipe buffers;
基于 sync.Pool 標準庫來實現 pipe pool,并利用 runtime.SetFinalizer 來解決定期釋放 pipe buffers 的問題。
第一個方案需要引入額外的 goroutine,并且該 goroutine 也為這個設計增加了不確定的因素,而第二個方案則更加優雅,因為利用了 Go 的 runtime 來解決定時釋放 pipe buffers 的問題,實現上更加的優雅,所以很快,我和其他 reviewers 就達成一致決定采用第二個方案。
sync.Pool 是 Go 語言提供的臨時對象緩存池,一般用來復用資源對象,減輕 GC 壓力,合理使用它能對程序的性能有顯著的提升。很多頂級的 Go 開源庫都會重度使用 sync.Pool 來提升性能,比如 Go 領域最流行的第三方 HTTP 框架 fasthttp 就在源碼中大量地使用了 sync.Pool,并且收獲了比 Go 標準 HTTP 庫高出近 10 倍的性能提升(當然不僅僅靠這一個優化點,還有很多其他的),fasthttp 的作者 Aliaksandr Valialkin 作為 Go 領域的大神(Go contributor,給 Go 貢獻過很多代碼,也優化過 sync.Pool),在 fasthttp 的 best practices 中極力推薦使用 sync.Pool,所以 Go 的 pipe pool 使用 sync.Pool 來實現也算是水到渠成。
sync.Pool 底層原理簡單來說就是:私有變量+共享雙向鏈表。
Google 了一張圖來展示 sync.Pool 的底層實現:
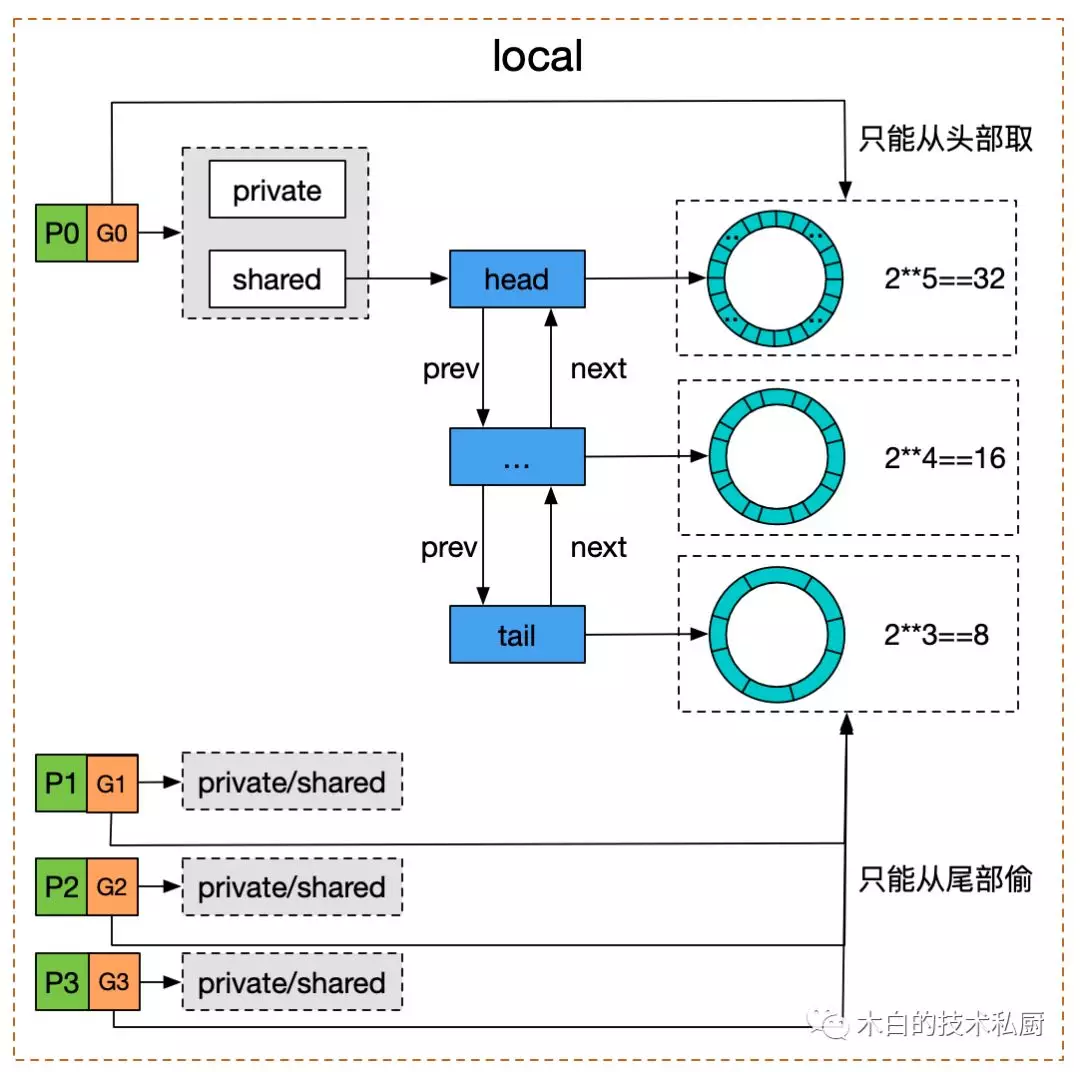
在某個 P 上的 goroutine 在從 sync.Pool 嘗試獲取緩存的對象時,內部會先嘗試去取本地私有變量 private,如果沒有則去 shared 雙向鏈表表頭取,該鏈表可以被其他 P 消費,鏈表的節點是一個環形隊列,復用內存,共享雙向鏈表在 Go 1.13 之前使用互斥鎖 sync.Mutex 保護,Go 1.13 之后改用 atomic CAS 實現無鎖并發,原子操作無鎖并發適用于那些臨界區極小的場景,性能會被互斥鎖好很多,正好很貼合 sync.Pool 的場景,因為存取臨時對象的操作是非常快速的,如果使用 mutex,則在競爭時需要掛起那些搶鎖失敗的 goroutines 到 wait queue,等后續解鎖之后喚醒并放入 run queue,等待調度執行,還不如直接忙輪詢等待,反正很快就能搶占到臨界區。
sync.Pool 基于 victim cache 會保證緩存在其中的資源對象最多不超過兩個 GC 周期就會被回收掉。
因此我使用了 sync.Pool 來實現 Go 的 pipe pool,把 pipe 的管道文件描述符對存儲在其中,并發之時進行復用,而且會定期自動回收,但是還有一個問題,當 sync.Pool 中的對象被回收的時候,只是回收了管道的文件描述符對,也就是兩個整型的 fd 數,并沒有在操作系統層面關閉掉 pipe 管道。
因此,還需要有一個方法來關閉 pipe 管道,這時候可以利用 runtime.SetFinalizer 來實現。這個方法其實就是對一個即將放入 sync.Pool 的資源對象設置一個回調函數,當 Go 的 三色標記 GC 算法檢測到 sync.Pool 中的對象已經變成白色(unreachable,也就是垃圾)并準備回收時,如果該白色對象已經綁定了一個關聯的回調函數,則 GC 會先解綁該回調函數并啟動一個獨立的 goroutine 去執行該回調函數,因為回調函數使用該對象作為函數入參,也就是會引用到該對象,那么就會導致該對象重新變成一個 reachable 的對象,所以在本輪 GC 中不會被回收,從而使得這個對象的生命得以延續一個 GC 周期。
在每一個 pipe buffer 放回 pipe pool 之前通過 runtime.SetFinalizer 指定一個回調函數,在函數中使用系統調用關閉管道,則可以利用 Go 的 GC 機制定期真正回收掉 pipe buffers,從而實現了一個優雅的 pipe pool in Go,相關的 commits 如下:
- internal/poll: implement a pipe pool for splice() call
- internal/poll: fix the intermittent build failures with pipe pool
- internal/poll: ensure that newPoolPipe doesn't return a nil pointer
- internal/poll: cast off the last reference of SplicePipe in test
為 Go 的 splice 引入 pipe pool 之后,對性能的提升效果如下:
- goos: linux
- goarch: amd64
- pkg: internal/poll
- cpu: AMD EPYC 7K62 48-Core Processor
- name old time/op new time/op delta
- SplicePipe-8 1.36µs ± 1% 0.02µs ± 0% -98.57% (p=0.001 n=7+7)
- SplicePipeParallel-8 747ns ± 4% 4ns ± 0% -99.41% (p=0.001 n=7+7)
- name old alloc/op new alloc/op delta
- SplicePipe-8 24.0B ± 0% 0.0B -100.00% (p=0.001 n=7+7)
- SplicePipeParallel-8 24.0B ± 0% 0.0B -100.00% (p=0.001 n=7+7)
- name old allocs/op new allocs/op delta
- SplicePipe-8 1.00 ± 0% 0.00 -100.00% (p=0.001 n=7+7)
- SplicePipeParallel-8 1.00 ± 0% 0.00 -100.00% (p=0.001 n=7+7)
直接創建 pipe buffer 和利用 pipe pool 復用相比,耗時下降在 99% 以上,內存使用則是下降了 100%。
當然,這個 benchmark 只是一個純粹的存取操作,并未加入具體的業務邏輯,所以是一個非常理想化的壓測,不能完全代表生產環境,但是 pipe pool 的引入對使用 Go 的 io 標準庫并基于 splice 進行高頻的零拷貝操作的性能必定會有數量級的提升。
這個特性最快應該會在今年下半年的 Go 1.17 版本發布,到時就可以享受到 pipe pool 帶來的性能提升了。
小結
通過給 Go 語言實現一個 pipe pool,期間涉及了多種并發、同步的優化思路,我們再來歸納總結一下。
- 資源復用,提升并發編程性能最有效的手段一定是資源復用,也是最立竿見影的優化手段。
- 數據結構的選取,數組支持 O(1) 隨機訪問并且能更好地利用 CPU cache,但是這些優勢在 pool 的場景下并不明顯,因為 pool 中的資源具有等價性和單個存取(非批量)操作,數組需要預先分配固定內存并且伸縮的時候會有額外的內存管理負擔,鏈表隨取隨棄,天然支持動態伸縮。
- 全局鎖的優化,兩種思路,一種是根據資源的特性嘗試對鎖的粒度進行降級,一種是通過引入本地緩存,嘗試錯開多線程對資源的訪問,減少競爭全局鎖的頻次。
- 利用語言的 runtime,像 Go、Java 這類自帶一個龐大的 GC 的編程語言,在性能上一般比不過 C/C++/Rust 這種無 GC 的語言,但是凡事有利有弊,自帶 runtime 的語言也具備獨特的優勢,比如 HAProxy 的 pipe pool 是 C 實現的,在進程的生命周期中創建的 pipe buffers 會一直存在占用資源(除非主動關閉,但是很難準確控制時機),而 Go 實現的 pipe pool 則可以利用自身的 runtime 進行定期的清理工作,進一步減少資源占用。
參考&延伸
sync.Pool
pipe pool in HAProxy
internal/poll: implement a pipe pool for splice() call
internal/poll: fix the intermittent build failures with pipe pool
internal/poll: ensure that newPoolPipe doesn't return a nil pointer
internal/poll: cast off the last reference of SplicePipe in test
Use Thread-local Storage to Reduce Synchronization
ELF Handling For Thread-Local Storage
References
[1] 《Linux I/O 原理和 Zero-copy 技術全面揭秘》: https://strikefreedom.top/linux-io-and-zero-copy
[2] gls: https://github.com/jtolio/gls
[3] fasthttp: https://github.com/valyala/fasthttp
[4] best practices: https://github.com/valyala/fasthttp#fasthttp-best-practices
[5] internal/poll: implement a pipe pool for splice() call: https://github.com/golang/go/commit/643d240a11b2d00e1718b02719707af0708e7519
[6] internal/poll: fix the intermittent build failures with pipe pool: https://github.com/golang/go/commit/6382ec1aba1b1c7380cb525217c1bd645c4fd41b
[7] internal/poll: ensure that newPoolPipe doesn't return a nil pointer: https://github.com/golang/go/commit/8b859be9c3fd1068b659afa1db76dadb210c63de
[8] internal/poll: cast off the last reference of SplicePipe in test: https://github.com/golang/go/commit/832c70e33d8265116f0abce436215b8e9ee4bb08
[9] sync.Pool: https://github.com/golang/go/blob/master/src/sync/pool.go
[10] pipe pool in HAProxy: https://github.com/haproxy/haproxy/blob/v2.4.0/src/pipe.c
[11] internal/poll: implement a pipe pool for splice() call: https://github.com/golang/go/commit/643d240a11b2d00e1718b02719707af0708e7519
[12] internal/poll: fix the intermittent build failures with pipe pool: https://github.com/golang/go/commit/6382ec1aba1b1c7380cb525217c1bd645c4fd41b
[13] internal/poll: ensure that newPoolPipe doesn't return a nil pointer: https://github.com/golang/go/commit/8b859be9c3fd1068b659afa1db76dadb210c63de
[14] internal/poll: cast off the last reference of SplicePipe in test: https://github.com/golang/go/commit/832c70e33d8265116f0abce436215b8e9ee4bb08
[15] Use Thread-local Storage to Reduce Synchronization: https://software.intel.com/content/www/us/en/develop/articles/use-thread-local-storage-to-reduce-synchronization.html
[16] ELF Handling For Thread-Local Storage: https://akkadia.org/drepper/tls.pdf


























