老大讓我設計億級系統的Redis緩存...
圖片來自 Pexels
工程中引入 Redis Client 二方包,初始化一個 Bean 實例 RedisTemplate ,一切搞定,so easy。
如果是幾十、幾百并發的業務場景,緩存設計可能并不需要考慮那么多,但如果是億級的系統呢?
緩存知識圖譜
首先,先了解緩存知識圖譜。
早期的緩存用于加速 CPU 數據交換的 RAM。隨著互聯網的快速發展,緩存的應用更加寬泛,用于數據高速交換的存儲介質都稱之為緩存。
使用緩存時,我們要關注哪些指標?緩存有哪些應用模式?以及緩存設計時有哪些 Tip 技巧?
一圖勝千言,如下:
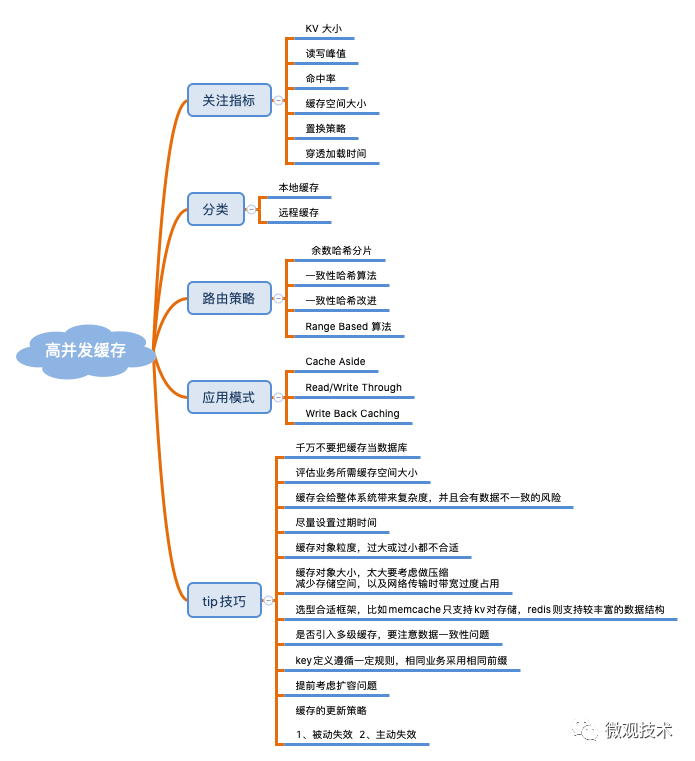
緩存七大經典問題
緩存在使用過程不可避免會遇到一些問題,對于高頻的問題我們大概歸為了 7 類。具體內容下面我們一一道來。
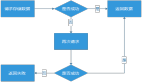
①緩存集中失效
當業務系統查詢數據時,首先會查詢緩存,如果緩存中數據不存在,然后查詢 DB 再將數據預熱到 Cache 中,并返回。緩存的性能比 DB 高 50~100 倍以上。
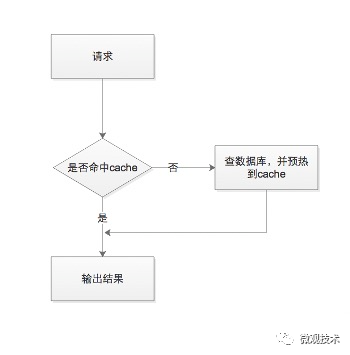
很多業務場景,如:秒殺商品、微博熱搜排行、或者一些活動數據,都是通過跑任務方式,將 DB 數據批量、集中預熱到緩存中,緩存數據有著近乎相同的過期時間。
當過這批數據過期時,會一起過期,此時,對這批數據的所有請求,都會出現緩存失效,從而將壓力轉嫁到 DB,DB 的請求量激增,壓力變大,響應開始變慢。
那么有沒有解呢?當然有了。我們可以從緩存的過期時間入口,將原來的固定過期時間,調整為過期時間=基礎時間+隨機時間,讓緩存慢慢過期,避免瞬間全部過期,對 DB 產生過大壓力。
②緩存穿透
不是所有的請求都能查到數據,不論是從緩存中還是 DB 中。
假如黑客攻擊了一個論壇,用了一堆肉雞訪問一個不存的帖子 id。按照常規思路,每次都會先查緩存,緩存中沒有,接著又查 DB,同樣也沒有,此時不會預熱到 Cache 中,導致每次查詢,都會 cache miss。
由于 DB 的吞吐性能較差,會嚴重影響系統的性能,甚至影響正常用戶的訪問。
解決方案如下:
- 方案一:查存 DB 時,如果數據不存在,預熱一個特殊空值到緩存中。這樣,后續查詢都會命中緩存,但是要對特殊值,解析處理。
- 方案二:構造一個 BloomFilter 過濾器,初始化全量數據,當接到請求時,在 BloomFilter 中判斷這個 key 是否存在,如果不存在,直接返回即可,無需再查詢緩存和 DB。
③緩存雪崩
緩存雪崩是指部分緩存節點不可用,進而導致整個緩存體系甚至服務系統不可用的情況。
分布式緩存設計一般選擇一致性 Hash,當有部分節點異常時,采用 rehash 策略,即把異常節點請求平均分散到其他緩存節點。
但是,當較大的流量洪峰到來時,如果大流量 key 比較集中,正好在某 1~2 個緩存節點,很容易將這些緩存節點的內存、網卡過載,緩存節點異常 Crash。
然后這些異常節點下線,這些大流量 key 請求又被 rehash 到其他緩存節點,進而導致其他緩存節點也被過載 Crash,緩存異常持續擴散,最終導致整個緩存體系異常,無法對外提供服務。
解決方案:
- 方案一:增加實時監控,及時預警。通過機器替換、各種故障自動轉移策略,快速恢復緩存對外的服務能力
- 方案二:緩存增加多個副本,當緩存異常時,再讀取其他緩存副本。為了保證副本的可用性,盡量將多個緩存副本部署在不同機架上,降低風險。
④緩存熱點
對于突發事件,大量用戶同時去訪問熱點信息,這個突發熱點信息所在的緩存節點就很容易出現過載和卡頓現象,甚至 Crash,我們稱之為緩存熱點。
這個在新浪微博經常遇到,某大 V 明星出軌、結婚、離婚,瞬間引發數百千萬的吃瓜群眾圍觀,訪問同一個 key,流量集中打在一個緩存節點機器,很容易打爆網卡、帶寬、CPU 的上限,最終導致緩存不可用。
解決方案:
- 首先能先找到這個熱 key 來,比如通過 Spark 實時流分析,及時發現新的熱點 key。
- 將集中化流量打散,避免一個緩存節點過載。由于只有一個 key,我們可以在 key 的后面拼上有序編號,比如 key#01、key#02。。。key#10 多個副本,這些加工后的 key 位于多個緩存節點上。
- 每次請求時,客戶端隨機訪問一個即可。
可以設計一個緩存服務治理管理后臺,實時監控緩存的 SLA,并打通分布式配置中心,對于一些 hot key 可以快速、動態擴容。
⑤緩存大 Key
當訪問緩存時,如果 key 對應的 value 過大,讀寫、加載很容易超時,容易引發網絡擁堵。
另外緩存的字段較多時,每個字段的變更都會引發緩存數據的變更,頻繁的讀寫,導致慢查詢。
如果大 key 過期被緩存淘汰失效,預熱數據要花費較多的時間,也會導致慢查詢。
所以我們在設計緩存的時候,要注意緩存的粒度,既不能過大,如果過大很容易導致網絡擁堵;也不能過小,如果太小,查詢頻率會很高,每次請求都要查詢多次。
解決方案:
- 方案一:設置一個閾值,當 value 的長度超過閾值時,對內容啟動壓縮,降低 kv 的大小。
- 方案二:評估大 key 所占的比例,由于很多框架采用池化技術,如:Memcache,可以預先分配大對象空間。真正業務請求時,直接拿來即用。
- 方案三:顆粒劃分,將大 key 拆分為多個小 key,獨立維護,成本會降低不少。
- 方案四:大 key 要設置合理的過期時間,盡量不淘汰那些大 key。
⑥緩存數據一致性
緩存是用來加速的,一般不會持久化儲存。所以,一份數據通常會存在 DB 和緩存中,由此會帶來一個問題,如何保證這兩者的數據一致性。另外,緩存熱點問題會引入多個副本備份,也可能會發生不一致現象。
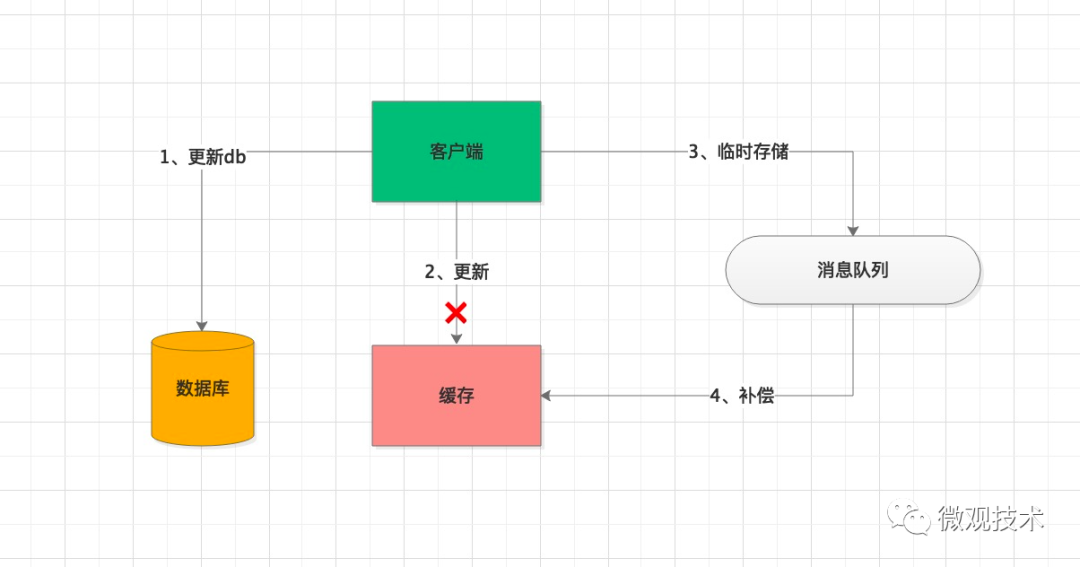
解決方案:
方案一:當緩存更新失敗后,進行重試,如果重試失敗,將失敗的 key 寫入 MQ 消息隊列,通過異步任務補償緩存,保證數據的一致性。
方案二:設置一個較短的過期時間,通過自修復的方式,在緩存過期后,緩存重新加載最新的數據。
⑦數據并發競爭預熱
互聯網系統典型的特點就是流量大,一旦緩存中的數據過期、或因某些原因被刪除等,導致緩存中的數據為空,大量的并發線程請求(查詢同一個 key)就會一起并發查詢數據庫,數據庫的壓力陡然增加。
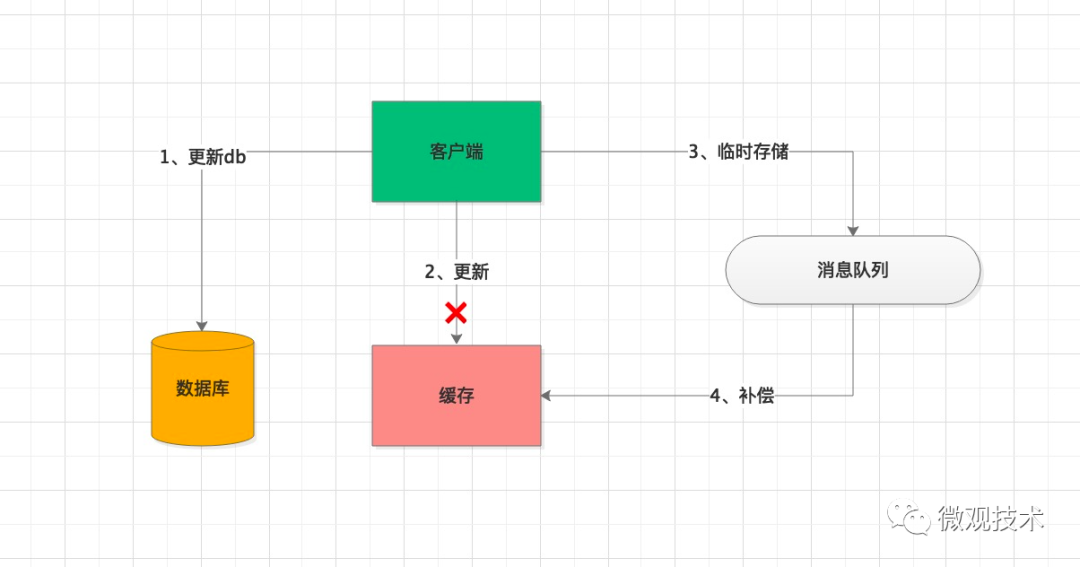
如果請求量非常大,全部壓在數據庫,可能把數據庫壓垮,進而導致整個系統的服務不可用。
解決方案:
方案一:引入一把全局鎖,當緩存未命中時,先嘗試獲取全局鎖,如果拿到鎖,才有資格去查詢 DB,并將數據預熱到緩存中。
雖然,client 端發起的請求非常多,但是由于拿不到鎖,只能處于等待狀態,當緩存中的數據預熱成功后,再從緩存中獲取。
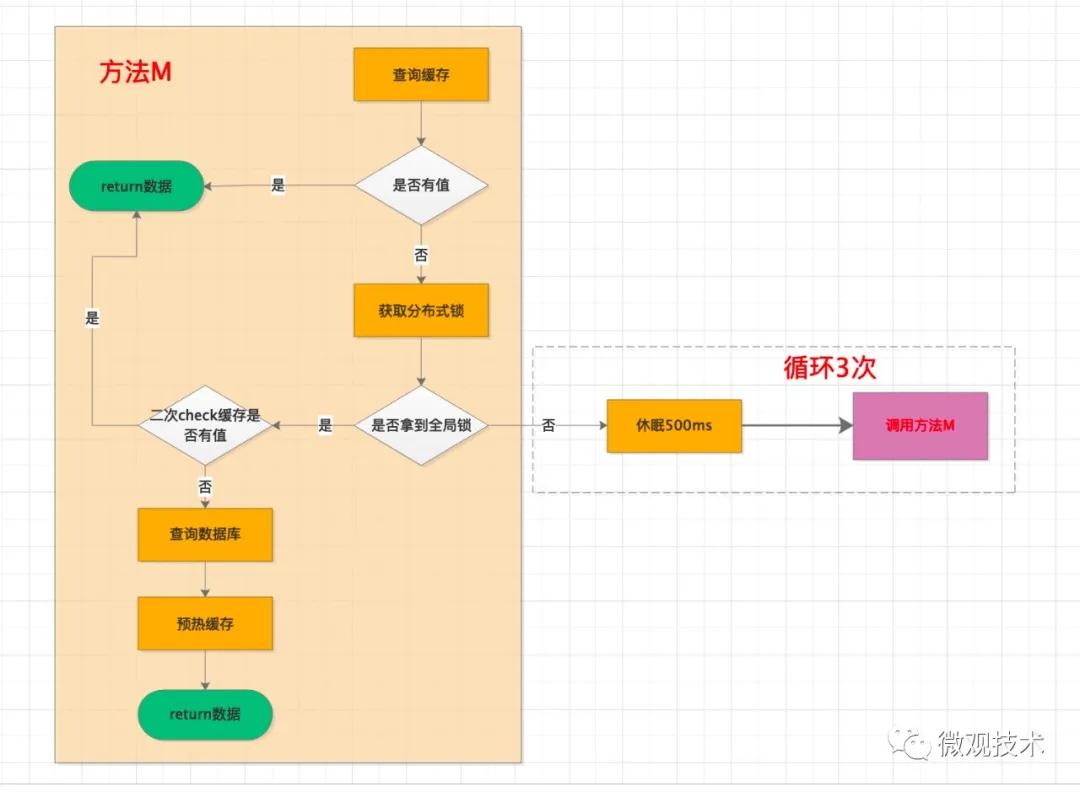
為了便于理解,簡單畫了個流程圖。這里面特別注意一個點,由于有一個并發時間差,所以會有一個二次 check 緩存是否有值的校驗,防止緩存預熱重復覆蓋。
方案二:緩存數據創建多個備份,當一個過期失效后,可以訪問其他備份。
寫在最后
緩存設計時,有很多技巧,優化手段也是千變萬化,但是我們要抓住核心要素。那就是,讓訪問盡量命中緩存,同時保持數據的一致性。
作者:TomGE
簡介:前阿里架構師,出過專利,競賽拿過獎,,負責過電商交易、社區、營銷、金融等業務,多年團隊管理經驗。
編輯:陶家龍
出處:轉載自公眾號微觀技術(ID:weiguanjishu)