億級高性能通知系統實踐
在一個公司中,消息通知系統是不可或缺的一部分,每個團隊都可能開發了一套獨自的消息通知組件,隨著公司業務團隊的日益增長,維護繁瑣、排查問題復雜、開發成本等問題就會凸顯出來。(例如我們的企微群通知,由于消息內容不同模板不同,一個項目內使用的組件就有3種,還不包含其他通知部分。)
基于這樣的背景,我們就迫切需要開發一套通用的消息通知系統。那么如何高效地處理大量的消息請求以及服務穩定性的保障,成為了開發者需要面對的重要挑戰。本文將探討如何構建高性能的消息通知系統。
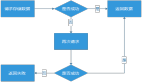
1 服務劃分
 圖片
圖片
- 配置層: 主要是后臺管理系統,做一些發送的配置,包括請求方式、請求地址、預期響應結果、通道綁定、通道選擇、重試策略以及結果查詢等功能。
- 接口層:對外提供服務的方式,支持RPC與MQ的方式,后續如需Http或其他方式可以擴展添加。
- 基礎服務層:業務核心層,包括消息的首次發送與重試發送,消息通道的路由選擇以及服務的調用包裝。其中可以看到正常與異常的服務發送執行器,通過這樣的設計可以對異常服務的發送與正常服務發送進行隔離,避免異常服務的發送對正常服務造成影響。比如請求某一消息通道的接口耗時長了,導致請求該通道的資源占用時間較長,從而影響的正常服務的請求調用。執行器的選擇是根據路由器進行路由的,其中路由策略包括配置的路由策略以及動態服務異常自發現路由策略。所謂正常服務與異常服務指的是調用的下游服務方是否正常,比如我們發送支付成功的消息或調用第三方短信服務,如果在一段時間響應都比較慢或直接失敗等我們就可以判定為異常服務。
- 通用組件層:主要是對一些通用組件的封裝。
- 存儲層:包括緩存層與持久化層,緩存層主要是緩存配置的發送策略、重試策略以及其他一些需要進行緩存的內容,持久化層主要是ES與MySQL,MySQL存儲消息的發送記錄以及配置,ES主要存儲消息的發送記錄供用戶查詢。
2 系統設計
2.1 首次消息發送
 圖片
圖片
在接受消息發送請求的時候,一般會通過 RPC 服務請求和 MQ 消息消費進行處理,這兩種方式各有優缺點,RPC 這種方式,我們無需考慮消息的丟失問題,MQ 可以實現異步解耦、削峰填谷。
2.1.1 冪等性的處理
為了防止接收到同樣的消息內容進行發送處理,我們通常會做一些冪等性的設計。冪等性的判斷有很多手段,比如先加鎖再查詢或利用數據庫的唯一主鍵等來實現,但其實在我們消息量很大的時候,查數據庫就有點慢了。因為發送消息的這種場景,重復消息一般在短時間內發生的,一般不會有跨很多天來一筆已經發送過的消息,所以可以設計利用 Redis 來實現,先判斷是否有相同的Redis Key,再判斷消息內容是否相同,有可能相同的Redis Key,發送不同的消息內容,這種是允許的,具體看對應的業務需求。
private boolean isDuplicate(MessageDto messageDto) {
String redisKey = getRedisKey(messageDto);
boolean isDuplicate = false;
try {
if (!RedisUtils.setNx(redisKey, messageDto, 30*60L)) {
isDuplicate = true;
}
if (isDuplicate) {
MessageDto oldDTO = RedisUtils.getObject(redisKey);
if (Objects.equals(messageDto,oldDTO)) {
log.info("消息重復了");
} else {
isDuplicate = false;
}
}
} catch (Exception e) {
isDuplicate = false;
}
return isDuplicate;
}2.1.2 問題服務動態發現器
上文提到路由器中的路由策略包括配置的路由策略和動態服務異常自發現路由策略,其中動態服務異常自發現路由策略核心在于服務異常自發現,核心是依據問題服務動態發現器實現的,當我們發現某一個消息通道服務異常時可以自動路由采用異常通知執行器執行。
我們主要是借助sentinel的API在各自節點JVM內實現的,針對設置的時間窗口內請求的總次數和失敗的總次數進行統計,達到設定值,就認為請求的服務有問題了,認定其為異常服務。核心主要是以下兩個方法,其中loadExecuteHandlerRules方法主要是對流控規則的設定,我們可以通過Apollo或Nacos進行動態的修改,judge方法是對請求和失敗的攔截,判斷允許正常訪問,一旦攔截后就認為是異常服務,在內存中進行標記記錄,后續請求通過異常執行器執行處理。
當我們看到這兒會不會有疑問,問題服務在啥時候會恢復正常呢,難道服務出現一次問題,就一直被認定為問題服務了?當時不是的,我們也設計了類似熔斷器那樣的自動恢復功能,在判斷為問題服務后會經過一段時間的靜默期,靜默期內所有對該服務的請求都走異常通知器的執行流程,當靜默期過后,此時到達了半熔斷期,就是如果訪問正常的次數達到一定值后,就會恢復為正常。
//加載執行器的規則 durationInSec 時間窗口長度 requestCount 請求總量 failCount失敗總量
public void loadExecuteHandlerRules(Long durationInSec,Long requestCount,Long failCount) {
List<ParamFlowRule> rules = new ArrayList<>();
//REQUEST_RESOURCE 請求資源 可自定義
rules.add(ofParamFlowRule(REQUEST_RESOURCE, requestCount, durationInSec));
//REQUEST_RESOURCE 失敗資源 可自定義
rules.add(ofParamFlowRule(FAIl_RESOURCE, failCount, durationInSec));
ParamFlowRuleManager.loadRules(rules);
}
public ParamFlowRule ofParamFlowRule(String resource, Long failCount, Long durationInSec) {
ParamFlowRule rule = new ParamFlowRule();
rule.setResource(FAIl_RESOURCE);
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(failCount);
rule.setDurationInSec(durationInSec);
rule.setParamIdx(0);
return rule;
}//key 請求的標識key,可以是對應某一服務的標識,reqSuc 請求是否成功,false是失敗,true是成功
public static boolean judge(String key, boolean reqSuc) {
return isBlock(REQUEST_RESOURCE, reqSuc, key) && isBlock(FAIl_RESOURCE, reqSuc, key);
}
public Boolean isBlock(String resource, boolean reqSuc, String key) {
boolean block = false;
Entry failEntry = null;
try {
failEntry = entry(resource, EntryType.IN, reqSuc ? 0 : 1, key);
} catch (BlockException e) {
block = true;
} finally {
if (failEntry != null) {
failEntry.exit();
}
}
return block;
}2.1.3 sentinel 滑動窗口的實現原理(環形數組)
 圖片
圖片
根據傳入的時間窗口大小和數量,計算數組的數量,數組的下標就是windowsId,windowsStart是每個數組的起始時間值。
例如:統計 1s 的請求量,設置兩個窗口,那么每個窗口對應的id 就是0、1,相應的時間范圍就是 0m-500ms,500ms-1000ms。如果當前時間是 700ms,那么對應的窗口 id=(700/500)%2=0, 對應的 windowStart=700-(700%500)=200,對應的起始就是 id 為 0 的窗口;如果當前時間是 1200ms,對應的窗口 id=(1200/500)%2=0;對應的 windowStart=1200-(1200%500)=1000 大于 id=0 的起始時間,重置 id 為 0 的窗口起始值,id=0 的位置不變。
2.1.4 線程池的動態調整
消息處理完成后,利用線程池進行異步發送,線程池分為正常服務的線程池和異常服務的線程池,至于為啥設計不同的線程池,我們在下面穩定性設計方面闡述。線程池核心參數的設定一般會根據任務類型和 CPU 核數進行一個初始化的設定,后續我們一般會壓測來動態的調整來滿足我們的目標。那么我們怎樣可以設計一個可以動態調整的線程池呢?
一般我們可以通過 Apollo 或 Nacos 等統一配置來動態修改線程池的參數,但是線程池的阻塞隊列長度是不允許修改的,當然我們可以自己自定義一個隊列來實現這樣的功能。接下來我們講述的這種設計,是不用通過自定義阻塞隊列的方式去實現的。
ThreadPoolExecutor pool = new ThreadPoolExecutor(poolSize, poolSize,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());我們直接定義了一個無界的線程池,核心線程數和最大線程數相等,而且用的是默認的丟棄策略,那么就有疑問了,這樣的線程池我們在使用的時候,會有內存溢出和消息的丟失風險,別著急,我們繼續往下看。
Notifier notifier = getNotifier();
if (!notifier.isBusy()) {
notifier.execute(msgContent);
}
public boolean isBusy() {
return notifyPool.getQueue().size() >= config.getMaxHandlerSize() * 2;
}在每次添加任務的時候會判斷線程池隊列中的任務是否達到設定的最大值,如果達到就不會繼續添加了,當前線程池處于繁忙狀態了,后續可以利用 MQ 落庫,之后通過重試任務進行發送了,也保證了永遠不會觸發線程池的拒絕策略。
2.2 重試消息發送
 圖片
圖片
部分消息因為系統達到瓶頸處理不過來或某些消息發送失敗需要重試,這些消息都可以通過任務重試來進行處理,當然利用這種方式也可以實現延遲消息的發送。
實現這種重試的消息機制可以利用分布式定時任務調度框架,一般為了提高重試效率,會采用分片廣播這種方式,自己做好消息重復發送的控制,我們也可以利用調度線程池來實現。
public void init() {
ScheduledExecutorService scheduledService = new ScheduledThreadPoolExecutor(taskRepository.size());
for (Map.Entry<String, TaskHandler> entry : taskRepository.entrySet()) {
final String taskName = entry.getKey();
final TaskHandler handler = entry.getValue();
scheduledService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
// 是否繁忙判斷
if (handler.isBusy()) {
return;
}
handleTask(taskName, handler);
} catch (Throwable e) {
logger.error(taskName + " task hanlder fail!", e);
}
}
}, 30, 5, TimeUnit.SECONDS);
}
}每次進行任務撈取進行調度時,會首先判斷下當前 handler 是否繁忙,其實就是重試不同類型任務的線程池資源是否充足,如果不充足的話,即使撈取出來,也一直是排隊等待。
public void handTask(String taskName, TaskHandler handler) {
Lock lock = LockFactory.getLock(taskName);
List<ScheduleTaskEntity> taskList = null;
try {
if (lock.tryLock()) {
taskList = getTaskList(taskName, handler);
}
} finally {
lock.unlock();
}
if (taskList == null) return;
handler.handleData(taskList);
}為了防止不同的節點處理相同的任務進行了加鎖控制,每次撈取的任務量是根據不同任務 handler 設置的量來確定的,撈取完成后發送至 MQ,然后采用線程池進行發送處理。
2.2.1 ES與MySQL數據同步
由于發送消息的數據量,后臺在進行數據查詢時主要是通過ES進行查詢處理的,這就涉及到數據庫數據與ES數據一致性的問題。當然也可以采用分庫分表或寬表等技術進行處理,分庫分表對一些非分片鍵的查詢可能不太友好。
 圖片
圖片
ES 更新完成后修改數據庫狀態為更新完成狀態,若此時通知記錄表還有更新,就會將同步狀態初始化,若修改數據庫為init先于同步完成后的更新就會出現數據不一致的問題,所以每次同步時攜帶上數據庫中的update_time,大于等于db中的update_time才會更新完成(其實update_time就是一個版本號)。
 圖片
圖片
ES按月滾動建立索引,每月新建立的索引,標簽都是hot,新增的數據都會放入hot節點上進行存儲,到了第二月,通過定時任務將上月索引的tag修改為cold,ES集群就會自動將數據遷移到標簽為cold節點上(cold節點的性能一般配置都比較低,對性能要求并不高)。
3 穩定性的保障
上述一系列的設計是圍繞高性能進行考慮的,當然在穩定性方面我們也不能忽略,下述幾方面也是我們在穩定性方面的考慮。
3.1 流量突增
面對流量突增時做了兩層降級。當流量緩慢增大時,線程池繁忙后,利用MQ做了一次流量削峰、異步落庫,后續定時任務處理發送,發送的延時時間是0s;當流量陡增,用sentinel進行判斷,不經任何判斷直接MQ削峰落庫,后續消費是延遲消費的,待資源空閑才進行撈取處理。
3.2 問題服務的資源隔離
首先我們想想為啥要做問題服務的隔離呢,不做會有什么后果呢?設想一下如果不隔離,問題服務與正常服務采用同一線程池資源進行處理,當問題服務請求請求耗時時間較長,線程釋放慢,會導致大量正常服務的消息不能及時進行處理,這樣就會導致問題服務影響到正常服務的消息處理,所以才需要做問題服務與正常服務的資源艙壁隔離。
3.3 第三方服務的保護
正常的第三方服務一般都會做限流降級設置,防止服務被擊垮。如果一些開發水平欠缺的服務沒有做,就需要我們進行考慮了,一方面不能因為我們的請求量較大,影響到別人服務,另一方面,我們的服務不能因為第三方服務而引發問題,所以通常我們需要考慮進行熔斷處置。
3.4 中間件的容錯
在我們使用各種中間件時,也應該考慮的中間件的問題。比如公司MQ需要進行擴容升級,會使MQ宕機數秒,針對這種問題的容錯,在進行開發時也應盡可能的考慮設計到。
3.5 完善的監控體系
我們也應該建立完善的監控系統,來保障服務的穩定運行,能在問題擴散之前及時發現處理,能在問題發生后進行快速的處理,能在后期優化處理時提供輔助依據。
3.6 服務的雙活部署、彈性擴縮容
在運維層面,也應該考慮服務不同機房的部署,以保證服務的可用性,為了應對流量的變化同時也基于成本的考慮,也可以基于服務的綜合指標進行彈性擴縮容。
4 總結
關于作者趙培龍 采貨俠JAVA開發工程師