大腦模擬NLP,高德納獎(jiǎng)得主:神經(jīng)元集合演算用于句子解析
上周,Google Research 舉辦了一個(gè)關(guān)于深度學(xué)習(xí)概念理解的在線研討會(huì)。研討會(huì)上,獲獎(jiǎng)的計(jì)算機(jī)科學(xué)家和神經(jīng)科學(xué)家發(fā)表了演講,討論了深度學(xué)習(xí)和神經(jīng)科學(xué)的新發(fā)現(xiàn)如何幫助創(chuàng)造更好的人工智能系統(tǒng)。
盡管所有的演講和討論都非常具有價(jià)值,但有一個(gè)特別突出的話題值得分享:世界頂尖計(jì)算機(jī)科學(xué)理論學(xué)家、哥德爾獎(jiǎng)和高德納獎(jiǎng)獲得者、哥倫比亞大學(xué)計(jì)算機(jī)科學(xué)教授、Christos Papadimitriou 關(guān)于「大腦中單詞表征」的演講。
在演講中,Papadimitrio 討論了我們對(duì)大腦中信息處理機(jī)制日益加深的理解,如何有助于創(chuàng)建在理解和參與對(duì)話方面更加魯棒的算法。具體而言,他提出了一個(gè)簡單而高效的模型,該模型解釋了在大腦的不同區(qū)域如何相互溝通,來解決認(rèn)知問題。
「現(xiàn)在發(fā)生的事情,也許是世界上最偉大的奇跡之一。」Papadimitriou 說道,這里是指他如何與觀眾進(jìn)行交流。大腦將結(jié)構(gòu)化的知識(shí)轉(zhuǎn)換成電波,這些電波通過不同的介質(zhì)傳輸并到達(dá)聽眾的耳朵,然后又被大腦處理并轉(zhuǎn)化為結(jié)構(gòu)化知識(shí)。
「毫無疑問,所有這些都通過神經(jīng)元和突觸發(fā)生。但是,如何完成的呢?這是一個(gè)問題。」Papadimitriou 表示,「我相信在未來 10 年里,我們會(huì)對(duì)細(xì)節(jié)有更好的了解。」
大腦中神經(jīng)元集合
認(rèn)知和神經(jīng)科學(xué)領(lǐng)域正試圖弄清楚大腦中的神經(jīng)活動(dòng)是如何轉(zhuǎn)化為語言、數(shù)學(xué)、邏輯、推理等其他功能的。如果科學(xué)家們成功地用數(shù)學(xué)模型來描述大腦的工作方式,那么他們將為創(chuàng)造能夠模仿人類思維的 AI 系統(tǒng)打開一扇新的大門。
許多研究集中在單個(gè)神經(jīng)元,直到幾十年前,科學(xué)家們還認(rèn)為單個(gè)神經(jīng)元對(duì)應(yīng)于單個(gè)思維。最流行的例子是「祖母細(xì)胞理論」,該理論認(rèn)為,每個(gè)人的大腦中可能存在一個(gè)特殊的神經(jīng)細(xì)胞,專門用于識(shí)別自己的祖母。但最近的發(fā)現(xiàn)駁斥了這種說法。新研究聲稱并證明了大量的神經(jīng)元和每個(gè)概念相關(guān),連接不同概念的神經(jīng)元之間可能存在重疊。
這些腦細(xì)胞群被稱為集合(assemblies),Papadimitriou 將其描述為一組高度連接、穩(wěn)定的神經(jīng)元,代表著一個(gè)詞、一個(gè)想法、一個(gè)物體等。
神經(jīng)科學(xué)家 György Buzsáki 將這種集合描述為「大腦的字母表。」
大腦數(shù)學(xué)模型
為了更好地理解集合作用,Papadimitriou 提出了一個(gè)大腦數(shù)學(xué)模型,稱為「交互循環(huán)網(wǎng)絡(luò)」。在這個(gè)模型下,大腦被劃分為有限數(shù)量的區(qū)域,每個(gè)區(qū)域包含幾百萬個(gè)神經(jīng)元。每個(gè)區(qū)域內(nèi)都有循環(huán)現(xiàn)象,這意味著神經(jīng)元之間相互作用。這些區(qū)域中的每一個(gè)都與其他幾個(gè)區(qū)域有聯(lián)系。這些區(qū)域間連接可以被激發(fā)或抑制。
該模型具有隨機(jī)性、可塑性和抑制性。隨機(jī)性意味著每個(gè)大腦區(qū)域的神經(jīng)元是隨機(jī)連接的。而且,不同的區(qū)域之間隨機(jī)連接。可塑性使神經(jīng)元和區(qū)域之間的聯(lián)系能夠通過經(jīng)驗(yàn)和訓(xùn)練進(jìn)行調(diào)整,而抑制性意味著在任何時(shí)刻,有限數(shù)量的神經(jīng)元被激發(fā)。
Papadimitriou 將此描述為一個(gè)基于生命的三種主要力量的非常簡單的數(shù)學(xué)模型。
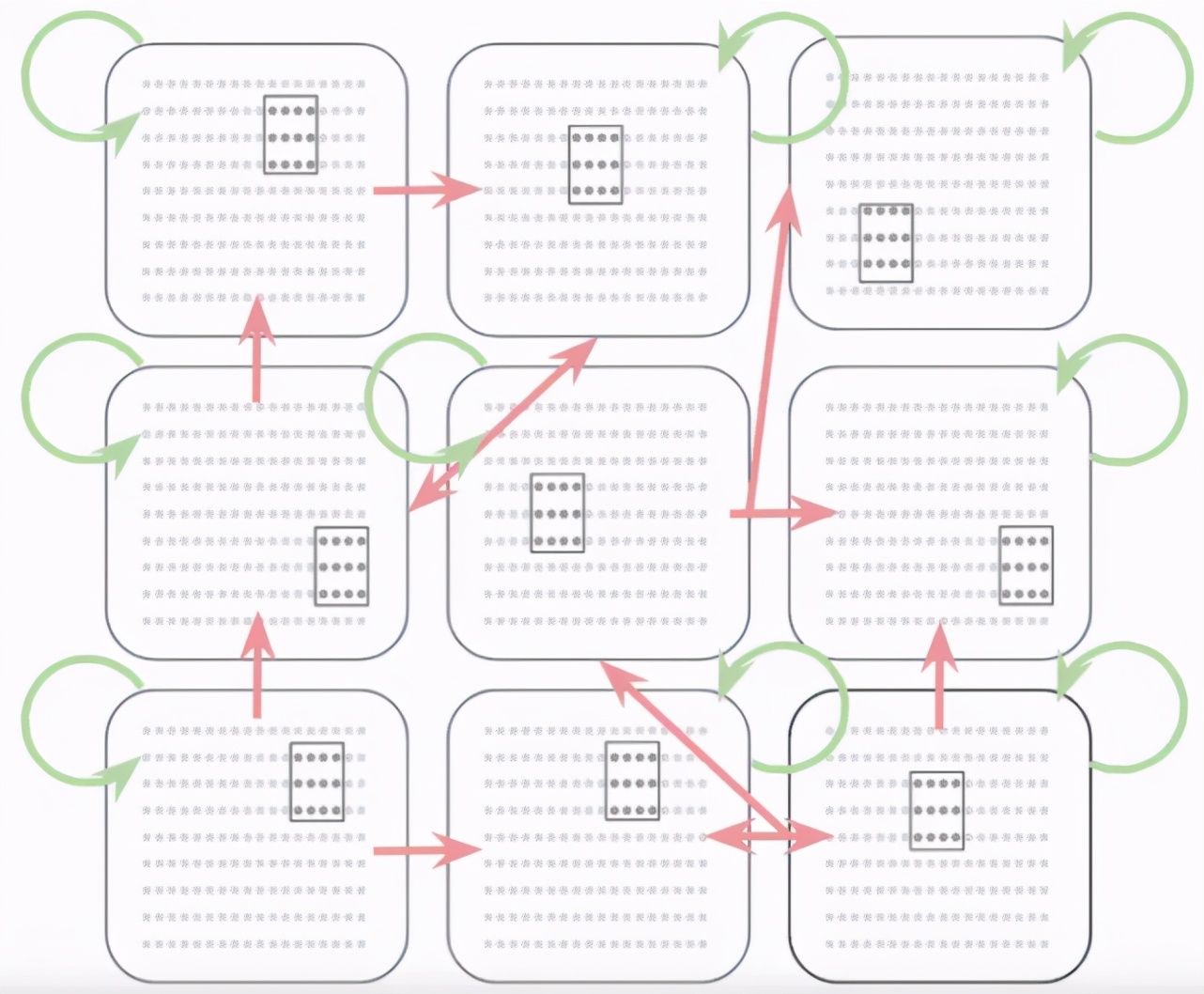
Papadimitriou 與一組來自不同學(xué)術(shù)機(jī)構(gòu)的科學(xué)家一起,在去年發(fā)表的一篇論文中詳細(xì)闡述了這一模型。集合是模型的關(guān)鍵組成部分,并實(shí)現(xiàn)了科學(xué)家們所謂的「集合演算(assembly calculus)」,這是一組能夠處理、存儲(chǔ)和檢索信息的操作。

論文地址:
https://www.pnas.org/content/117/25/14464
「這些行為不是憑空進(jìn)行的。我相信它們是真實(shí)的,可以從數(shù)學(xué)上證明并通過模擬驗(yàn)證這些操作對(duì)應(yīng)真實(shí)的行為…… 這些操作對(duì)應(yīng)于(在大腦中)觀察到的行為,」Papadimitriou said 表示。
Papadimitriou 和他的同事們假設(shè)集合和集合演算是解釋大腦認(rèn)知功能的正確模型,比如推理、計(jì)劃和語言。他在谷歌深度學(xué)習(xí)會(huì)議的演講中表示:大部分認(rèn)知能力都符合這一點(diǎn)。
基于集合演算的自然語言處理
為了測試思維模式,Papadimitriou 和他的同事構(gòu)建了一個(gè)自然語言處理系統(tǒng),該系統(tǒng)使用集合演算來解析英語句子。實(shí)際上,他們正試圖創(chuàng)建一個(gè) AI 系統(tǒng),模擬大腦中容納與詞匯和語言理解相對(duì)應(yīng)的集合區(qū)域。
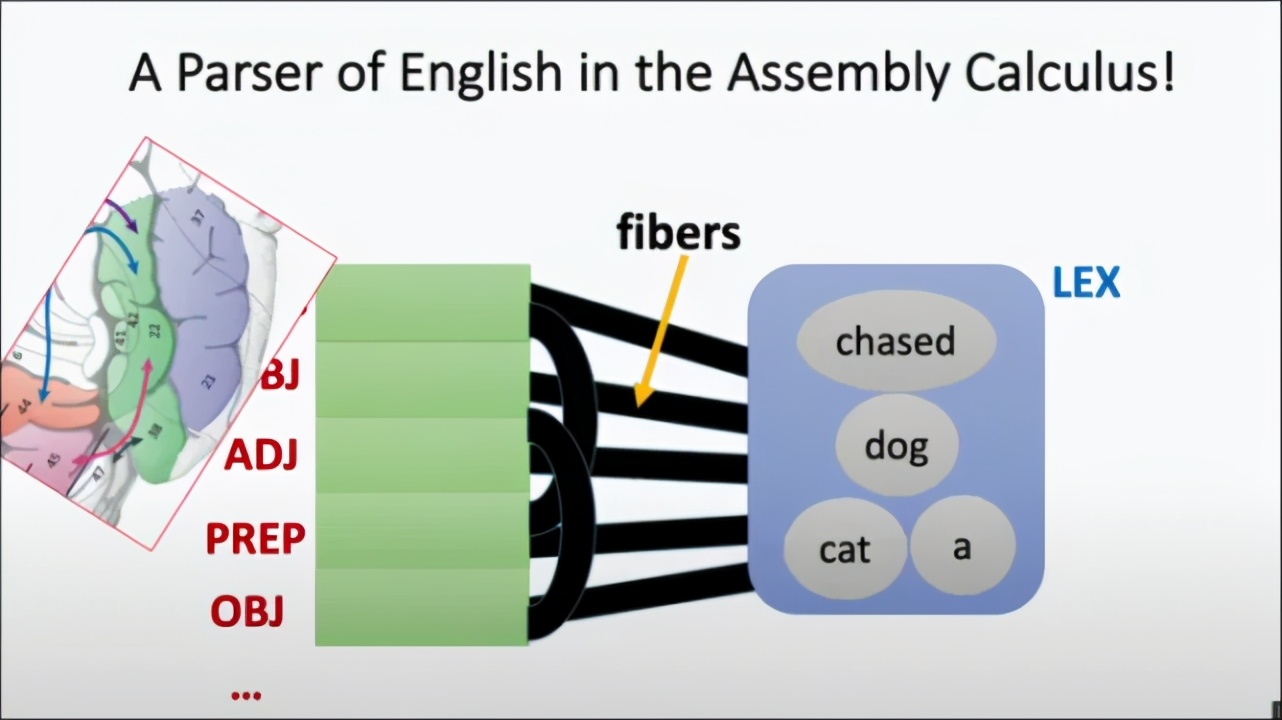
Papadimitriou 說:「如果一個(gè)單詞序列激發(fā)了集合,這個(gè)引擎就會(huì)產(chǎn)生一個(gè)句子解析。」他承認(rèn),人工智能模型仍然是初步階段,缺少了語言的許多重要部分。研究人員正在制定計(jì)劃來填補(bǔ)現(xiàn)有的語言空白。但他們認(rèn)為,所有這些部分都可以用集合演算來補(bǔ)充,這個(gè)假設(shè)需要通過時(shí)間的驗(yàn)證。
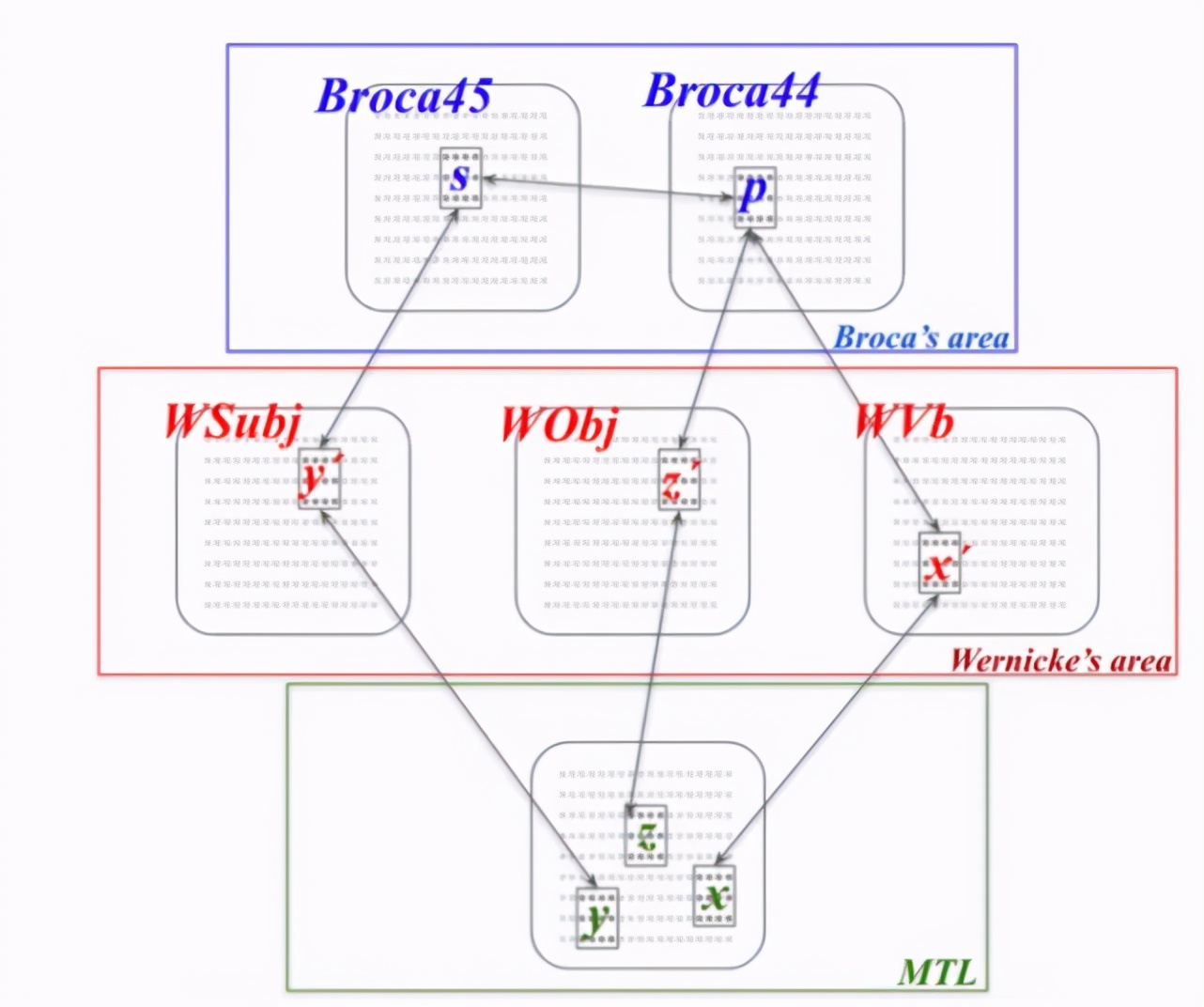
「這是語言的神經(jīng)基礎(chǔ)嗎?是不是生來左腦就有這樣的東西,」Papadimitriou 問道。關(guān)于語言如何在人類大腦中運(yùn)作,以及如何與其他認(rèn)知功能聯(lián)系在一起,仍然有許多問題需要解決。但 Papadimitriou 認(rèn)為,集合模型使我們更接近于理解這些功能,并回答剩下的問題。