如何在Kubernetes上有效使用CoreDNS?
譯文【51CTO.com快譯】一次我們?yōu)橥泄茉贙ubernetes集群上的一個應(yīng)用程序增加了HTTP請求,然后導(dǎo)致了5xx錯誤的激增。在一個GraphQL服務(wù)器上的一個應(yīng)用程序,調(diào)用大量外部的API,然后返回聚合反應(yīng)。開始我們采用的應(yīng)對方法是增加應(yīng)用程序的副本數(shù)量,看它是否提高了性能并減少了錯誤。
隨著我們進一步的深入研究,發(fā)現(xiàn)大多數(shù)的失敗都與DNS解析有關(guān)。這就是我們開始在Kubernetes上深入研究DNS解析的原因。
CoreDNS指標
DNS服務(wù)器在其數(shù)據(jù)庫中存儲記錄,并使用該數(shù)據(jù)庫回答域名查詢。如果DNS服務(wù)器沒有此數(shù)據(jù),它會嘗試從其他DNS服務(wù)器找到解決方案。
CoreDNS成為Kubernetes 1.13+之后的默認DNS服務(wù)。如今,當使用托管Kubernetes集群或為應(yīng)用程序工作負載自我管理集群時,通常調(diào)整應(yīng)用程序,而沒有過多的關(guān)注Kubernetes提供的服務(wù)或如何利用它們。
DNS解析是任何應(yīng)用程序的基本要求,即使是在Kubernetes集群上,也要確保CoreDNS正確配置和運行。
默認情況下,集群應(yīng)該始終有一個儀表板盤觀察關(guān)鍵的CoreDNS指標。為了獲得CoreDNS指標,你應(yīng)該啟用Prometheus插件作為CoreDNS配置的一部分。
下面是使用Prometheus插件從CoreDNS實例中啟用度量集合的配置示例。
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods verified
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}以下是我們建議您在儀表板中使用的關(guān)鍵指標。如果你正在使用Prometheus、DataDog、Kibana等,可以從社區(qū)/提供者那里找到現(xiàn)成的儀表板模板。
a.高速緩存命中百分比:使用CoreDNS高速緩存響應(yīng)的請求的百分比;
b.DNS請求延遲:
- CoreDNS:CoreDNS處理DNS請求所花費的時間
- 上行服務(wù)器:處理轉(zhuǎn)發(fā)到上行的DNS請求所花費的時間
c.轉(zhuǎn)發(fā)到上行服務(wù)器的請求數(shù);
d.請求的錯誤代碼:
- NXDomain:不存在的域
- FormErr:DNS請求格式錯誤
- ServFail:服務(wù)器故障
- NoError:無錯誤,已成功處理請求
e.CoreDNS資源使用情況:服務(wù)器消耗的不同資源,例如內(nèi)存,CPU等。
我們使用DataDog來監(jiān)視特定的應(yīng)用程序。下面是用DataDog構(gòu)建的一個示例儀表板:
?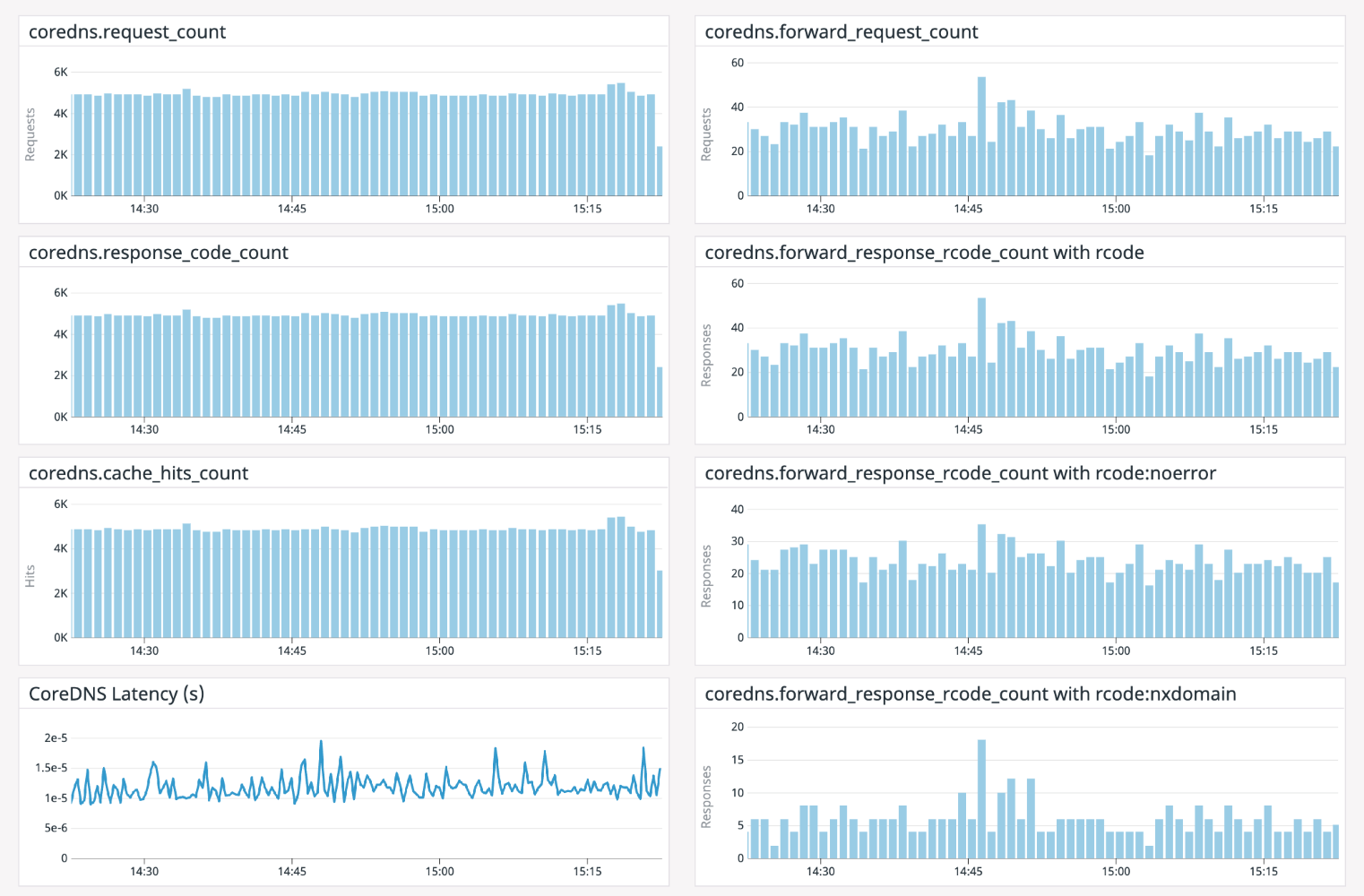 ?
?
減少DNS錯誤
當我們開始深入研究應(yīng)用程序如何向CoreDNS發(fā)出請求時,我們觀察到大多數(shù)出站請求都是通過應(yīng)用程序向外部API服務(wù)器發(fā)出的。
這通常是resolv.conf在應(yīng)用程序部署窗格中的外觀:
nameserver 10.100.0.10
search kube-namespace.svc.cluster.local svc.cluster.local cluster.local us-west-2.compute.internal
options ndots:5
Kubernetes嘗試通過不同級別的DNS查找來解析FQDN。
考慮到上述DNS配置,當DNS解析器向CoreDNS服務(wù)器發(fā)送查詢時,它會根據(jù)搜索路徑嘗試搜索域。
如果我們正在尋找一個域boktube.io,它將執(zhí)行以下查詢來在最后一個查詢中接收成功的響應(yīng):
botkube.io.kube-namespace.svc.cluster.local <= NXDomain
botkube.io.svc.cluster.local <= NXDomain
boktube.io.cluster.local <= NXDomain
botkube.io.us-west-2.compute.internal <= NXDomain
botkube.io <= NoERROR
由于我們進行了過多的外部查找,因此我們收到了很多NXDomain DNS搜索的響應(yīng)。為了優(yōu)化這一點,我們在Deployment對象中定制了spec.template.spec.dnsConfig。這是改變的樣子:
dnsPolicy: ClusterFirst
dnsConfig:
options:
- name: ndots
value: "1"
通過以上改變,pods上的resolve.conf也改變了。只對外部域執(zhí)行搜索。
這減少了對DNS服務(wù)器的查詢數(shù)量,也有助于減少應(yīng)用程序的5xx錯誤。通過下圖可以看出NXDomain響應(yīng)次數(shù)的差異:
?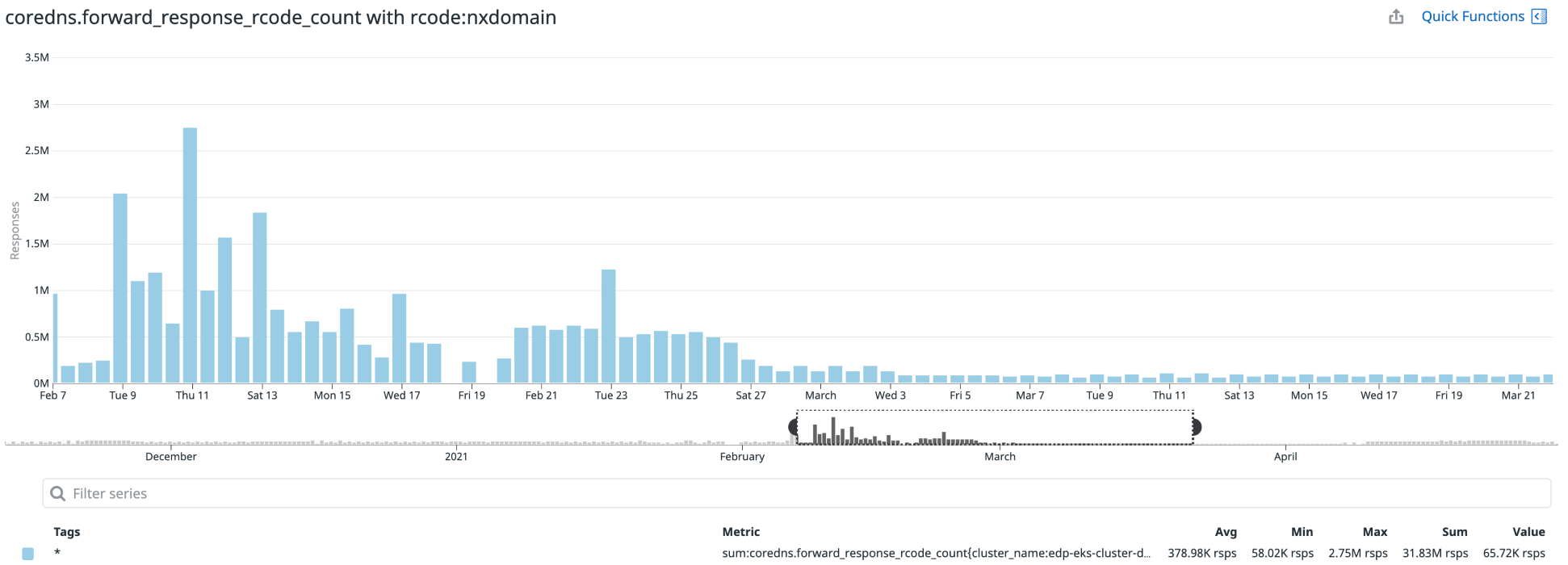 ?
?
因此我們收到了許多NXDomain響應(yīng)DNS搜索。為了對此進行優(yōu)化,我們在Deployment對象中自定義了spec.template.spec.dnsConfig。這是變化的樣子:
針對此問題的更好解決方案是在Kubernetes 1.18+中引入的[Node Level Cache](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)。
根據(jù)您的需要自定義CoreDNS
我們可以使用插件自定義CoreDNS。Kubernetes支持不同類型的工作負載,而標準的CoreDNS配置可能無法滿足你的所有需求。CoreDNS有兩個樹內(nèi)插件和外部插件。
您嘗試解析的FQDN的類型可能會根據(jù)你在集群上運行的工作負載的類型而有所不同,例如應(yīng)用程序之間是否相互通信或在Kubernetes集群外部進行交互的獨立應(yīng)用程序。
我們應(yīng)該嘗試相應(yīng)地調(diào)整CoreDNS的旋鈕。假設(shè)您在特定的公共/私有云中運行Kubernetes,并且大多數(shù)由DNS支持的應(yīng)用程序都在同一云中。在這種情況下,CoreDNS還提供特定的云相關(guān)或通用插件,可用于擴展DNS區(qū)域記錄。
決定的關(guān)鍵因素之一是你是否在Kubernetes集群中運行適當數(shù)量的CoreDNS實例。建議至少運行兩個CoreDNS服務(wù)器實例,以更好地保證DNS請求得到服務(wù)。
你可能需要為您的集群添加額外的CoreDNS實例或配置HPA (Horizontal Pod Autoscaler),具體取決于服務(wù)的請求數(shù)量、請求的性質(zhì)、在集群上運行的工作負載數(shù)量和集群的大小。
諸如被服務(wù)的請求數(shù)量、請求的性質(zhì)、在集群上運行的工作負載數(shù)量以及集群大小等因素應(yīng)該有助于你決定CoreDNS實例的數(shù)量。
本強調(diào)了Kubernetes中DNS請求循環(huán)的重要性。很多時候,我們會覺得這不是DNS的問題,但最終會發(fā)現(xiàn)確實的DNS問題,小心這個坑。
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】