













面試侃集合 | LinkedBlockingQueue篇
面試官:好了,聊完了ArrayBlockingQueue,我們接著說說LinkedBlockingQueue吧
Hydra:還真是不給人喘口氣的機會,LinkedBlockingQueue是一個基于鏈表的阻塞隊列,內部是由節(jié)點Node構成,每個被加入隊列的元素都會被封裝成下面的Node節(jié)點,并且節(jié)點中有指向下一個元素的指針:
- static class Node<E> {
- E item;
- Node<E> next;
- Node(E x) { item = x; }
- }
LinkedBlockingQueue中的關鍵屬性有下面這些:
- private final int capacity;//隊列容量
- private final AtomicInteger count = new AtomicInteger();//隊列中元素數量
- transient Node<E> head;//頭節(jié)點
- private transient Node<E> last;//尾節(jié)點
- //出隊鎖
- private final ReentrantLock takeLock = new ReentrantLock();
- //出隊的等待條件對象
- private final Condition notEmpty = takeLock.newCondition();
- //入隊鎖
- private final ReentrantLock putLock = new ReentrantLock();
- //入隊的等待條件對象
- private final Condition notFull = putLock.newCondition();
構造函數分為指定隊列長度和不指定隊列長度兩種,不指定時隊列最大長度是int的最大值。當然了,你要是真存這么多的元素,很有可能會引起內存溢出:
- public LinkedBlockingQueue() {
- this(Integer.MAX_VALUE);
- }
- public LinkedBlockingQueue(int capacity) {
- if (capacity <= 0) throw new IllegalArgumentException();
- this.capacity = capacity;
- last = head = new Node<E>(null);
- }
還有另一種在初始化時就可以將集合作為參數傳入的構造方法,實現非常好理解,只是循環(huán)調用了后面會講到的enqueue入隊方法,這里暫且略過。
在LinkedBlockingQueue中,隊列的頭結點head是不存元素的,它的item是null,next指向的元素才是真正的第一個元素,它也有兩個用于阻塞等待的Condition條件對象。與之前的ArrayBlockingQueue不同,這里出隊和入隊使用了不同的鎖takeLock和putLock。隊列的結構是這樣的:
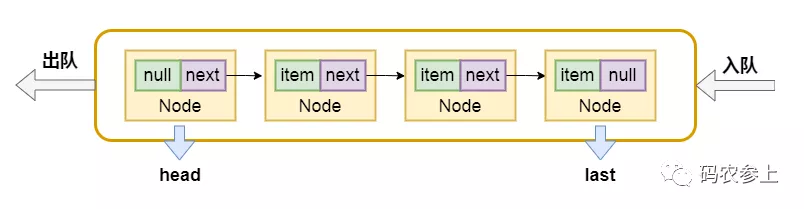
面試官:為什么要使用兩把鎖,之前ArrayBlockingQueue使用一把鎖,不是也可以保證線程的安全么?
Hydra:使用兩把鎖,可以保證元素的插入和刪除并不互斥,從而能夠同時進行,達到提高吞吐量的的效果
面試官:嗯,那還是老規(guī)矩,先說插入方法是怎么實現的吧
Hydra:這次就不提父類AbstractQueue的add方法了,反正它調用的也是子類的插入方法offer,我們就直接來看offer方法的源碼:
- public boolean offer(E e) {
- if (e == null) throw new NullPointerException();
- final AtomicInteger count = this.count;//隊列中元素個數
- if (count.get() == capacity)//已滿
- return false;
- int c = -1;
- Node<E> node = new Node<E>(e);
- final ReentrantLock putLock = this.putLock;
- putLock.lock();
- try {
- //并發(fā)情況,再次判斷隊列是否已滿
- if (count.get() < capacity) {
- enqueue(node);
- //注意這里獲取的是未添加元素前的對列長度
- c = count.getAndIncrement();
- if (c + 1 < capacity)//未滿
- notFull.signal();
- }
- } finally {
- putLock.unlock();
- }
- if (c == 0)
- signalNotEmpty();
- return c >= 0;
- }
offer方法中,首先判斷隊列是否已滿,未滿情況下將元素封裝成Node對象,嘗試獲取插入鎖,在獲取鎖后會再進行一次隊列已滿判斷,如果已滿則直接釋放鎖。在持有鎖且隊列未滿的情況下,調用enqueue入隊方法。
enqueue方法的實現也非常的簡單,將當前尾節(jié)點的next指針指向新節(jié)點,再把last指向新節(jié)點:
- private void enqueue(Node<E> node) {
- last = last.next = node;
- }
畫一張圖,方便你理解:
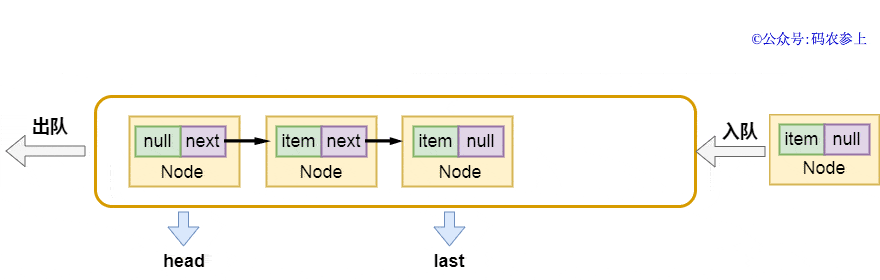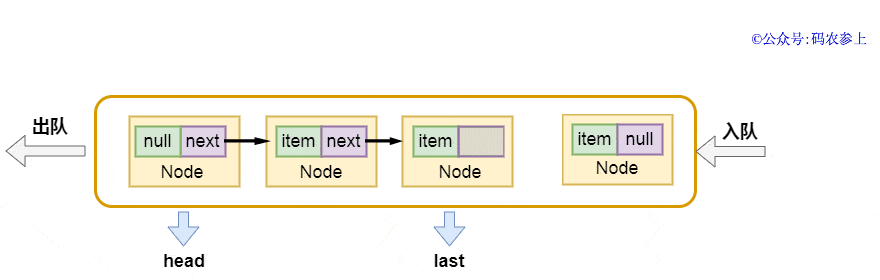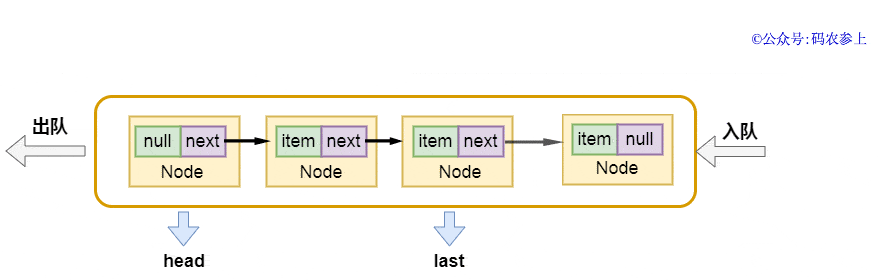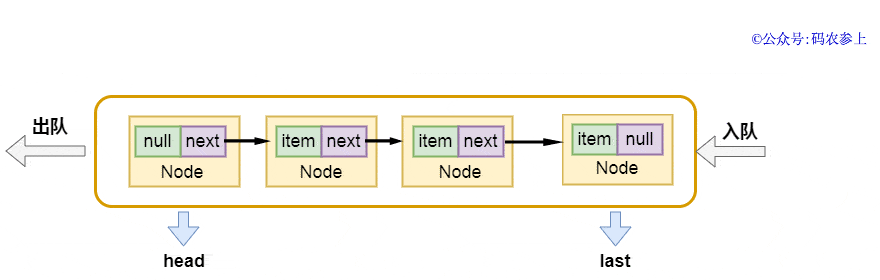
在完成入隊后,判斷隊列是否已滿,如果未滿則調用notFull.signal(),喚醒等待將元素插入隊列的線程。
面試官:我記得在ArrayBlockingQueue里插入元素后,是調用的notEmpty.signal(),怎么這里還不一樣了?
Hydra:說到這,就不得不再提一下使用兩把鎖來分別控制插入和獲取元素的好處了。在ArrayBlockingQueue中,使用了同一把鎖對入隊和出隊進行控制,那么如果在插入元素后再喚醒插入線程,那么很有可能等待獲取元素的線程就一直得不到喚醒,造成等待時間過長。
而在LinkedBlockingQueue中,分別使用了入隊鎖putLock和出隊鎖takeLock,插入線程和獲取線程是不會互斥的。所以插入線程可以在這里不斷的喚醒其他的插入線程,而無需擔心是否會使獲取線程等待時間過長,從而在一定程度上提高了吞吐量。當然了,因為offer方法是非阻塞的,并不會掛起阻塞線程,所以這里喚醒的是阻塞插入的put方法的線程。
面試官:那接著往下看,為什么要在c等于0的情況下才去喚醒notEmpty中的等待獲取元素的線程?
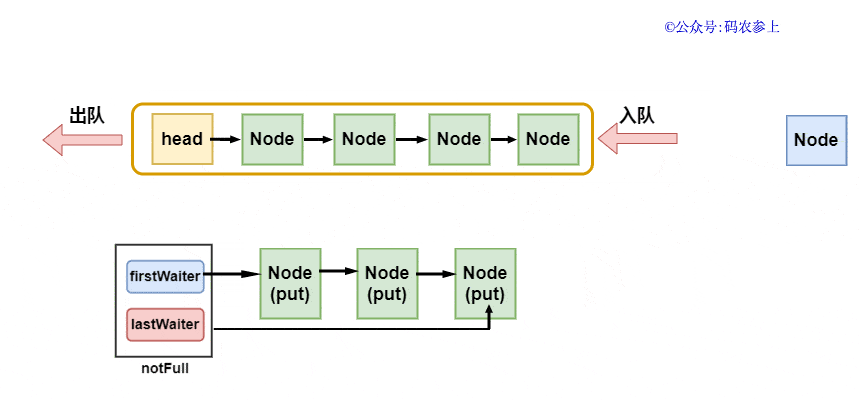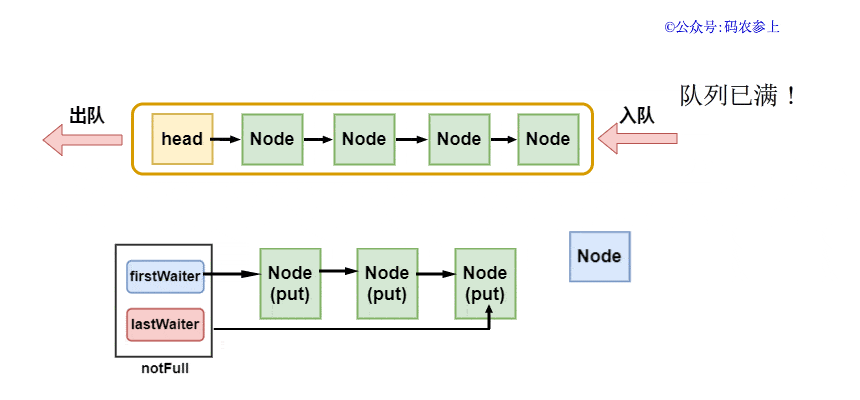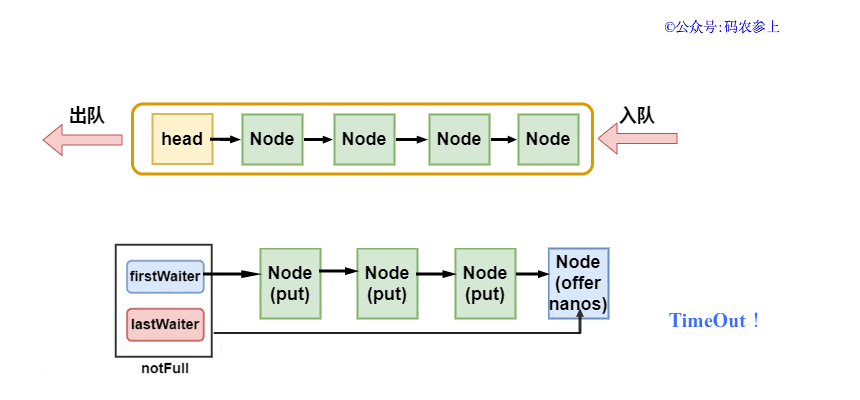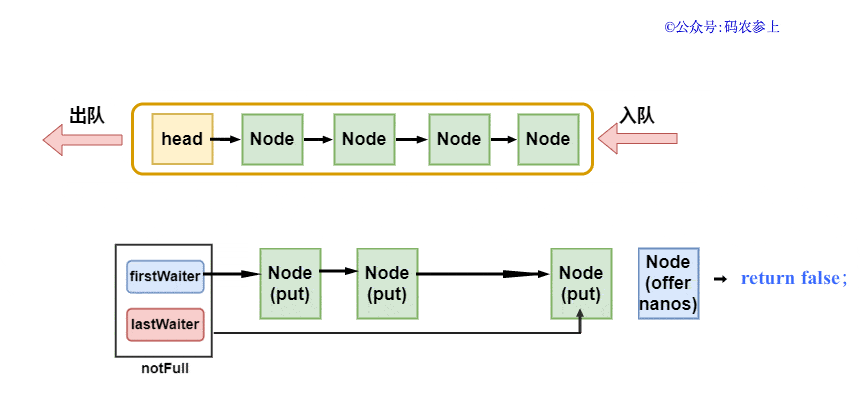
Hydra:其實獲取元素的方法和上面插入元素的方法是一個模式的,只要有一個獲取線程在執(zhí)行方法,那么就會不斷的通過notEmpty.signal()喚醒其他的獲取線程。只有當c等于0時,才證明之前隊列中已經沒有元素,這時候獲取線程才可能會被阻塞,在這個時候才需要被喚醒。上面的這些可以用一張圖來說明:
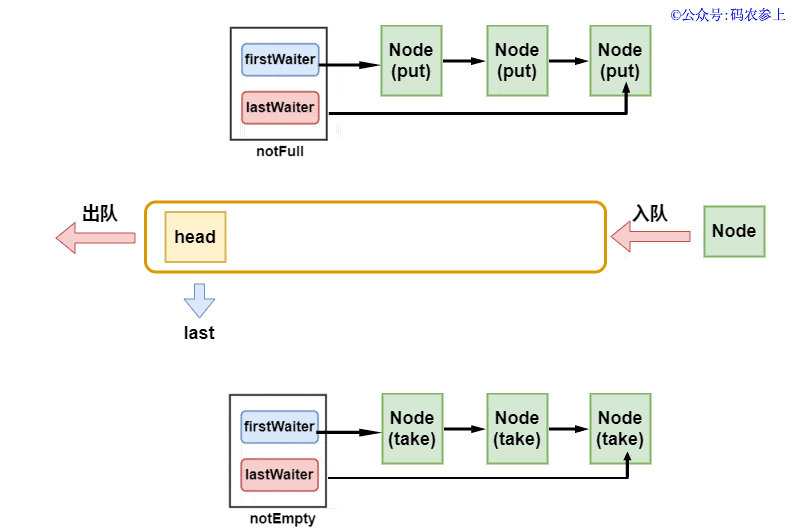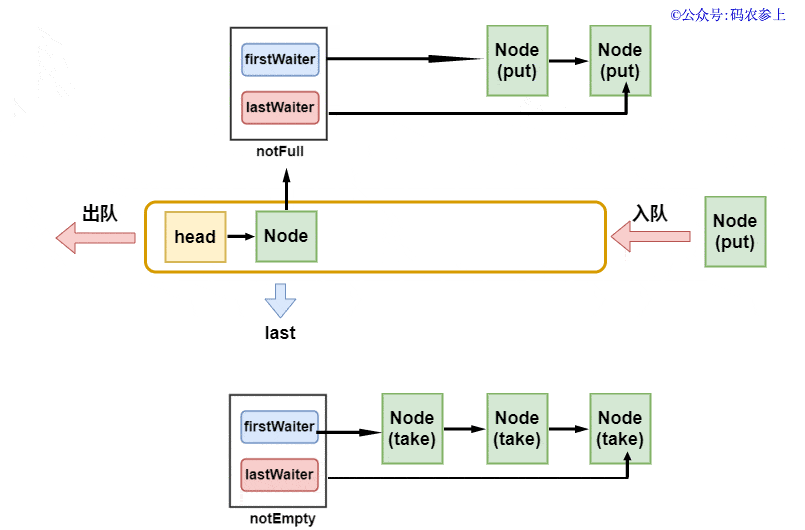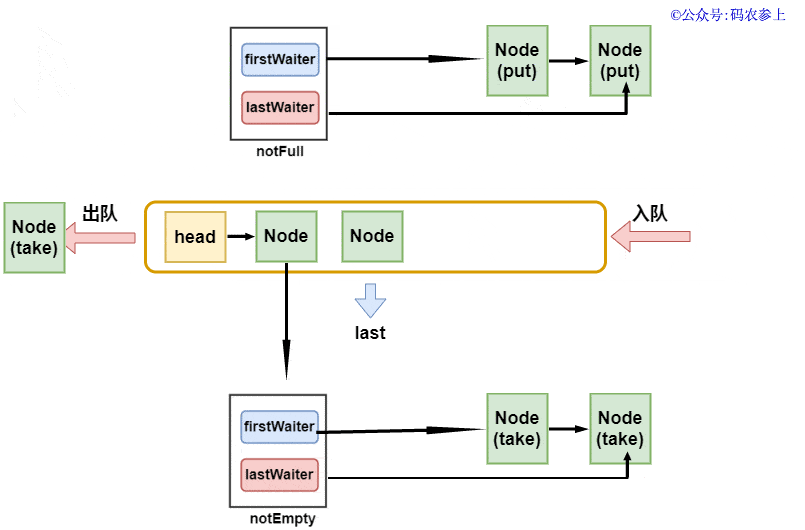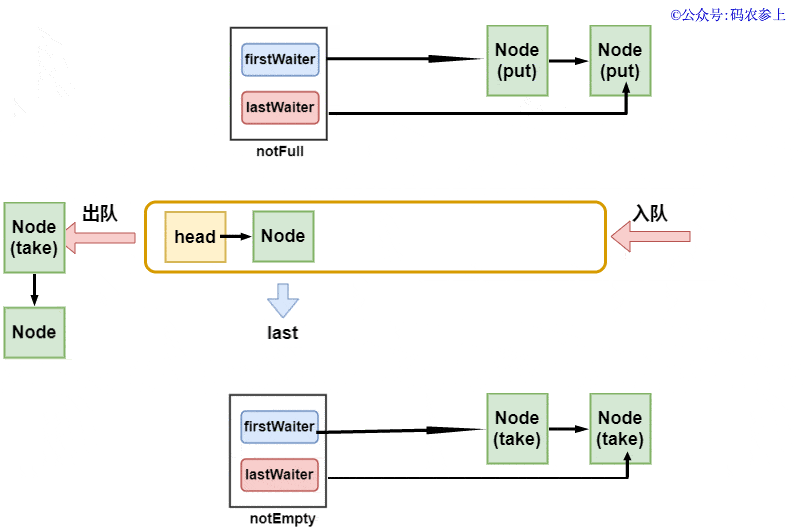
由于我們之前說過,隊列中的head節(jié)點可以認為是不存儲數據的標志性節(jié)點,所以可以簡單的認為出隊時直接取出第二個節(jié)點,當然這個過程不是非常的嚴謹,我會在后面講解出隊的過程中再進行補充說明。
面試官:那么阻塞方法put和它有什么區(qū)別?
Hydra:put和offer方法整體思路一致,不同的是加鎖是使用的是可被中斷的方式,并且當隊列中元素已滿時,將線程加入notFull等待隊列中進行等待,代碼中體現在:
- while (count.get() == capacity) {
- notFull.await();
- }
這個過程體現在上面那張圖的notFull等待隊列中的元素上,就不重復說明了。另外,和put方法比較類似的,還有一個攜帶等待時間參數的offer方法,可以進行有限時間內的阻塞添加,當超時后放棄插入元素,我們只看和offer方法不同部分的代碼:
- public boolean offer(E e, long timeout, TimeUnit unit){
- ...
- long nanos = unit.toNanos(timeout);//轉換為納秒
- ...
- while (count.get() == capacity) {
- if (nanos <= 0)
- return false;
- nanos = notFull.awaitNanos(nanos);
- }
- enqueue(new Node<E>(e));
- ...
- }
awaitNanos方法在await方法的基礎上,增加了超時跳出的機制,會在循環(huán)中計算是否到達預設的超時時間。如果在到達超時時間前被喚醒,那么會返回超時時間減去已經消耗的時間。無論是被其他線程喚醒返回,還是到達指定的超時時間返回,只要方法返回值小于等于0,那么就認為它已經超時,最終直接返回false結束。
面試官:費這么大頓功夫才把插入講明白,我先喝口水,你接著說獲取元素方法
Hydra:……那先看非阻塞的poll方法
- public E poll() {
- final AtomicInteger count = this.count;
- if (count.get() == 0)//隊列為空
- return null;
- E x = null;
- int c = -1;
- final ReentrantLock takeLock = this.takeLock;
- takeLock.lock();
- try {
- if (count.get() > 0) {//隊列非空
- x = dequeue();
- //出隊前隊列長隊
- c = count.getAndDecrement();
- if (c > 1)
- notEmpty.signal();
- }
- } finally {
- takeLock.unlock();
- }
- if (c == capacity)
- signalNotFull();
- return x;
- }
出隊的邏輯和入隊的非常相似,當隊列非空時就執(zhí)行dequeue進行出隊操作,完成出隊后如果隊列仍然非空,那么喚醒等待隊列中掛起的獲取元素的線程。并且當出隊前的元素數量等于隊列長度時,在出隊后喚醒等待隊列上的添加線程。
出隊方法dequeue的源碼如下:
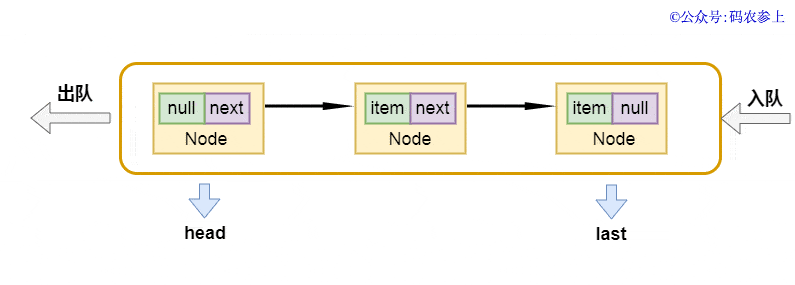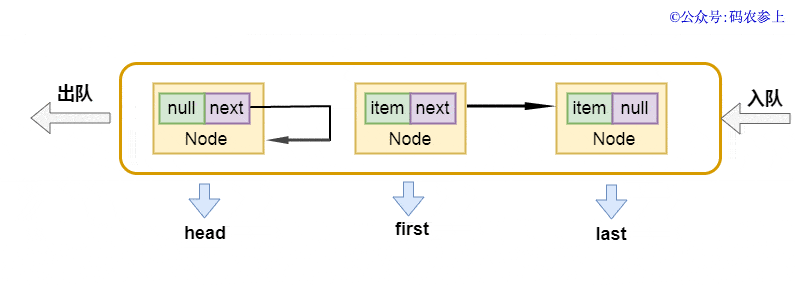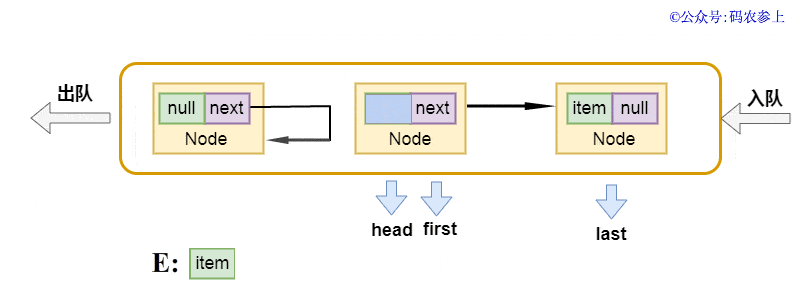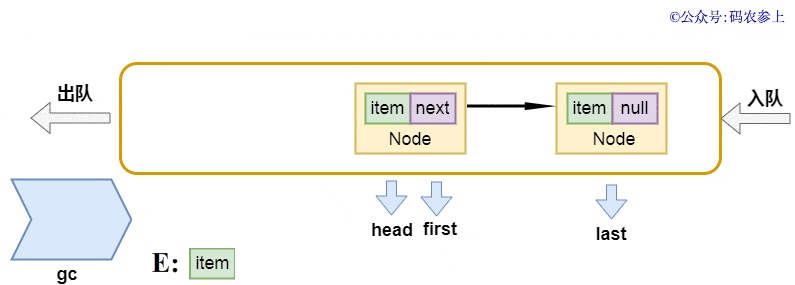
- private E dequeue() {
- Node<E> h = head;
- Node<E> first = h.next;
- h.next = h; // help GC
- head = first;
- E x = first.item;
- first.item = null;
- return x;
- }
之前提到過,頭節(jié)點head并不存儲數據,它的下一個節(jié)點才是真正意義上的第一個節(jié)點。在出隊操作中,先得到頭結點的下一個節(jié)點first節(jié)點,將當前頭結點的next指針指向自己,代碼中有一個簡單的注釋是help gc,個人理解這里是為了降低gc中的引用計數,方便它更早被回收。之后再將新的頭節(jié)點指向first,并返回清空為null前的內容。使用圖來表示是這樣的:
面試官:(看看手表)take方法的整體邏輯也差不多,能簡單概括一下嗎
Hydra:阻塞方法take方法和poll的思路基本一致,是一個可以被中斷的阻塞獲取方法,在隊列為空時,會掛起當前線程,將它添加到條件對象notEmpty的等待隊列中,等待其他線程喚醒。
面試官:再給你一句話的時間,總結一下它和ArrayBlockingQueue的異同,我要下班回家了
Hydra:好吧,我總結一下,有下面幾點:
1、隊列長度不同,ArrayBlockingQueue創(chuàng)建時需指定長度并且不可修改,而LinkedBlockingQueue可以指定也可以不指定長度
2、存儲方式不同,ArrayBlockingQueue使用數組,而LinkedBlockingQueue使用Node節(jié)點的鏈表
3、ArrayBlockingQueue使用一把鎖來控制元素的插入和移除,而LinkedBlockingQueue將入隊鎖和出隊鎖分離,提高了并發(fā)性能
4、ArrayBlockingQueue采用數組存儲元素,因此在插入和移除過程中不需要生成額外對象,LinkedBlockingQueue會生成新的Node節(jié)點,對gc會有影響














