













成熟的AI應該自己寫代碼,IBM發布5億行代碼數據集,包含55種語言
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
在ImageNet頻頻出現在計算機視覺研究的今天,IBM也為智能編碼(AI for Code)帶來了它的專屬數據集——CodeNet。
1400萬個編程項目,5億行代碼,超過55種的不同編碼語言。研究人員希望這一數據集能為編碼自動化領域(比如大型項目代碼的調試、維護和遷移)帶來便利。
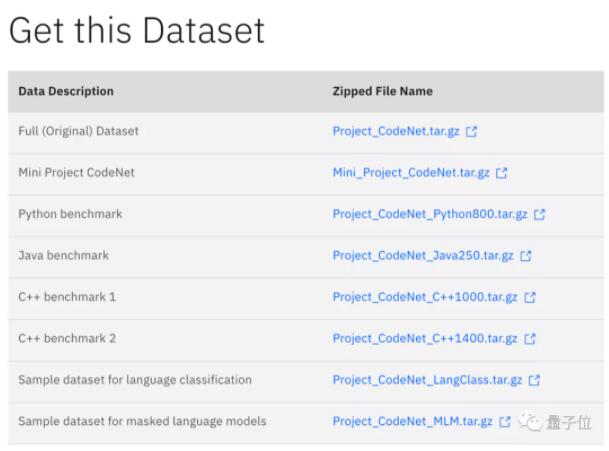
△下載鏈接見文末
獨一無二的數據基礎
CodeNet的數據基礎來自兩個OJ(Online Judge)平臺AIZU和AtCoder所提交的實例。
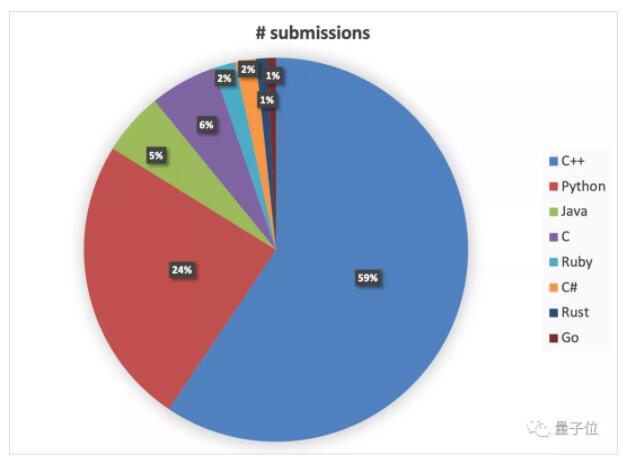
△大聲告訴我世界上最好的語言是什么?
在這種在線編程平臺上提交的解決方案,除了大規模的代碼數據之外,還有許多高質量的元數據(Metadata)和注釋。
比如對于OJ平臺的問題,就有如問題描述、內存限制、問題難度等信息。
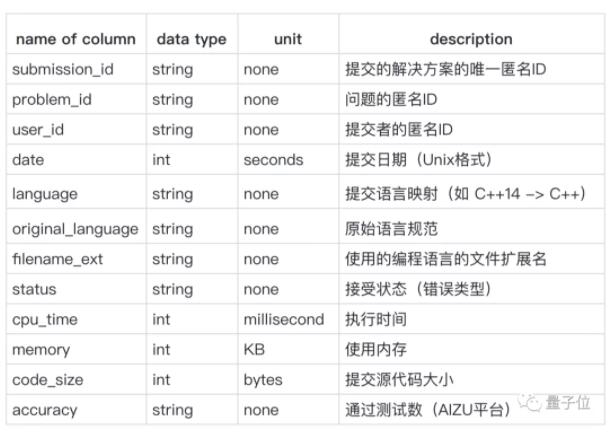
用戶提交的案例也一樣:
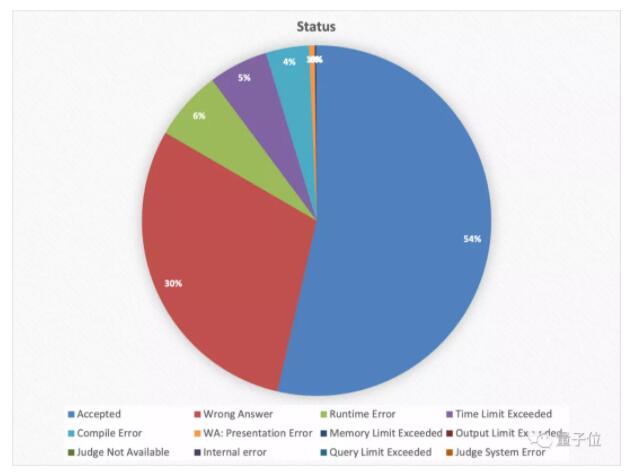
而在平臺自動審查機制下,提交的解決方案的不同狀態同樣也可以作為重要參考數據。
CodeNet能做什么?
基準測試
當在CodeNet-1K(C++ 1000基準)與最大的公開數據集之一GCJ-297上訓練相同的MISIM模型,并在第三個獨立的數據集POJ-104上測試這兩個訓練好的模型時:
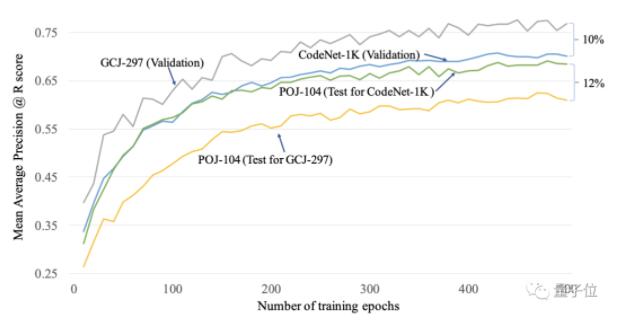
△模型在CodeNet-1K上訓練時的POJ-104測試分數比在GCJ-297上的高12%
這表明了CodeNet-1K擁有更好的泛化能力。
而分別使用MLP、CNN、C-BERT、GNN在CodeNet的幾個基準上進行了代碼分類、代碼相似性評估和代碼完成等實驗后,大多數任務都獲得了90%以上的準確率。
實際應用
基于不同編程語言間的規則,將幾段代碼轉換成其他語言,對AI來說并非難事。
但如果是上千上萬行,甚至是一個大型項目,其代碼語義就會涉及到上下文,而上下文又可能牽扯到多個代碼庫。在這樣的復雜語境下的語言翻譯可是個不小的挑戰。
在以前,通常先由機器完成程序50%~60%的遷移,涉及復雜規則的部分再由人力負責,非常棘手且費事費力。
可就在不久前,IBM通過基于CodeNet的AI for Code成功將一位大型汽車客戶的持續代碼遷移過程(多代Java技術開發的3500個Java文件,超一百萬行代碼),從一年縮短到了四星期。
因為在CodeNet的數據基礎中,90%以上的問題的描述、輸入格式說明、輸出格式說明,以及50%以上的提交代碼的輸入和輸出樣本,就是確定不同語言間的代碼等價與否的關鍵。
這就極大地推動了代碼翻譯的強化學習技術。
而大量于內存限制、執行時間、錯誤類型的元數據,也可以用來標記源代碼中的潛在缺陷,并進一步訓練開發代碼優化系統。
CodeNet數據集提供了一套利于理解和使用的技術,在協助廣大開發者和研究者開發算法,推進AI編碼的同時,也為企業開啟IT現代化帶來了持續不斷的商業價值。
技術上如何實現
在統計數據時,研究者們組織所有數據成為一個嚴格的目錄結構:最上層是Project CodeNet目錄,下方的子目錄分別為:
*數據
細分為每個問題中源碼、腳本語言。
*元數據
存放所有問題的problem_list.csv文件和提交案例的csv文件。
*問題描述
存放問題的HTML文件,包含文本的廣泛描述。
然后使用命令行工具或像ls和grep這樣的應用程序來提取,對csv文件可使用csvkit組件(如csvstat)。
對于數據集則采用bash腳本進行訪問選擇:

△腳本已給出。
最后通過標記器產生標記流、AST生成解析到抽象語法樹、構建數據流圖以分析代碼,最終將代碼樣本轉換為可被AI算法識別和使用的表現形式:
△處理過程所用到的工具。
編程自動化的未來
IBM的研究者們還在不斷地改進和開發CodeNet,期望它能夠加速AI編程的算法進步。
而隨著機器學習領域的不斷發展,不僅是代碼的“實現”,連“設計”也開始向計算機一側傾靠(比如GAN通過對抗學習尋找最優解)。
未來真的可以像DNA的自我編輯那樣,實現完全的自動編程嗎?
建議先封裝幾個人類程序員,來幫計算機完成算法第一步的“精確描述問題需求”。






















