用Transformer進行圖像語義分割,性能超最先進的卷積方法
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
正如大家所知,在進行圖像語義分割時,圖像被編碼成一系列補丁后往往很模糊,需要借助上下文信息才能被正確分割。
因此上下文建模對圖像語義分割的性能至關重要!
而與以往基于卷積網絡的方法不同,來自法國的一個研究團隊另辟蹊徑,提出了一種只使用Transformer的語義分割方法。
 最先進的卷積方法">
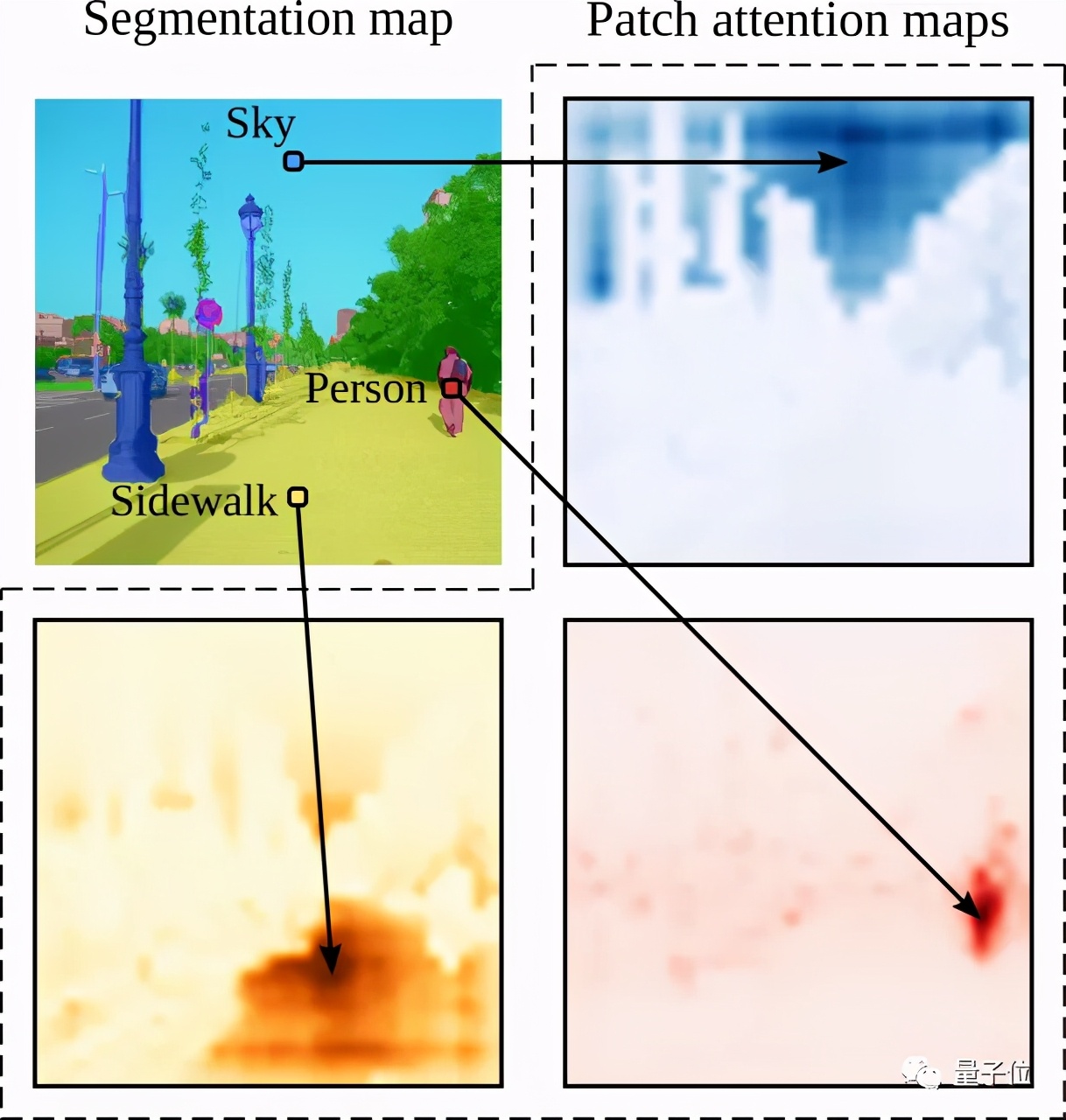
最先進的卷積方法">該方法“效果拔群”,可以很好地捕捉圖像全局上下文信息!
 最先進的卷積方法">
最先進的卷積方法">要知道,就連取得了驕人成績的FCN(完全卷積網絡)都有“圖像全局信息訪問限制”的問題。(卷積結構在圖像語義分割方面目前有無法打破的局限)
而這次這個方法在具有挑戰性的ADE20K數據集上,性能都超過了最先進的卷積方法!
不得不說,Transformer跨界計算機視覺領域真是越來越頻繁了、效果也越來越成功了!
那這次表現優異的Transformer語義分割,用了什么不一樣的“配方”嗎?
使用Vision Transformer
沒錯,這次這個最終被命名為Segmenter的語義分割模型,主要基于去年10月份才誕生的一個用于計算機視覺領域的“新秀”Transformer:Vision Transformer,簡稱ViT。
ViT有多“秀”呢?
ViT采用純Transformer架構,將圖像分成多個patches進行輸入,在很多圖像分類任務中表現都不輸最先進的卷積網絡。
缺點就是在訓練數據集較小時,性能不是很好。
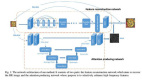
Segmenter作為一個純Transformer的編碼-解碼架構,利用了模型每一層的全局圖像上下文。
基于最新的ViT研究成果,將圖像分割成塊(patches),并將它們映射為一個線性嵌入序列,用編碼器進行編碼。再由Mask Transformer將編碼器和類嵌入的輸出進行解碼,上采樣后應用Argmax給每個像素一一分好類,輸出最終的像素分割圖。
下面是該模型的架構示意圖:
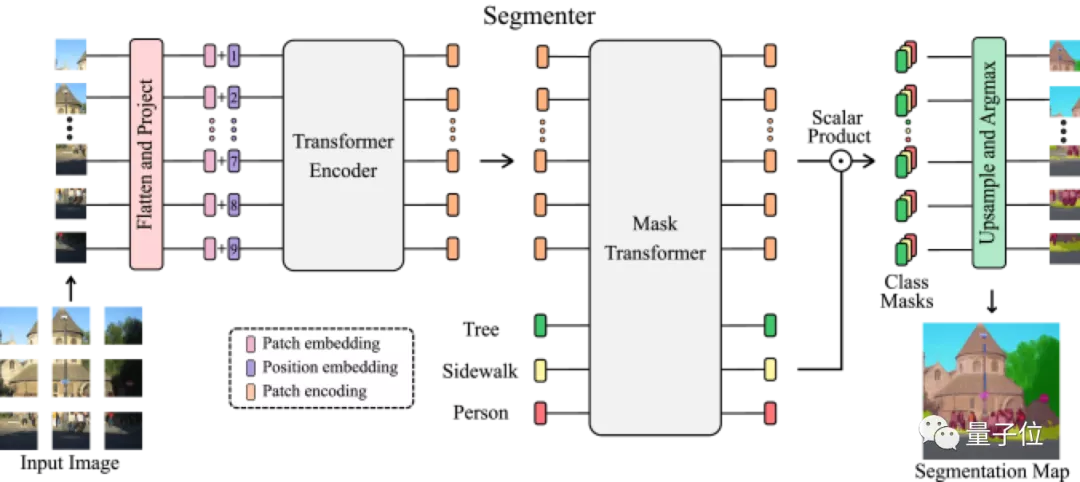 最先進的卷積方法">
最先進的卷積方法">解碼階段采用了聯合處理圖像塊和類嵌入的簡單方法,解碼器Mask Transformer可以通過用對象嵌入代替類嵌入來直接進行全景分割。
效果如何
多說無益,看看實際效果如何?
首先他們在ADE20K數據集上比較不同Transformer變體,研究不同參數(正則化、模型大小、圖像塊大小、訓練數據集大小,模型性能,不同的解碼器等),全方面比較Segmenter與基于卷積的語義分割方法。
其中ADE20K數據集,包含具有挑戰性的細粒度(fine-grained)標簽場景,是最具挑戰性的語義分割數據集之一。
下表是不同正則化方案的比較結果:
他們發現隨機深度(Stochastic Depth)方案可獨立提高性能,而dropout無論是單獨還是與隨機深度相結合,都會損耗性能。
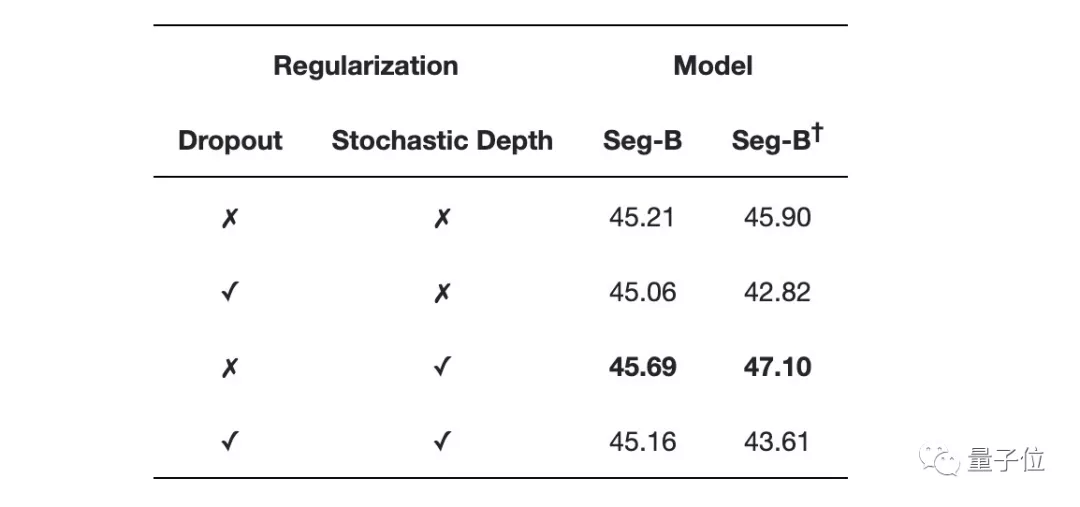 最先進的卷積方法">
最先進的卷積方法">不同圖像塊大小和不同transformer的性能比較發現:
增加圖像塊的大小會導致圖像的表示更粗糙,但會產生處理速度更快的小序列。
減少圖像塊大小是一個強大的改進方式,不用引入任何參數!但需要在較長的序列上計算Attention,會增加計算時間和內存占用。
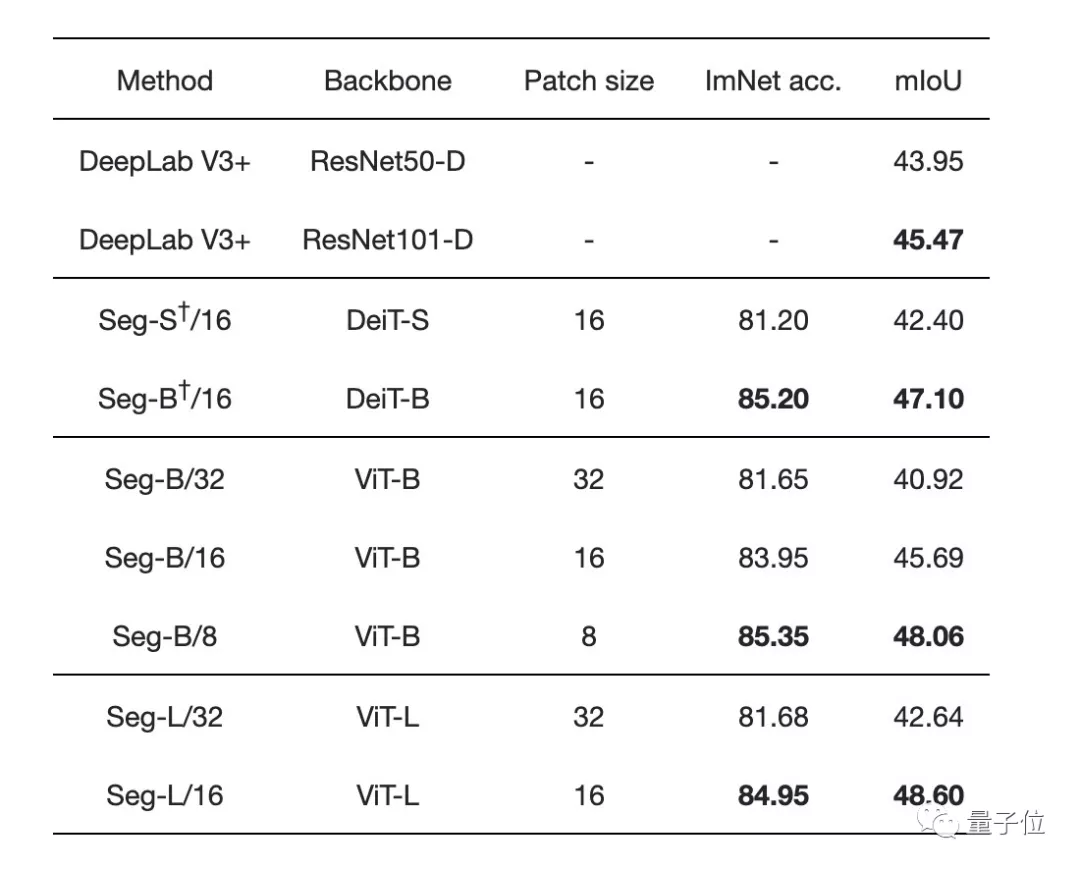 最先進的卷積方法">
最先進的卷積方法">Segmenter在使用大型transformer模型或小規模圖像塊的情況下更優:
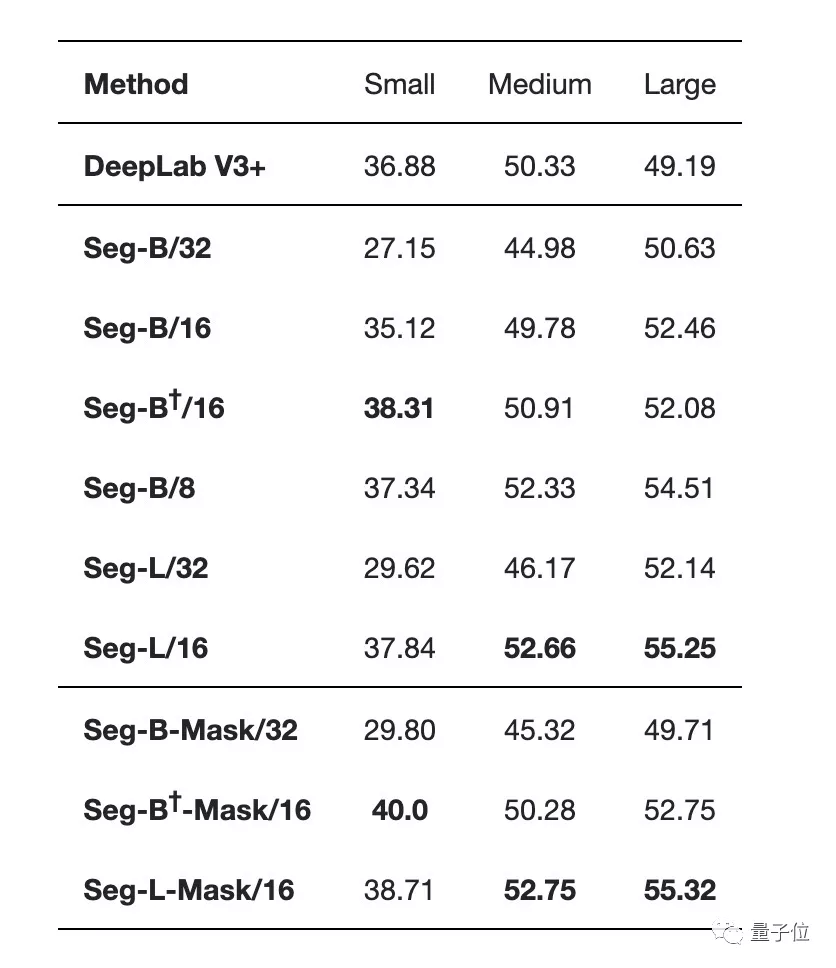 最先進的卷積方法">
最先進的卷積方法">(表中間是帶有線性解碼器的不同編碼器,表底部是帶有Mask Transformer作為解碼器的不同編碼器)
下圖也顯示了Segmenter的明顯優勢,其中Seg/16模型(圖像塊大小為16x16)在性能與準確性方面表現最好。
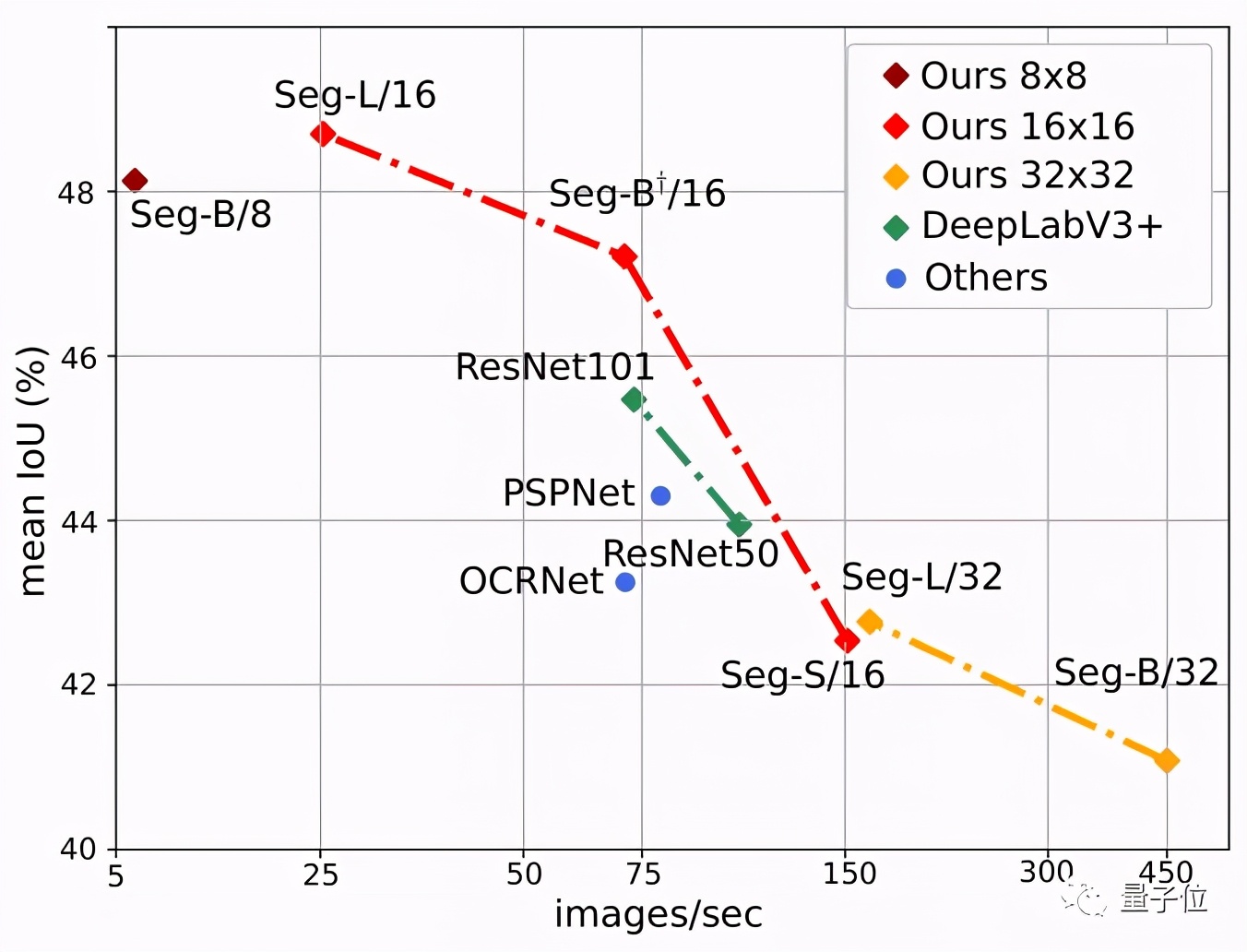 最先進的卷積方法">
最先進的卷積方法">最后,我們再來看看Segmenter與SOTA的比較:
在最具挑戰性的ADE20K數據集上,Segmenter兩項指標均高于所有SOTA模型!
 最先進的卷積方法">
最先進的卷積方法">(中間太長已省略)
 最先進的卷積方法">
最先進的卷積方法">在Cityscapes數據集上與大多數SOTA不相上下,只比性能最好的Panoptic-Deeplab低0.8。
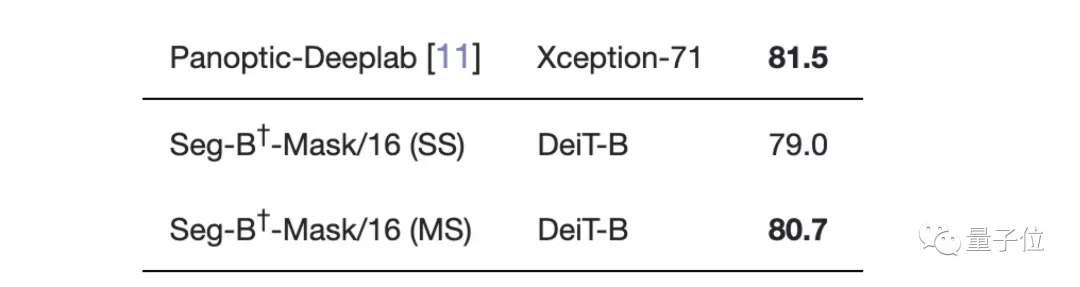 最先進的卷積方法">
最先進的卷積方法">在Pascal Context數據集上的表現也是如此。
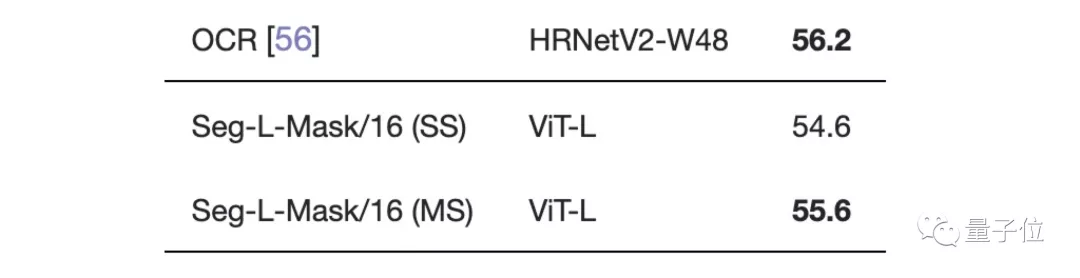 最先進的卷積方法">
最先進的卷積方法">剩余參數比較,大家有興趣的可按需查看論文細節。
論文地址:
https://www.arxiv-vanity.com/papers/2105.05633/