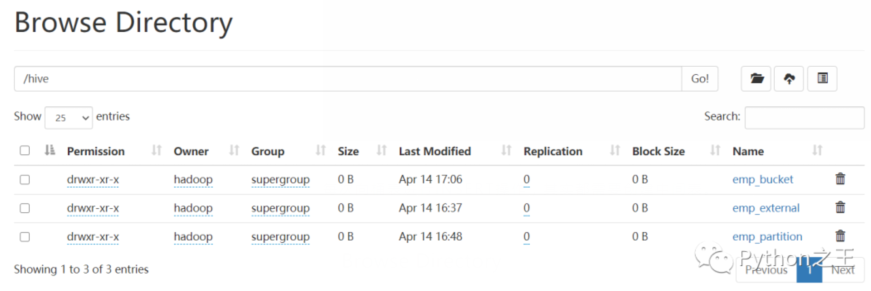
Hive中的內部表、外部表、分區表和分桶表
在Hive數據倉庫中,重要點就是Hive中的四個表。Hive 中的表分為內部表、外部表、分區表和分桶表。
內部表
默認創建的表都是所謂的內部表,有時也被稱為管理表。因為這種表,Hive 會(或多或少地)控制著數據的生命周期。Hive 默認情況下會將這些表的數據存儲在由配置項hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定義的目錄的子目錄下。當我們刪除一個管理表時,Hive 也會刪除這個表中數據。管理表不適合和其他工具共享數據。
具體的內部表創建命令
- CREATE TABLE emp(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"; -- 分隔符\t
外部表
外部表稱之為EXTERNAL_TABLE;其實就是,在創建表時可以自己指定目錄位置(LOCATION);如果刪除外部表時,只會刪除元數據不會刪除表數據;
具體的外部表創建命令,比內部表多一個LOCATION而已。
- CREATE EXTERNAL TABLE emp_external(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_external';
「內部表和外部表的區別:」
- 創建內部表時:會將數據移動到數據倉庫指向的路徑;
- 創建外部表時:僅記錄數據所在路徑,不對數據的位置做出改變;
- 刪除內部表時:刪除表元數據和數據;
- 刪除外部表時,刪除元數據,不刪除數據。
分區表
分區表實際上就是對應一個 HDFS 文件系統上的獨立的文件夾,該文件夾下是該分區所有的數據文件。Hive 中的分區就是分目錄,把一個大的數據集根據業務需要分割成小的數據集。在查詢時通過 WHERE 子句中的表達式選擇查詢所需要的指定的分區,這樣的查詢效率會提高很多。
具體的分區表創建命令如下,比外部表多一個PARTITIONED。PARTITIONED英文意思就是分區的,需要指定表中的其中一個字段,這個就是根據該字段的不同,劃分不同的文件夾。
- CREATE EXTERNAL TABLE emp_partition(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2)
- )
- PARTITIONED BY (deptno INT) -- 按照部門編號進行分區
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_partition';
分桶表
分區在HDFS上的表現形式是一個目錄,分桶則是一個單獨的文件。分桶則是指定分桶表的某一列,讓該列數據按照哈希取模的方式隨機、均勻地分發到各個桶文件中。
具體的分桶表創建命令如下,比分區表的不同在于CLUSTERED。CLUSTERED英文意思就是群集的。分桶操作和分區一樣,需要根據某一列具體數據來進行哈希取模操作,故指定的分桶列必須基于表中的某一列(字段)
- CREATE EXTERNAL TABLE emp_bucket(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照員工編號散列到四個 bucket 中
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_bucket';
「分區表和分桶表的區別:」
Hive 數據表可以根據某些字段進行分區操作,細化數據管理,可以讓部分查詢更快。同時表和分區也可以進一步被劃分為 Buckets,分桶表的原理和 MapReduce 編程中的 HashPartitioner 的原理類似;分區和分桶都是細化數據管理,但是分區表是手動添加區分,由于 Hive 是讀模式,所以對添加進分區的數據不做模式校驗,分桶表中的數據是按照某些分桶字段進行 hash 散列形成的多個文件,所以數據的準確性也高很多。
分桶表的建表有三種方式:直接建表,CREATE TABLE LIKE 和 CREATE TABLE AS SELECT
- 注:不能直接向桶表中加載數據,需要使用insert語句插入數據,因此只要見到load data 到桶表的,基本是亂來的。分桶表的數據通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因為 CTAS 操作會觸發 MapReduce,因此分桶的時間是比較長的,因為要進行MapReduce操作。
根據上面命令,成功創建了內部表、外部表、分區表和分桶表。
下面依次插入數據到四張表,emp.txt具體內容如下:
- 7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20
- 7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
- 7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
- 7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20
- 7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
- 7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30
- 7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10
- 7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20
- 7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10
- 7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
- 7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20
- 7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30
- 7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20
- 7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
具體的插入數據命令如下所示:
- ## 內部表
- load data local inpath "emp.txt" into table emp;
- ## 外部表
- load data local inpath "emp.txt" into table emp_external;
- ## 分區表
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=10);
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20);
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30);
- ## 分桶表
- -- 啟用桶表
- set hive.enforce.bucketing=true;
- -- 限制對桶表進行load操作
- set hive.strict.checks.bucketing = true;
- INSERT INTO TABLE emp_bucket SELECT * FROM emp; --這里的 emp 表就是一張普通的雇員表
每次向桶表進行INSERT操作,其實都需要創建中間表。