













SQL Server數據庫分區表的應用實例
作者:菜光
本文介紹一個SQL Server數據庫分區表的應用實例,通過這個實例,我們得出:創建分區表可以優化查詢的效率。接下來就讓我們來一起看看這個實例吧。
用SQL Server數據庫做一個網游發號系統。功能是將廠商給的N個卡號導入到庫里在固定的時間為用戶提供領取。這個系統***的亮點應該就是這個N的不確定性,不同的廠商提供的卡數量不同,N可能是10也可能是10W。經過分析得表結構如下圖:
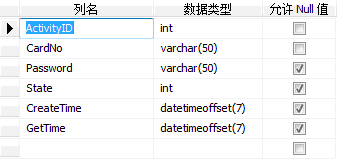
現在做一個簡單的測試,在這個表里插入2000W條數據,然后根據ActivityID隨機查詢一條數據出來,居然需要4秒多。。于是決定嘗試用分區表來優化查詢效率。
分區函數如下:
- CREATE PARTITION FUNCTION [Card_PF](int)
- AS
- RANGE LEFT FOR VALUES (500, 1000, 1500, 2000, 2500, 3000)
這里我是用的ActivityID作為分區的條件。每500個活動一個區。
分區方案如下:
- CREATE PARTITION SCHEME [Card_PS]
- AS
- PARTITION [Card_PF] TO ([Card1], [Card2], [Card3], [Card4], [Card5], [Card6], [Card7])
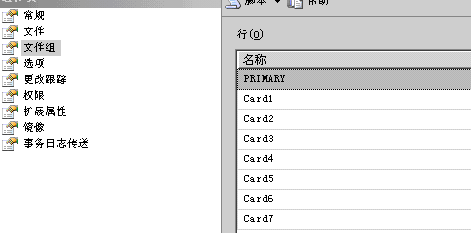
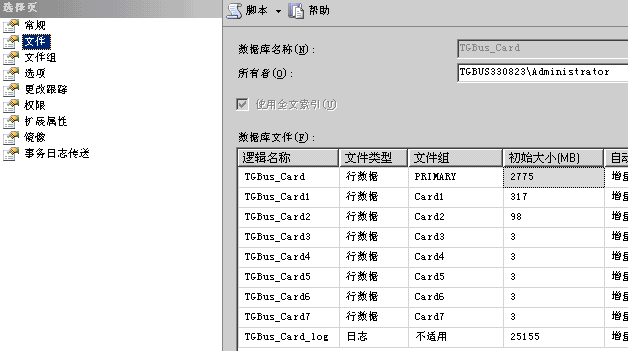
下圖是對應的文件和文件組:
接下來就是最關鍵的一步,為這個表增加一個聚合索引,并且采用上面創建的分區方案:
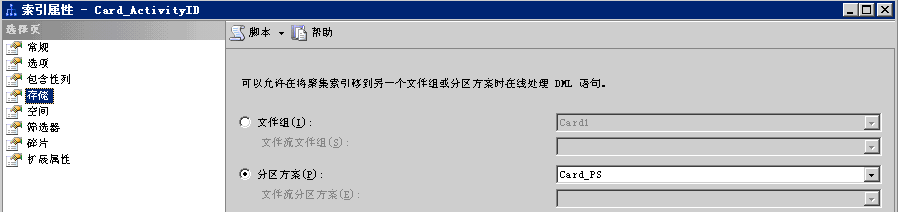
到此為止分區表已經創建完畢,為了更好的測試效果我在這個新建立的表里從新插入2000W條數據,同樣的SQL語句運行時間在1秒左右。
關于SQL Server數據庫分區表的知識就介紹到這里,如果您想了解更多的SQL Server數據庫的知識,可以看一下這里的文章:http://database.51cto.com/sqlserver/,您的收獲將是我們***的快樂!
【編輯推薦】
責任編輯:趙鵬
來源:
博客園










