













你要偷偷學會排查線上CPU飆高的問題,然后驚艷所有人!
前段時間我們新上了一個新的應用,因為流量一直不大,集群QPS大概只有5左右,寫接口的rt在30ms左右。
因為最近接入了新的業務,業務方給出的數據是日常QPS可以達到2000,大促峰值QPS可能會達到1萬。
所以,為了評估水位,我們進行了一次壓測。壓測過程中發現,當單機QPS達到200左右時,接口的rt沒有明顯變化,但是CPU利用率急劇升高,直到被打滿。
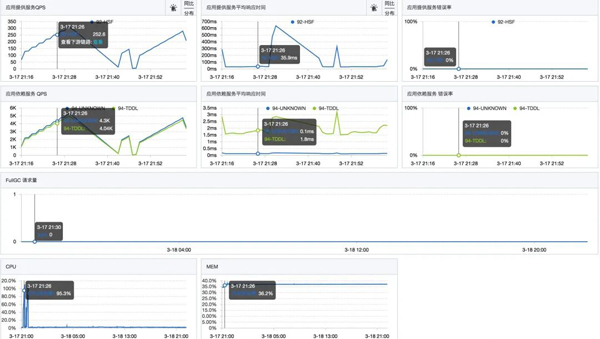
壓測停止后,CPU利用率立刻降了下來。
于是開始排查是什么導致了CPU的飆高。
問題排查與解決
在壓測期間,登錄到機器,開始排查問題。
本案例的排查過程使用的阿里開源的Arthas工具進行的,不使用Arthas,使用JDK自帶的命令也是可以。
在開始排查之前,可以先看一下CPU的使用情況,最簡單的就是使用top命令直接查看:
- top - 10:32:38 up 11 days, 17:56, 0 users, load average: 0.84, 0.33, 0.18
- Tasks: 23 total, 1 running, 21 sleeping, 0 stopped, 1 zombie
- %Cpu(s): 95.5 us, 2.2 sy, 0.0 ni, 76.3 id, 0.0 wa, 0.0 hi, 0.0 si, 6.1 st
- KiB Mem : 8388608 total, 4378768 free, 3605932 used, 403908 buff/cache
- KiB Swap: 0 total, 0 free, 0 used. 4378768 avail Mem
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 3480 admin 20 0 7565624 2.9g 8976 S 241.2 35.8 649:07.23 java
- 1502 root 20 0 401768 40228 9084 S 1.0 0.5 39:21.65 ilogtail
- 181964 root 20 0 3756408 104392 8464 S 0.7 1.2 0:39.38 java
- 496 root 20 0 2344224 14108 4396 S 0.3 0.2 52:22.25 staragentd
- 1400 admin 20 0 2176952 229156 5940 S 0.3 2.7 31:13.13 java
- 235514 root 39 19 2204632 15704 6844 S 0.3 0.2 55:34.43 argusagent
- 236226 root 20 0 55836 9304 6888 S 0.3 0.1 12:01.91 systemd-journ
可以看到,進程ID為3480的Java進程占用的CPU比較高,基本可以斷定是應用代碼執行過程中消耗了大量CPU,接下來開始排查具體是哪個線程,哪段代碼比較耗CPU。
首先,下載Arthas命令:
- curl -L http://start.alibaba-inc.com/install.sh | sh
啟動
- ./as.sh
使用Arthas命令"thread -n 3 -i 1000"查看當前"最忙"(耗CPU)的三個線程:
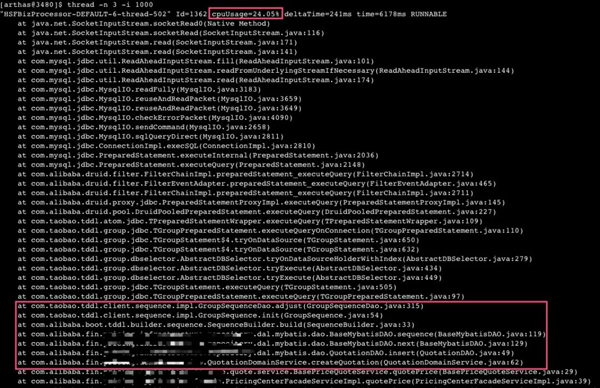
通過上面的堆棧信息,可以看出,占用CPU資源的線程主要是卡在JDBC底層的TCP套接字讀取上。連續執行了很多次,發現很多線程都是卡在這個地方。
通過分析調用鏈,發現這個地方是我代碼中有數據庫的insert,并且使用TDDL(阿里內部的分布式數據庫中間件)來創建sequence,在sequence的創建過程中需要和數據庫有交互。
但是,基于對TDDL的了解,TDDL每次從數據庫中查詢sequence序列的時候,默認會取出1000條,緩存在本地,只有用完之后才會再從數據庫獲取下一個1000條序列。
按理說我們的壓測QPS只有300左右,不應該這么頻繁的何數據庫交互才對。但是,經過多次使用Arthas的查看,發現大部分CPU都耗盡在這里。
于是開始排查代碼問題。最終發現了一個很傻的問題,那就是我們的sequence創建和使用有問題:
- public Long insert(T dataObject) {
- if (dataObject.getId() == null) {
- Long id = next();
- dataObject.setId(id);
- }
- if (sqlSession.insert(getNamespace() + ".insert", dataObject) > 0) {
- return dataObject.getId();
- } else {
- return null;
- }
- }
- public Sequence sequence() {
- return SequenceBuilder.create()
- .name(getTableName())
- .sequenceDao(sequenceDao)
- .build();
- }
- /**
- * 獲取下一個主鍵ID
- *
- * @return
- */
- protected Long next() {
- try {
- return sequence().nextValue();
- } catch (SequenceException e) {
- throw new RuntimeException(e);
- }
- }
是因為,我們每次insert語句都重新build了一個新的sequence,這就導致本地緩存就被丟掉了,所以每次都會去數據庫中重新拉取1000條,但是只是用了一條,下一次就又重新取了1000條,周而復始。
于是,調整了代碼,把Sequence實例的生成改為在應用啟動時初始化一次。這樣后面在獲取sequence的時候,不會每次都和數據庫交互,而是先查本地緩存,本地緩存的耗盡了才會再和數據庫交互,獲取新的sequence。
- public abstract class BaseMybatisDAO implements InitializingBean {
- @Override
- public void afterPropertiesSet() throws Exception {
- sequence = SequenceBuilder.create().name(getTableName()).sequenceDao(sequenceDao).build();
- }
- }
通過實現InitializingBean,并且重寫afterPropertiesSet()方法,在這個方法中進行Sequence的初始化。
改完以上代碼,提交進行驗證。通過監控數據可以看出優化后,數據庫的讀RT有明顯下降:
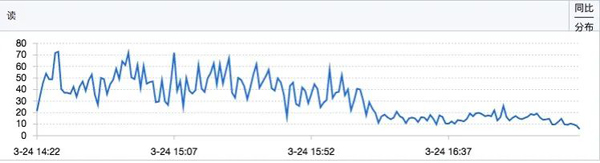
sequence的寫操作QPS也有明顯下降:
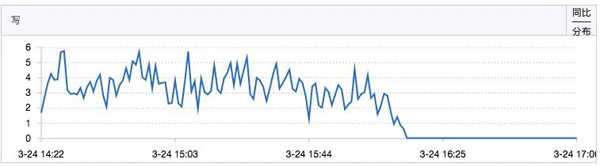
于是我們開始了新的一輪壓測,但是發現,CPU的使用率還是很高,壓測的QPS還是上不去,于是重新使用Arthas查看線程的情況。
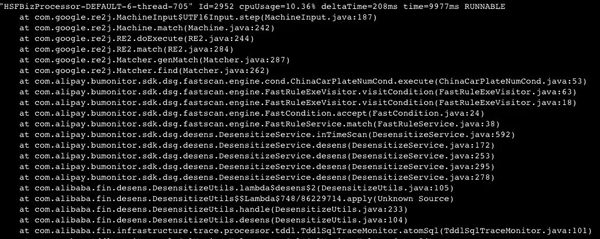
發現了一個新的比較耗費CPU的線程的堆棧,這里面主要是因為我們用到了一個聯調工具,該工具預發布默認開啟了TDDL的采集(官方文檔中描述為預發布默認不開啟TDDL采集,但是實際上會采集)。
這個工具在打印日志過程中會進行脫敏,脫敏框架會調用Google的re2j進行正則表達式的匹配。
因為我的操作中TDDL操作比較多,默認采集大量TDDL日志并且進行脫敏處理,確實比較耗費CPU。
所以,通過在預發布中關閉DP對TDDL的采集,即可解決該問題。
總結與思考
本文總結了一次線上CPU飆高的問題排查過程,其實問題都不難,并且還挺傻的,但是這個排查過程是值得大家學習的。
其實在之前自己排查過很多次CPU飆高的問題,這次也是按照老方法進行排查,但是剛開始并沒有發現太大的問題,只是以為是流量升高導致數據庫操作變多的正常現象。
期間又多方查證(通過Arthas查看sequence的獲取內容、通過數據庫查看最近插入的數據的主鍵ID等)才發現是TDDL的Sequence的初始化機制有問題。
在解決了這個問題之后,以為徹底解決問題,結果又遇到了DP采集TDDL日志導致CPU飆高,最終再次解決后有了明顯提升。
所以,事出反常必有妖,排查問題就是一個抽絲剝繭的過程。























