CPU飆高,系統性能問題如何排查?
壓測時或多或少都收到過CPU或者Load高的告警,如果是單機偶發性的,經常會認為是“宿主機搶占導致的”,那事實是否真是如此呢?是什么引起了這些指標的飆高?網絡、磁盤還是高并發?有什么工具可以定位?TOP、PS還是vmstat?CPU高&Load高和CPU低&Load高,不同的表征又代表著什么?
一 背景知識
LINUX進程狀態
LINUX 2.6以后的內核中,進程一般存在7種基礎狀態:D-不可中斷睡眠、R-可執行、S-可中斷睡眠、T-暫停態、t-跟蹤態、X-死亡態、Z-僵尸態,這幾種狀態在PS命令中有對應解釋。

- D (TASK_UNINTERRUPTIBLE),不可中斷睡眠態。顧名思義,位于這種狀態的進程處于睡眠中,并且不允許被其他進程或中斷(異步信號)打斷。因此這種狀態的進程,是無法使用kill -9殺死的(kill也是一種信號),除非重啟系統(沒錯,就是這么頭硬)。不過這種狀態一般由I/O等待(比如磁盤I/O、網絡I/O、外設I/O等)引起,出現時間非常短暫,大多很難被PS或者TOP命令捕獲(除非I/O HANG死)。SLEEP態進程不會占用任何CPU資源。
- R (TASK_RUNNING),可執行態。這種狀態的進程都位于CPU的可執行隊列中,正在運行或者正在等待運行,即不是在上班就是在上班的路上。
- S (TASK_INTERRUPTIBLE),可中斷睡眠態。不同于D,這種狀態的進程雖然也處于睡眠中,但是是允許被中斷的。這種進程一般在等待某事件的發生(比如socket連接、信號量等),而被掛起。一旦這些時間完成,進程將被喚醒轉為R態。如果不在高負載時期,系統中大部分進程都處于S態。SLEEP態進程不會占用任何CPU資源。
- T&t (__TASK_STOPPED & __TASK_TRACED),暫停or跟蹤態。這種兩種狀態的進程都處于運行停止的狀態。不同之處是暫停態一般由于收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOUT四種信號被停止,而跟蹤態是由于進程被另一個進程跟蹤引起(比如gdb斷點)。暫停態進程會釋放所有占用資源。
- Z (EXIT_ZOMBIE), 僵尸態。這種狀態的進程實際上已經結束了,但是父進程還沒有回收它的資源(比如進程的描述符、PID等)。僵尸態進程會釋放除進程入口之外的所有資源。
- X (EXIT_DEAD), 死亡態。進程的真正結束態,這種狀態一般在正常系統中捕獲不到。
Load Average & CPU使用率
談到系統性能,Load和CPU使用率是最直觀的兩個指標,那么這兩個指標是怎么被計算出來的呢?是否能互相等價呢?
Load Average
不少人都認為,Load代表正在CPU上運行&等待運行的進程數,即
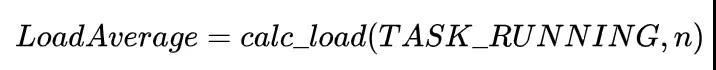
但Linux系統中,這種描述并不完全準確。
以下為Linux內核源碼中Load Average計算方法,可以看出來,因此除了可執行態進程,不可中斷睡眠態進程也會被一起納入計算,即:

- 602staticunsignedlongcount_active_tasks(void)
- 603 {
- 604structtask_struct*p;
- 605unsignedlongnr=0;
- 606607read_lock(&tasklist_lock);
- 608for_each_task(p) {
- 609if ((p->state==TASK_RUNNING610 (p->state&TASK_UNINTERRUPTIBLE)))
- 611nr+=FIXED_1;
- 612 }
- 613read_unlock(&tasklist_lock);
- 614returnnr;
- 615 }
- ......
- 625staticinlinevoidcalc_load(unsignedlongticks)
- 626 {
- 627unsignedlongactive_tasks; /* fixed-point */628staticintcount=LOAD_FREQ;
- 629630count-=ticks;
- 631if (count<0) {
- 632count+=LOAD_FREQ;
- 633active_tasks=count_active_tasks();
- 634CALC_LOAD(avenrun[0], EXP_1, active_tasks);
- 635CALC_LOAD(avenrun[1], EXP_5, active_tasks);
- 636CALC_LOAD(avenrun[2], EXP_15, active_tasks);
- 637 }
- 638 }
在前文 Linux進程狀態 中有提到過,不可中斷睡眠態的進程(TASK_UNINTERRUTED)一般都在進行I/O等待,比如磁盤、網絡或者其他外設等待。由此我們可以看出,Load Average在Linux中體現的是整體系統負載,即CPU負載 + Disk負載 + 網絡負載 + 其余外設負載,并不能完全等同于CPU使用率(這種情況只出現在Linux中,其余系統比如Unix,Load還是只代表CPU負載)。
CPU使用率
CPU的時間分片一般可分為4大類:用戶進程運行時間 - User Time, 系統內核運行時間 - System Time, 空閑時間 - Idle Time, 被搶占時間 - Steal Time。除了Idle Time外,其余時間CPU都處于工作運行狀態。
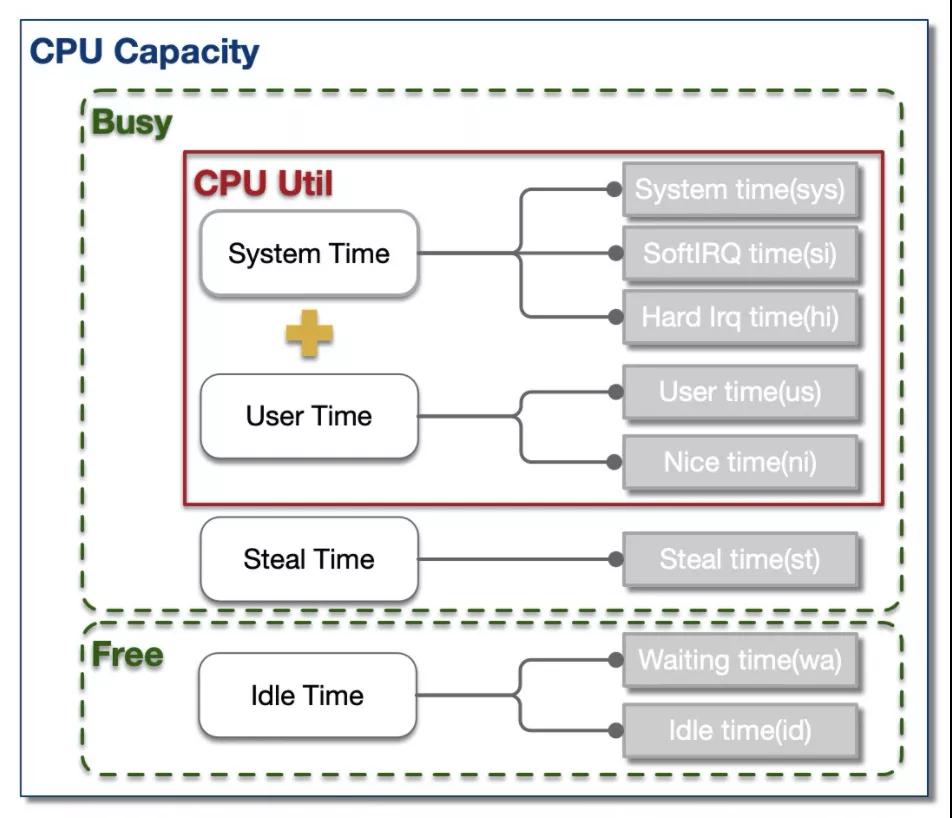
通常而言,我們泛指的整體CPU使用率為User Time 和 Systime占比之和(例如tsar中CPU util),即:
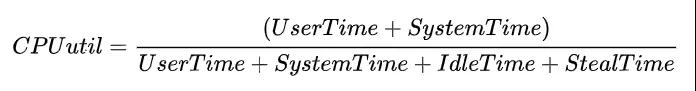
為了便于定位問題,大多數性能統計工具都將這4類時間片進一步細化成了8類,如下為TOP對CPU時間片的分類。

- us:用戶進程空間中未改變過優先級的進程占用CPU百分比
- sy:內核空間占用CPU百分比
- ni:用戶進程空間內改變過優先級的進程占用CPU百分比
- id:空閑時間百分比
- wa:空閑&等待I/O的時間百分比
- hi:硬中斷時間百分比
- si:軟中斷時間百分比
- st:虛擬化時被其余VM竊取時間百分比
這8類分片中,除wa和id外,其余分片CPU都處于工作態。
二 資源&瓶頸分析
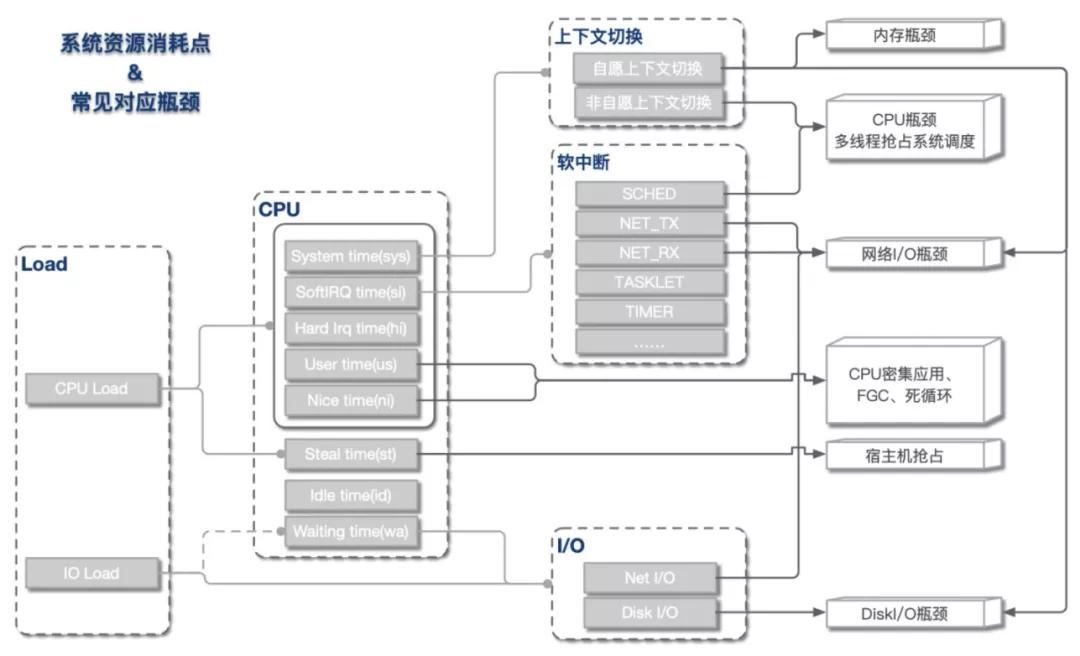
從上文我們了解到,Load Average和CPU使用率可被細分為不同的子域指標,指向不同的資源瓶頸。總體來說,指標與資源瓶頸的對應關系基本如下圖所示。
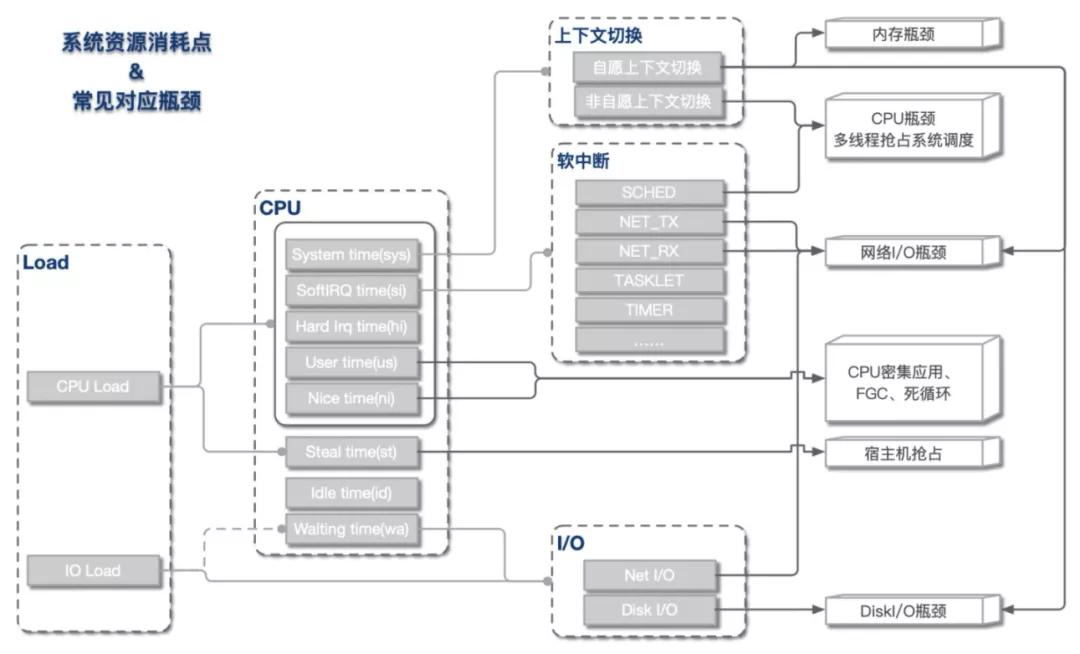
Load高 & CPU高
這是我們最常遇到的一類情況,即load上漲是CPU負載上升導致。根據CPU具體資源分配表現,可分為以下幾類:
CPU sys高
這種情況CPU主要開銷在于系統內核,可進一步查看上下文切換情況。
- 如果非自愿上下文切換較多,說明CPU搶占較為激烈,大量進程由于時間片已到等原因,被系統強制調度,進而發生的上下文切換。
- 如果自愿上下文切換較多,說明可能存在I/O、內存等系統資源瓶頸,大量進程無法獲取所需資源,導致的上下文切換。
CPU si高
這種情況CPU大量消耗在軟中斷,可進一步查看軟中斷類型。一般而言,網絡I/O或者線程調度引起軟中斷最為常見:
- NET_TX & NET_RX。NET_TX是發送網絡數據包的軟中斷,NET_RX是接收網絡數據包的軟中斷,這兩種類型的軟中斷較高時,系統存在網絡I/O瓶頸可能性較大。
- SCHED。SCHED為進程調度以及負載均衡引起的中斷,這種中斷出現較多時,系統存在較多進程切換,一般與非自愿上下文切換高同時出現,可能存在CPU瓶頸。
CPU us高
這種情況說明資源主要消耗在應用進程,可能引發的原因有以下幾類:
- 死循環或代碼中存在CPU密集計算。這種情況多核CPU us會同時上漲。
- 內存問題,導致大量FULLGC,阻塞線程。這種情況一般只有一核CPU us上漲。
- 資源等待造成線程池滿,連帶引發CPU上漲。這種情況下,線程池滿等異常會同時出現。
Load高 & CPU低
這種情況出現的根本原因在于不可中斷睡眠態(TASK_UNINTERRUPTIBLE)進程數較多,即CPU負載不高,但I/O負載較高。可進一步定位是磁盤I/O還是網絡I/O導致。
三 排查策略
利用現有常用的工具,我們常用的排查策略基本如下圖所示:
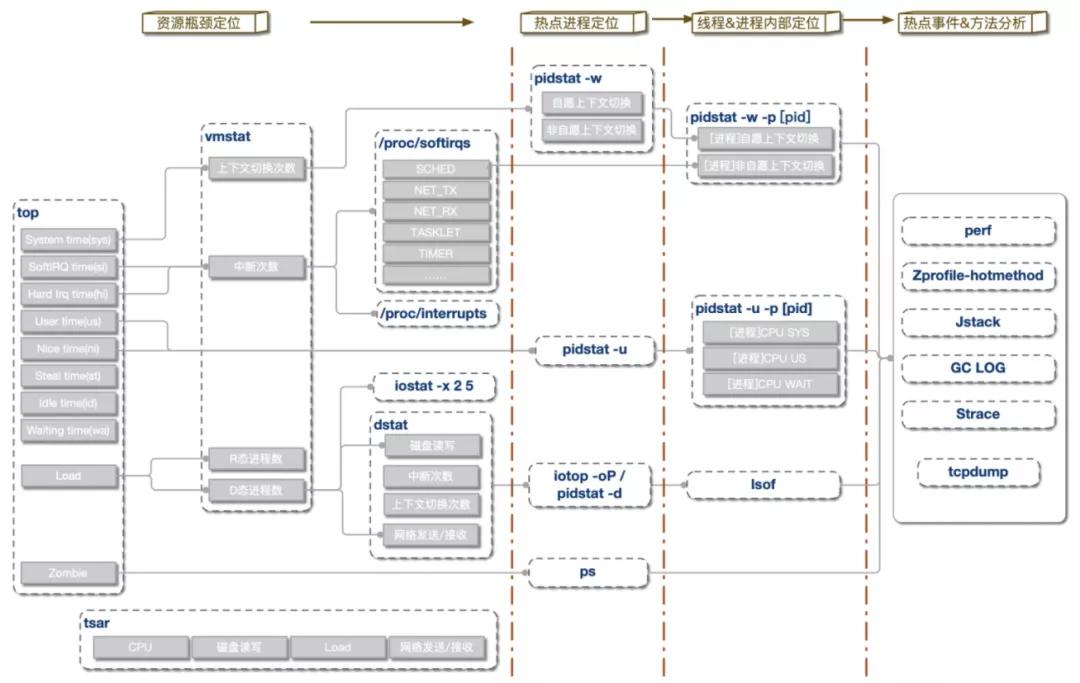
從問題發現到最終定位,基本可分為四個階段:
資源瓶頸定位
這一階段通過全局性能檢測工具,初步定位資源消耗異常位點。
常用的工具有:
- top、vmstat、tsar(歷史)
- 中斷:/proc/softirqs、/proc/interrupts
- I/O:iostat、dstat
熱點進程定位
定位到資源瓶頸后,可進一步分析具體進程資源消耗情況,找到熱點進程。
常用工具有:
- 上下文切換:pidstat -w
- CPU:pidstat -u
- I/O:iotop、pidstat -d
- 僵尸進程:ps
線程&進程內部資源定位
找到具體進程后,可細化分析進程內部資源開銷情況。
常用工具有:
- 上下文切換:pidstat -w -p [pid]
- CPU:pidstat -u -p [pid]
- I/O: lsof
熱點事件&方法分析
獲取到熱點線程后,我們可用trace或者dump工具,將線程反向關聯,將問題范圍定位到具體方法&堆棧。
常用的工具有:
- perf:Linux自帶性能分析工具,功能類似hotmethod,基于事件采樣原理,以性能事件為基礎,支持針對處理器相關性能指標與操作系統相關性能指標的性能剖析。
- jstack
- 結合ps -Lp或者pidstat -p一起使用,可初步定位熱點線程。
- 結合zprofile-threaddump一起使用,可統計線程分布、等鎖情況,常用與線程數增加分析。
- strace:跟蹤進程執行時的系統調用和所接收的信號。
- tcpdump:抓包分析,常用于網絡I/O瓶頸定位。
相關閱讀
[1]Linux Load Averages: Solving the Mystery
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
[2]What exactly is a load average?
http://linuxtechsupport.blogspot.com/2008/10/what-exactly-is-load-average.html