《吃透 MQ 系列》之扒開 Kafka 的神秘面紗
大家好,我是武哥。這是《吃透 MQ 系列》的第二彈,有些珊珊來遲,后臺被好幾個讀者催更了,實屬抱歉!
這篇文章拖更了好幾周,起初的想法是:圍繞每一個具體的消息中間件,不僅要寫透,而且要控制好篇幅,寫下來發(fā)現(xiàn)實在太難了,兩者很難兼得。
最后決定還是分成多篇寫吧。一方面,能加快下輸出頻率;另一方面,大家也更容易消化。
廢話不多說了,第二彈開始發(fā)車。
01 為什么從 Kafka 開始?
《吃透 MQ 》的開篇 圍繞 MQ 「一發(fā)一存一消費」的本質(zhì)展開,講解了 MQ 的通用知識,同時系統(tǒng)性地回答了:如何著手設(shè)計一個 MQ?
從這篇文章開始,我會講解具體的消息中間件,之所以選擇從 Kafka 開始,有 3 點考慮:
第一,RocketMQ 和 Kafka 是目前最熱門的兩種消息中間件,互聯(lián)網(wǎng)公司應(yīng)用最為廣泛,將作為本系列的重點。
第二,從 MQ 的發(fā)展歷程來看,Kafka 先于 RocketMQ 誕生,并且阿里團隊在實現(xiàn) RocketMQ 時,充分借鑒了 Kafka 的設(shè)計思想。掌握了 Kafka 的設(shè)計原理,后面再去理解 RocketMQ 會容易很多。

第三,Kafka 其實是一個輕量級的 MQ,它具備 MQ 最基礎(chǔ)的能力,但是在延遲隊列、重試機制等高級特性上并未做支持,因此降低了實現(xiàn)復(fù)雜度。從 Kafka 入手,有利于大家快速掌握 MQ 最核心的東西。
交代完背景,下面請大家跟著我的思路,一起由淺入深地分析下 Kafka。
02 扒開 Kafka 的面紗
在深入分析一門技術(shù)之前,不建議上來就去了解架構(gòu)以及技術(shù)細節(jié),而是先弄清楚它是什么?它是為了解決什么問題而產(chǎn)生的?
掌握這些背景知識后,有利于我們理解它背后的設(shè)計考慮以及設(shè)計思想。
在寫這篇文章時,我查閱了很多資料,關(guān)于 Kafka 的定義可以說五花八門,不仔細推敲很容易懵圈,我覺得有必要帶大家捋一捋。
我們先看看 Kafka 官網(wǎng)給自己下的定義:
- Apache Kafka is an open-source distributed event streaming platform.
翻譯成中文就是:Apache Kafka 是一個開源的分布式流處理平臺。
Kafka 不是一個消息系統(tǒng)嗎?為什么被稱為分布式的流處理平臺呢?這兩者是一回事嗎?
一定有讀者會有這樣的疑問,要解釋這個問題,需要先從 Kafka 的誕生背景說起。
Kafka 最開始其實是 Linkedin 內(nèi)部孵化的項目,在設(shè)計之初是被當(dāng)做「數(shù)據(jù)管道」,用于處理以下兩種場景:
- 1、運營活動場景:記錄用戶的瀏覽、搜索、點擊、活躍度等行為。
- 2、系統(tǒng)運維場景:監(jiān)控服務(wù)器的 CPU、內(nèi)存、請求耗時等性能指標。
可以看到這兩種數(shù)據(jù)都屬于日志范疇,特點是:數(shù)據(jù)實時生產(chǎn),而且數(shù)據(jù)量很大。
Linkedin 最初也嘗試過用 ActiveMQ 來解決數(shù)據(jù)傳輸問題,但是性能無法滿足要求,然后才決定自研 Kafka。
所以從一開始,Kafka 就是為實時日志流而生的。了解了這個背景,就不難理解 Kafka 與流數(shù)據(jù)的關(guān)系了,以及 Kafka 為什么在大數(shù)據(jù)領(lǐng)域有如此廣泛的應(yīng)用?也是因為它最初就是為解決大數(shù)據(jù)的管道問題而誕生的。
接著再解釋下:為什么 Kafka 被官方定義成流處理平臺呢?它不就提供了一個數(shù)據(jù)通道能力嗎,怎么還和平臺扯上關(guān)系了?
這是因為 Kafka 從 0.8 版本開始,就已經(jīng)在提供一些和數(shù)據(jù)處理有關(guān)的組件了,比如:
- 1、Kafka Streams:一個輕量化的流計算庫,性質(zhì)類似于 Spark、Flink。
- 2、Kafka Connect:一個數(shù)據(jù)同步工具,能將 Kafka 中的數(shù)據(jù)導(dǎo)入到關(guān)系數(shù)據(jù)庫、Hadoop、搜索引擎中。
可見 Kafka 的野心不僅僅是一個消息系統(tǒng),它早就在往「實時流處理平臺」方向發(fā)展了。
這時候,再回來看 Kafka 的官網(wǎng)介紹提到的 3 種能力,也不難理解了:
- 1、數(shù)據(jù)的發(fā)布和訂閱能力(消息隊列)
- 2、數(shù)據(jù)的分布式存儲能力(存儲系統(tǒng))
- 3、數(shù)據(jù)的實時處理能力(流處理引擎)
這樣,kafka 的發(fā)展歷史和定義基本縷清了。當(dāng)然,這個系列僅僅關(guān)注 Kafka 的前兩種能力,因為這兩種能力都和 MQ 強相關(guān)。
03 從 Kafka的消息模型說起
理解了 Kafka 的定位以及它的誕生背景,接著我們分析下 Kafka 的設(shè)計思想。
上篇文章中我提到過:要吃透一個MQ,建議從「消息模型」這種最核心的理論層面入手,而不是一上來就去看技術(shù)架構(gòu),更不要直接進入技術(shù)細節(jié)。
所謂消息模型,可以理解成一種邏輯結(jié)構(gòu),它是技術(shù)架構(gòu)再往上的一層抽象,往往隱含了最核心的設(shè)計思想。
下面我們嘗試分析下 Kafka 的消息模型,看看它究竟是如何演化來的?
首先,為了將一份消息數(shù)據(jù)分發(fā)給多個消費者,并且每個消費者都能收到全量的消息,很自然的想到了廣播。
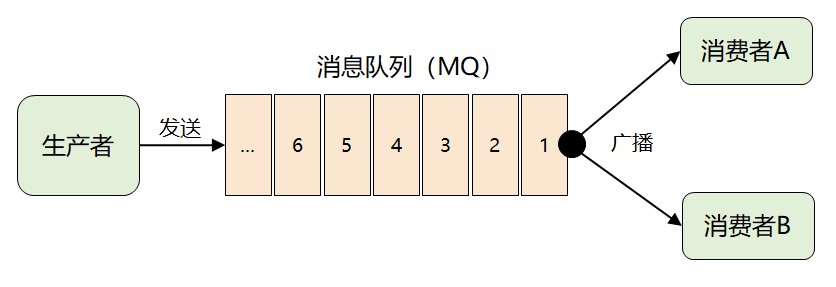
緊接著問題出現(xiàn)了:來一條消息,就廣播給所有消費者,但并非每個消費者都想要全部的消息,比如消費者 A 只想要消息1、2、3,消費者 B 只想要消息4、5、6,這時候該怎么辦呢?
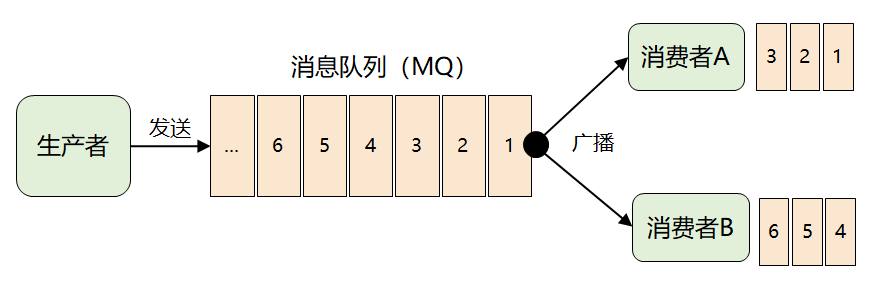
這個問題的關(guān)鍵點在于:MQ 不理解消息的語義,它根本無法做到對消息進行分類投遞。
此時,MQ 想到了一個很聰明的辦法:它將難題直接拋給了生產(chǎn)者,要求生產(chǎn)者在發(fā)送消息時,對消息進行邏輯上的分類,因此就演進出了我們熟知的 Topic 以及發(fā)布-訂閱模型。
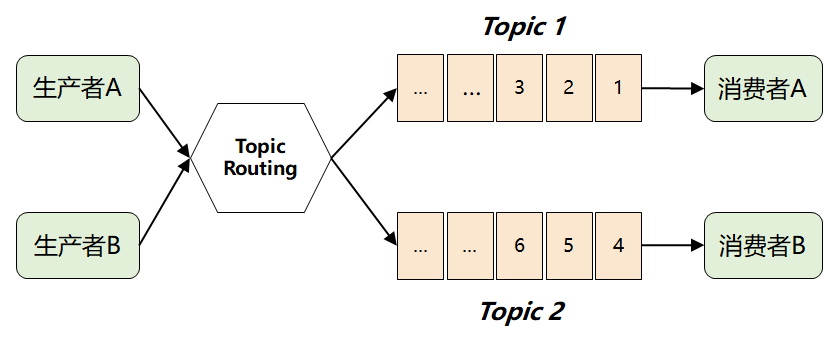
這樣,消費者只需要訂閱自己感興趣的 Topic,然后從 Topic 中獲取消息即可。
但是這樣做了之后,仍然存在一個問題:假如多個消費者都對同一個 Topic 感興趣(如下圖中的消費者 C),那又該如何解決呢?
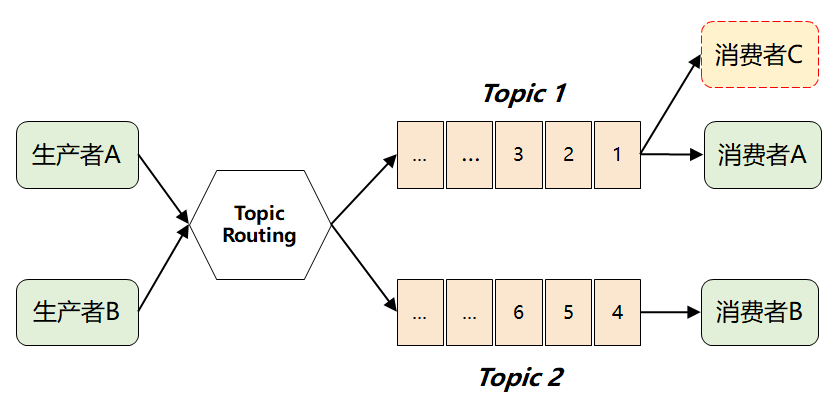
如果采用傳統(tǒng)的隊列模式(單播),那當(dāng)一個消費者從隊列中取走消息后,這條消息就會被刪除,另外一個消費者就拿不到了。
這個時候,很自然又想到下面的解決方案:
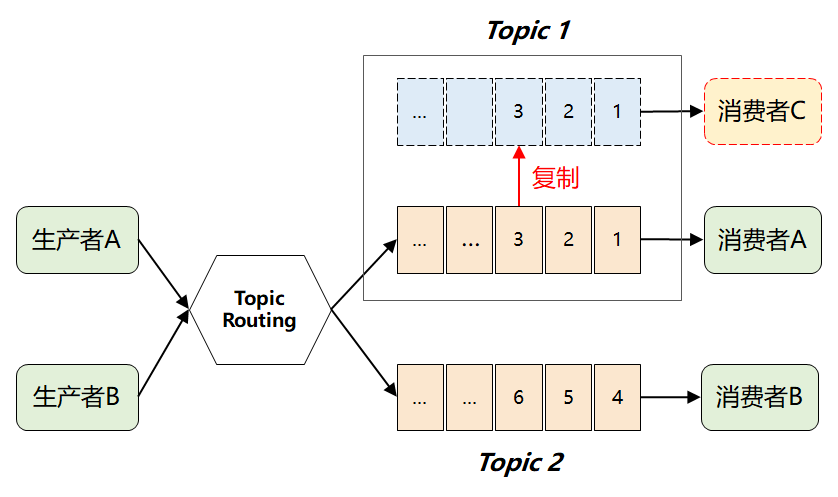
也就是:當(dāng) Topic 每增加一個新的消費者,就「復(fù)制」一個完全一樣的數(shù)據(jù)隊列。
這樣問題是解決了,但是隨著下游消費者數(shù)量變多,將引發(fā) MQ 性能的快速退化。尤其對于 Kafka 來說,它在誕生之初就是處理大數(shù)據(jù)場景的,這種復(fù)制操作顯然成本太高了。
這時候,就有了 Kafka 最畫龍點睛的一個解法:它將所有消息進行了持久化存儲,由消費者自己各取所需,想取哪個消息,想什么時候取都行,只需要傳遞一個消息的 offset 即可。
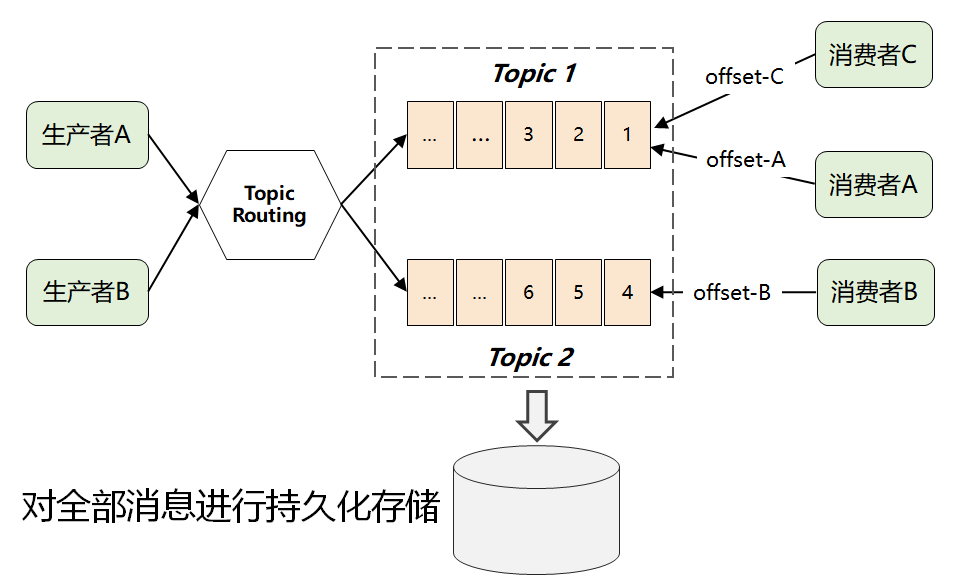
這樣一個根本性改變,徹底將復(fù)雜的消費問題又轉(zhuǎn)嫁給消費者了,這樣使得 Kafka 本身的復(fù)雜度大大降低,從而為它的高性能和高擴展打下了良好的基礎(chǔ)。(這是 Kafka 不同于 ActiveMQ 和 RabbitMQ 最核心的地方)
最后,簡化一下,就是下面這張圖:
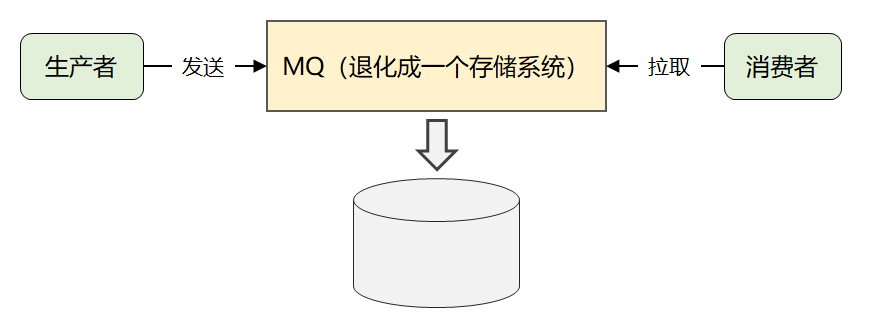
這就是 Kafka 最原始的消息模型。
這也間接解釋了第二章節(jié)中:為什么官方會將 Kakfa 同時定義成存儲系統(tǒng)的原因。
當(dāng)然 Kafka 的精妙設(shè)計遠非這些,由于篇幅原因,后面的文章再接著分析。
04 寫在最后
這篇文章從 Kafka 的誕生背景講起,帶大家捋清了 Kafka 的定義和它要解決的問題。
另外,一步步分析了 Kafka 的消息模型和設(shè)計思想,這是 Kafka 最頂層的抽象。
本文轉(zhuǎn)載自微信公眾號「武哥漫談IT」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系武哥漫談IT公眾號。